【数据库】复杂场景下基于代价的连接条件下推:实践与思考
文章目录
前言
在实际的业务系统中,SQL 往往不像教科书示例那样简洁。随着业务复杂度的提升,CTE(公用表表达式)、多层子查询、窗口函数及聚集计算被广泛用于组织逻辑。然而,这类 SQL 在提升可读性的同时,也给查询优化器带来了巨大挑战。尤其是在 JOIN 条件无法有效提前过滤数据的场景下,性能问题尤为突出。
本文将围绕真实客户场景中频繁出现的痛点——复杂查询中因 JOIN 条件下推失败导致的性能瓶颈,系统性地介绍一种**基于代价模型的连接条件下推(Cost-based Join Predicate Pushdown)**的设计与实现思路。
一、问题背景
1.1 客户场景中的典型痛点
在许多客户业务中,SQL 通常采用如下模式组织逻辑:
- 在子查询或 CTE 中完成大量计算(如去重、聚集、窗口函数等);
- 在外层与其他表进行 JOIN,并施加高选择性的过滤条件。
例如:
-- 示意代码:外层过滤条件 s2.b = 3 无法影响子查询 s 的执行
SELECT *
FROM (SELECT DISTINCT s1.a FROM s1) s
JOIN s2 ON s.a = s2.a
WHERE s2.b = 3;
从业务语义上看,这条 SQL 没有任何问题;但从执行角度看,却隐藏着严重的性能隐患:
- 子查询
s需要对s1做全量扫描并去重; - 外层
s2.b = 3的高选择性条件,无法反向约束子查询的扫描范围; - 导致子查询输出一个巨大的中间结果集;
- 后续的 JOIN、聚集等操作都发生在“大数据量”之上,性能急剧下降。
根本问题并不在于 JOIN 本身,而在于过滤发生得不够早。
1.2 业界普遍面临的两大难点
将 JOIN 条件下推到子查询内部,看似直观有效,但在数据库内核层面,这一问题远非想象中简单,主要体现在两个方面:
1.2.1 语义安全性(Equivalence)
JOIN 条件下推本质上是在改变谓词生效的位置。如果处理不当,极易改变 SQL 的语义,尤其是在以下场景中:
- 聚集操作(GROUP BY)
- 窗口函数(Window Function)
- 去重或集合操作(DISTINCT / UNION)
- 含有副作用或非确定性函数的表达式
因此,并非所有 JOIN 条件都可以安全地下推,必须有严格的等价性判定机制。
1.2.2 代价评估(Cost)
即便在语义上等价,下推也未必“划算”:
- 下推后可能触发参数化执行,导致子查询被重复执行 N N N 次;
- 当外层基数较大时,重复计算的开销可能远超收益;
- 极端情况下,性能反而会出现灾难性下降。
这意味着:JOIN 条件下推不仅要“能推”,更要“值得推”。
二、传统方案的局限
传统优化器在面对上述 SQL 时,通常采用如下执行策略:
- 完整执行子查询:扫描基表,执行 DISTINCT/UNION/窗口函数等复杂操作;
- 生成大中间结果集:子查询输出全部数据;
- 外层 JOIN 与过滤:再与外层表进行 JOIN,并施加过滤条件。
这一策略的致命缺陷在于:外层的高选择性 JOIN/WHERE 条件,无法反向约束子查询的扫描范围。当子查询本身计算复杂且数据量大时,这种执行路径几乎必然成为性能瓶颈。
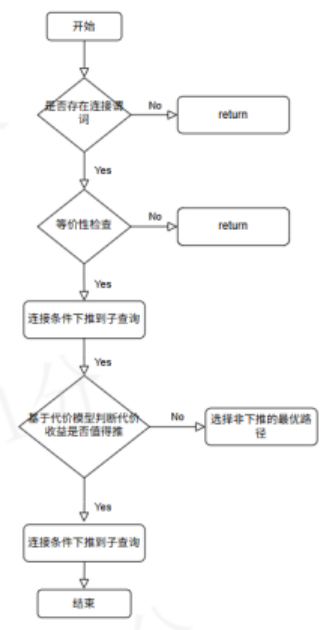
三、金仓数据库基于代价的连接条件下推设计
在金仓数据库最新 V009R002C014 版本中,针对上述问题,我们引入了一套**“等价性 + 代价模型”双重约束**的连接条件下推机制。整体思路概括为两步:
3.1 能不能推:等价性判定(Equivalence)
在这一阶段,优化器的目标不是“尽可能多地下推”,而是只识别绝对安全的下推机会:
- 结构分析:分析子查询结构,判断是否满足语义等价条件;
- 约束判定:对包含聚集、窗口、UNION 等的复杂子查询进行严格校验;
- 谓词拆分:将 JOIN 条件拆分为“可参数化部分(依赖外层列)”和“子查询内部列”。
符合条件的 JOIN 谓词会被改写为参数化过滤条件,注入到子查询的扫描或过滤阶段中。
这一步解决的是:“推下去之后,结果会不会变?”
