Course15:视觉大模型与多模态理解
Qwen 多模态模型中图片 Token ID 与向量的核心理解
文本 Token 是 “语言的最小语义单元”,图片 Token 是 “视觉的最小特征单元”
—— 两者最终都会被映射到同一维度的向量空间,让模型能 “读懂” 图文的关联语义。
| 维度 | 文本 Token(如 Qwen 的中文分词) | 图片 Token(Qwen-VL 的视觉 Token) |
|---|---|---|
| 拆分方式 | 按语义拆分(字 / 词 / 子词,如 “手机”→[手,机]) | 按空间特征拆分(网格切块→特征编码) |
| Token ID 含义 | 对应词典里的语义符号(如 ID=1001→“手”) | 对应视觉特征的编码索引(无字面含义) |
| 向量本质 | 语义向量(代表这个词的含义) | 视觉特征向量(代表这个区域的视觉特征) |
文本 Token 是 “语言积木”,图片 Token 是 “视觉积木”,向量是 “积木的特征描述”,Qwen-VL 就是用这些积木拼出图文关联的逻辑。
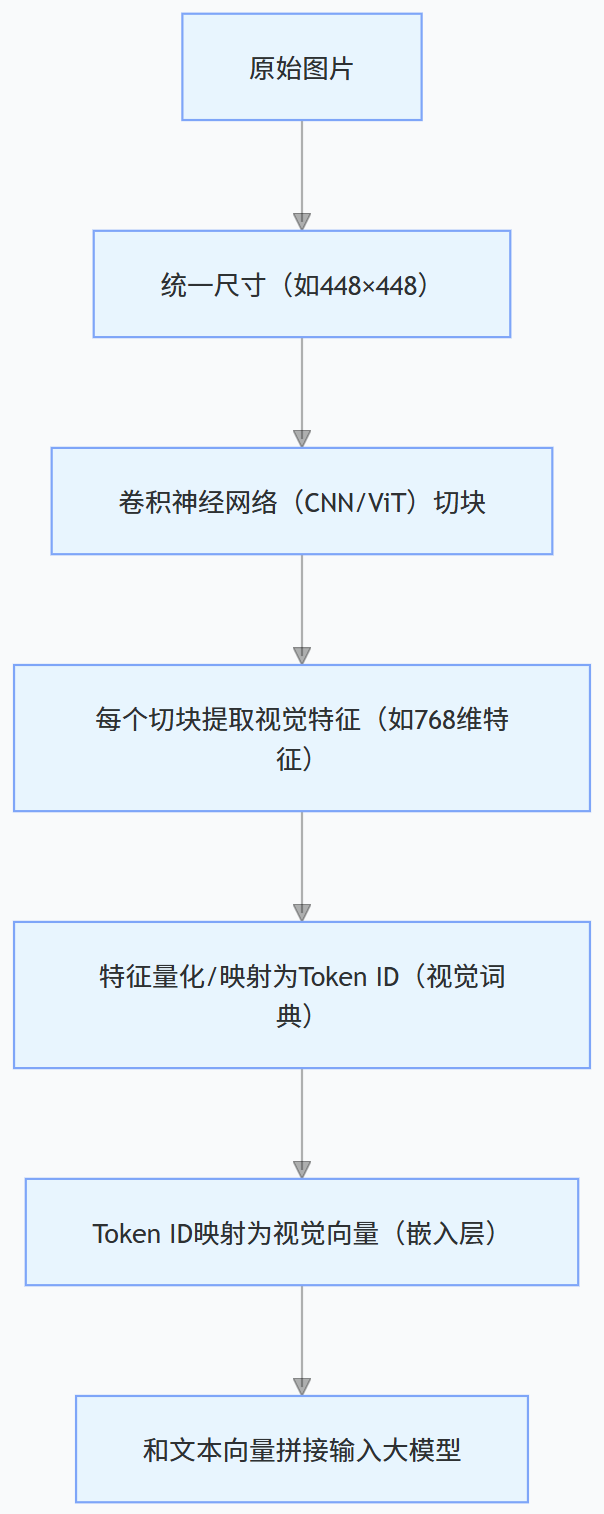
Qwen-VL 中图片 Token 的生成过程(核心逻辑)
每个 Patch 通过卷积 / Transformer 层提取视觉特征(比如 768 维的特征向量,代表这个 Patch 的颜色、纹理、边缘、形状等信息);
• Qwen-VL 内置一个 “视觉词典”(和文本词典类似,但存的是视觉特征模板),把每个 Patch 的特征匹配到词典中最接近的模板,得到一个视觉 Token ID;
