AIGC检测的底层逻辑:为什么你的论文会被判为AI生成
AIGC检测的底层逻辑:为什么你的论文会被判为AI生成
“明明自己一个字一个字敲的,为什么AIGC检测报告显示AI率38%?”
这是许多2026届毕业生在首次使用AI检测工具后的真实困惑。也有反过来的情况——某些大段使用AI生成的内容,检测结果却显示正常。AI检测系统到底在用什么逻辑判断一篇论文是不是AI写的?
这篇文章不讲表面的应对技巧,而是带你从底层原理出发,真正理解AIGC检测系统是怎么"思考"的。搞懂了这一层,你才能对症下药。
一、AI检测系统在"看"什么?
很多同学以为AIGC检测就是把你的论文和AI生成的内容做"比对"——类似查重。但事实上,AIGC检测和传统查重是完全不同的技术路径。
1.1 传统查重 vs AIGC检测
| 对比维度 | 传统查重 | AIGC检测 |
|---|---|---|
| 核心原理 | 文本相似度匹配 | 文本生成模式识别 |
| 比对对象 | 已有文献数据库 | AI语言模型的统计特征 |
| 判断依据 | “你的文字和谁的一样” | “你的文字像不像机器写的” |
| 误判原因 | 引用未标注 | 写作风格过于"规范" |
AIGC检测系统本质上是在做一件事:判断一段文本更像是人写的还是机器生成的。它不需要找到你"抄"了谁,而是分析你的文字本身是否具有AI生成的统计特征。
1.2 检测系统的四个核心分析维度
目前主流的AIGC检测系统(包括知网、维普、万方的AI检测模块)主要从以下四个维度分析文本:
第一维度:词汇选择的可预测性
AI语言模型的工作原理是"预测下一个最可能的词"。这意味着AI生成的文本在词汇选择上往往偏向"安全"和"常见"的搭配。检测系统会计算一段文本中每个词出现的"意外程度"——如果一篇文章中几乎每个词都是"最可能的选择",那它被AI生成的概率就很高。
人类写作不同。我们会使用一些不那么"标准"的表达方式、口语化的转折、甚至偶尔出现的用词不当——这些"不完美"反而是人类写作的标志。
第二维度:句式结构的均匀度
打开一篇AI生成的论文,你会发现一个微妙的规律:句子长度的分布非常均匀。大多数句子在15-25个字之间,很少出现特别短(3-5字)或特别长(50字以上)的句子。
人类写作则不同。我们会在强调某个观点时用一个很短的句子,在展开复杂论述时写出一个长句,这种句式长度的"波动"是人类写作自然产生的节奏感。
第三维度:语义连贯模式
AI在组织段落时有一个典型特征:每个段落都是一个相对独立的"信息块",段落之间的过渡往往依赖一些模板化的连接词(“此外”、“与此同时”、"值得注意的是"等)。
而人类在写论文时,段落之间的逻辑过渡更加多样——有时是通过反驳前一段的某个观点来引出新段落,有时是通过提出一个新问题来实现转折,这种过渡方式的多样性很难被AI完美模拟。
第四维度:信息密度分布
这是近两年检测系统重点强化的一个维度。AI生成的文本有一个特点:信息密度在全文中分布非常均匀。每个段落承载的"有效信息量"差不多。
人类论文不是这样的。引言部分信息密度相对低,文献综述部分信息密度急剧升高,方法论部分可能细节很多但推进缓慢,结论部分又会变得精炼——这种信息密度的"高低起伏"本身就是人类写作的特征。
二、为什么"自己写的"也会被判高AI率?
