DINOV1~3全系列讲解
一、DINOV1
今天我们学习一个在视觉领域大名鼎鼎的自监督模型DINO。它不需要任何标签信息,也不需要原来对比学习里大量的副样本,就能训练出一个在当时最好的视觉特征提取器。而且它训练出来的vision transformer还能自动找到物体的轮廓,分出前景背景。那他到底是怎么做到的呢?今天我们就来一探究竟。
在开始之前先学习transformer模型和vision transformer模型。这两个模型我之前都讲过,你可以看我之前的文章进行了解。DINO来自self distillation with no labels中的DI和NO。我们先看一下论文的标题,emerging properties in self supervised vision transformers,翻译为中文就是在自监督的IT中所涌现出的特性。

Transformer一出现在NLP领域,就以压倒性的优势战胜了RNN LSTM等循环神经网络,统治了NLP领域。但是VIT的出现只是证明了transformer架构在视觉领域只是能打,但是还没有到吊打卷积神经网络的程度。作者就想这可能不是transformer架构的问题,还是预训练方法的问题。
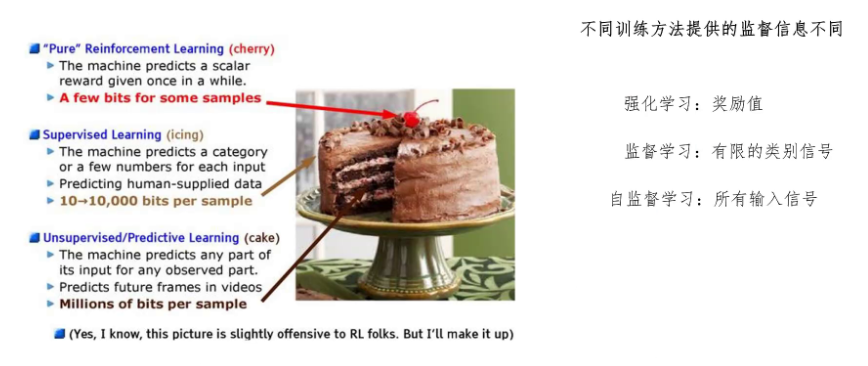
yang这个著名的蛋糕图可以很好地说明不同训练方法之间的差异。如果把整个人工智能领域比作一个蛋糕的话,强化学习让模型所能学到的信息,就像蛋糕上的樱桃是非常少的。因为在强化学习里,人们能提供给模型的监督信息很少,往往只能告诉模型这个预测结果好或者不好,具体怎么做需要模型自己去揣摩。
监督学习能学到的东西就像蛋糕外面的奶油。监督学习我们给模型的学习信息是标签值,标签值可以明确的告诉模型答案是什么,但是答案提供的信息还是太少了。比如对于一个猫狗分类的模型,我们提供的标签就只有这是猫或者是狗的二元信息模型根据这些信息很难学习到什么是真正的狗或者猫。
而自监督学习能学到的东西就像是整个蛋糕里面的面包,它能给模型提供大量的信息,因为所有的输入都是监督信号。比如大语言模型,一句话里每一个token都能给模型提供学习信号。
我们现在来看transformer模型在NLP领域,BERT模型两个预训练任务都是自监督学习。第一个任务是MLM,随机隐藏掉句子里的一些词,让模型进行预测。第二个任务是NSP,给模型两句话,让模型判断这两句话在原文里是否是连续的。GPT是通过训练语言模型的方式,也就是给定前面的token,让模型预测下一个token的方式来训练模型,也是一个自监督的学习方式。

自监督学习方式因为不需要人手动标注数据,所以训练数据容易获取,数量充足。另外它能够提供的训练信息也很多,所以可以训练出效果非常好的transformer架构的模型。反观transformer架构,在计算机视觉这边,ViT用的还是监督学习的方式,在ImageNet和JFT数据集上进行分类任务的训练。作者认为,这是导致ViT效果没有吊打卷积神经网络的真正原因。
之前在计算机视觉领域,大家也尝试过自监督学习。比如对比学习,大家用的任务一般都是实例判别任务,也就是每张图都被看作是一个独立的类别,并通过区分不同的图像来训练模型。比如我们有一张猫的图片,然后通过数据增强得到另一张猫的图片,它被认为是正例,然后再取其他猫的图片作为负例,让模型要能区分出正例和负例。这种方式强迫模型要能够理解图片里面的语义信息,从而提取出好的图片特征。但是对比学习有个弊端,就是需要batch size足够的大,才能有好的结果。一个batch里只能有一对正例,其余都是负例,也就是需要有足够多的负例,模型才能够进行好的对比学习,学出好的特征。而dino想要的是一种不用标签,也不用构建负例的方式来训练模型,这种方式就是一种自蒸馏的方式。
1.1DINO基本思想
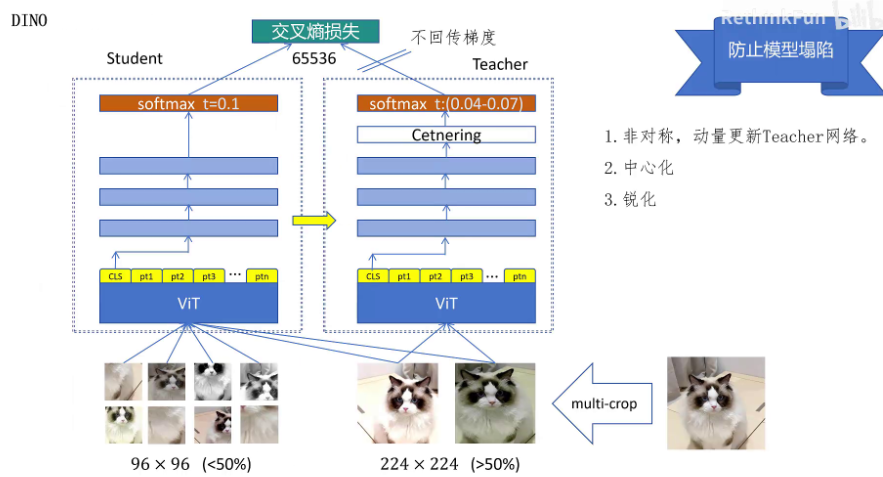
首先我们拿一张图片,然后用它生成两张全局图片尺寸为224 * 224,占原图的面积大于50%,它可以看到原图的全局信息。还有8张96 * 96的局部截图,它们所占原图的比例都小于50%。然后对生成的这些图片都进行图像增强,包括调整灰度、色彩水平翻转等,然后我们生成两个结构一样的网络,一个是教师网络,一个是学生网络。它们都是由Backbone加上三层全连接,最后加一个softmax构成的。我们一个个来看,Backbone可以是ViT,也可以是ResNet,什么模型都可以,只要能提供一个全局的图像特征就行。
