HIL-DAFT——双智能体的人类在环RL框架微调的人形VLA(先离线预热后在线交互):为完成螺栓装配,主智能体负责常规操作、精细化执行体依据语音指令实行细粒度调整
前言
- 25年8月,我便在博客中预言到,工厂智能化中,vla与RL结合是绝对主流之一
- 25年11月,π*0.6更把这个趋势推向高峰,后出来了很多在「机械臂乃至轮式人形」上部署vla+offline2online RL(有的还加了触觉),但把这一套部署在双足人形上的,相对少见
本文特此来解读下小米和香港城市大学联合推出的这个HIL-DAFT
第一部分 Dual-Actor Fine-Tuning of VLA Models: A Talk-and-Tweak Human-in-the-Loop Approach
1.1 引言、相关工作、问题设置
1.1.1 引言
如原论文所说,近期的研究进展已经证明,在预训练的语言模型和视觉-语言模型上进行 RL 微调具有显著效果
- 8-Vla-rl
- 9-Flare
- 10-Training language models to follow instructions with human feedback,此即chatgpt的前身instructGPT
然而,要将这些成功经验迁移到现实世界中的机器人 VLA 模型上仍然十分困难,其原因在于样本效率低以及安全性方面的顾虑
为应对这些挑战,将人类引导融入在线学习的人在回路(human-in-the-loop)策略逐渐受到关注
- 11-HIL-SERL
- 12-Conrft
- 13-Rlif
其中,Chen 等人[12] 提出了一个强化微调(Reinforced Fine-Tuning, RFT)框架,将离线阶段与在线阶段相结合,在单任务场景中实现了显著的样本效率。然而,其在多任务设置和长时域操作中的适用性仍未被探索
此外,现有的人类在环 RL 方法通常只依赖物理纠正(例如 SpaceMouse),缺乏一种系统性的方式将这些干预转化为对策略微调具有语义意义的指导
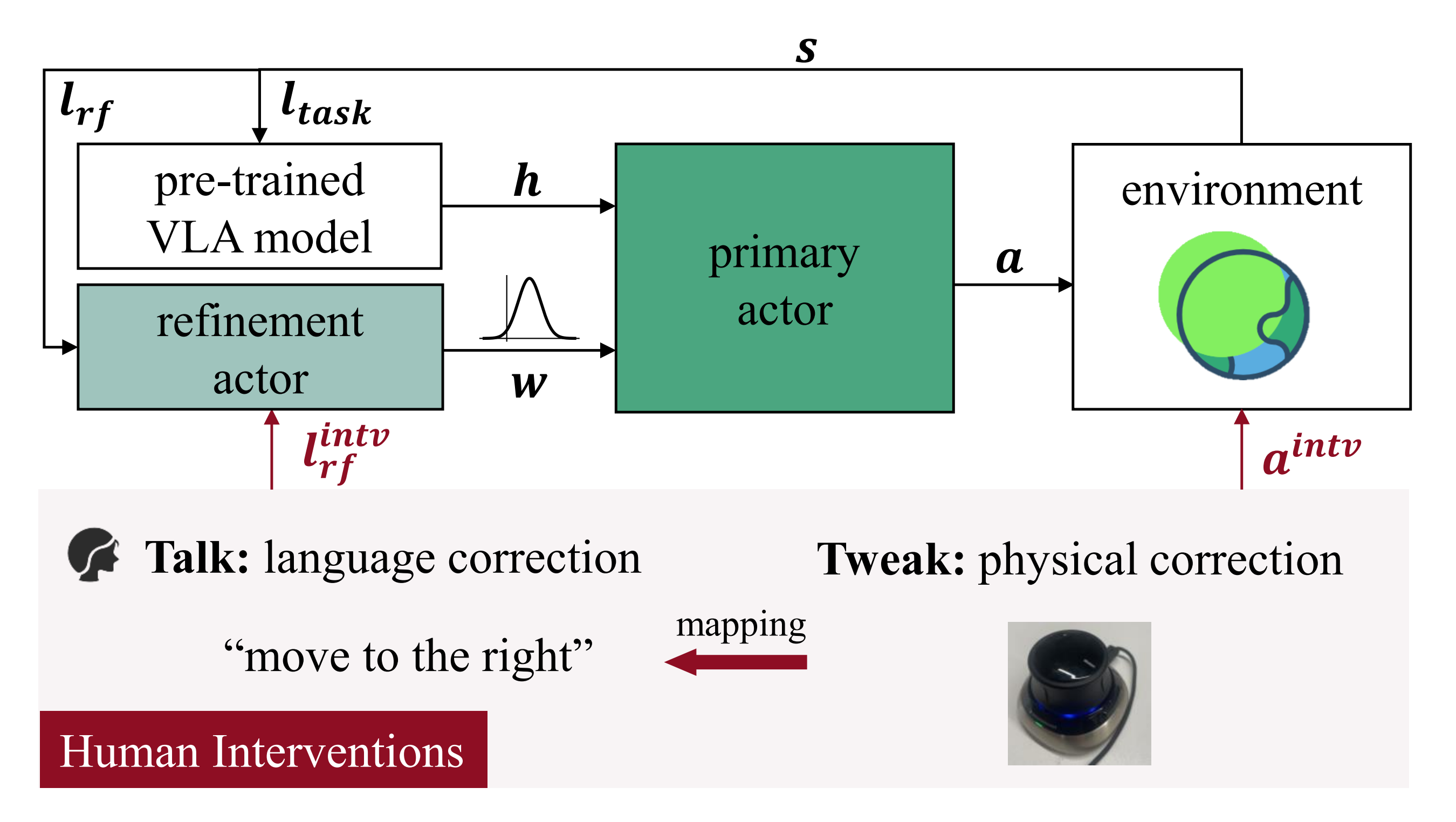
为了解决这些局限性,来自小米和香港城市大学的研究者提出了一种双执行体的人类在环RL框架『人在环双行为体 VLA 微调框架概览。主行为体通过扩散过程生成稳健的多任务动作,而精炼行为体在潜在噪声空间中工作,以提供细粒度的调整。人类干预通过“talk-and-tweak(对话与微调)”机制集成,将物理纠正转换为具有语义依据的精炼指令』
