2026年知网AIGC检测最新动态:算法又升级了什么?
2026年知网AIGC检测最新动态:算法又升级了什么?
如果你是2026届的毕业生,最近可能听到了一个让人不太安心的消息——知网的AIGC检测系统又升级了。从2024年知网首次推出AI检测功能到现在,这套系统已经经历了多次迭代,每一次升级都意味着检测能力的进一步增强。那么这一次,到底升级了什么?对正在写论文的你又意味着什么?
这篇文章会从技术层面拆解本次升级的核心变化,帮你搞清楚知网检测的底层逻辑发生了怎样的演进。

一、回顾:知网AIGC检测系统的演进路径
要理解这次升级改了什么,先得回头看看知网的AI检测走过了怎样的路。
1.1 初代检测(2024年上半年)
知网最早的AIGC检测模块基于文本困惑度(Perplexity)和突发度(Burstiness)两个核心指标。简单来说:
- 困惑度衡量一段文字是否"太顺了"——AI生成的内容往往过于流畅、缺少人类写作中的信息密度波动
- 突发度衡量句式和用词的多样性——AI倾向于保持稳定的句式结构,而人类写作会有明显的风格起伏
这个阶段的检测有一定效果,但误判率偏高,尤其对于写作功底好、行文流畅的同学容易出现"误伤"。
1.2 AMLC-III时期(2024年下半年至2025年)
知网在2024年下半年推出了AMLC-III(Academic Misconduct Literature Check 第三代),AI检测能力有了质的飞跃:
- 引入了大规模语言模型特征库,能识别主流AI工具(ChatGPT、文心一言、通义千问等)的生成特征
- 增加了段落级和篇章级的双层检测机制
- 引入语义连贯性分析,检测论文各段落之间的逻辑过渡是否呈现"机械拼接"特征
1.3 2026年新版本:AMLC-IV的到来
今年初,知网正式上线了第四代检测引擎。这也正是本文要重点分析的部分。
二、2026年知网AIGC检测的核心升级点

根据目前能获取到的技术文档和高校内部通知,AMLC-IV在以下几个维度做了重要改进:
2.1 跨模型指纹识别
过去的检测主要针对几个主流大模型的输出特征做比对。新版本的关键升级在于引入了"跨模型指纹识别"机制:
- 不再依赖特定模型的"签名"特征,而是提取AI生成文本的通用模式
- 即使使用小众模型(如开源的Llama、Mixtral等)生成内容,检测系统也能从文本的统计分布中发现异常
- 对经过"改写"处理的AI文本,检测敏感度显著提升
这意味着什么? 过去有同学用小众AI工具写论文来"绕过"检测,这条路在2026年基本行不通了。
2.2 深层语义一致性检测
这是本次升级中技术含量最高的部分。新版检测引入了"深层语义一致性分析"模块:
| 检测维度 | 说明 | 针对的问题 |
|---|---|---|
| 论点-论据匹配度 | 检测论证过程中论点与支撑材料的逻辑紧密程度 | AI生成的内容常出现"论据堆砌但逻辑薄弱" |
| 术语使用连贯性 | 分析专业术语在全文中的使用是否前后一致 | AI有时会在同一篇文章中对同一概念使用不同表述 |
| 认知深度梯度 | 评估论文从引入到深入的认知递进是否自然 | AI倾向于在每个段落保持相同的分析深度 |
| 个人经验痕迹 | 检测是否包含研究过程中的具体经历描述 | AI很难生成真实的研究体验 |
2.3 混合写作比例识别
2026版本还有一个重要变化——它不再只给出"是/否"的二元判断,而是能够估算一篇论文中AI参与的比例区间。
比如检测报告可能会显示:“本文AIGC疑似比例为35%-45%,集中在第二章第三节和第四章第一节。”
这种精细化的检测方式让"部分用AI、部分自己写"的策略也变得有风险——即使整体AI率不高,某些段落被标记为高AI疑似,导师在评审时同样可能提出质疑。
2.4 多语种和翻译检测增强
针对"先用AI写英文再翻译成中文"这种常见的绕检方式,新版本加入了翻译腔识别模块:
- 识别中文文本中的英语思维模式(如从句嵌套过深、被动语态频率异常)
- 检测翻译工具产出的典型句式结构
- 对中英文混合论文的AI检测做了专门优化
三、升级后的实际影响:数据说话
从已经使用新版本检测系统的高校反馈来看,升级带来的变化是显著的:
- AI文本检出率:从AMLC-III的约78%提升到AMLC-IV的约89%
- 误判率:从12%左右降低到7%以下
- 二次改写文本的检出率:从45%提升到约68%——这个数据意味着简单的同义词替换已经很难骗过新系统
对于毕业生来说,有几个直接影响需要注意:
- 检测阈值普遍收紧:部分高校已经将AIGC率的合格线从30%调整到20%甚至更低
- 复检频率增加:一些学校开始在答辩前进行二次AI检测
- 段落级追溯:新版报告会具体标注哪些段落的AI疑似度最高,导师可以有针对性地提问
四、面对升级,毕业生该怎么应对?