3.2 值不值推:代价模型(Cost)
在通过等价性校验后,并不会立刻选择下推,而是进入代价评估阶段:
- 路径评估:对比下推前后的执行路径;
- 规模估算:比较子查询扫描行数及中间结果规模;
- 成本计算:评估参数化执行带来的重复计算成本;
- 决策选择:选择整体代价(Cost)最低的执行计划。
如果代价模型判断下推收益不足,甚至可能带来性能回退,优化器将自动放弃下推,选择其他执行路径。
这一步解决的是:“推下去之后,真的会更快吗?”
四、效果验证
4.1 最小化用例验证
测试 SQL:
SELECT *
FROM (SELECT DISTINCT * FROM s3) s3, s1
WHERE s1.s1a = s3.s3a;
测试结果:
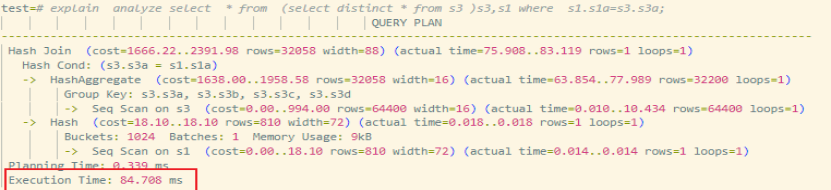
-
未下推:子查询全表扫描 + 去重,执行时间约 84ms。
-
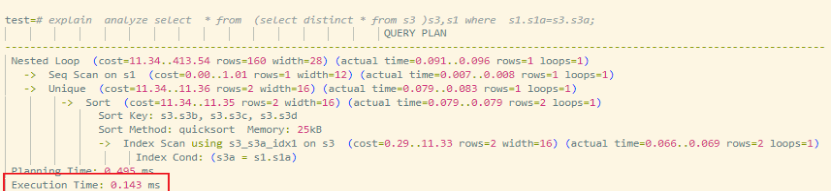
-
下推后:子查询扫描阶段即可被 JOIN 条件裁剪,执行时间约 0.14ms。
-
结论:中间结果规模显著下降,性能提升数量级明显。
对比测试(某不支持下推的 D 厂商数据库):
EXPLAIN SELECT /*+ use_nl(s3 s1) */ *
FROM (SELECT DISTINCT * FROM s3) s3, s1
WHERE s1.s1a = s3.s3a;
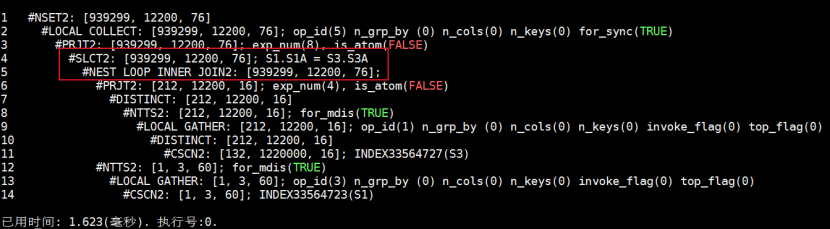
- 执行时间:约 1.62ms,性能差距显著。
4.2 复杂场景验证
测试 SQL:
EXPLAIN ANALYZE
SELECT * FROM (
SELECT * FROM (
SELECT DISTINCT * FROM s3
UNION
SELECT DISTINCT * FROM s3a
) s3, s1
WHERE s1.s1d = s3.s3a
) s
JOIN (
SELECT * FROM (
SELECT s3a, SUM(s3b) OVER (PARTITION BY s3a) AS s3d
FROM s3
) s3, s1
