CVPR 2025 | GaussianSpa: An “Optimizing-Sparsifying” Simplification Framework
01 论文信息
- 论文题目: GaussianSpa: An “Optimizing-Sparsifying” Simplification Framework for Compact and High-Quality 3D Gaussian Splatting
- 论文作者: Yangming Zhang, Wenqi Jia, Wei Niu, Miao Yin
- 发表单位: Department of Computer Science, University of Texas at Arlington;School of Computing, University of Georgia
- 发表会议\期刊: CVPR 2025
- 代码链接: https://github.com/noodle-lab/GaussianSpa
02 论文主要贡献
-
论文将 3DGS 的简化问题形式化为一个带稀疏约束的优化问题。作者不是把高斯剪枝简单看作后处理操作,而是把“保留渲染质量”和“压缩高斯数量”统一到同一个优化目标中。具体而言,作者将 Gaussian 的 opacity 作为核心稀疏变量,在训练目标中加入 (\ell_0) 稀疏约束,从而使 3DGS 的简化问题具有更明确的优化建模基础。
-
论文提出了一种 “optimizing-sparsifying” 交替求解框架。该框架把整个简化过程分为两个相互交替的子问题:一部分负责优化原始 Gaussian 参数,保证场景重建与渲染质量;另一部分负责对辅助变量进行精确稀疏化,从而逐步将模型压缩到更紧凑的表示。这种交替求解思路避免了直接对原始 Gaussian 粗暴裁剪所带来的不可逆信息损失。
-
GaussianSpa 在实现上引入了辅助变量 z 与对偶变量 u,并通过类似增广拉格朗日 / ADMM 风格的方式,在训练过程中持续推动真实 opacity 向稀疏表示靠近。也就是说,作者不是训练结束后一次性删点,而是在训练中逐步把高斯表示推向更稀疏的状态,使得模型能在压缩过程中更平滑地适应新的表示形式。
-
作者还展示了该框架具有一定的通用性。从公开代码来看,GaussianSpa 不仅可以基于 vanilla 3DGS 中的 opacity 做稀疏化,也可以结合 Mini-Splatting 中的 importance score 作为稀疏化依据。这说明该方法并不是严格绑定某一种单一剪枝标准,而是可以适配不同的高斯重要性度量方式。
-
实验结果表明 GaussianSpa 能在显著减少 Gaussian 数量的同时保持甚至提升渲染质量。论文与项目主页中均强调,在 Deep Blending 数据集上,相比原始 3DGS,GaussianSpa 在 Gaussian 数量减少约 10 倍 的情况下,平均 PSNR 仍可提升 0.9 dB,体现出该方法在质量与压缩率之间取得了较优平衡。
03 论文创新点
- 将 3DGS 简化问题显式建模为带 (\ell_0) 稀疏约束的优化问题。 传统高斯剪枝方法通常更偏向经验式规则,而本文从优化角度出发,将 Gaussian opacity 的稀疏性直接纳入训练目标,使“高质量重建”和“高压缩率表示”在统一框架下共同求解。
- 提出“Optimizing-Sparsifying”交替求解机制。 作者没有直接对原始 Gaussian 参数做不可逆剪枝,而是把求解拆成两个阶段:优化步负责最小化渲染损失并逼近稀疏目标,稀疏化步则对辅助变量执行精确稀疏化。这种交替过程相比直接硬剪枝更稳定,也更容易在压缩过程中保持图像质量。
- 引入辅助变量 z 和对偶变量 u,将稀疏约束平滑地融入训练过程。 在代码实现中,优化步通过附加二次罚项 (|a-z+u|^2) 让真实 opacity 向稀疏变量靠近,而稀疏化步再根据 opacity 或 importance score 对 z 做 hard thresholding。该设计使模型在训练阶段逐渐适应稀疏结构,而不是依赖训练结束后的单次暴力裁剪。
04 方法
4.1 问题建模
4.1.1 带稀疏约束的优化目标
论文将 3DGS 的简化写成如下优化问题:
mina,ΘL(a,Θ) \min_{\boldsymbol{a},\boldsymbol{\Theta}} \mathcal{L}(\boldsymbol{a},\boldsymbol{\Theta}) a,ΘminL(a,Θ)
同时满足:
∥a∥0≤κ \|\boldsymbol{a}\|_0 \leq \kappa ∥a∥0≤κ
其中,(\boldsymbol{a}) 表示 Gaussian 的 opacity,(\boldsymbol{\Theta}) 表示其余 Gaussian 参数,(\kappa) 表示允许保留的非零高斯数量。
4.1.1.1 选择 opacity 作为稀疏变量的原因
opacity 直接决定单个 Gaussian 对最终渲染的贡献。