算法越来越强,但这并不意味着用了AI辅助就"完蛋了"。关键在于用对方法。
4.1 写作阶段的建议
- 用AI做思路拓展而非直接生成正文:让AI帮你列大纲、梳理文献脉络,但具体论述用自己的语言完成
- 注入个人研究经历:在方法论和讨论部分加入你自己的实验过程、遇到的问题等真实体验
- 控制每次AI辅助的文本量:不要整段整段地使用AI输出,而是把它当作"素材"来改写
4.2 完稿后的降AI处理
如果论文已经写完,检测发现AI率偏高,这时候就需要专业的降AI工具来帮忙了。但这里要特别注意——不是所有降AI工具都能应对知网2026年的新算法。
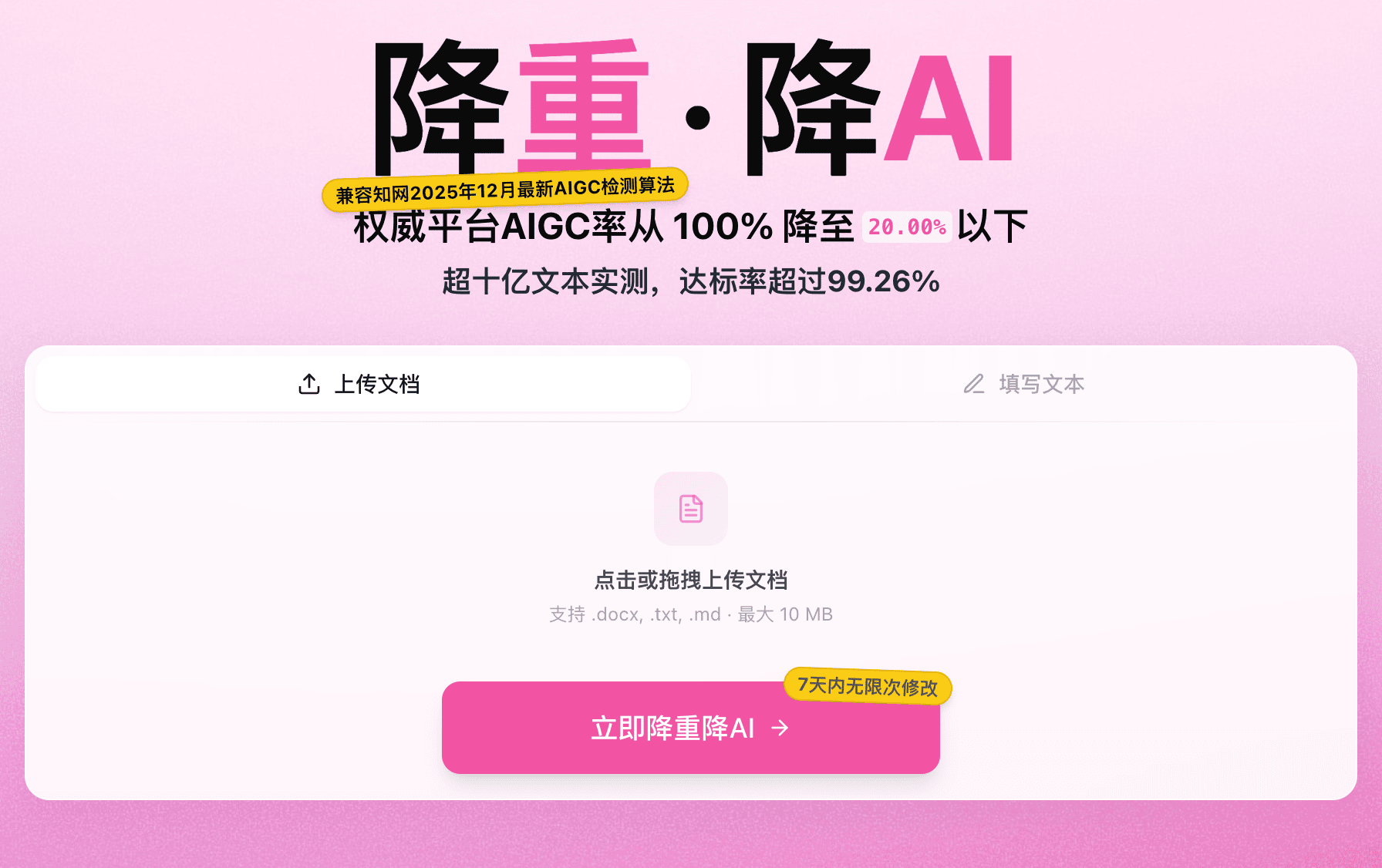
嘎嘎降AI(aigcleaner.com)是目前市面上针对知网新版检测做了专门适配的工具。它采用"语义同位素分析+风格迁移网络"的双引擎架构,不只是做表面的同义词替换,而是对文本的语义结构进行深层重构。在知网AMLC-IV环境下的实测数据显示,99.26%的处理文档能通过检测,知网AI率从99.5%降至3.8%。新用户可以免费体验1000字,处理价格为4.8元/千字。
如果你的论文是专门针对知网提交的,也可以看看比话降AI(bihuapass.com)。它的Pallas NeuroClean 2.0引擎专攻知网AIGC检测,达标率99%,知网AI率控制在15%以下,价格8元/千字,新用户500字免费。不达标承诺全额退款。