Token ID 是 “索引”,向量是 “本质” ◦
Token ID 只是一个数字标签(比如 ID=20001),本身无意义,只是用来查 “视觉词典”; ◦ 向量才是核心:768 维的向量,每一个维度代表一个视觉特征维度,所有维度组合起来,就唯一描述了这个 Patch 的视觉特征。
图片 Token 向量和文本 Token 向量 “在同一语义空间”
Qwen-VL 的核心设计是 “图文对齐”:
-
训练时,模型会学习 “文本 Token 向量” 和 “图片 Token 向量” 的关联(比如文本 “红色苹果” 的向量,和图片中 “苹果 Patch” 的向量会被拉到相近位置);
-
推理时,模型能通过向量的相似度,理解 “文字描述” 和 “图片内容” 的对应关系。
VLM在车辆保险理赔的应用



视频基础模型
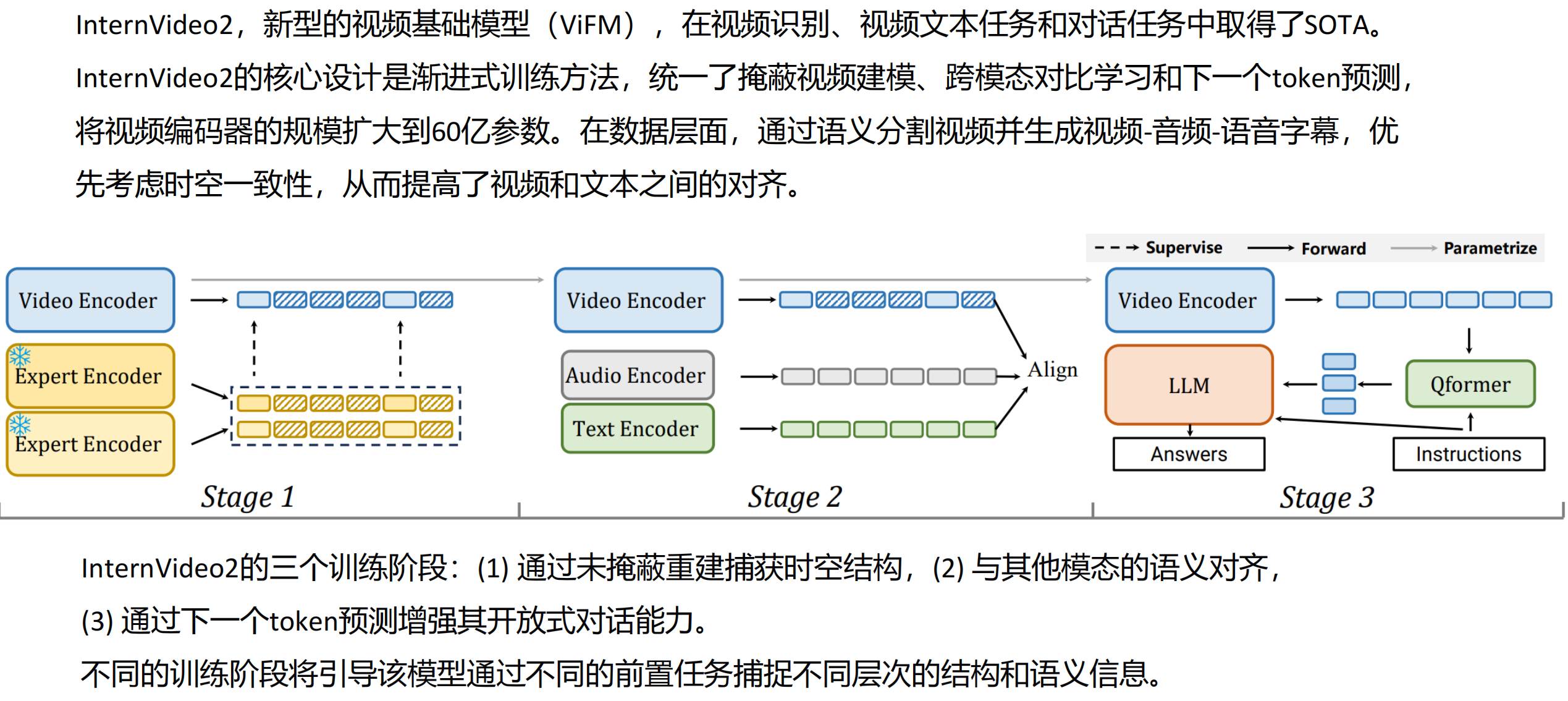
视频多模态注释框架 VidCap
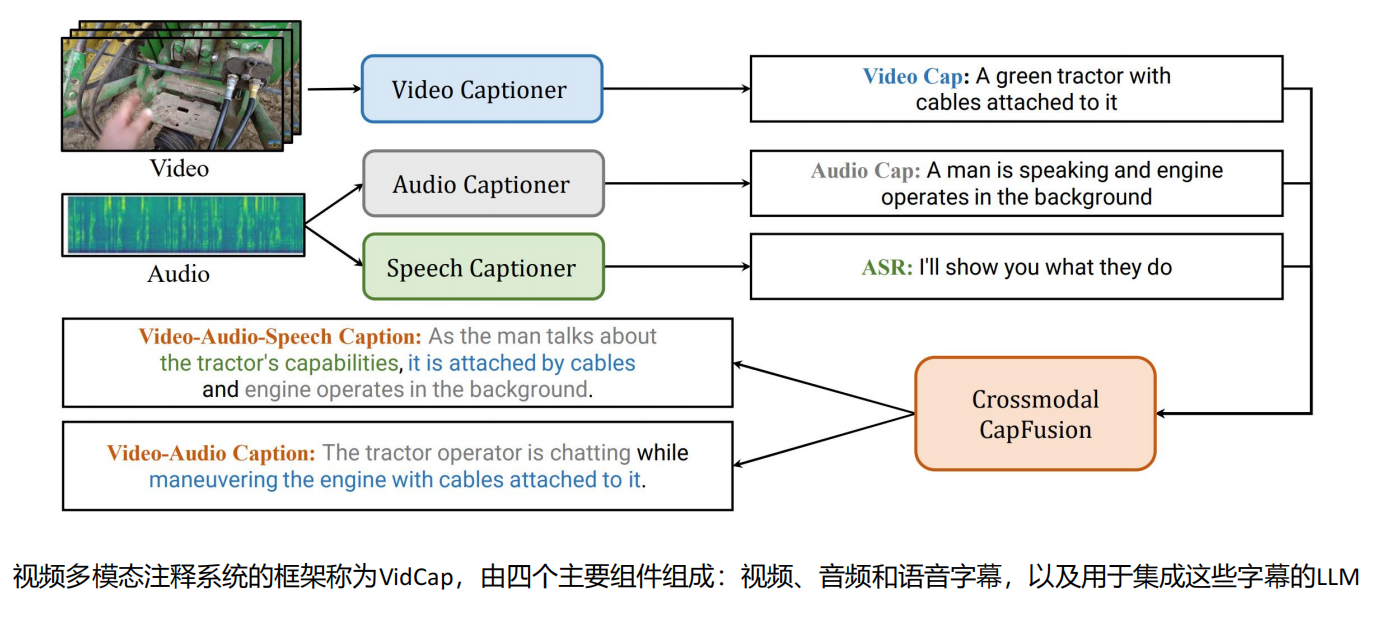
InternVideo2 预训练
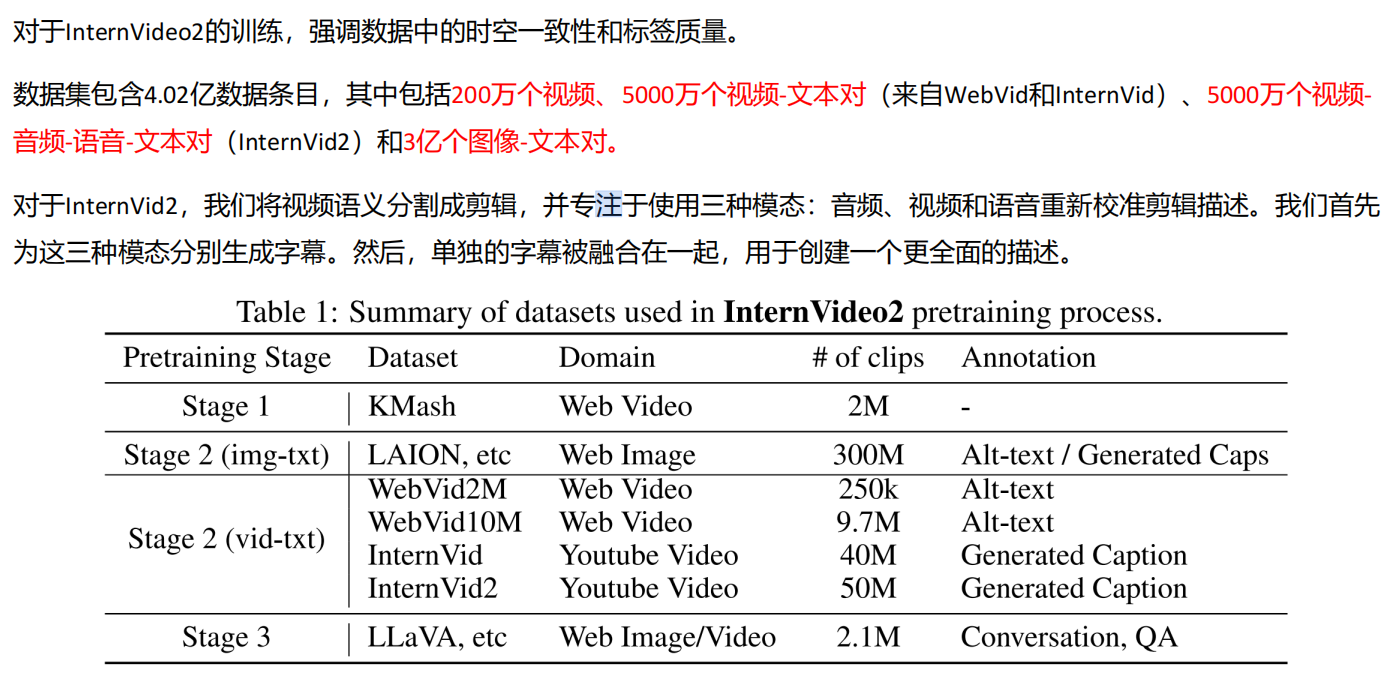
模型表现:时间动作识别

模型表现:混淆动作识别

模型表现:视频中心对话
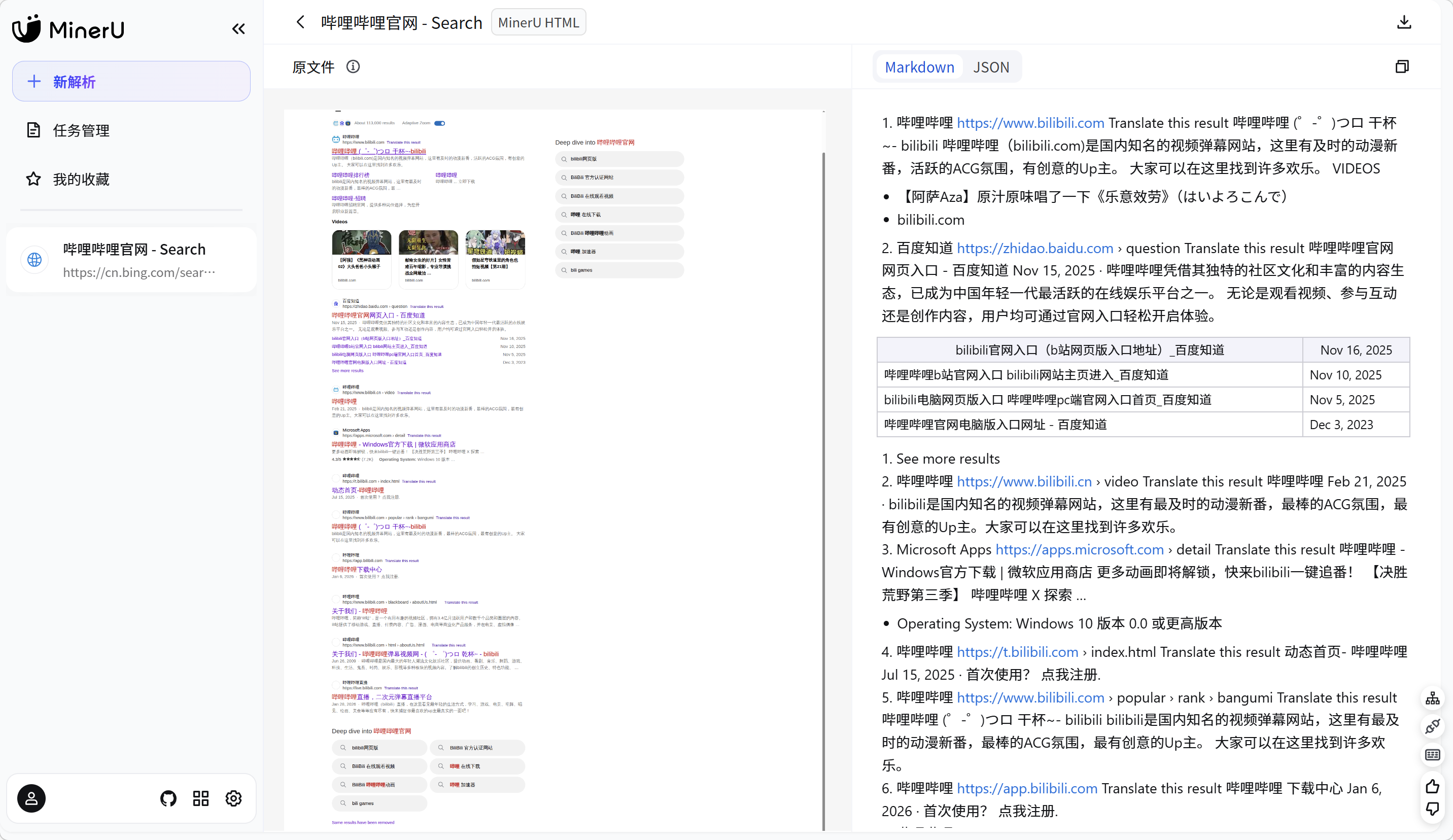
MinerU
MinerU 专注于高效解析和提取复杂的 PDF 文档、网页和电子书,并将其转换为易于分析的 Markdown 或
JSON 格式。由上海人工智能实验室OpenDataLab 团队 开发。
核心技术
• 布局检测:基于 LayoutLMv3 微调,识别文本、表格、图片等区域。
• 公式识别:使用 YOLOv8 检测公式,UniMERNet 模型转换 LaTeX。
• OCR 增强:采用 PaddleOCR 提高文本识别准确率。
应用场景
• 大模型训练:为书生·浦语等模型提供高质量语料。
• 学术研究:提取论文、教材中的关键信息。
• 法律与金融:解析合同、研报等结构化数据。
MinerU:网页信息解析
CASE:VLM在寿险里的应用,多语言识别


CASE:VLM在车险里的应用

CASE:车辆剐蹭视频理解

Q&A
Q:老师,啥时讲解下 deep agents + skills ?