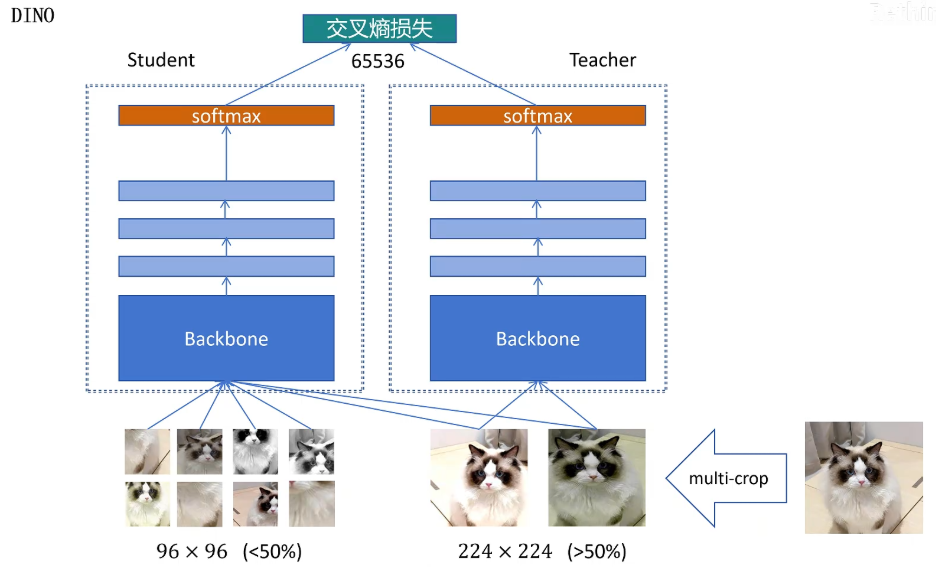
上面这三个线性层是投射层,用来将学生网络和教师网络生成的特征投射到同一个向量空间里,最后输出的特征为65536维。最后加一个softmax,将神经网络输出的logits转化为概率分布。这两张全局的图片同时输入教师网络,也输入学生网络。这8张局部图片只输入学生网络,最后用教师网络和学生网络的输出概率分布向量计算交叉熵损失。希望他们两个输出的概率分布越相似越好。
注意对于全局图片,学生网络和教师网络要用不同的全局图片的输出进行loss计算。我们希望教师网络可以看到全局的图像,生成整体的语义信息。学生网络看到局部,为了能够和教师网络输出同样的特征,必须根据局部信息推断出整体的语义信息,从而让模型学会抽取高级语义特征。
那这样就可以开始训练了吗?因为一般的蒸馏网络里,教师网络都是一个已经训练好的大模型,它把自己的知识教授给学生网络。而在DINO里,教师网络和学生网络都是随机初始化的,而且网络结构都一样,目前这样的网络结构是训练不起来的,如果这样你开始直接训练,很快模型就会找到一个捷径,也就是教师网络和学生网络。最后softmax后都是65536,只有一个值是1,其余全是0。并且不论你输入什么样的图片,它的输出也会一直不变,loss也为零,没有办法进行训练,这就叫做模型塌陷。因为这样对于网络学习是最简单的,它只要让网络输出的项链中一个值比其他值大很多,就可以达到让loss最小化。
1.2解决模型塌陷
那DINO是如何解决模型塌陷问题的呢?第一个做法是教师网络不是靠损失函数来更新模型参数的,而是利用学生网络的权重动量更新自己的权重。它不回传梯度,而是通过在这里用这个公式来更新自己的权重。
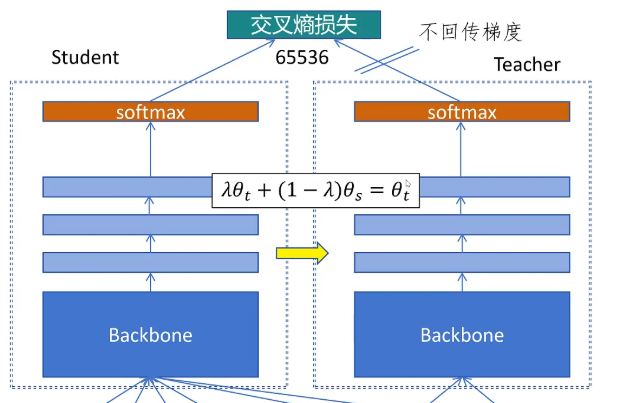
θt是教师网络的权重θs是学生网络的权重。Lambda在训练过程中从0.996逐步变为1。可以看到这里,因为lamda接近于1,每次更新时θt大部分还是来自于自己的值,只有0.00几的值来自于θs,学生网络每次通过loss函数的反向传播来更新自己的参数。教师网络通过动量更新机制保证了自己输出的特征很稳定,让学生网络可以学到一致的信号。并且作者发现,在整个训练过程中,教师网络的表现一直优于学生网络。
防止模型塌陷的第二个方法是给教师网络里增加一个中心化处理,中心化的具体做法就是教师网络的输出减去自己之前输出的均值,这里模型输出的值和均值都是向量,也就是对向量里每个维度都进行减均值的操作。如果网络每次都让固定位置输出一个很大的值,那通过减均值操作就可以排除这个影响。
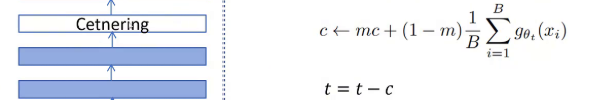
这里均值c的更新也是通过动量更新的方式,这里m是个系数,后边这个B是batch size,后边这个表达式就是对这个batch模型的输出取均值。这里t代表教师网络,在这里的输出中心化就是用教师网络的输出减去之前的均值c,防止模型塌陷。
第三个办法就是尖锐化处理。尖锐化处理是通过给softmax里增加温度系数来实现的这是我们熟悉的soft max公式。后边这个公式就是给soft max公式里增加了温度系数,也就是给每个XI除以一个温度系数T如果温度系数为1,那就退化为标准的softmax。
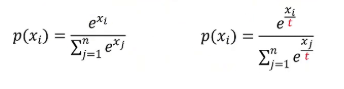
这里我们对这十个数计算标准的soft max也就是温度系数为1,得到的概率分布是这样的。如果我们把温度系数设置为0.1,softmax的输出是这样的,可以看到分布变得非常尖锐,几乎所有的值都集中在一个位置。而我们如果把温度系数设置为10,可以看到softmax之后的分布会变得非常均匀。
DINO里的尖锐化就是给教师网络里最后的softmax设置的温度系数为0.04,训练过程中逐步增加到0.07。这么小的温度值让输出的向量基本上只有一个位置为1,其余位置都为零,这样就让教师网络输出一个高置信度的硬目标。