- 其paper地址为:Dual-Actor Fine-Tuning of VLA Models: A Talk-and-Tweak Human-in-the-Loop Approach
其作者包括
Piaopiao Jin1,∗,† , Qi Wang1,∗ , Guokang Sun1 , Ziwen Cai1,2 , Pinjia He2 , and Yangwei You1 - 其项目地址为:sites.google.com/view/hil-daft
具体而言
- 其中,主执行体负责产生任务通用的动作,而精细化执行体在主策略的潜在噪声空间中运行,根据精细化指令对动作进行细粒度调整
————
为实现高效的双智能体学习,作者提出了一种“对话与微调”(talk-and-tweak)干预方案。在常见做法(在 rollout 过程中使用 SpaceMouse 纠正动作)的基础上,作者将这一范式扩展为:把物理纠正映射为自然语言的精细化指令
例如,用SpaceMouse 向右微调会被口头表述为“向右移动”。主行为体利用物理纠正来提升其基线性能,而精细化行为体则学习将语言指令与相应的定向调整建立关联
这样的设计不仅保留了通用操作能力,还实现了精确的、由指令驱动的细粒度调整 - 另,为了检验所提出方法的有效性,作者研究了一个长时域操作任务:机器人必须依次将散落在桌面上的螺栓竖直放置、抓取并进行装配『如下图图 2 所示,三个操作任务的示意图。(a) 将螺栓竖直放置;(b) 拾取螺栓;(c) 将螺栓装配到螺柱上』
最终,该方法在仅经过 101 分钟的在线微调后,就在各个子任务上都达到了 100%的成功率,展现出很强的样本效率
此外,它在超过 12 步的序列上依然保持 50% 的完成率,凸显了其在长时序操作方面的鲁棒性。且作者进一步将该框架扩展到多机器人学习,体现了其灵活性以及在提升样本效率和训练稳定性方面的潜力
1.1.2 相关工作
首先,对于面向大模型的强化微调
其次,对于人在环路的人机协同机器人学习
最后,对于策略适应
1.1.3 问题设置与预备知识
本文研究一项具有挑战性的机器人操作任务,其中机器人需要处理散落在桌面上的螺栓,如图 2 所示
该任务包含三个阶段:
- 通过抓取螺栓的一端将其立起
- 稳定、可靠地拾取螺栓
- 通过将螺栓插入一个部分被遮挡的槽中来完成装配
每个阶段在位置和对齐方面都需要达到毫米级精度
