别再手动啃文献了!大模型在材料科学中的硬核应用,看完这一篇,科研效率提升10倍!

在AI与材料科学研究中,文献知识的提取与重构至关重要,但传统人工提取方式存在效率低、信息完整性和逻辑一致性难保障等问题。北京工业大学孙少瑞研究团队提出了一种基于大语言模型(LLMs)的通用方法,成功解决了这一难题,相关成果发表于《Communications Materials》。
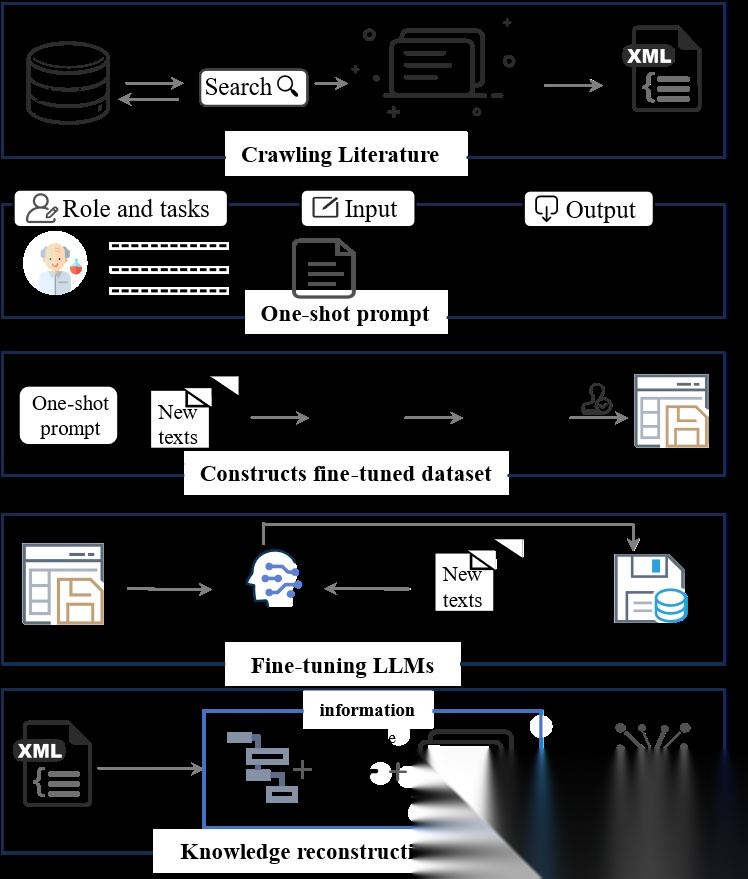
构建高效的文献知识提取框架
研究团队采用LLM,通过提示词设计构建了包含156个合成段落的高质量数据集,涵盖6337个合成相关实体信息。随后,利用该数据集微调LLaMA3-8B-instruct、Gemma-7B、Phi3-mini-128k-instruct和GPT3.5-turbo-1106四种主流LLMs。

Fig. One-shot prompt learning designed for GPT-4 to construct a work-cleaned dataset
在选择性催化还原(SCR)催化剂合成路线提取任务中,微调后的模型表现优异,信息提取的精确率达0.928、召回率0.957、F1分数0.962,显著优于MatBERT、SciBERT等传统基线模型。其中,GPT和Llama模型性能突出,GPT在合成步骤和条件提取上的F1分数分别高达0.983和0.981,能精准捕捉实验关键细节。同时,模型的“幻觉”发生率低,且合成步骤的逻辑顺序准确性高,为实验可重复性提供了保障。
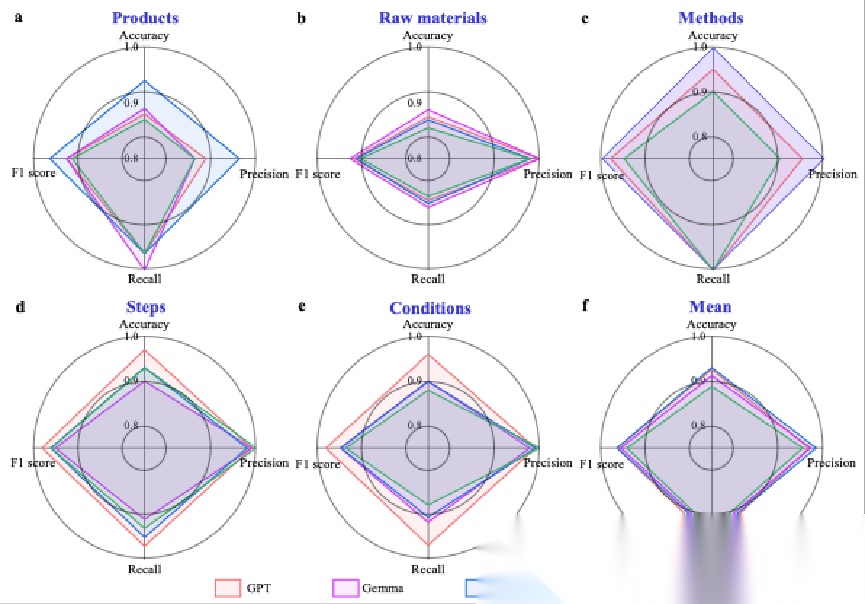
