面试被拷问到哑口无言?大模型底层原理与Agent工程化(非常详细),从入门到精通,收藏这一篇就够了!
我又收到了26届同学投递阿里淘天大模型Agent岗的真实一面凉经,同学原话是:“全程30分钟无一句废话,从Transformer底层数学原理,到大模型对齐、Agent工程化、场景性能优化,再到算法手写,12个问题连环拷打,面完直接大脑空白,已经是没招了”。
我看完完整面试实录的第一感受是:淘天的面试,比通用Agent开发岗的考察更深、更贴业务,既要求你吃透大模型的底层原理,又必须有Agent全链路的工程化落地能力,没有一道题是背知识点就能应付的,每一问都在区分“demo选手”和“能落地做事的候选人”。
这篇内容,我完整还原了面试实录,同时做了逐题考点拆解、候选人踩坑点复盘、校招满分回答框架、核心知识点补全,哪怕你没面过淘天,这份内容也能覆盖90%大厂大模型Agent岗的校招核心考点,直接复用在你的面试备考里。
面试全程实录(30分钟高压无缓冲,连环拷打)
面试官:你好,我是淘天大模型团队的面试官,我们直接开始,先不做自我介绍,先问基础原理。
候选人:好的面试官。
面试官:第一个问题,Transformer中Attention的本质是什么?你能从数学角度简要解释一下吗?
候选人:(慌了,只背了公式)Attention就是QKV三个矩阵,计算查询和键的相似度,然后softmax归一化,加权求和Value,得到注意力输出。
面试官:我问的是本质,不是计算流程。数学角度也不是让你背公式,解释一下背后的数学意义。
候选人:(沉默几秒)本质…就是给不同的token分配不同的权重,关注重要的信息。数学上就是点积计算相似度,然后加权求和。
面试官:行,那顺着这个问,在Agent多轮对话任务中,你觉得Attention的局限性体现在哪些方面?
候选人:主要是长上下文的算力消耗高,还有上下文窗口的限制,多轮对话太长了就处理不了。
面试官:只有这些?结合Agent多轮对话的具体场景,比如多步规划、工具调用,再想想。
候选人:…暂时想不到其他的了。
面试官:好,我们问大模型对齐相关的。简要介绍一下SFT的核心流程,以及数据集的构建策略,SFT之后常见的对齐阶段训练还有哪些?它们之间的目的有何区别?
候选人:SFT就是有监督微调,用问答对数据训练模型,让它遵循指令。数据集就是收集高质量的问答对,清洗之后格式化。SFT之后还有RLHF,用人类反馈做强化学习,让模型更符合人类偏好。
面试官:数据集构建的核心策略是什么?只说收集清洗?对齐阶段只有RLHF?每个阶段的目的区别,你也没讲清楚。
候选人:(开始紧张)数据集要保证高质量,和业务场景匹配…对齐阶段还有DPO,也是对齐用的。
面试官:那正好,PPO和DPO在大模型对齐中的主要区别是什么?DPO训练通常有哪些注意事项?用过GRPO么?
候选人:DPO比PPO简单,不用训练奖励模型,直接用偏好数据训练。注意事项就是数据质量要高。GRPO…没了解过。
面试官:行,那问RAG,什么是RAG,它是怎么提升生成质量的?与传统检索+模型生成的流程有何不同?如何评估一个RAG系统是否work的?
候选人:RAG就是检索增强生成,把文档存到向量库,用户提问的时候召回相关内容,给大模型生成,减少幻觉。和传统检索生成差不多,就是用了向量检索。评估的话,人工看回答对不对。
面试官:差不多?那我问你,你简历里写的Modular Agent项目,能讲讲它是如何实现多步规划的吗?
候选人:用了ReAct框架,让大模型先思考再行动,每一步先规划要做什么,然后调用工具,拿到结果再规划下一步。
面试官:模块化体现在哪里?多步规划的完整链路,从目标拆解到执行修正,具体是怎么实现的?
候选人:…就是把思考和行动分开,模块化的设计,具体的实现就是用提示词引导大模型做规划。
面试官:项目里提到了多个工具调用链路,调度策略是如何设计的?是否有异常fallback策略?
候选人:让大模型根据用户的问题,选择对应的工具调用。异常的话,就让大模型重试。
面试官:只有重试?那Agent评估体系包括哪些维度?如何衡量planning能力 vs hallucination rate?