此外,该任务的长时域变体要求机器人在多个螺栓上顺序执行这三个阶段,将它们串联成一系列连续操作
- 作者假设可以访问一个预训练的视觉-语言-动作(VLA)模型
,该模型对RGB 观测、自身运动状态以及任务指令进行编码
- 动作头采用扩散策略[21] 实现,其中动作是通过逐步对高斯噪声去噪生成的
不过,不同于执行多步去噪,作者采用一致性策略[22]-[24],将多步过程蒸馏为一步预测
为了实现高效的多任务泛化和细粒度的适应性,作者采用了一种双智能体学习框架,用于动作生成。在一致性策略中,一个动作是通过对高斯噪声样本进行去噪得到的——定义为公式1:
其中 是控制初始噪声尺度的超参数。由于
的不同采样会导致不同的动作输出,作者设计了两种互补的动作生成模式
令 表示以噪声
为条件的一致性策略
- 在主模式下,
从公式1——
中采样,保持策略的原始行为
- 在细化模式下,噪声则从一个学习到的分布中采样:
其中均值以状态
和精炼语言指令
为条件
通过保留这两种模式,双执行器框架实现了直接的适应性:当给定精炼指令时, 会引导策略朝与该指令一致的行动发展;否则,系统将默认采用由主执行器定义的原始行为
1.2 HIL-DAFT的完整方法论
1.2.1 双行为者强化学习系统
机器人操作任务被表述为一个马尔可夫决策过程(MDP),即如下所示
其中
表示状态空间
表示动作空间
表示转移动力学
表示回报函数
表示初始状态分布
为折扣因子
当环境执行单个动作 时,该双行动者框架提供了两种互补的机制来生成该动作
- 在没有基于语言的细化时,主行动者
通过对高斯噪声去噪来采样候选动作,如Eqn.(1) 所定义
- 当给定细化指令时,
指定的已学习分布的样本进行去噪
双执行者框架通过两个连续的训练阶段进行优化:离线预热阶段和在线交互阶段(图3)
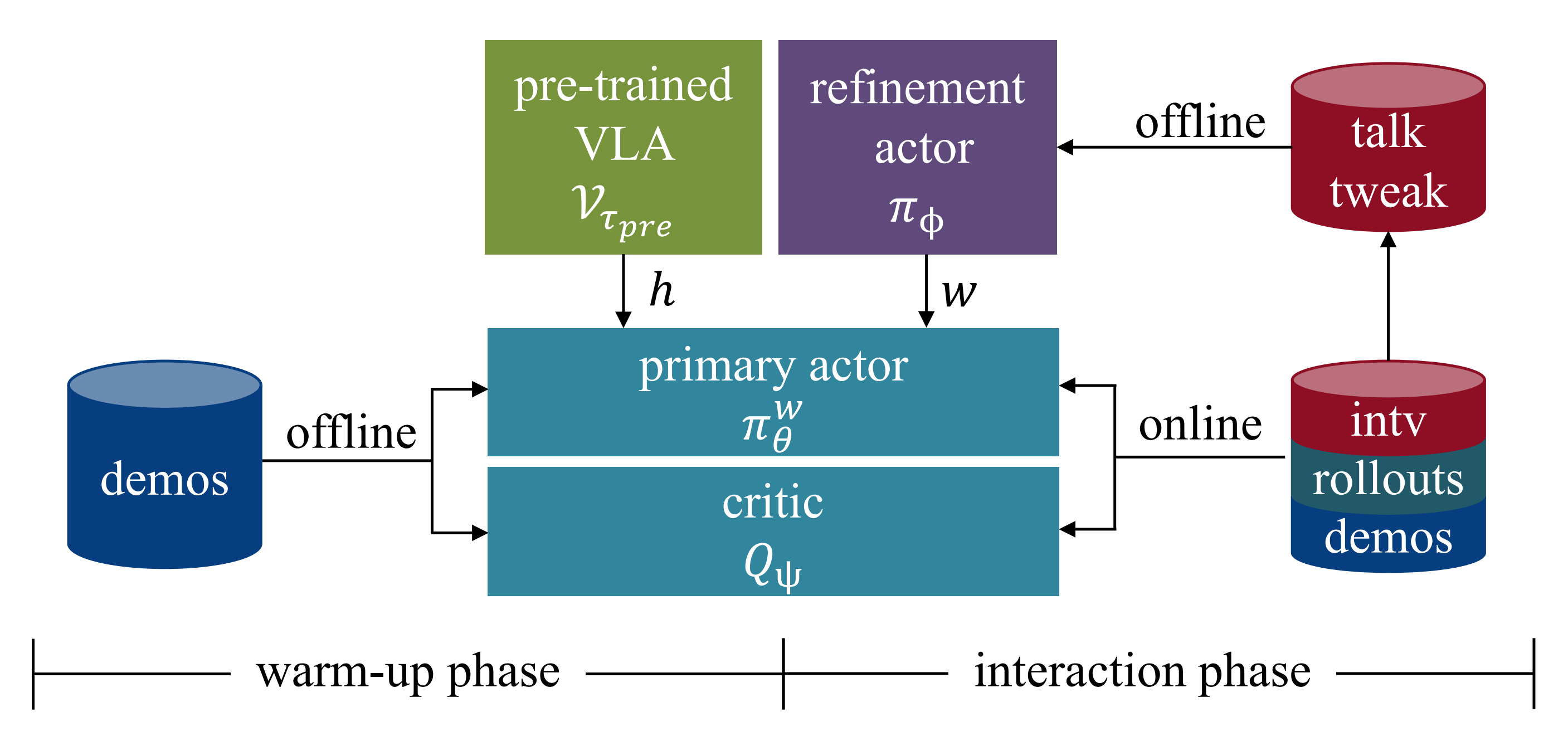
- 在预热阶段,主策略
使用示例数据(demonstration data)进行初始化,以建立稳定的性能基线
- 在在线交互阶段,
与此同时,引入精炼策略,以在潜在空间中实现基于语言条件的自适应
在预热阶段,作者使用一个预训练的视觉-语言-动作(VLA)模型 将任务指令
和状态
(RGB 图像和本体感受输入)编码为任务嵌入
主策略在奖励最大化和行为克隆(BC)的混合目标下进行优化
- 一方面,BC目标引导策略去模仿专家演示
- 另一方面,策略被鼓励去最大化其动作的期望Q 值,其损失函数定义为