跨领域域应用:模型适配多领域材料合成信息提取
不同于传统提取方法泛化能力弱的局限,该研究的微调模型展现出强大的跨领域迁移能力。在完成SCR领域训练后,模型成功应用于锂离子电池(Li-ion)、析氢反应(HER)、氧还原反应(ORR)、析氧反应(OER)和甲醇水蒸气重整(MSR)五大领域。每个领域测试结果显示,Llama、Gemma和GPT模型在各领域的产物、原料、合成方法等信息提取任务中均保持高准确率,能够快速适配不同材料体系的文献知识的提取与重构需求。
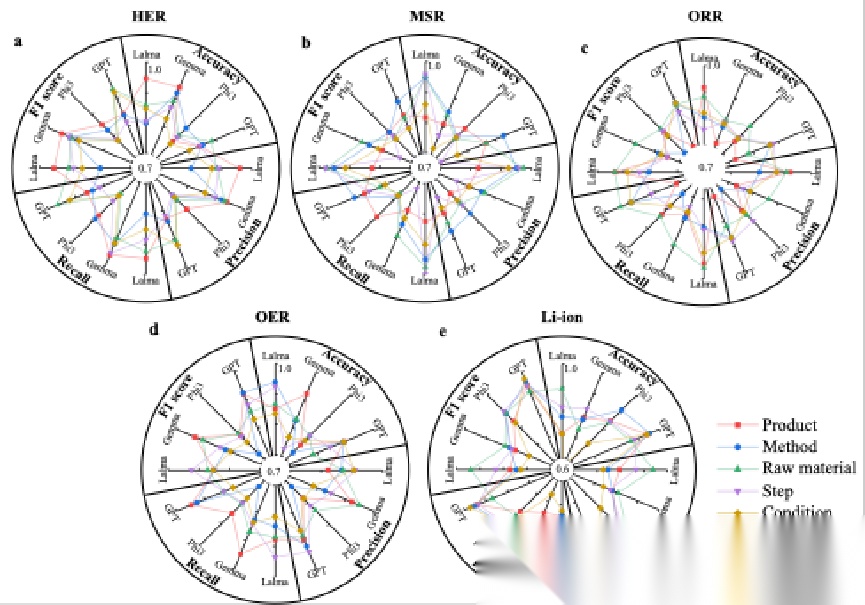
**Fig.10 | Performance of fine-tuned LLMs across five domains.**The figure compares the performance of four LLMs (Llama, Gemma, Phi3, GPT) across five domains: a HER, b MSR,c ORR, d OER, and e Li-ion research. Model capabilities are evaluated using accuracy, precision, recall, and F1 score to assess their performance in extracting information related to products, methods, raw materials, steps, and conditions.