候选人:评估就是看任务能不能完成,规划能力看规划的步数对不对,幻觉率看回答有没有编造内容,人工评估。
面试官:你项目里微调了Qwen,选择的训练阶段和Loss函数是如何决定的?
候选人:选了SFT阶段,用了交叉熵损失,因为SFT能让模型适配业务场景,交叉熵损失是大模型训练常用的。
面试官:为什么不选其他阶段?为什么不用其他Loss?选择的依据是什么?
候选人:…因为SFT最常用,交叉熵损失效果最好。
面试官:行,项目里的Prompt自动推荐模块用了哪些优化策略?有没有尝试过Prompt压缩或embedding表示的方式?
候选人:用了Few-Shot示例,让大模型生成对应的Prompt。压缩和embedding没试过。
面试官:接下来是场景题,假如一个Agent 推理链路包含3个工具+高频请求,系统整体延迟较高,你会如何优化?
候选人:加缓存,把工具调用的结果缓存起来,还有提升机器配置,用更好的GPU。
面试官:只有这些?最后一道题,现场手写代码,岛屿数量,用DFS或者BFS都可以,给你5分钟。
候选人:(手写代码,写了一半卡壳,边界条件处理错了,最终勉强写完,但是有bug)
面试官:行,时间差不多了,我的问题问完了,你有什么要问我的吗?
候选人:(心态已经崩了)想问一下,校招面淘天的大模型Agent岗,核心需要具备哪些能力?
面试官:第一,底层原理要吃透,不能只背流程,要知道为什么这么做;第二,要有真的落地经验,不是搭个demo就完事,要懂工程化、全链路的优化;第三,基础要牢,算法、工程能力都不能缺。
候选人:好的,谢谢面试官。
(面试结束2天后,收到感谢信)
逐题深度拆解|考点+踩坑点+校招满分回答
这12道题,完全贴合淘天大模型Agent岗的业务场景,分为三大模块:大模型底层原理(1-5题)、Agent项目与工程化拷打(6-10题)、场景题与算法基础(11-12题),每一题我都给你拆解清楚,校招面试直接复用。
一、大模型底层原理|从背知识点到吃透本质
1. Transformer中Attention的本质是什么?你能从数学角度简要解释一下吗?
核心考点:不是考察你能不能背QKV的计算流程,而是看你有没有理解Attention的核心设计思想,能不能从底层讲清它的数学意义,这是大厂校招区分“背书选手”和“懂原理的候选人”的核心题。
核心踩坑点:只复述QKV的计算步骤,不讲本质;只写公式,不解释背后的数学意义和物理含义。
校招满分回答框架:
Attention的核心本质,是通过内容寻址的软查询机制,实现序列内全局上下文的自适应信息筛选与加权聚合,解决了传统RNN类模型无法并行计算、长程依赖建模能力弱的问题。
从数学角度,它的核心逻辑可以拆解为3层核心意义:
-
相似度匹配的核函数计算:Attention的核心是计算Query(查询)和Key(键)的相似度,最常用的缩放点积注意力,本质是用点积作为核函数,衡量两个向量的语义相似性,缩放因子√d_k是为了避免高维向量点积值过大,导致softmax后梯度消失。公式为:
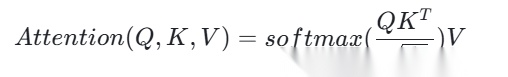
-
归一化的概率分布映射:通过softmax函数,把相似度得分转化为和为1的概率权重分布,实现对不同token的注意力分配——权重越高,代表模型越关注该token的信息,从数学上实现了“聚焦重要信息、过滤无关信息”的能力。
-
自适应的线性加权聚合:用归一化后的权重,对Value(值)矩阵做加权求和,最终的输出是所有Value向量的线性组合,权重由输入序列的内容自适应决定,而非固定的权重矩阵,这也是它被称为“自注意力”的核心原因。
简单来说,数学上它就是一个自适应的线性变换层,通过序列内元素的两两交互,学习全局的依赖关系,最终输出融合了全上下文信息的特征表示。
2. 在Agent多轮对话任务中,你觉得Attention的局限性体现在哪些方面?