单Agent + Skills
LangChain (deep agents) +Skills
Q:教师模型如何体现他的作用呢在代码中?在代码中都没看到教师模型,蒸馏和GRPO的过程都没看到
教师模型 => 帮我撰写训练集 <query, answer> 知识蒸馏
Q:单agent如果功能太多会不会导致注意力不集中反而不如分发agent+多专业agent协作好
单Agent + Skills 是当前主流
多Agent 也有问题,
Q:金融行业意图识别只需要SFT就可以吗?准备的数据应该什么格式
<query, answer>
Q:教师模型和蒸馏和GRPO 是分开独立工作的对吗老师? 教师模型先把数据弄好,再做模型蒸馏 GRPO这些对吗?
Qwen3.5
tokenizer
id
32700 个文本ID
image => tokenizer id, text => text tokenizer id
64000个
信息表达的统一 => tokenizer id
Q: “图像的tokenizer”--->变成了text tokenizer吗?
input token =>output token (只输出了text)
<query, answer>
<text+image, answer>
所以不管图像还是视频最终都是转化为文字,本质对文字进行处理吗?
语义理解(token) =>
input(text, image) => model(统一编码,token) =>output
医疗的规范格式?
多模态图像理解,现阶段可能还不成熟
Step1,整理一个测试集 <query, image => answer>
Step2,通过 prompt + LLM,进行回答
Step3, 人工进行审核 =》 是否某种能力缺失
进行人工标注,整理成新的训练 <query, image =>人的answer>
使用unsloth 进行微调;
qwen-vl => 回答一些问题 => 找到回答质量不太好的
蒸馏gemini 对这些问题,重新回答 => 梳理出 <query, image, answer>
Q:数据标注工作
业务同事来标注(冷启动,作为种子数据) =>
业务一般只给出基本原则,具体的还是要开发做
Q:为什么不直接用gemini而让qwen-vl去学习gemini
gemini 成本高
gemini 回答也不一定都对 (初步标注)=> 人工修正
产品标
openclaw + gemini/GPT5.4 =>
成本低;
Q:能不能详细讲一下如何自动化批量生成标注数据
大模型帮我们进行标注
qwen-vl 的训练
gemini进行标注 <query, image => answer>
Q:InternVideo2 ,理解视频是直接输入MP4,还是要从原文件抽帧输入多图?
直接给mp4
Q:openclaw能免费使用吗?
不能,它需要其他的大模型
Q:每一步完成的标准是什么?
训练集 和 验证集进行评估,如果 验证集的loss 很久没有下降了(比如 最近20轮) => 已经学好
Q:mineru 算大模型吗?
mineru不是生成式AI,
layout + ocr 的文本识别模型
Q:qwen vl和DS有什么区别
qwen-vl 多模态大模型(支持 图像,文本)=> 文本回答
deepseek 文本 => 文本
Q:没有看懂最后需要的结果是什么
mineru => .md .json
input: pdf, html, docx, ppt
Q:image -> image token, text -> text token, 这两类token怎么计算语义相关性
embedding
text input => 多模态embedding 1024维度
image input => 多模态embedding 1024维度
Q:多模态模型怎么做RAG?
rag 提供补充上下文
query + RAG => LLM
text input => 多模态embedding 1024维度
image input => 多模态embedding 1024维度
RAG知识库 里面会有很多chunks,也都有chunks embedding
Q:学校作业批改照片识别,使用哪种OCR方法识别准确高
qwen-vl

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)