训练缓冲区从演示初始化
整体策略损失整合了这两个互补的目标——定义为公式6:
其中λ1 和λ2 是两个目标之间的折中系数
在预热阶段,Q 函数的学习是使用 Calibrated Q-Learning(Cal-QL)[25] 来完成的,遵循了文献[12-即ConRFT] 的工作
这种方法显式地减弱了分布外动作的影响,从而稳定了基于离线数据的策略改进
在在线阶段,机器人直接与物理环境交互以进行持续学习
- 主策略
使用与公式(6)中
相同的损失函数进行优化
而训练数据D 则从示例缓冲区和在线rollout 缓冲区
中等量采样——详见下图的右下角
- 在此阶段,Q 函数损失λ2 的权重被提高,而行为克隆损失λ1 的权重被降低。这种调度方式在在线经验累积的同时提高了训练的稳定性,并确保了有效的奖励最大化
且本阶段中的Q 函数采用标准的Bellman 损失进行优化,而非Cal-QL 变体
精化动作器 使用离线强化学习进行训练
- 在给定状态
- 精化 actor 使用 ResNet [26] 对 RGB 图像进行编码,并使用 T5 模型 [27] 对精化指令进行编码。每个嵌入通过各自的多层感知机(MLP)被投影到统一的维度
这些特征向量随后被拼接,并由最后一个 MLP 处理以生成输出
精炼 actor 使用多个目标进行优化
- 作者首先施加一个 BC 损失,以引导策略朝向示范行为
其中,表示将在Sec. IV-B 中介绍的talk-and-tweak人类干预数据集
- 在此基础上,作者通过引入Q-function最大化项来实现进一步的优化:
- 为了进一步稳定训练,作者引入一个正则项,用于约束细化actor 在没有显式细化指令时与初始策略保持一致
一个固定的语言指令”[null]” 被用来表示没有指令的情况,从而确保模型输入的一致性
最终,整体训练目标将这些组件结合在一起:
其中、
、
是这三个目标之间的权衡系数
1.2.2 有效的“对话与微调”(Talk-and-Tweak)人类干预设计
人为干预被纳入在线学习阶段,以确保交互安全并加速策略收敛。具体而言,当智能体执行不安全或次优动作时,人类监督者可以直接进行干预
由此产生的动作对被存储在干预数据集
中,作为后续策略更新的基础
在此基础上,作者提出了一种“对话与微调”(talk-and-tweak)数据集生成方案。在此方案中,每个物理修正(微调)都通过基于规则的映射与相应的自然语言优化指令(表述)相匹配
人类干预通常跨越多个连续的时间步长。