核心考点:不是泛泛讲Attention的通用缺点,而是看你有没有真的做过Agent多轮对话场景,能不能结合业务场景讲清痛点,考察你的场景化思考能力。
核心踩坑点:只说长上下文算力高、窗口限制,完全不结合Agent多轮对话、多步规划、工具调用的特定场景,面试官会直接判定你没有真实的Agent落地经验。
校招满分回答框架:
在Agent多轮对话任务中,Attention的局限性,核心集中在长程对话的鲁棒性、多步决策的因果建模、工程化效率三个方面,具体体现在5个点:
- 长轮对话的上下文稀释与注意力漂移:多轮对话中,历史信息会不断累积,而Attention的权重分配是全局的,早期的关键信息(比如第一轮的用户核心需求、工具返回的关键结果),会被后续的冗余对话稀释,注意力权重越来越低,导致模型忘记初始目标,出现规划偏离、回答答非所问的问题,这在Agent长链路多步规划中尤为致命。
- 多步工具调用的长程因果依赖建模不足:Agent多轮对话中,工具调用的执行结果有严格的因果顺序(必须先拿到A工具的结果,才能执行B工具),而因果自注意力对超长序列的长程逻辑依赖建模能力有限,多轮对话中早期的关键因果约束,会随着序列长度增加被稀释,导致模型忽略前置工具的执行结果,出现“还没调用工具就编造返回结果、跳过前置步骤直接执行后续操作”的幻觉问题;同时,自注意力仅能建模token级别的依赖,无法天然对齐“工具调用-结果返回-下一步规划”这种步骤级的强因果逻辑,容易出现规划链路的逻辑断裂。
- 冗余上下文的算力与效率瓶颈:多轮对话中,每一轮新增的对话内容,都会让Attention的计算复杂度平方级增长(O(n²)),尤其是高频请求的场景,会导致推理延迟急剧升高,同时大量的冗余历史信息,会占用宝贵的上下文窗口,挤压工具调用、知识库内容的空间。
- 细粒度的历史信息筛选能力不足:Agent多轮对话中,不是所有历史信息都有用,大部分是中间执行过程的冗余信息,而Attention只能做全局的权重分配,无法精准筛选出“和当前规划步骤强相关的历史信息”,很容易被无关的中间结果干扰,导致规划出错。
- 多轮对话中的幻觉放大效应:单轮对话中,Attention的微小偏差,只会导致单句的生成错误;但在Agent多轮对话中,前一轮的注意力偏差导致的错误结果,会被带入下一轮的上下文,Attention会基于错误的信息继续分配权重,形成错误的正反馈,最终导致幻觉被不断放大,整个规划链路完全崩盘。
3. 简要介绍一下SFT的核心流程,以及数据集的构建策略,SFT之后常见的对齐阶段训练还有哪些?它们之间的目的有何区别?
核心考点:考察你对大模型全流程训练与对齐的完整认知,不是只知道SFT的概念,而是懂工业级的落地流程,尤其是数据集构建——这是SFT效果好坏的核心,也是大厂最看重的落地能力。
核心踩坑点:只说SFT是有监督微调,数据集就是问答对,后续只知道RLHF,讲不清每个训练阶段的核心目的和适用场景,完全没有工业级落地的思考。
校招满分回答框架:
SFT(有监督微调),是大模型从“通用底座”到“适配特定场景/指令遵循”的核心训练阶段,核心是用高质量的标注数据,引导模型学习符合人类预期的输出格式、内容风格和任务执行逻辑。
SFT的核心流程,分为6个标准化步骤:
- 底座模型选型与基线评估:选择适配业务场景的底座模型,先做通用能力、场景任务的基线效果评估,明确微调的优化目标;
- 指令数据集构建与清洗:基于业务场景,构建高质量的指令-回答对数据集,完成去重、去脏、格式标准化、质量分级;
- 数据格式化与训练配置:按照底座模型的要求,把数据格式化为统一的对话模板,配置训练超参数(学习率、batch size、epoch数、冻结策略等);
- 模型微调训练:通常冻结底座模型的底层Transformer层,只微调顶层,或者用LoRA等轻量化微调方式,避免灾难性遗忘,同时监控训练loss的收敛情况;
- 模型效果验证:训练完成后,用测试集做自动化效果评估,核心看指令遵循率、任务完成率、输出格式准确率,同时评估通用能力的保留情况;
- 模型迭代与上线:针对效果不达标的场景,补充对应的数据,重新微调迭代,直到符合业务要求,最终上线。