因此,作者没有直接对位置、颜色或尺度做稀疏约束,而是把 opacity 作为核心稀疏变量。这样既符合 3DGS 的渲染机制,也便于后续做剪枝。

4.1.2 总体求解思路
由于带 (\ell_0) 约束的问题难以直接求解,作者引入辅助变量 (z) 和对偶变量 (u),把问题拆成两个交替执行的子问题:
- Optimizing step:优化原始 Gaussian 参数;
- Sparsifying step:对辅助变量做精确稀疏化。
这就是论文标题中的 “Optimizing-Sparsifying”。
4.2 Optimizing Step
4.2.1 数学形式
项目主页给出的优化步如下:
mina,ΘL(a,Θ)+δ2∥a−z+λ∥2 \min_{\boldsymbol{a},\boldsymbol{\Theta}} \mathcal{L}(\boldsymbol{a},\boldsymbol{\Theta}) + \frac{\delta}{2}\|\boldsymbol{a}-\boldsymbol{z}+\boldsymbol{\lambda}\|^2 a,ΘminL(a,Θ)+2δ∥a−z+λ∥2
这一步的目标有两个:
- 保持原始 3DGS 的重建质量;
- 让真实 opacity 逐渐靠近稀疏变量 (z)。
4.2.2 代码实现
在代码 optimizing_spa.py 中,优化步通过额外增加一个二次罚项实现:
loss += 0.5 * self.init_rho * (torch.norm(self.gaussians.get_opacity - self.z + self.u, p=2)) ** 2
也就是说,训练时不仅最小化原始渲染误差,还会额外约束当前 opacity 向稀疏目标靠近。
4.2.3 原始重建损失
训练脚本 train_op.py、train_opacity.py 和 train_imp_score.py 中,基础损失为:
Ll1 = l1_loss(image, gt_image)
ssim_value = ssim(image, gt_image)
loss = (1.0 - opt.lambda_dssim) * Ll1 + opt.lambda_dssim * (1.0 - ssim_value)
即采用 L1 + SSIM 的组合损失。
其中默认 lambda_dssim = 0.2,表示训练主要由 L1 驱动,同时加入一定比例的结构相似性约束。
4.3 Sparsifying Step
4.3.1 数学形式
项目主页给出的稀疏化步如下:
minzh(z)+δ2∥a−z+λ∥2 \min_{\boldsymbol{z}} h(\boldsymbol{z}) + \frac{\delta}{2}\|\boldsymbol{a}-\boldsymbol{z}+\boldsymbol{\lambda}\|^2 zminh(z)+2δ∥a−z+λ∥2
这里的 (z) 可以看作真实 opacity 的“精确稀疏版本”。
作者并不直接裁剪原始 Gaussian,而是先更新 z,再通过训练让真实 opacity 逼近它。这样能减少直接剪枝带来的不可逆损失。
4.3.2 基于 opacity 的稀疏化
在 optimizing_spa.py 中,若采用 opacity 作为稀疏标准,则对应函数为:
def prune_z(self, z):
index = int(self.prune_ratio * len(z))
z_sort, _ = torch.sort(z, 0)
z_threshold = z_sort[index-1]
z_update = ((z > z_threshold) * z)
return z_update
其含义是:
- 对当前 z 排序;
- 找到阈值;
- 低于阈值的元素直接置零;
- 高于阈值的元素保留。
这本质上是一种基于阈值的 hard thresholding。
4.3.3 基于 importance score 的稀疏化
若结合 Mini-Splatting 的 importance score,则使用:
def prune_z_metrics_imp_score(self, z, imp_score):
index = int(self.prune_ratio * len(z))
imp_score_sort, _ = torch.sort(imp_score, 0)
imp_score_threshold = imp_score_sort[index-1]
indices = imp_score < imp_score_threshold
z[indices == 1] = 0
return z
这说明 GaussianSpa 不仅能基于 opacity 稀疏化,也能基于重要性得分进行稀疏化。

4.4 对偶变量 u 的作用
在 OptimizingSpa.update() 中,关键更新逻辑如下:
z = self.gaussians.get_opacity + self.u
...