之前我们提到的中心化可以防止教师网络输出的向量中有一个固定位置为很大大的值,但是网络又有可能所有的位置都输出都差不多大的值,还是学不到任何有意义的信息。教师网络尖锐化的输出,让学生网络也必须明确的选择某个特征维度作为主要输出,从而避免了模糊或均匀的预测。DINO网络里对学生网络的softmax也会设置一个温度值——0.1,来让学生网络也输出更确定的结果。然而学生网络的温度值还是小于教师网络的,所以中心化和尖锐化两个策略的结合就很好地避免了网络塌陷的问题。所以在DINO网络设计中,通过动量更新教师网络,让学生网络和教师网络非对称,同时加上中心化和锐化,就很好地防止了模型塌陷的问题。
接下来我们看一下dino论文里给出的伪代码,gs是学生网络,gt是教师网络。

第一步让教师网络和学生网络的参数值一样,然后读取一个batch的训练数据,通过数据增强得到视图x1和x2,然后让两个视图分别经过学生网络和教师网络得到最后soft max之后的概率分布值,将教师网络和学生网络对不同视图输出的分布值计算交叉熵loss。然后平均用loss只更新学生网络,利用学生网络的参数值动量更新教师网络的参数。用教师网络这个batch输出的均值动量更新均值c。下边是损失函数的定义,可以看到这里教师网络断开了梯度传递。在计算学生网络的softmax时,除以学生网络的温度值,论文里设置为0.1。教师网络在进行softmax时,首先减去均值做中心化处理,然后除以教师网络的温度值做尖锐化处理,最后应用交叉熵损失函数。
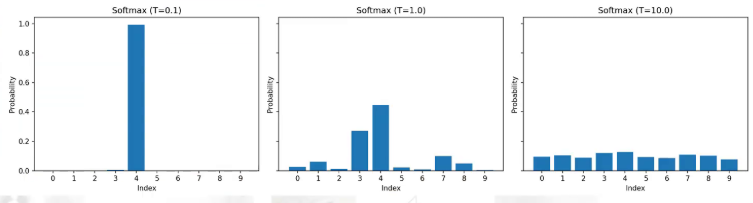
1.3复习ViT
接下来我们再复习一下ViT的网络架构。首先把一个图片拆成patch,一般patch的大小为16 * 16,8 * 8或5 * 5。然后经过一个线性层进行编码映射,再加上位置编码。注意这里在所有的图片patch前增加一个CLS token,用来提取图片的全局信息。最终我们ViTbackend就是取最后一层CLS token输出的特征,后边再加三层MLP的投射层,最后加一个soft max。需要注意的是在我们训练好了ViT的DINO之后,我们直接取ViT的输出特征作为整个图片的特征,并不需要后面的三层MLP和softmax。后边的那三层MLP和softmax只是在DINO训练时使用的。
1.4评价
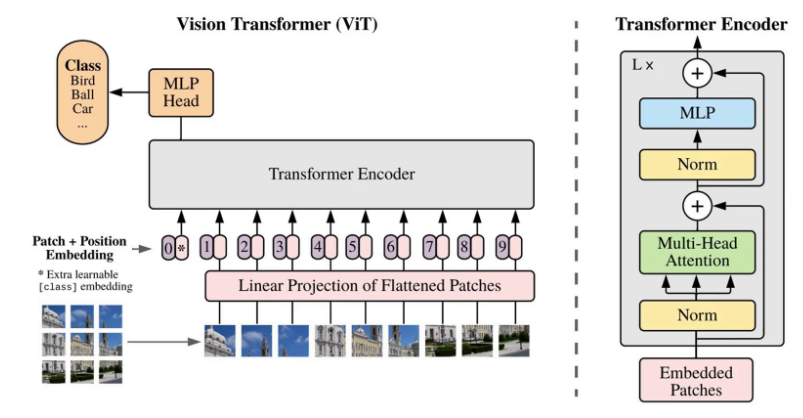
下边我们看一下DINO训练的ViT模型效果如何。在DINO之前评价一个预训练模型的好坏通常有两个办法,一个是给预训练模型后边增加一个线性分类头,冻结预训练模型的参数,只训练线性分类头,看看模型表现如何。第二个办法就是全参数量微调。DINO作者认为,这两种做法都是有可学习的参数,并且依赖于超参数的设置,不能最真实的体现预训练模型的效果。
他提出了一种新的评估方法,那就是用KNN来评估。具体做法就是用预训练好的网络输出所有训练图片的特征向量,然后对于要预测的图片也生成特征向量。然后用预测图片的特征向量和训练图片的特征向量进行比较,找到最相似的几个训练图片,以训练图片的label进行投票决定预测图片的分类。这样完全没有训练参数能更纯粹的比较预训练模型提取特征的能力。
所以作者进行了以下的实验,第一是和之前的自监督模型进行比较,大家都用ResNet50作为BackBone,然后可以看到DINO训练方法,可以得到最好的结果,但是和别的模型相差不大。接下来大家都换为ViT-S模型,可以看到DINO和ViT相结合,效果一下子就提升上来了,远超其他自监督模型。而且更让人惊喜的是,KNN模型的分类精度竟然和线性图分类的精度很接近。这个性质是ResNet50里没有的,也就是说dino和IT进行配合提取的特征质量是非常高的,即使直接用KNN分类效果也是非常好的。
最后一组实验作者比较了DINO ViT设置不同patch大小的结果,有了一个重大的发现,那就是PH大小从16 * 16减小到8 * 8,性能可以大幅提升。可以看到这里用ViT-base模型,patch大小是16 * 16,性能也比不上ViT-small模型 patch大小是8 * 8。但是这也是有代价的,可以发现模型的推理速度会大幅下降,因为patch变小后,图片分割的序列长度会大幅增加,导致transformer架构处理速度度下降。
除了DINO和ViT性能大幅超越之前的自监督网络外,还有一个涌现的特征就是最后一层cls token对其他图片patch token的注意力竟然可以进行语义分割,这是之前预训练网络都不具备的。比如我们看这里,因为ViT是多头注意力,cls token里不同的头对不同图像patch的注意力用不同的颜色表示,我们把注意力大的部分标记出来,可以发现不同的头,注意到不同的语义实体,比如这里连马的缰绳也和马的本体区分开来了。