理解了上面四个维度,你就能理解为什么有些确实是自己写的论文也会被标记为高AI率。

2.1 高频被误判的写作习惯
以下几种写作习惯容易触发AIGC检测系统的"警报":
习惯一:过度追求"学术味"
有些同学在写论文时会刻意使用非常正式的表达,每句话都很工整、逻辑严密。这种"完美的学术写作"反而与AI生成文本的特征高度吻合。不是说你不该写得规范,而是过于追求"标准化表达"会让文本失去个人特色。
习惯二:大量使用"万能连接词"
“首先…其次…再次…最后…” 这种层层递进的写法在AI文本中非常常见。如果你全文都在使用这类模板化的逻辑结构,检测系统会认为你的文本更像AI输出。
习惯三:每段都是"论点+解释+例子"的三段式
这是很多写作课教的标准段落结构,但恰好也是AI最擅长的输出模式。当你的每个段落都严格遵循这个模式时,段落结构的"可预测性"就非常高。
习惯四:引用大量AI处理过的二手资料
如果你参考的文献本身已经被AI翻译或改写过,你在引用、转述这些内容时,就可能继承了其中的AI语言特征。这种"间接传染"是很多同学没有意识到的。
2.2 学科差异导致的不公平
值得特别指出的是,不同学科的论文在AIGC检测中面临的处境是不同的:
- 理工科论文:包含大量公式、数据表格和实验描述,这些内容不太容易被标记为AI生成,通常AI率偏低
- 人文社科论文:以文字论述为主,写作风格对检测结果影响巨大,更容易出现高AI率
- 管理学、教育学论文:这类论文的"学术套话"本来就多,和AI的输出特征重叠度高,是误判的重灾区
三、检测系统的技术局限性
AIGC检测并非万能的,了解它的局限有助于你理性看待检测结果。
3.1 概率判断而非确定性判断
所有AIGC检测系统给出的结果本质上都是一个概率值,而非确定性的"是/否"判断。当报告显示AI率40%时,它的实际含义是:基于当前的检测模型,这段文本有40%的特征与AI生成文本相似。
这意味着:
- 检测结果会随着检测系统的版本更新而变化
- 同一篇论文在不同检测平台上可能得到不同的AI率
- 存在一定的误判空间,且无法完全消除
3.2 对混合写作的判断困难
当一篇论文中部分内容是自己写的、部分是AI辅助的、部分是从其他文献改写的,检测系统要准确区分这三类内容是非常困难的。目前的技术水平还做不到精确到每句话的AI归属判定。
3.3 "改写"与"原创"的模糊边界
如果你用自己的理解重新表述了一个AI给你的观点,这到底算AI生成还是人类原创?在语言层面上,重新表述已经改变了文本的统计特征,但如果你的改写方式仍然保留了AI式的表达习惯,检测系统可能还是会标记它。
四、知道原理后,怎么有效降低AI率?