diff = self.gaussians.get_opacity - self.z
self.u += diff
对偶变量 u 用来记录真实 opacity 与稀疏变量 z 之间的偏差。
在后续训练中,这个偏差会持续被修正,从而使真实 Gaussian 表示逐步向稀疏目标靠拢。这个过程具有明显的 ADMM / 增广拉格朗日风格。
4.5 训练流程
4.5.1 前期训练与 densification
从 arguments/__init__.py 可知默认参数为:
iterations = 40000densify_until_iter = 15000simp_iteration1 = 15000optimizing_spa_start_iter = 15200optimizing_spa_stop_iter = 25200optimizing_spa_interval = 50
这说明 GaussianSpa 的整体流程不是一开始就压缩,而是:
- 前期先正常训练并 densify;
- 中期开始逐步简化;
- 后期再做最终稀疏化与微调。
4.5.2 第一次简化
在 train_opacity.py 和 train_imp_score.py 中,到达 simp_iteration1 后,会先计算 importance score:
imp_score = update_imp_score(scene, args, gaussians, pipe, background)
然后根据保留概率采样一部分 Gaussian:
prob = (imp_score+1)/(imp_score+1).sum()
num_sampled = int(N_xyz*(1-opt.prune_ratio1))
indices = np.random.choice(N_xyz, size=num_sampled, p=prob, replace=False)
mask[indices] = True
gaussians.prune_points(mask==False)
其中,prune_ratio1 表示第一次显式剪枝比例,默认值为 0.50。
也就是说,作者会先在中期做一次较粗的剪枝,去掉一部分明显不重要的 Gaussian。
4.5.3 交替优化-稀疏化阶段
在 optimizing_spa_start_iter 之后,训练脚本会初始化 OptimizingSpa,并在每隔 optimizing_spa_interval 次迭代时执行一次更新:
optimizingSpa.update(imp_score)
同时,在这些阶段内,loss 会额外加入稀疏一致性项。
这意味着:
- 普通训练继续进行;
- 稀疏目标被周期性注入优化过程;
- z 和 u 被不断更新;
- Gaussian 表示逐步向更稀疏的状态过渡。