令表示一系列被干预的动作,其中每个
编码了机器人动作
- 前三个维度表示平移运动
- 接下来的三个维度表示旋转运动
- 最后一个维度则表示夹爪指令
且语言映射仅专注于翻译成分
在时间窗口 J 内的累积位移计算方式为
其中J 表示时间窗口为J = 5 步。对于每个平移轴,如果累积位移超过预定义阈值σ = 0.001 m,则生成相应的细化指令:
其中d ∈(x, y, z) 表示平移轴
最终的精炼指令 是通过将三个平移轴上的指令进行拼接得到的,从而产生诸如” 向右并向前移动” 之类的精炼指令。得到的talk-and-tweak 三元组
取代了标准的干预二元组
,并被加入到用于策略学习的干预缓冲区中
这样的增强将原始的纠正动作转换为具有语义基础的精炼指令,使精炼actor 能够将高层次的语言指导映射到物理动作上
1.2.3 高效的多任务学习
提出了一个多任务学习框架,能够在多样化任务之间实现可扩展且稳定的学习。如图4 所示『该框架将一个共享的 actor 与按任务划分的critics 进行耦合,在保持任务特定价值函数的同时,实现一致的策略学习』
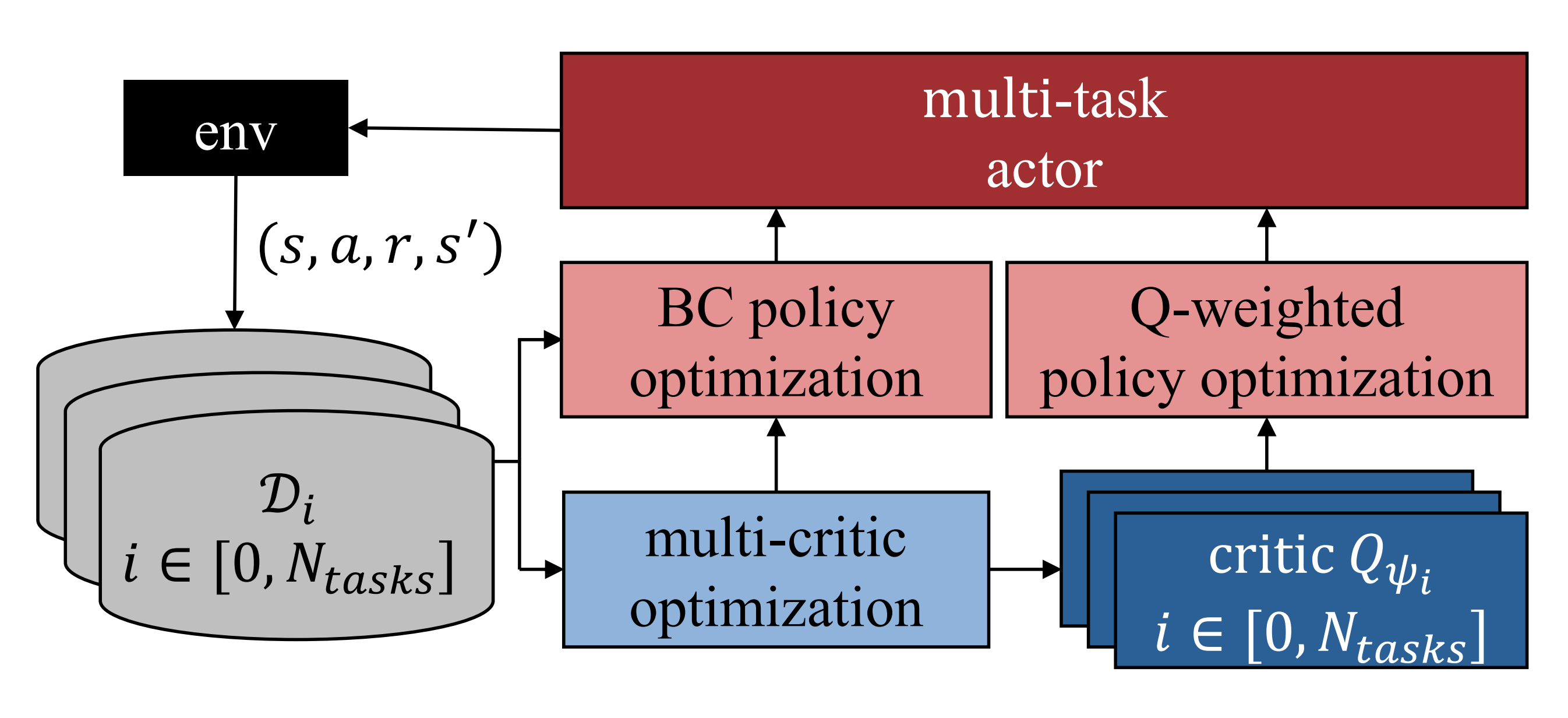
该架构采用共享的多任务actor 和任务特定的critic ,其中
表示任务标识符
具体而言,每个critic 使用ResNet[26] 对RGB 图像进行编码,使用多层感知机(MLP)对本体感知输入进行编码,并使用另一个MLP 对动作a进行编码。得到的特征被拼接后输入到一个MLP 头部,以产生Q 值
为了支持多任务训练,作者扩展了[11] 中提出的任务级回放缓冲机制。具体来说,对于每个任务i ,维护三个独立的缓冲区:专家示例 、策略生成的回合
和人工干预
- 在预热阶段,
仅包含离线示例
- 在随后的在线交互阶段,它会通过来自
的干预数据进行扩充
在交互阶段,主actor 通过在所有任务和缓冲区类型上进行均匀采样来更新,即,这鼓励在示范数据和自主交互之间进行均衡学习
细化actor 则使用聚合的干预数据集
相比之下,每个任务特定的评价器仅使用其对应任务缓冲区中的数据进行更新,从而保证稳定且任务特定的价值估计
详细过程总结于算法1 中

为方便大家更好的理解上述算法1,我还是给大家逐行解读下
0. 准备与初始化 (Require & Line 1)
输入依赖 (Require):
一个预训练的视觉-语言-动作(VLA)模型