最后我们再回过头来看一下DINO的意义,1、它不需要标签,也不需要负例,就能训练出强大的视觉预训练模型。2、ViT在自监督下就自然学会了语义分割。3、基础训练框架简单稳定,不依赖对比损失,不依赖负样本,也不依赖大的batch size。4、DINO训练出来的ViT提取图片的特征纯度高,可以广泛的应用于下游任务。
二、DINOV2
下面学习DINOV2,它的论文题目是无监督学习鲁棒的视觉特征。

NLP里面GPT1、GPT2和GPT3的成功,证明了大规模数据加自监督训练任务加大模型可以获得强大的通用特征。作者想在视觉领域复制这种成功,训练一个强大的视觉基础模型以后,在解决视觉问题时,不需要fine-tuning,不需要数据增强,也不需要大规模标注,只要直接把图丢进这个视觉基础模型里,拿到的特征就能解决图像分类、物体检测、语义实例分割、图像检索等各种问题。
2.1数据准备
首先我们看数据部分,DINOV1用的是image net 1K的数据集,大约有128万张图片。DINOV2想要的数据不光要求量大,还要质量足够好,因为来自互联网爬取的图片有很多广告、表情、文字、截图等噪声数据,并且有大量重复的图片。首先作者收集了12亿张原始图片,然后做embedding,接着进行去重,这里采用了拷贝检验的技术,对于原始图片经过拉伸、旋转、调整亮度等生成的图片,也会被认为是重复图片被去除掉。
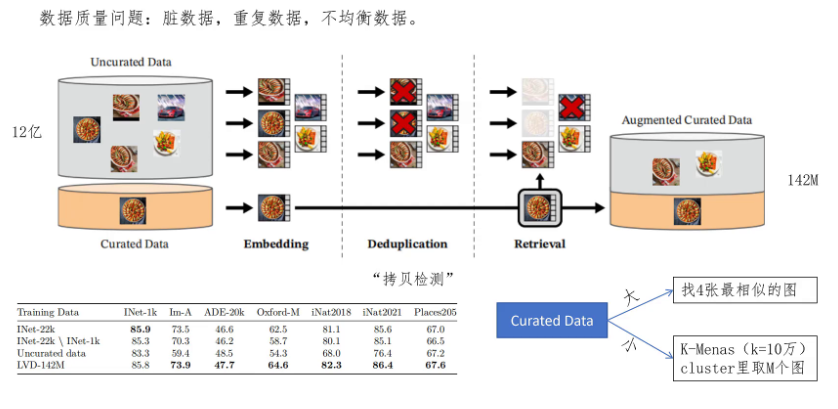
然后怎么从剩下的图片中寻找高质量的图片呢?作者想到的办法就是以常用的公开数据集作为样本,这些数据叫做Curated的data,利用Curated的data在这12亿数据中寻找类似的图片。如果这个Curated的data数据集里的样本足够多,就每拿一张图片,根据向量相似度寻找四张和自己最接近的图片放入最终数据集,作者事先把这12亿张图片的embedding做了k means聚类,一共聚了10万个cluster。如果这个Curated的data的数据样本比较小,则选择这个Curated的data里图片所在的class里取一定数量的图片。通过这种方法,获得了1亿4200万的高质量图片。
后边作者在消融实验里也做了对比,同样的模型框架,在这个数据集上训练的模型表现高于其他数据集上训练的模型,特别是和原始的Curated的data进行的对比。接下来我们看模型的规模,DINOV1在ViT-small和ViT-base上进行训练,DINOV2主要在ViT-L和ViT-G上进行训练。

2.2之前的模型
接下来我们看一下模型的训练任务,在当时正是CLIP模型大放异彩的时期。它利用图像和文本对来训练一个文本编码器和一个图像编码器。通过训练让图像和文本编码器在匹配的文本对上生成的向量要尽可能的相似,在不匹配的文本对上生成的图像和文本向量要尽可能的不相似。最终通过这种方式训练的图像编码器可以很好地提取图像中的语义信息,并且可以用自然语言来匹配查询。
作者认为,CLIP模型利用图文对的训练方式限制了模型从图片中提取特征的能力,因为文本描述只是对图像信息的近似。俗话说一图胜千言,把图片描述成文本,总是有信息丢失的,而且像素级的信息是无法通过文本描述体现的。最后,图文对数据也不是很容易获取,不像GPT那样可以用任何文本来训练,同时也只用文本信息来进行训练。作者想视觉特征提取,就应该只用视觉信息进行自监督学习,这样最纯粹,效果也会最好。
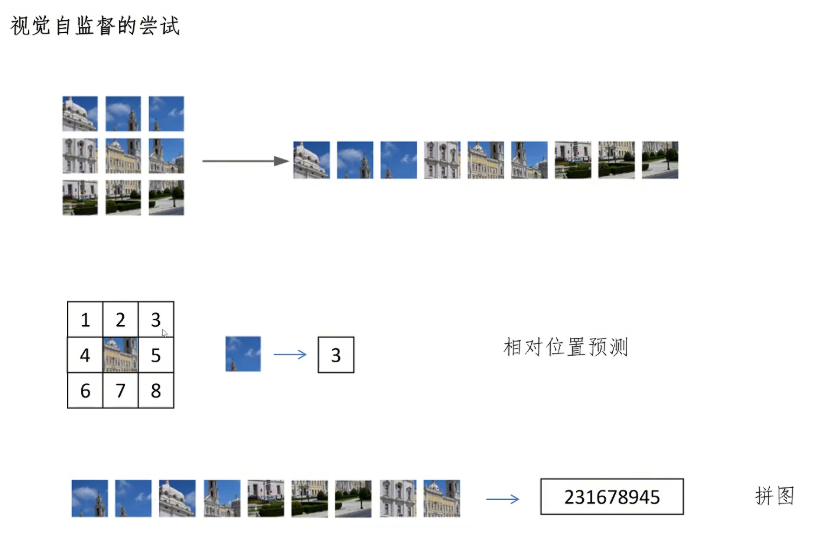
当然,在DINO之前,也有很多纯粹基于视觉特征的自监督学习,比如把图片分割为多个patch,给出两个相邻的patch,以一个patch为中心,让模型预测另一个patch在中心patch的哪个位置,一共有8种不同的可能位置。还有把打乱的patch进行排序,拼图的预测任务。还有对灰度图片进行上色,变成彩色图片的预训练任务。也有把原始图片的一些patch mask掉,让模型恢复这些patch的像素值。其中最著名的就是何恺明的MAE模型。
