OmniVideo-R1:利用查询意图和模态注意强化视听推理
26年2月来自清华、腾讯、湖南大学、新加坡国立、西交大和香港中文大学的论文“OmniVideo-R1: Reinforcing Audio-visual Reasoning with Query Intention and Modality Attention”。
人类通过多种模态感知世界,这些模态协同运作,从而形成对周围环境的整体理解。然而,现有的全视频模型在视听理解任务上仍然面临诸多挑战。本文提出一种名为 OmniVideo-R1 的强化框架,旨在提升混合模态推理能力。OmniVideo-R1 通过两种关键策略赋予模型“利用全模态线索进行思考”的能力:(1) 基于自监督学习范式查询-密集落地;(2) 基于对比学习范式的模态注意融合。
强化学习(Christiano et al., 2017)已成为一种显著提升大语言模型鲁棒性和事实准确性的有效方法(Ouyang et al., 2022)。在实践中,策略模型训练通常采用离策略学习设置来提高样本效率。然而,对于混合专家(MoE)模型(例如,Qwen3-Omni-30B-A3B (Xu et al., 2025c)),不同专家的激活会导致token分布发生显著变化。在这种情况下,token-级重要性采样通常会在训练梯度中引入高方差噪声,这种噪声会在长序列中累积,并被裁剪机制进一步加剧。为此,本文方法直接在序列-级进行优化,遵循组序列策略优化(GSPO)算法(Zheng et al., 2025)提出的公式。
