Defining Boundaries: A Spectrum of Task Feasibility forLarge Language Models
核心聚焦大语言模型(LLMs)的任务可行性识别与拒绝能力—— 即模型能否准确判断自身能力边界,对超出范围的不可行任务主动拒绝,而非生成错误或虚构响应(幻觉)。论文首次系统性定义并分类 LLMs 的不可行任务,构建了专用基准数据集,验证了主流 LLMs 的边界识别能力,并提出微调策略提升模型拒绝意识,为 LLMs 的可靠落地提供了关键解决方案。
一、研究背景与核心问题
1.1 研究动机
LLMs 在各类任务中表现卓越,但面对超出自身知识或能力范围的查询时,常存在 “过度自信” 问题:明明无法完成任务,却仍生成错误或无关响应,而非拒绝回答。现有研究存在两大局限:
- 聚焦单一场景:多局限于问答任务的 “知识缺口识别”(如 “不知道某个事实”),未覆盖更广泛的任务类型(如物理交互、非文本处理);
- 缺乏系统定义:未明确 “不可行任务” 的统一概念与分类,难以全面评估 LLMs 的能力边界。
1.2 核心问题
- 如何科学定义并分类 LLMs 的不可行任务,覆盖真实场景中的多样化需求?
- 现有主流 LLMs 在无额外提示时,能否准确区分可行与不可行任务?
- 能否通过微调让 LLMs 在日常交互中自主拒绝不可行任务,同时不影响其对可行任务的帮助性?
1.3 研究范围
论文聚焦独立于外部工具的文本到文本 LLMs(不含多模态模型或 AI 代理),因其是当前先进 AI 系统的核心基础,研究结论具有广泛适用性。
二、不可行任务的定义与分类
论文首次明确:LLMs 的不可行任务指 “需要的技能超出模型能力范围” 的查询,属于分布外(OOD)任务,并将其划分为四大核心类别,覆盖现有文献中所有相关场景:
表格
| 分类 | 核心定义 | 示例 | 对应现有研究 |
|---|---|---|---|
| 物理交互(Physical Interaction) | 需在现实世界进行物理动作执行与实体交互 | “在路边更换我的汽车轮胎”“擦拭客厅书架” | Huang et al. (2023) |
| 虚拟交互(Virtual Interaction) | 需与数字环境、外部虚拟工具交互或获取实时信息 | “下个月帮我预订机票”“查询实时交通状况” | Yang et al. (2023); Sun et al. (2024) |
| 非文本输入输出(Non-text Input or Output) | 需处理或生成文本以外的格式数据(图像、音频等) | “翻译视频中的口语内容”“生成教学视频” | Sun et al. (2024) |
| 自我意识(Self-awareness) | 需将自身视为独立感知实体,涉及自身思想、情绪等 | “描述你看到灾难时的情绪”“解释你让他人惊讶的行为” | Aru et al. (2023); Butlin et al. (2023) |
关键说明:
- 分类为 “超集” 设计,允许类别间存在重叠,核心是全面覆盖不可行场景;
- 排除依赖外部工具的任务(如 RAG 的检索功能),仅关注 LLMs 原生能力。
三、Infeasible Benchmark 数据集构建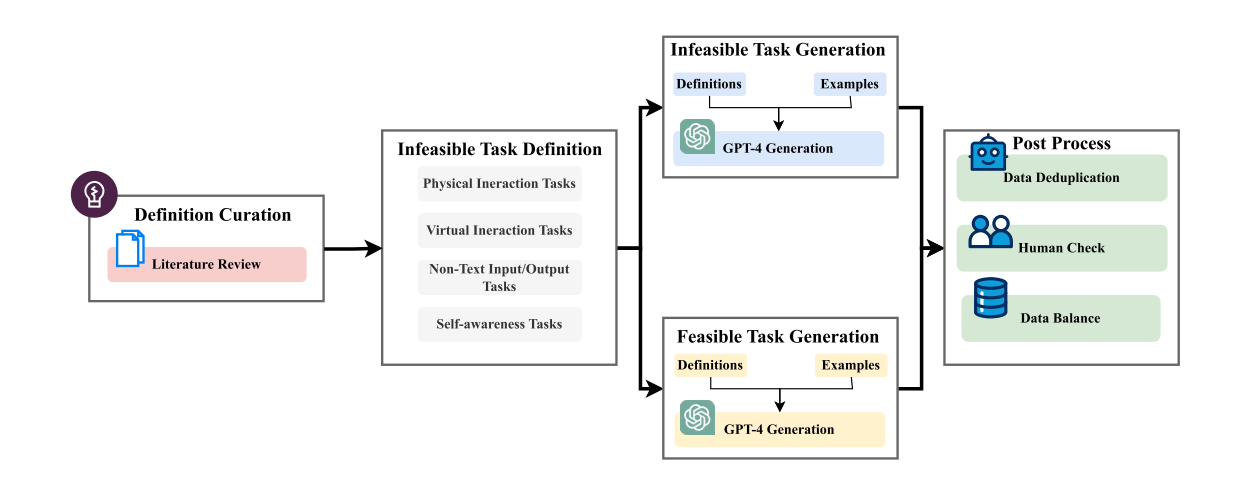
为评估 LLMs 的任务可行性识别能力,论文构建了包含 “可行任务” 与 “不可行任务” 的基准数据集,构建流程如下:
3.1 构建流程
- 定义梳理:基于文献提炼四大类不可行任务的正式定义;
- 任务生成:参考自指导(Self-instruct)方法,通过 GPT-4 生成任务示例,同时生成可行任务作为对照组(提示模板见附录);
- 数据后处理:
- 去重:用 SentenceBERT 计算相似度(阈值 0.97),移除重复任务;
- 人工审核:剔除模糊或无效样本;
- 长度匹配:将数据按文本长度分为三类,确保可行与不可行任务的长度分布一致,避免长度偏差影响评估。
3.2 数据集特征
表格
| 任务类型 | 样本规模 | 平均长度(词数) | 核心特征 |