我们回到我们之前讲过的DINO模型,它通过把图片切分为全局和局部不同的视图,并且数据增强给教师网络只看全局,视图给学生网络看全局和局部视图。网络采用ViT网络提取cls token生成的全局特征,通过一个三层的MLP做投射,经过softmax希望学生网络通过局部视图生成的概率分布和教师网络生成的概率分布一致。学生网络通过loss函数的梯度回传更新参数,教师网络通过学生网络动量更新网络参数,而且教师网络采用了中心化和锐化来防止模型塌陷。
在DINOv1之后,有人基于他的工作做出了一个新的模型,叫做iBOT。iBOT里沿用了DINOv1里的方法训练模型,就是通过cls token提取的全局特征,来训练学生网络对图片整体语义的理解能力,这个loss叫做CLS loss。
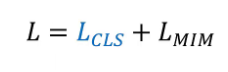
除此之外,iBOT还训练了一个loss叫做MIM loss。MIM的意思是mask image model图像掩码建模。他的做法是让学生网络和教师网络都看全局的视图,但是把学生视图里的一些相邻的patch mask掉,然后取学生网络的最后一层,这些被mask掉的patch token输出的feature,经过投射头的输出。然后教师网络这边可以看到所有的patch,同样提取对应patch token,在ViT网络最后一层输出的feature都经过各自的三层MLP进行投射。
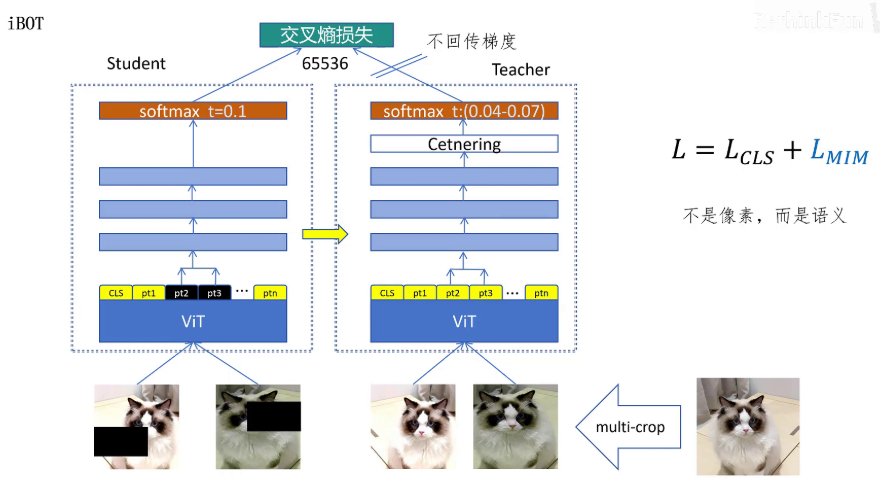
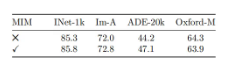
教师网络这边还有中心化和锐化处理,softmax,然后计算交叉熵损失,通过MIM loss可以增加模型对patch细节语义的理解。需要特别注意的是,这里对patch的mask预测的不是像素值,而是一个概率分布的向量。可以理解这里提取的是patch的语义信息。DINOv1里也采用了这个MIM loss,作者也做了消融实验。可以看到增加MIM loss后,大部分情况下对模型性能都是有所提生的。
2.3创新点
对于DINOv2同样的教师网络只看全局视图,学生网络看全局和局部视图。首先我们看学生网络看全局视图的情况,这时候会把学生网络一些相邻的patch mask掉。然后CLS token的输出和教师网络cls token的输出 计算cls loss,mask的patch token的输出和教师网络对应的patch token计算MIM loss。
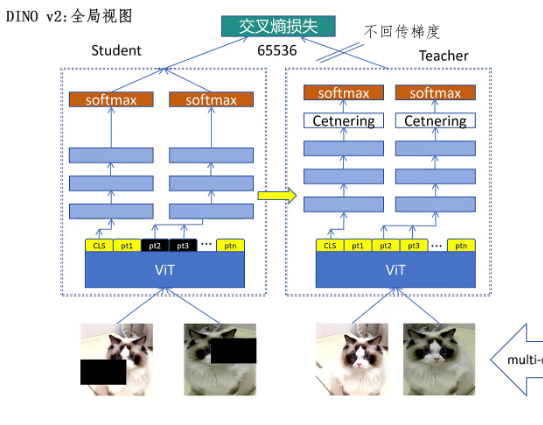
需要注意的是DINOv2通过实验发现cls token和patch token用不同的映射头效果有提升。但是iBOT论文里说CLS token和patch token共用映射头效果更好,这可能是训练数据的规模不同引起的。然后看学生网络,看到局部视图的情况,这时不会对学生网络的局部视图进行mask,因为局部视图的patch和教师网络的全局视图的patch位置不能对应。这里就只计算cls loss,也只用cls token的映射头。
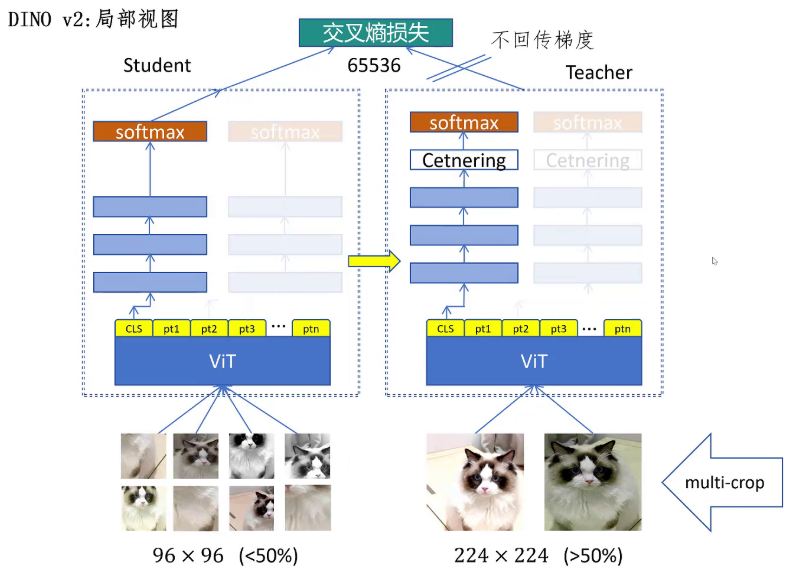
DINOv2还对中心化方法进行了改进,之前v1用减去 教师网络输出均值 的方式来做中心化,教师网络的均值通过动量更新。中心化的作用是防止模型每次不论输入是什么,只让固定的一个位置输出较大的值,引起模型塌陷。
DINOv2这里采用了SK居中的方式,它可以看作是soft max的升级版。它不光能保证每个样本输出的概率分布加和为一,还能保证每个拜池里的样本在不同类别的分布均匀,防止拜尺里所有的样本都固定选择一个类别。

它是怎么做到的呢?首先这里的L是ViT cls或者patch token在经过三层LMP后的输出logits。先用温度参数 temperature 缩放 logits,再取指数,得到一个非负的矩阵。温度越高,概率分布越平滑;温度越低,分布越尖锐(更接近 one-hot)。Q可以看作是soft max函数里的分子项,然后经过一个循环,这个循环在DINOv2里设置为3。首先对于每个样本来说,每个维度的指数值除以每个样本所有维度的指数值之和,这里其实就是soft max的公式。
这两行归一化是关键的,对于这个batch里所有的样本在某一个维度的指数值 除以 所有样本在这个位置的指数值的加和,这样就可以防止所有的样本都在同一个位置,概率值很大。如果这个位置所有的样本概率值都大,则除的数就大,相当于减小了所有样本选择这个位置的概率输出。这样循环3次,就达到了中心化的效果,让一个batch里不同的样本可以均匀的分布在不同的类别上。