基于一致性模型(consistency policy)的策略头
每个任务独立的 Critic 模型
各类数据缓冲区:专家示范数据
、在线滚动探索数据
、人类干预数据
,以及全局的 talk-tweak 语料库
第 1 行: 随机初始化网络参数
Phase I: 离线预热阶段 (Offline Warm-up phase, Lines 2-8)
本质:利用现有的少量完美演示数据,给模型打下基础,防止在线探索时发生灾难性的乱动。 * 第 2-8 行: 开启离线训练循环
第 3-6 行: 遍历每一个任务
。从该任务的示范数据集
中采样一个大小为
的小批量数据
。然后用这些数据更新该任务专属的 Critic 模型
第 7 行: 将所有任务的采样数据
聚合起来,更新全局共享的主策略
Phase II: 在线交互阶段 (Online interaction phase, Lines 9-30)
本质:让机器人真机下场试错。为了保证效率,这一阶段采用了多线程并发结构,分为学习线程(Learning Thread)和交互线程(Interaction Thread)
A. 学习线程 (Learning Thread, Lines 9-17) - 负责后台大脑更新
第 9 行: 等待每个任务的探索缓冲池
至少收集到 100 条转移数据(transitions),以保证训练稳定
第 10-14 行: 开启在线训练循环 。遍历所有任务
)的数据组合成当前任务的批次
第 15 行: 汇总所有任务的混合数据
第 16 行: 核心创新点体现。使用全局的
数据集来专门更新微调策略
B. 交互线程 (Interaction Thread, Lines 18-30) - 负责前台执行与数据收集
第 18-20 行: 遍历任务并在环境中执行步数
第 21-22 行: 如果人类没有进行干预,则模型按照当前的主策略
输出动作 。产生的轨迹
存入常规探索库
第 23-24 行: 如果此时人类介入(比如用 SpaceMouse 强行矫正了机器人的动作),则记录下人类修正后的动作
。这段被纠正的轨迹存入特定任务的干预库
第 28-29 行 (位于循环尾部的数据增强): 将刚刚收集到的人类干预数据
融合进全局的语言-调整库
这意味着人类每一次接管,既让主模型多了一次正确示范,也让微调模型多了一次“将物理调整翻译为语言”的学习素材
// 待更

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)