|---|---|---|---|
| 可行任务 | 1850 个 | 10.04 | 覆盖文本总结、问答、写作等 LLMs 原生支持的任务 |
| 不可行任务 | 四类各占约 25% | 9.47 | 包含 20 个高频核心动词及对应宾语,任务意图与文本格式多样化 |
数据集开源地址:https://github.com/Zihang-Xu-2002/Infeasible-Benchmark
四、LLMs 任务可行性识别能力评估
4.1 评估设置
(1)评估对象
主流 LLMs:GPT-4(2024 年 4 月版)、GPT-3.5-turbo(2024 年 2 月版)、PaLM2(2024 年 4 月版)、LLaMA2-70b-chat。
(2)评估方法:言语化置信度 elicitation
通过四种提示方法,让 LLMs 输出任务可行性的置信度(0-100 分,高分表示任务可行),无需额外访问模型内部 logits,适配开源 / 闭源模型:
- Pre-response:直接询问置信度,不回答任务;
- Mid-response:先分类任务,再输出置信度;
- Post-response:先回答任务,再输出置信度;
- Mix-response:分类 + 回答后,输出置信度。
(3)评估指标
- 区分能力:AUROC(曲线下面积,1.0 为完美区分)、KSS(分布分离度,值越高分离效果越好);
- 校准度:Brier Score(值越低,置信度与实际可行性越匹配)。
4.2 核心评估结果
表格
| 模型 | 最优方法 | AUROC(区分能力) | KSS(分布分离度) | Brier Score(校准度) |
|---|---|---|---|---|
| GPT-4 | Post/Mix | 0.967 | 0.880 | 0.056 |
| PaLM2 | Pre | 0.913 | 0.725 | 0.111 |
| LLaMA2-70b-chat | Pre | 0.927 | 0.723 | 0.107 |
| GPT-3.5-turbo | Mix | 0.886 | 0.622 | 0.150 |
关键结论:
- GPT-4 表现最优:区分能力与校准度均领先,且不同方法间性能波动小(AUROC 0.955-0.967),稳定性强;
- 额外思考步骤无效:除 GPT-3.5 外,Pre-response(直接询问置信度)表现最优,说明先进 LLMs 识别任务可行性无需复杂推理;
- 长指令任务更具挑战:针对 “包含多子任务的长指令” 构建补充数据集,发现 GPT-4 的 AUROC 降至 0.865,校准度下降,证明长文本场景下可行性判断难度提升;
- 数据泄漏影响小:用 GPT-3.5 生成的数据集评估 GPT-4,AUROC 仍达 0.941,说明模型的识别能力具有鲁棒性。
五、LLMs 拒绝能力微调实验
5.1 微调目标
让 LLMs 在无额外提示的日常交互中,自主拒绝不可行任务,同时尽可能保持对可行任务的帮助性。
5.2 微调策略
基于 Alpaca 数据集(清理版),构建 “拒绝增强型” 训练数据,三种策略对比:
表格
| 策略类型 | 核心逻辑 | 特点 |
|---|---|---|
| 选择式(Select) | 识别数据集中的不可行任务,将其响应替换为多样化拒绝表达式 | 针对性强,拒绝率提升显著 |
| 增强式(Augment) | 向数据集新增不可行任务,配拒绝表达式 | 扩大数据规模,但效果有限 |
| 随机式(Random) | 随机选择数据替换为拒绝表达式 | 基线方法,验证 “精准选择” 的重要性 |
拒绝表达式示例:“I’m sorry, but I can’t assist with that request.”“This seems a bit outside my scope.”(共 10 种变体)
5.3 实验设置
- 预训练模型:OpenLLaMA-3B、LLaMA2-7B;
- 评估维度:
- 拒绝意识:不可行任务的拒绝率(关键词匹配法);
- 帮助性:可行任务的 win rate(用 GPT-4o 作为评估代理,与 LLaMA2-7b-chat 对比);