预算有限的同学可以考虑率零(0ailv.com),3.2元/千字的价格是三者中最低的,新用户同样有1000字免费额度。它的DeepHelix深度语义重构引擎能把AI率降到5%以下,已经处理了超过50万篇文档。
五、一个值得关注的趋势:检测与反检测的"军备竞赛"
知网每一次升级,本质上都是在和AI写作工具、降AI工具进行技术博弈。从行业发展来看,这场博弈会持续下去:
- 检测端会继续提升对深度改写文本的识别能力
- 降AI工具则会从"表层替换"转向"深层重构"
- 最终的平衡点可能是:检测系统不再追求100%识别AI文本,而是建立一个"合理使用"的判定框架
对毕业生来说,最务实的做法是:
- 以自主写作为主,AI辅助为辅
- 使用与最新检测系统适配的降AI工具做最终处理
- 在提交前自行做一次检测预查,确保数据达标
- 关注学校发布的最新AIGC检测标准和处理政策
知网的算法还会继续升级,但只要你理解了它的检测逻辑,就能找到合理合规的应对方式。毕竟,检测系统的目标不是阻止你使用任何AI工具,而是确保论文中有你自己的真实思考。把握住这个核心原则,无论算法怎么变,你都能从容应对。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献664条内容
已为社区贡献664条内容

所有评论(0)