理解了检测的底层逻辑,应对策略就变得清晰了——你需要做的是让你的文本在上述四个维度上更接近"人类写作"的统计分布。
4.1 自主优化的方向
- 打破句式均匀性:有意识地穿插长短句,在关键论点处使用短促有力的表达
- 增加信息密度波动:有的段落可以信息量很大,有的段落可以慢下来做情境铺垫
- 减少模板化连接词:用具体的逻辑关系替代泛化的连接词
- 加入个人化表达:描述你的研究动机、实验中遇到的困难、数据让你意外的地方
4.2 专业工具的技术路径
如果时间紧张或自行修改后AI率仍然偏高,专业的降AI工具能帮你解决问题。但需要注意,只有针对检测底层逻辑做了技术适配的工具才真正有效。
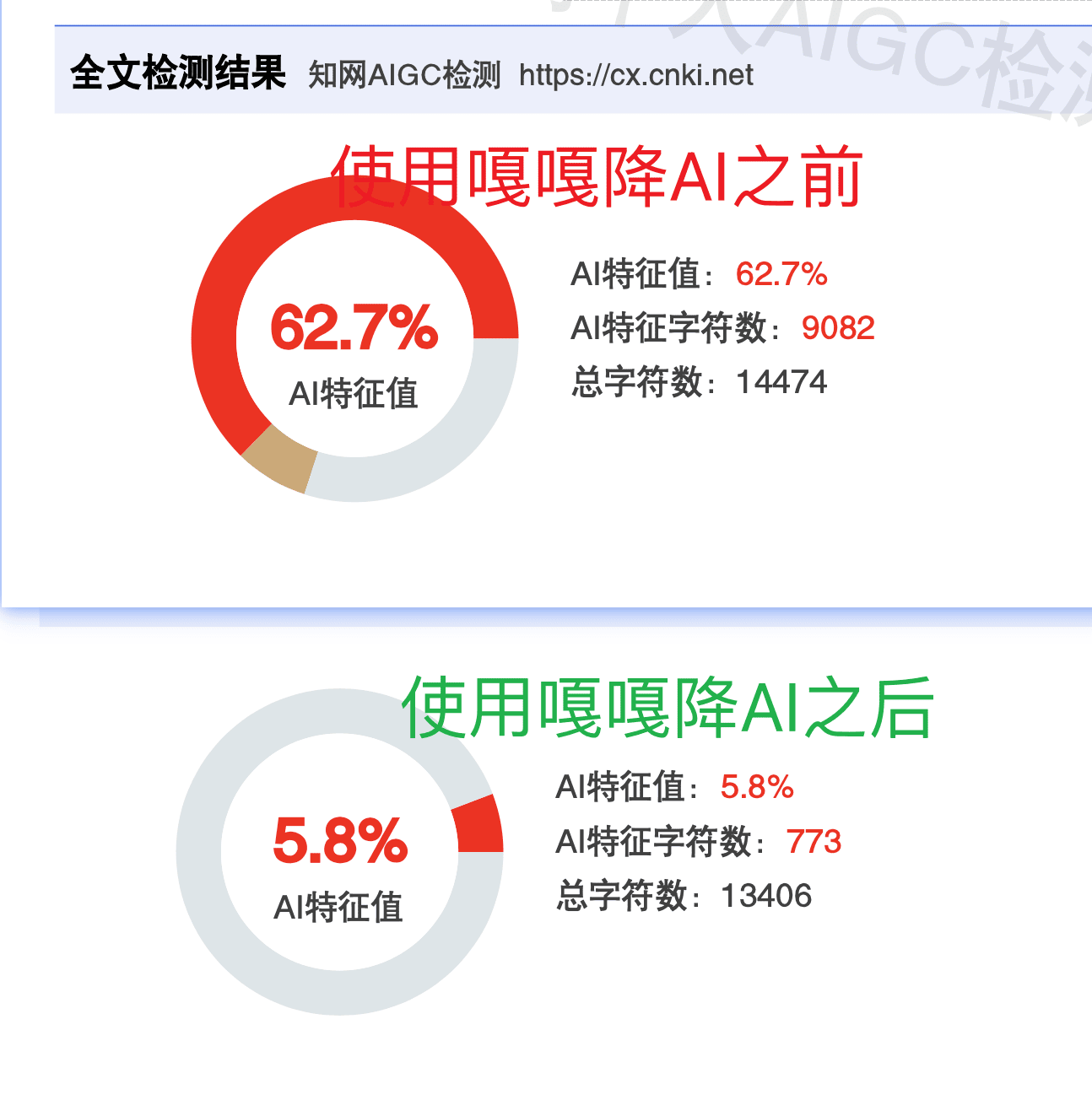
嘎嘎降AI(aigcleaner.com)的技术路径就是针对上面四个检测维度做逆向优化的。它的"语义同位素分析"会识别文本中哪些特征被检测系统标记为AI痕迹,然后通过"风格迁移网络"对这些特征进行深层改写——不是简单地换几个词,而是调整句式节奏、信息密度分布、段落过渡方式等深层特征。实测效果相当突出:知网AI率从99.5%降至3.8%,99.26%的达标率,支持知网、维普、万方等9大平台检测。价格是4.8元/千字,新用户可以免费试1000字。
比话降AI(bihuapass.com)走的是专精路线,它的Pallas NeuroClean 2.0引擎专门针对知网AIGC检测做了深度适配。如果你的论文只需要过知网这一关,比话是一个精准的选择。99%达标率,不达标全额退款,8元/千字,500字免费体验。
率零(0ailv.com)的DeepHelix引擎走深度语义重构路线,能把AI率压到5%以下,价格只要3.2元/千字,适合预算有限但又需要有效降AI的同学。已经处理超过50万篇文档,1000字免费体验,未达标可退款。
五、一个更深层的问题
AIGC检测技术在快速进步,但它本质上是在用AI来检测AI。这场技术博弈不会有终点。
作为毕业生,真正需要思考的不是"怎么骗过检测系统",而是"如何让AI成为你写作能力的放大器而非替代品"。理解检测的底层逻辑,不是为了钻空子,而是为了在合理使用AI辅助的前提下,确保你的论文能真实反映你的学术思考。
检测系统在判断文本是否"像人写的"——那么最好的应对方式,就是让你的论文确实包含只有你才能写出来的内容:你的研究问题、你的分析视角、你的实验发现、你的独立思考。这些东西,是任何检测系统都不会标记为AI生成的。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献936条内容
已为社区贡献936条内容

所有评论(0)