如图所示,OmniVideo-R1 采用 GSPO 算法优化整个推理过程,使模型能够提取与意图相关的线索,并在整个推理过程中有效地整合音视频信息。该模型行为的形成经历两个训练阶段。首先,引导模型发展查询密集型推理行为;然后,进一步训练模型以逻辑一致的方式整合多种模态。在第一阶段(QI),模型使用基于推理轨迹中生成的多个上下文和描述对的自监督目标进行训练。在第二阶段(MA),首先解耦模态特定的输入,然后对它们进行对比学习,从而促进深度融合的理解。值得注意的是,在整个训练流程中,OmniVideo-R1 不依赖任何显式的流程级标注来进行查询密集型上下文或模态融合。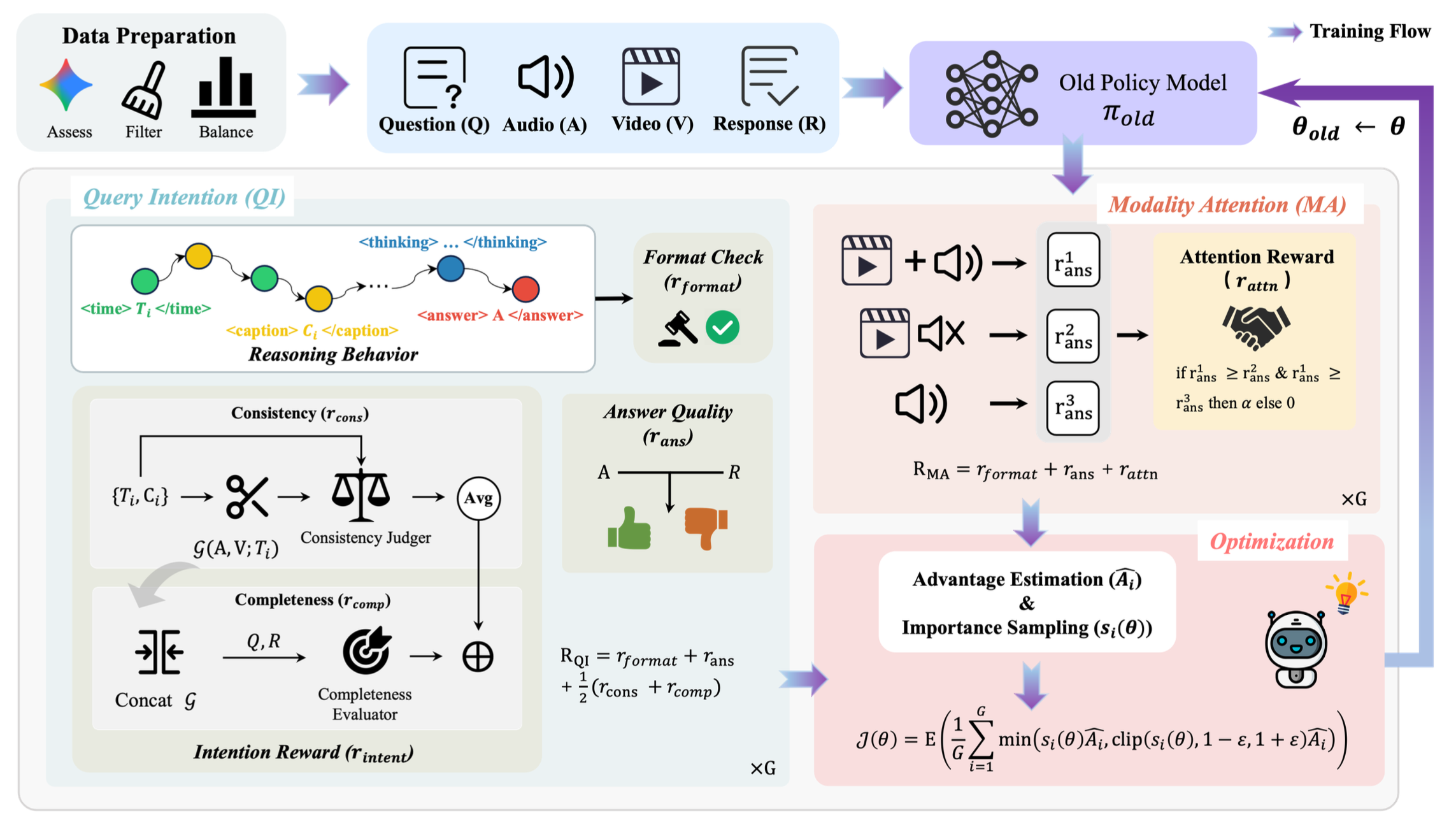
如图展示推理过程与 Qwen3-Omni-30B-A3B 的比较。OmniVideo-R1 赋予模型“利用全模态线索思考”的能力,即执行查询密集型基础分析,识别关键线索,从而实现更准确、更可靠的推理,得出最终答案。
数据准备
首先从 LLaVA-Video (Zhang et al., 2024) 和 Video-Vista (Li et al., 2024b) 收集原始数据,并进行结构验证以去除存在元数据问题(例如,无声视频)的样本。为了进一步过滤掉与多模态设置不符的低质量样本,应用如图所示的三阶段优化流程,该流程包括:(i) 质量评估,(ii) 启发式过滤,以及 (iii) 类别均衡。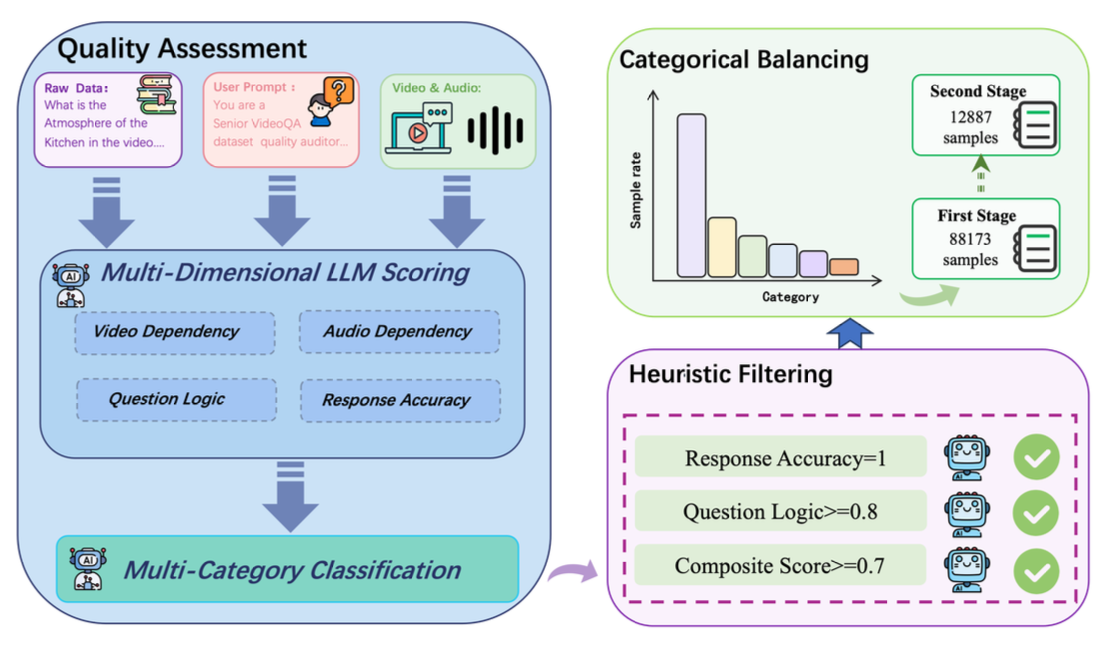
为了更清晰地展示处理后数据的分布情况,所得训练数据集的描述性统计数据如图所示。也就是说,数据集包含 16 个类别,每个类别的样本数量各不相同,从 35 到 34598 不等。包含音频和视频的问题质量很高,内容也十分丰富多样。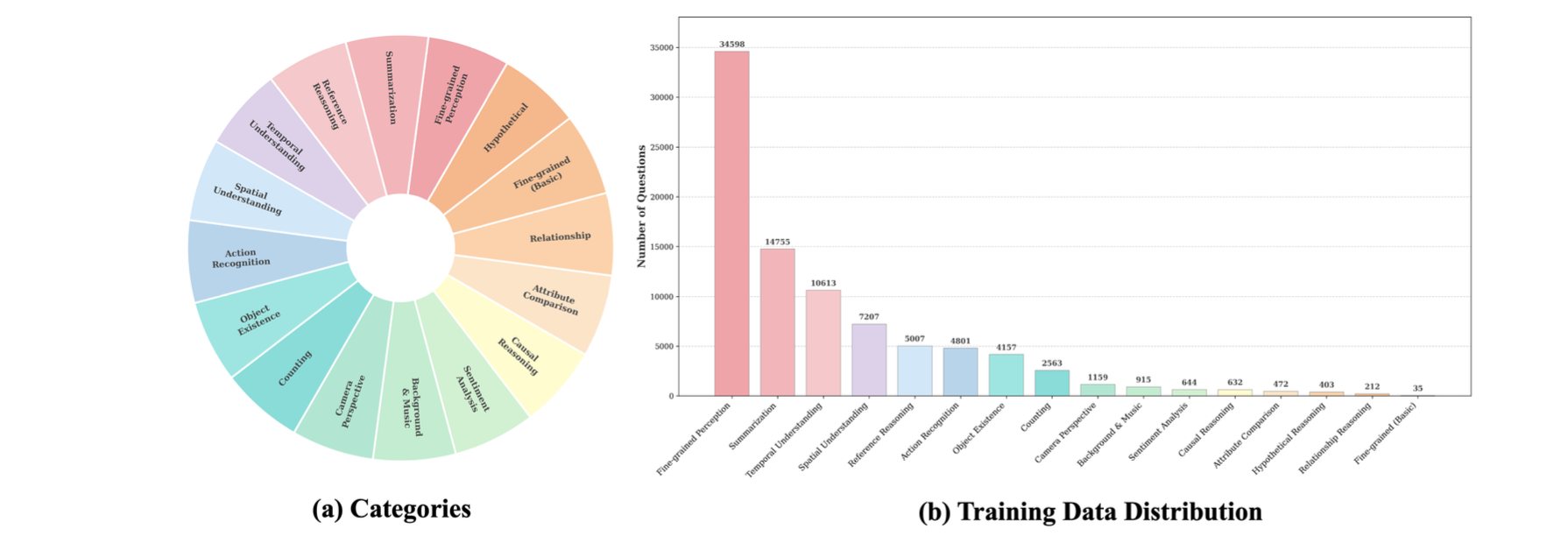