4.5.4 最终 pruning
在 optimizing_spa_stop_iter 时,代码会做最终剪枝。
对于 vanilla 3DGS,train_op.py 中按 opacity 保留 top-k:
opacity = gaussians.get_opacity
k_threshold = int((1-opt.prune_ratio2) * opacity.shape[0])
_, indices = torch.topk(opacity[:, 0], k=k_threshold, largest=True)
mask = torch.ones(opacity.shape[0], dtype=bool)
mask[indices] = False
gaussians.prune_points(mask)
对于 Mini-Splatting 版本,则按 importance score 做最终 pruning。
默认 prune_ratio2 = 0.80,说明第二阶段剪枝更激进,是整个 GaussianSpa 压缩过程的核心步骤。
4.6 importance score 的计算方式
在 update_imp_score() 中,作者会遍历所有训练视角,对每个 Gaussian 累计其多视角贡献:
render_pkg = render_imp(view, gaussians, pipe, background)
accum_weights = render_pkg["accum_weights"]
area_proj = render_pkg["area_proj"]
area_max = render_pkg["area_max"]
然后:
- indoor 场景下,importance 主要由
accum_weights决定; - outdoor 场景下,还会结合
accum_weights / area_proj。
这说明 importance score 反映的是 Gaussian 在多视角渲染中的综合贡献,而不是一个静态经验分数。
05 实验分析
主要分析 SOTA 对比表以及消融实验。
从论文摘要、项目主页和代码仓库公开的信息来看,GaussianSpa 的实验核心目标非常明确:验证该方法是否能够在显著减少 Gaussian 数量的同时,仍保持甚至提升渲染质量。
首先,从论文摘要与项目主页的结论可以看出,GaussianSpa 在 Deep Blending 数据集上的表现最具代表性。作者指出,相比原始 3DGS,GaussianSpa 在 Gaussian 数量减少约 10 倍 的情况下,平均 PSNR 仍提升 0.9 dB。这一结果表明,GaussianSpa 不是单纯依赖牺牲质量来换取压缩率,而是在训练过程中有效去除了冗余 Gaussian,并保留了决定渲染质量的关键表示。