因为它同时除了温度值进行了尖锐化,也有soft max的作用。所以sk中心化这一步就可以取代教师网络之前的中心化尖锐化和softmax。学生网络这边还是用带有温度系数的softmax。简单来说,sk算法通过交替进行规一化和列规一划,强迫模型在整个batch内公平的使用所有的特征维度,防止模型只盯着某几个维度输出。
Dino v2还有一个改进就是给loss函数里增加了一个迫使特征均匀分布的loss,那就是KoLeo loss。在进行KoLeo loss计算前,首先把特征向量进行归一化,保证所有特征向量的长度为1,那所有的特征向量就都分布在一个半径为1的球面上。KoLeo loss的作用,强迫一个batch里生成的特征向量要互相远离,让生成的特征向量铺满整个球面。
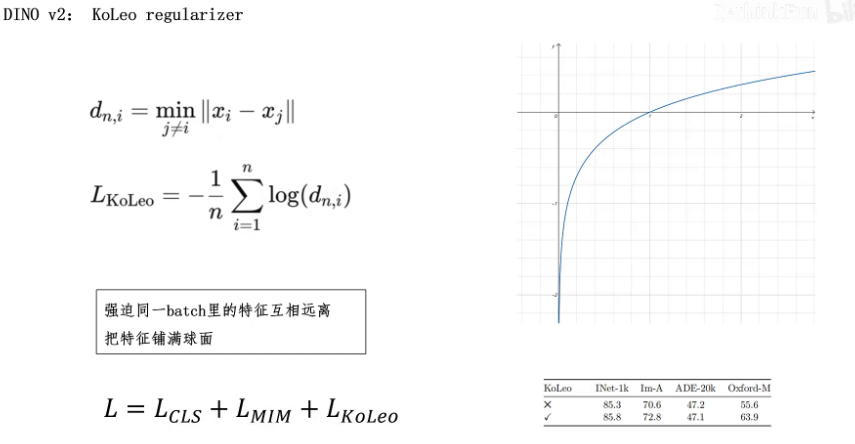
它的计算公式也很简单,首先计算batch里每个特征向量和离它最近的向量的欧式距离,然后取这个距离的log值,再取负值。可以看到如果这个距离很近接近零的话,它的log值再取负值就得到一个很大的正值,loss就很大。然后对半尺里所有的特征向量计算这个值再取平均作为KoLeo loss。所以最终DINOV2的loss就由三部分构成,cls loss、MIM loss、KoLeo loss. 作者也做了消融实验,可以发现增加了KoLeo loss后,模型精度也是有提升的。
另外DINOV2在训练时大部分时间都是用224 * 224的中等分辨率图片进行训练的,这样可以学到类别、物体、部件之间的语义关系,而且因为分辨率不大,训练效率很高。在模型训练快结束时用高分辨率图片进行训练,增加模型适应更长序列patch数据,同时能提取更精细的边界,增强像素级别任务的能力。
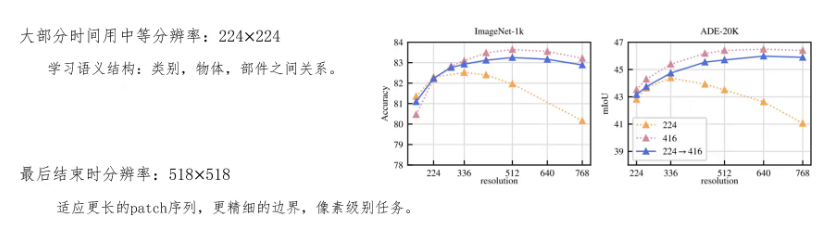
可以看这边的图,横坐标是图片分辨率的变化,越往右分辨率越高。纵坐标是模型的表现,越往上越好。最上面的这条线是一直用高分辨率图片训练的模型表现。中间这条线是DINOv2先用中等分辨率训练,最后用高分辨率增强的训练方法的模型表现。最下边这一条线是一直用中等分辨率训练模型的表现,可以看到先用中等分辨率进行训练,只在最后用高分辨率增强训练的方法和一直在高分辨率下进行训练的效果是差不多的,而且可以大大减少训练的代价。

DINOv2也做了很多工程化的工作,他们用的是A100的GPU,pytouch 2.0的框架。经过他们工程化的优化,比iBOT训练速度提升了2倍,而且显存占用只有iBOT的3分之1。DINOv2自研了flash attention的实现,另外也实现了sequent packing的技术。因为DINOv2训练时既有全局也有局部图片,导致每张图生成的token数量不同,序列长度不同。Sequence packing是把多张图的token序列拼成一个长序列送入GPU,利用mask技术让每张图只关注自己的patch,多个序列一并训练,增加显卡的利用率。另外还使用了pytouch的FSDP来实现模型分布式训练。最后他们还在训练的大模型基础上蒸馏训练了一些小模型,并且实验发现通过蒸馏得到的小模型比从头训练的小模型表现要好。
三、DINOv3
下面来学习DINOv3,DINOv3的愿景是让计算机视觉领域再也不需要费时费力的数据标注,并且希望用同一种训练方式来满足各个领域各种视觉任务。DINO系列一直坚持用自监督的方式来训练模型,当然DINOv3也不例外。那自监督的训练方式的优势是什么呢?首先自监督训练不需要标注或者像图片的标题这这种特性让自监督样的原数据,而且训练时不针对任何具体的下游任务,训练出来的模型信息非常丰富,而且鲁棒性可以满足不同的下游任务。学习可以应用在任何领域的计算机视觉任务,比如天文、遥感或者医学领域等。这些领域有着大量的原始图片,但是绝大部分都没有标注。
3.1数据准备
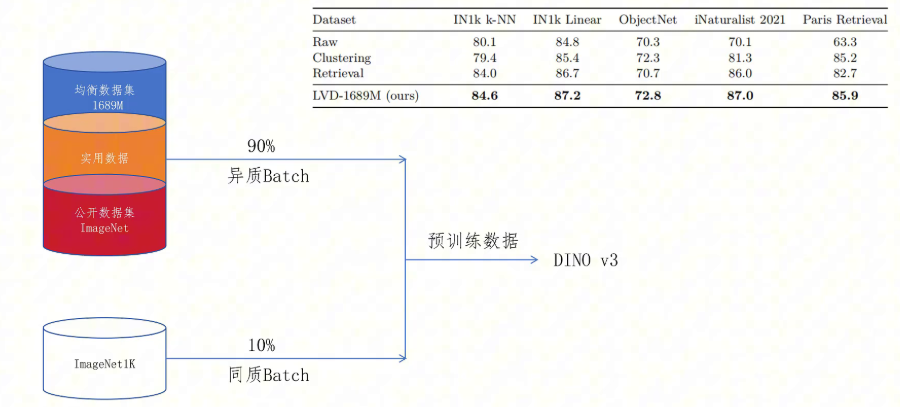
首先我们看对像DINOv3这样想要训练一个基础视觉大模型,需要准备什么样的数据呢?作者认为需要平衡数据的多样性和实用性。因为DINOv3的原始图片数据是从instagram上采集的,里面的图片肯定是自拍、美食、风景等这类的图片占大多数。但是像宇宙、医学、工业零件等的图片会非常少。要做通用大模型肯定希望图片要多种多样,但是同时要兼顾实用性。