查询密集型接地(QI)
查询密集型接地操作,旨在帮助模型识别视频序列中包含关键视听线索的关键帧(Wang et al., 2025c)。然而,人工标注提示相关的关键帧通常既复杂又耗时。为了解决这个问题,提出一种接地方法,该方法在不依赖任何密集标注的情况下,建立接地和字幕之间的对应关系,从而实现模型程序行为的自监督学习。
具体来说,给定一个问题和相应的视听内容(Q, A, V),鼓励模型以结构化的格式 … … … …生成输出。严格符合此输出模板的响应将获得奖励r_format = 1.0。对于每次部署,将生成的多个时间-描述对表示为{T_1,C_1,T_2,C_2,…,T_N,C_N}。然后,通过评估每个T_i和C_i之间的一致性奖励 r_cons 来进行自监督学习。
一方面,通过强制执行每个时间-描述对的正确性来进行自监督学习。另一方面,也要求标注准确,即它应该(i)以最小且有效的方式覆盖所有与意图相关的真实线索 T_gt,以及(ii)避免冗余预测。
然而,本文旨在解决没有真实值 T_gt 的难题,并提出一种软近似方法来求解。具体而言,首先裁剪所有预测片段,然后将它们连接成一个序列,并从内容完整性和精确度两个维度对其进行评估。换句话说,评估这些片段中包含的视听信息是否充分且准确,足以支持从问题 Q 到最终答案 R 的推理过程。即定义一个完整的奖励值 r_comp。
同时,也利用结果信号,如 (Guo et al., 2025) 所述。具体来说,对最终答案的质量进行软评估,并赋予其一个连续分数 r_ans。最后,在 QI 训练阶段的奖励定义为:
R_QI = r_format + r_ans + (r_cons + r_comp)/2.
从三个互补的角度建立一个统一的训练框架:(i) 全局格式正则化 r_format,(ii) 基于结果的约束 r_ans,以及 (iii) 过程级自监督 r_intent = ( r_cons + r_comp)/2。在此训练设计下,模型有望推断潜意图,提取与任务相关的线索,并对这些视听内容进行推理。
模态注意融合(MA)
由于 QI 阶段主要以视觉为中心进行评估,因此仅依赖查询密集型的接地机制仍然无法使模型捕捉到细微但关键的声音线索。这种无法利用音频线索的情况进一步导致大量冗余输出。为了解决这个问题,提出一种模态注意融合方案,其核心思想是鼓励模型充分利用并协同整合音频和视觉信息,以提高准确率。
具体而言,对于每个输入 x,比较模型在三种展开设置下的性能:(i)音频-视觉组合输入;(ii)仅无声视频输入;以及(iii)仅音频输入。对于一个理想的多模态理解模型而言,其在完整多模态输入下的性能不应逊于任何单模态输入下的性能,尤其是在需要同时利用声学和视觉线索才能正确回答问题的数据集上。这种对比式方法明确鼓励模型在有效融合音频和视觉信息时取得更优异的性能,而不是主要依赖单一模态。
基于对比式学习策略,多模态训练阶段专注于提升模型在特定数据子集中的能力,该子集尤其需要整合的音视频理解。此阶段旨在将推理范式从查询密集型的基础推理推进到更深层次的多模态理解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)