其次,在项目主页给出的多场景可视化对比中,GaussianSpa 在多个场景上都展现出明显的模型压缩能力。例如页面中展示了如下数量级对比:
- Ours:0.29M vs 3DGS:2.32M
- Ours:0.42M vs 3DGS:1.74M
- Ours:0.66M vs 3DGS:5.31M
这些结果说明 GaussianSpa 在不同场景下都能够显著减少 Gaussian 数量,同时保持较好的渲染质量。
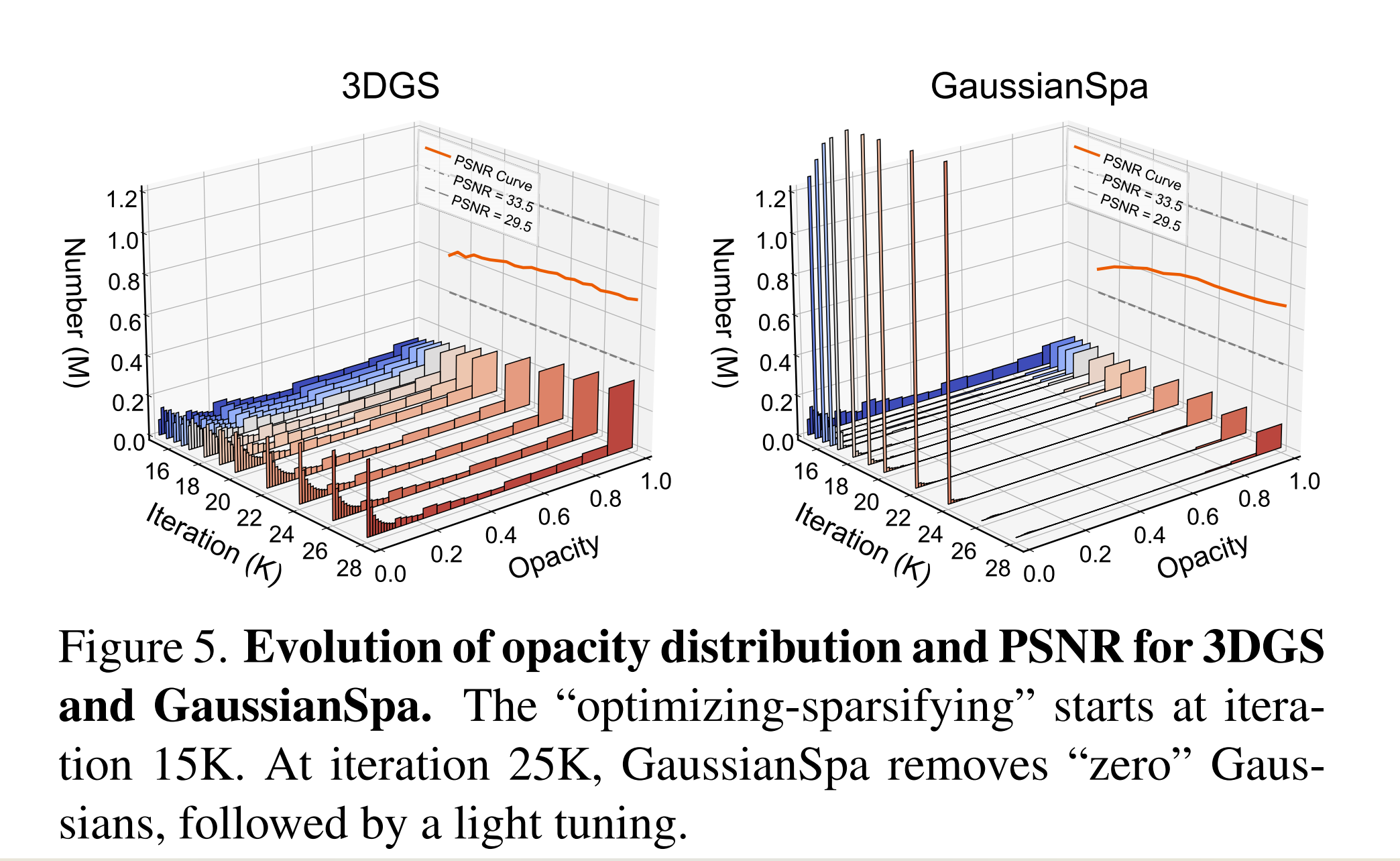
再次,项目主页还展示了 GaussianSpa 与 Mini-Splatting 的可视化结果。作者指出,在相近 Gaussian 数量下,GaussianSpa 对纹理细节的恢复更好。这说明 GaussianSpa 不仅具有较高压缩率,而且在细节保持方面也优于现有紧凑表示方法。
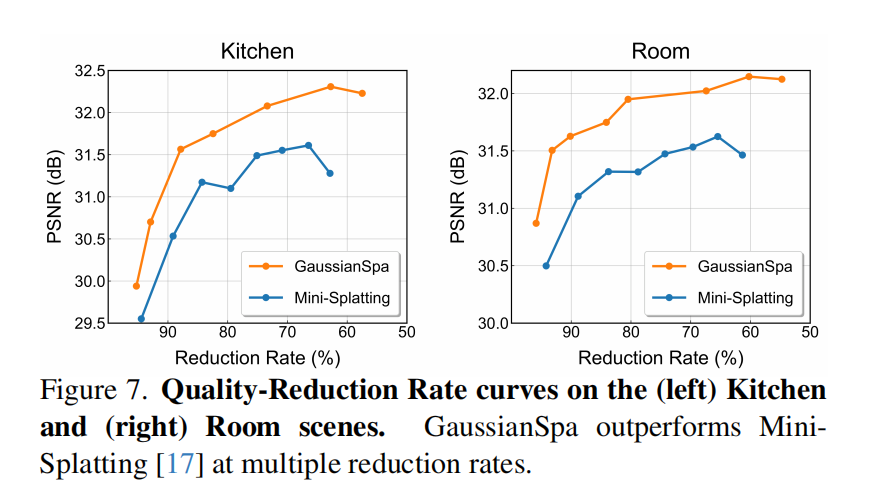
从实验流程来看,GaussianSpa 的压缩不是一次性完成,而是通过三阶段逐步实现:
- 前期正常训练并 densify;
- 在
simp_iteration1做第一次显式简化; - 在
optimizing_spa_start_iter到optimizing_spa_stop_iter之间交替执行优化与稀疏化; - 最终再执行大规模 pruning。
这说明作者默认认为:逐步压缩 比 一次性粗暴裁剪 更有利于维持图像质量,这一点也是本文实验设计的重要思想。
此外,README 中对不同场景给出了不同的推荐 prune_ratio1 和 prune_ratio2。例如 drjohnson、playroom、bonsai、stump 等场景的推荐参数并不完全一致。这说明 GaussianSpa 在不同场景复杂度下需要不同的压缩强度。换言之,虽然该框架具有较强通用性,但在实际应用中仍需要根据场景特点调整剪枝比例。
如果从实验结论上总结,本文主要说明了以下几点:
- GaussianSpa 能显著减少 Gaussian 数量,实现更紧凑的 3DGS 表示。
- 在较高压缩率下,GaussianSpa 仍能保持甚至提升渲染质量。
- 相较 vanilla 3DGS 和 Mini-Splatting,GaussianSpa 在质量-压缩率权衡上更优。
- 基于 opacity 与 importance score 的两种实现方式验证了 GaussianSpa 的通用性。
因此,GaussianSpa 的实验不仅证明了方法“能压缩”,更证明了它能在较高压缩率下维持高质量渲染,这也是本文最核心的价值所在。
06 个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)