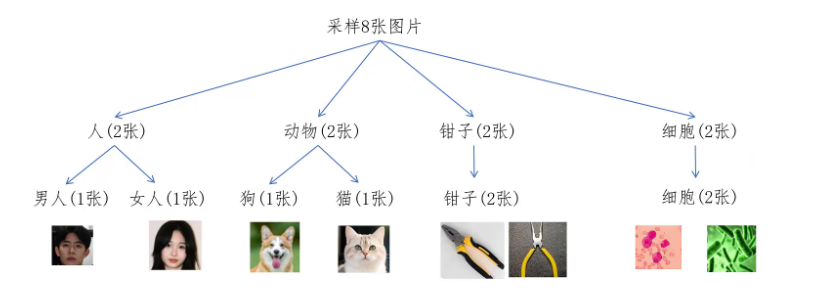
实用性怎么理解呢?因为我们最终训练的模型还是希望它服务于人类生活,应该要照顾人类关心的场景。比如你花了很多钱发射了一颗卫星去采集了土星表面的图片,它确实增加了图片的多样性,但是对于人类来说实用性不大。接下来我们就看作者是如何平衡图片的多样性和实用性的。从instagram上采集的原始图片,美女自拍是非常多的,帅哥的自拍,猫和狗的图片也有一些。某个医学生可能一时高兴,上传了两张自己细胞实验的,还有一个电工不知道买什么钳子好,发了两张钳子的照片在网上,可以看到数据是非常不均衡的。如果我们训练模型随机选八张图片,肯定大部分都是是美女图片。
那我们要如何做才能保证图片的多样性呢?首先对所有的图片提取特征,然后用特征向量做k means聚类。自然相似的图片会被聚类到一起,然后以每个聚类的中心点向量再进行聚类。那概念相似的类就会形成更高级别的类别。比如女人和男人就聚成了人这个类,猫和狗就聚集成了代表动物的一类。而像细胞和钳子,它们的特征向量距离其他类别中心都很远,还是保留独自一个类别。这样我们就把所有的数据形成了一个简单的二级分类。
这时如果我们要选一个batch 8张图片的话,会对所有的一级分类进行平均分配。每个类别两张图片,然后每个一级分类又会对自己的二级分类进行平均分配。可以看到最终采集的八张图片就很多样性。
在DINOv3里首先从instagram里采集了170亿张原始图片,接着用DINOv2来提取图片特征。对所有图片特征用k means一共聚集了5层,从下到上的类别数分别为2亿、800万、80万、十万、25000。最终从170亿图片里采集了16.89亿均衡分布的图片。
那接下来怎么解决图片实用性的问题呢?也就是让图片更贴近现实任务的需求呢?答案是和DINOv2一样,用人类已经为的现实任务构建好的数据集。比如image net的数据集,利用image net数据集里的图片生成的特征向量和170亿的原始图片特征向量进行匹配,找出相似的图片作为实用数据。最终,作者把从170亿图片里生成的均衡数据集、实用数据集再加上公开数据集一起构成了一个混合数据集。
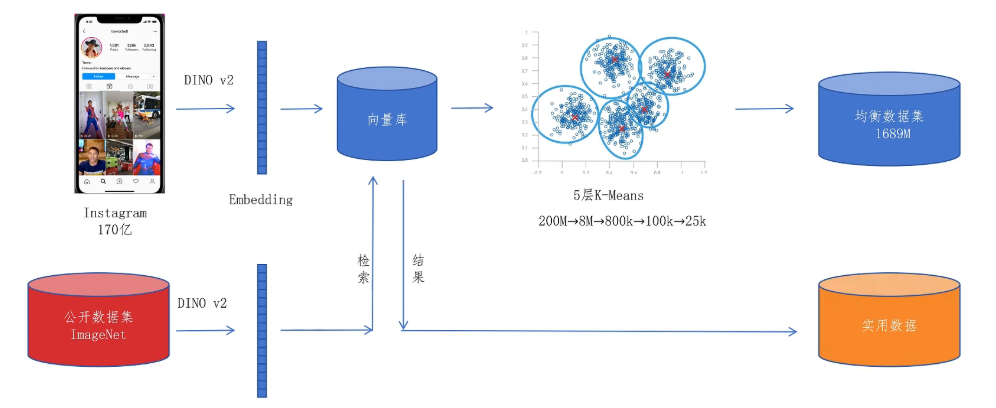
作者还从其他论文那里得到一个见解,那就是如果训练时一个batch里的数据是同样质量的,对模型训练有益于。所以作者在生成batch训练数据时,有10%的批次是从image net 1K的数据中采集的,保证了数据的同质性。有90%的批次是从这个混合的数据集里采集的。作者也做了一个消融实验,把论文里提出的数据混合方案和只用聚类方法或只用检索方法得来的数据集,以及原始未筛选的数据池进行对比,发现自己提出的混合方案训练出来的模型是最佳的。
3.2解决提取局部特征能力下降问题
在解决完训练数据的问题后,还有一个大的问题就是随着模型的训练,模型在提取图像全局特征的能力在不断提升。但是在提取局部特征的能力在下降。局部特征也叫做稠密特征。可以看这边的图,这条线是模型提取全局特征的能力,也就是CLS token提取的特征的表现,随着训练的迭代一直在稳步上涨。但是这条线表示模型提取稠密特征的能力,也就是各个patch提取的图片局部信息的特征表现。刚开始时是提升的,但是当训练迭代达到200K之后就会出现下滑。而且下面这个图,当模型参数增大到7B时,这种退化现象更严重了。这个问题就妨碍了DINOv3进一步增大训练数据和模型参数。
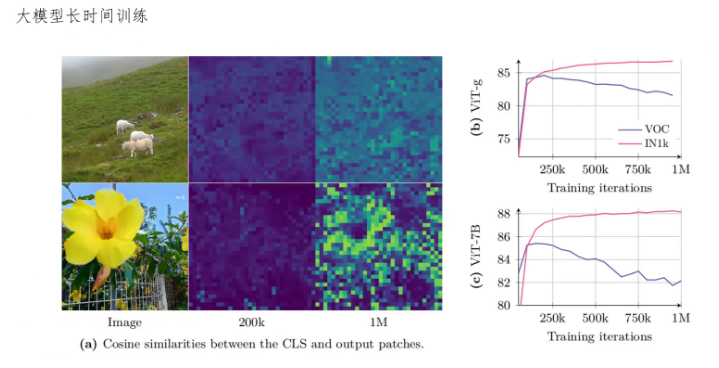
可以看到这个图反映了全局特征和局部特征的相似性。在模型训练200K迭代时,全局特征和局部特征基本没有相似性,但是当模型训练了100万迭代后,局部特征逐步也倾向于学习,全局语义和全局特征越来越相似。这种退化导致模型在最终做语义分割、深度估计等这种依赖稠密特征的任务时表现会变差。所以作者就需要想办法解决这种问题。
作者想到的办法叫做Gram Anchoring。他的思想非常简单,既然模型在训练迭代在200K时,patch之间的相关性最好,那我们就增加一个loss让它约束patch之间的相关性,就保持在200K相关性。注意这里并不是限制每个patch学到稠密特征的具体值,而是限制不同patch特征之间的相关性。因为我们最终使用稠密特征时,并不关心它的具体特征值是什么,只需要表示同一个物体的patch特征值尽可能的相似就可以。