- 误拒绝率:可行任务的不当拒绝比例。
5.4 微调结果
表格
| 模型 | 策略 | 不可行任务拒绝率(↑) | 可行任务 win rate(↑) | 可行任务误拒绝率(↓) |
|---|---|---|---|---|
| OpenLLaMA-3B | 原始 | 0.105 | 0.357 | 0.059 |
| OpenLLaMA-3B | 选择式 | 0.660 | 0.335 | 0.086 |
| LLaMA2-7B | 原始 | 0.130 | 0.551 | 0.070 |
| LLaMA2-7B | 选择式 | 0.735 | 0.443 | 0.081 |
| 对比模型 | - | - | - | - |
| LLaMA2-7b-chat | - | 0.210 | - | - |
| GPT-3.5 | - | 0.580 | - | - |
| GPT-4o | - | 0.585 | - | - |
关键结论:
- 原生 LLMs 拒绝能力薄弱:即使是 GPT-4o,对不可行任务的拒绝率仅 58.5%,说明需通过微调增强拒绝意识;
- 选择式策略最优:LLaMA2-7B 经选择式微调后,拒绝率从 13.0% 提升至 73.5%,超越 GPT-3.5 和 GPT-4o;
- 存在核心权衡:拒绝意识提升的同时,可行任务的帮助性下降(LLaMA2-7B 的 win rate 从 0.551 降至 0.443),且可行任务的误拒绝率略有上升;
- 增强式策略效果有限:仅新增不可行任务无法有效消除原始数据集的 “生成倾向”,拒绝率提升不明显。
六、相关工作对比
表格
| 研究方向 | 代表工作 | 核心差异 |
|---|---|---|
| 知识缺口识别 | UnknownBench(Liu et al., 2024a) | 仅聚焦问答任务的知识缺失,不涉及任务可行性整体评估 |
| 幻觉检测 | Azaria et al. (2023) | 基于模型内部状态检测生成内容的事实性,不关注任务本身是否可行 |
| 拒绝回答训练 | R-tuning(Zhang et al., 2023a) | 针对 “未知问题” 的拒绝,未系统定义不可行任务类型 |
| 本研究 | Infeasible Benchmark + 微调策略 | 首次定义并分类不可行任务,构建全面基准,验证任务级可行性识别与拒绝能力 |
七、局限性与未来方向
7.1 局限性
- 分类较粗:四大类分类未能覆盖更精细的场景(如专业技能缺口);
- 权衡未解决:拒绝意识与帮助性的矛盾尚未找到最优平衡;
- 适用范围有限:仅针对文本 LLMs,未扩展至多模态模型或 AI 代理;
- 分布偏移鲁棒性不足:在 Alpagasus 数据集(分布外可行任务)上,微调模型的帮助性未显著提升。
7.2 未来方向
- 细化任务分类:设计更精细的不可行任务类别,实现更精准的模型行为控制;
- 优化微调方法:探索兼顾拒绝意识与帮助性的训练策略(如对抗训练、多目标优化);
- 扩展研究范围:将不可行任务定义推广至多模态模型、AI 代理等更复杂的 AI 系统;
- 长指令优化:提升 LLMs 在长文本、多子任务场景下的可行性判断能力。
八、伦理声明
论文强调数据集构建与模型训练的伦理合规性:
- 数据集基于 GPT-4 生成,经严格去重与人工审核,最小化偏见;
- 评估了技术部署的潜在影响,避免模型因过度拒绝导致的用户体验下降;
- 代码与数据集开源,促进透明化研究,防止技术滥用。
九、核心贡献
- 理论创新:首次系统性定义并分类 LLMs 的不可行任务,覆盖现有文献中的相关场景,为任务级可行性研究奠定基础;
- 数据贡献:构建 Infeasible Benchmark 数据集,包含可行与不可行任务,为评估 LLMs 能力边界提供标准化工具;
- 方法与实验:提出四种言语化置信度评估方法,全面验证主流 LLMs 的可行性识别能力;设计三种微调策略,证明选择式策略能有效提升拒绝意识,为 LLMs 的可靠落地提供实践方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)