WHERE s1.s1a = s3.s3a
) j ON s.s3d = j.s3a;
在包含 UNION、DISTINCT、窗口函数及多层子查询的复杂 SQL 中:
-
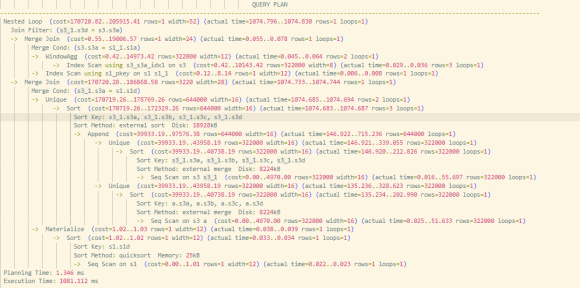
未下推时:
- 多个子查询对基表进行全量扫描;
- 生成多个巨大的中间结果集;
- 最终 JOIN 成为性能瓶颈,总耗时 1081ms。
-
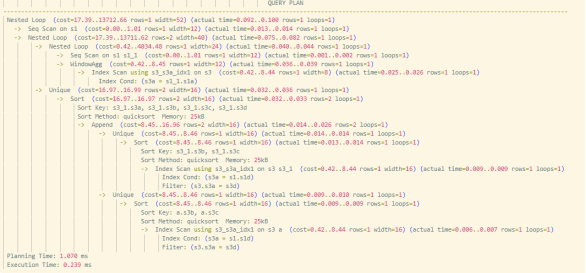
下推后:
- JOIN 条件提前参与子查询扫描;
- 多个子查询由“全量扫描”转为“选择性扫描”;
- 整体执行时间降至 0.23ms。
深度分析:
当连接条件不下推时,执行流程如下:先处理内部的 UNION 查询,其左右两侧需对基表进行去重的全扫描,产生大结果集 A;A 与基表 s1 连接产生中间结果集 B。同时,右侧子查询对基表 s3 分组并计算窗口函数得到大结果集 C,C 与 s1 连接得到结果集 D。最后,较大的中间结果集 B 和 D 进行连接。此过程中,子查询几乎需要对表进行全表扫描,耗时极长。
实现连接条件下推后,利用下推机制将过滤条件注入子查询内部,使得数据在扫描阶段即被筛选裁剪。这不仅减少了扫描时间,更使得后续连接操作的数据量大幅降低,整体查询从“全量扫描”转变为“筛选性扫描”,实现了从 1081ms 到 0.23ms 的数量级性能飞跃。
五、总结
在复杂查询优化中,连接条件下推并非一个简单的规则改写问题,而是一个典型的成本驱动型优化问题:
- 只做规则不看代价,可能带来灾难性的性能回退;
- 只看代价不保证等价,会直接破坏 SQL 语义。
通过**“等价性保障 + 基于代价的决策”**的组合设计,我们可以:
- 在确保安全的前提下,最大化 JOIN 条件的过滤能力;
- 显著减少子查询阶段的数据扫描量与中间结果规模;
- 在复杂 SQL 场景中获得数量级的性能提升。
此类优化对于 OLAP、混合负载以及复杂报表型查询尤为关键,也将成为未来查询优化器演进的重要方向之一。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)