我们看这个具体的公式,对于同一张图片,这里XS表示的是利用学生网络当前参数生成的patch特征,这里的XG表示的是教师网络训练到200K迭代时参数生成的patch特征。这里的G代表gram teacher首先对xs和xg进行L2归一化,保证它们的特征长度为1。然后XS和XS的转置矩阵相乘,内部就是计算任意两个patch的点乘长度为一的两个向量。计算点乘就是计算它们的余弦相似度,最终得到的就是学生网络生成的patch特征之间的余弦相似度矩阵,同样也得到gram teacher网络生成的patch特征之间的余弦相似度矩阵。最终把两个相似度矩阵,每一个对应位置元素的差的平方加起来作为gram loss。
需要注意的是只有在学生网络看到全局视图时才应用gram loss,并且为了效率只在训练了100万迭代后才加入gram loss。Gram teacher的权重取得是训练了100K或者200K时的教师网络的权重,并且每训练一万次迭代会用动量更新的主教师网络的参数来更新gram teacher的参数。
所以在训练DINOv3时,loss一共有四项构成,利用cls token输出的特征,计算的全局特征的DINO loss,计算局部稠密特征的iBOT loss,还有dino v2时我们讲过的让特征尽可能分散的KoLeo loss,最后再加上gram loss,并且gram loss只是在训练了100万次迭代后才加入的。可以看到在加入gram loss后,和稠密特征相关的iBOT loss也迅速下降,代表全局特征的DINO loss不变,gram loss也快速下降,然后保持平衡。
高分辨率的原始图片对于学习稠密特征有很大的帮助,所以作者在Gram teacher输入时采用了分辨率是学生网络2倍的图片,然后对生成的特征图下采样,得到优质并且尺寸和学生网络一致的特征,然后监督学生网络学习稠密特征之间的相似性。可以看这张图,这是原始图片,这是在256分辨率下生成的patch相关性图,这是在512分辨率下生成的。这个是在512生成的基础上做下采样得到的。
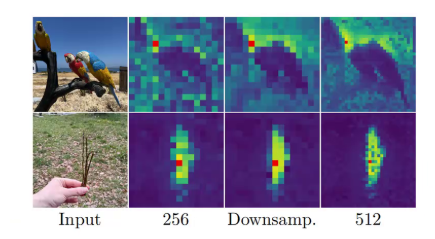
可以看到这种经过高分辨率得到的特征图,在下采样得到的监督信号是好于原始256分辨率的。在依赖局部特征的任务上,采用高分辨率增强的gram teacher表现要好于低分辨率的gram teacher。
3.3DINOv3总结
DINOv3整体的训练框架在DINOv2的基础上做了什么改动。首先这是DINOv2的训练框架,原始图片生成2个全局视图,8个局部视图。教师网络只看全局视图,学生网络看所有视图,全局视图会被mask,然后经过ViT外加三层的MLP做投射。CLS token和patch token用不同的投射头。教师网络这边用sk centnering,学生网络这边用带温度参数的softmax,最终学生和教师网络的CLS token之间计算dino loss,mask的patch token之间计算iBOT loss,学生网络参数动量更新。
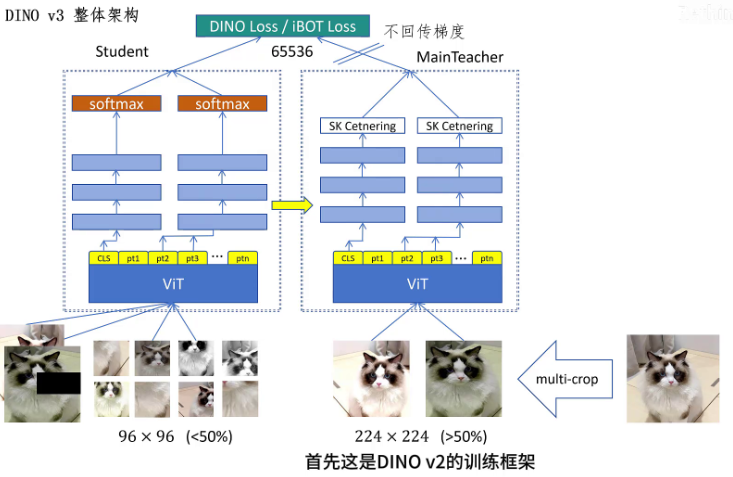
教师网络在DINO V3里首先给ViT输出增加了Koleo Loss增加训练的稳定性,然后就是增加了一个gram teacher,它是通过200K迭代时教师网络的参数初始化的,每一万次迭代用教师网络的参数更新一次gram teacher和学生网络之间计算gram loss。
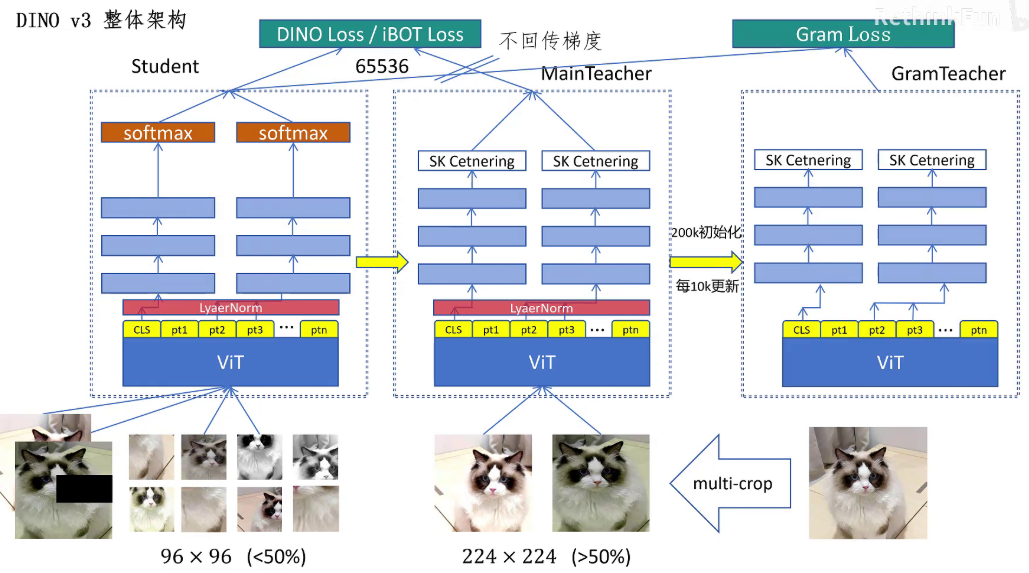
然后我们看一下一些训练的细节,dino v3的整体参数是70亿,优化器用的是AdamW学习英语,应用了warm up,但是取消了cos schedule,改用常数超参数,这样可以保证模型一直训练下去。Batch size为4096,每个batch的token有370万,两个全局视图分辨率为256乘256,局部视图的分辨率为112乘112。训练用了256个H100训练了十天。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)