规模提取:形成结构化文献知识资源
借助优化后的模型,研究团队对2205篇材料科学文献进行大规模信息提取,成功获取48925个核心实体,包括3715种产物、3186种制备方法、3011种原料、19102个合成步骤和23626个制备条件。所有提取数据均以标准化JSON格式存储,符合FAIR数据管理原则,为后续研究提供了可直接复用的结构化资源。目前,这些数据已公开在GitHub仓库(https://github.com/Shaoruisun/LLMs-MatLitRecon),方便科研人员获取使用。
知识图谱:可视化呈现材料关联网络
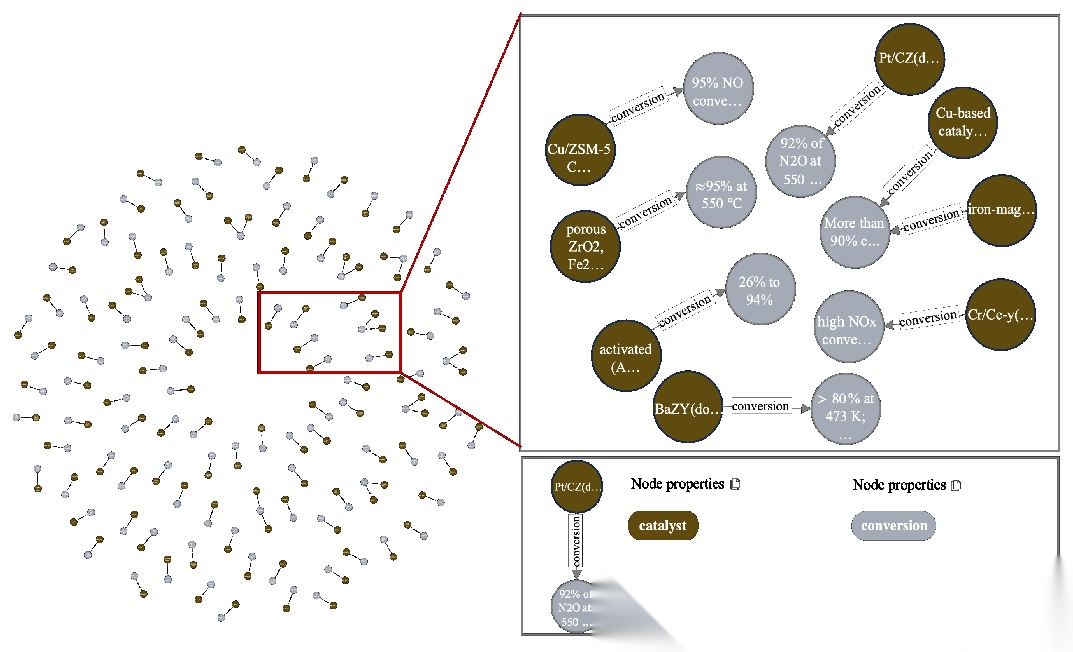
基于提取的海量实体和关系,研究团队构建了包含26400个节点、55338条关系的材料科学知识图谱。该图谱以催化剂为核心,串联起原料、合成方法、步骤、条件、性能指标等多层级信息,清晰呈现各要素间的物理化学依赖、工艺参数关联和性能相关性。

Fig. 11 | Visualization of partial synthetic entities and their relationships in the knowledge graph
通过这一知识图谱,科研人员可按合成方法查询适配催化剂、基于性能指标筛选材料(如快速锁定转化率超90%的高性能催化剂),还能追溯实验全流程细节。此外,图谱提供了详细的使用指南和交互式演示,助力科研人员高效开展数据探索与分析,加速新材料发现和实验设计优化。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)