SFT数据集的核心构建策略
数据集的质量,直接决定了SFT的效果上限,核心策略有5点:
- 场景优先,分布对齐:数据集必须和模型上线的业务场景强匹配,比如Agent工具调用场景,核心数据必须是工具调用的指令-执行对,在垂直Agent场景下,通用对话数据占比建议不超过30%,保证数据分布和业务场景分布一致;
- 高质量优先,宁缺毋滥:单条数据必须满足“指令清晰、回答准确、格式标准、符合预期”,优先选择人工标注的高质量数据,拒绝爬取的脏数据、低质量对话数据,通常1000条高质量数据,效果远好于10万条低质量数据;
- 多样性与均衡性:指令要覆盖业务场景的所有核心任务类型,同时兼顾指令的长度、复杂度、句式多样性,避免某一类任务的数据占比过高,导致模型过拟合,其他任务效果下降;
- 多轮对话的格式一致性:针对Agent多轮对话场景,必须构建多轮的对话数据集,严格按照“用户输入→模型输出→用户反馈→模型输出”的格式,保证模型能学习到多轮对话的上下文理解能力;
- 正反例结合,边界清晰:除了正例数据,还要加入一定比例的负例数据(比如拒绝回答、错误指令处理、异常场景应对),让模型学习到行为边界,知道什么该做、什么不该做。
SFT之后常见的对齐阶段训练,以及核心目的区别
SFT的核心是教模型“怎么说、怎么做”,而后续的对齐阶段训练,核心是教模型“什么该说、什么不该说”,也就是对齐人类偏好与业务要求,常见的阶段和目的区别如下:

4. 什么是RAG,它是怎么提升生成质量的?与传统检索+模型生成的流程有何不同?如何评估一个RAG系统是否work的?
核心考点:大厂Agent岗校招的必考题,和合集第一篇的考点形成呼应,核心考察你对RAG的本质理解,是搭过demo,还是真的懂工业级RAG的全链路设计与评估体系。
核心踩坑点:把RAG等同于“向量检索+大模型生成”,讲不清和传统检索生成的核心差异;评估只知道人工看,没有完整的、可量化的工业级评估体系。
校招满分回答框架:
RAG的核心定义与质量提升逻辑
RAG(检索增强生成),是一种结合外部知识库检索与大语言模型生成的技术框架,核心是通过实时召回与用户query强相关的权威外部知识,精准注入大模型的生成上下文,让模型基于真实、权威的知识生成回答,而非仅依赖底座模型训练时学到的知识。
它从4个核心维度,根本性提升生成质量:
- 解决知识时效性与边界问题:突破大模型训练数据的cutoff限制,能实时接入最新的、私有的领域知识,不需要重新训练模型,就能让模型掌握最新的信息;
- 从源头降低幻觉:让模型的所有生成内容,都有权威的知识来源可溯源,避免模型编造不存在的事实、数据,大幅提升回答的准确性;
- 降低领域适配成本:针对垂直领域场景,不需要大量的微调数据,只需要构建对应的领域知识库,就能让模型适配垂直场景的问答需求,落地成本远低于全量微调;
- 提升内容的可控性与可解释性:可以通过控制检索的知识库范围,约束模型的生成边界,同时所有生成内容都能溯源到对应的知识库片段,可解释性、可管控性远高于纯生成模型。
RAG与传统检索+模型生成的核心差异
两者看似都是“先检索,后生成”,但本质是“单点工具拼接”和“全链路协同系统”的区别,核心差异有4点:
- 检索的核心逻辑完全不同:传统检索生成,核心以基于关键词的字面匹配为主,仅能做浅层的语义匹配,无法深度理解用户query的深层语义和上下文意图;而RAG的核心是混合检索,以语义向量匹配为核心,结合关键词匹配、全文检索,能理解用户query的深层语义,召回字面不相关、但语义强相关的内容,匹配精度和召回率远高于传统检索。
- 知识处理与注入的深度不同:传统检索生成,只是把检索到的全文内容简单拼接到prompt里,没有做任何结构化处理,很容易出现上下文溢出、无关信息干扰;而RAG有完整的知识处理链路:文档解析→分块→结构化处理→元信息标注→嵌入→召回→重排→上下文融合,会精准筛选出和query最相关的知识片段,同时标注来源、页码、标题等元信息,和prompt做深度融合,既保证知识的精准性,又避免无关信息干扰。
- 与生成环节的协同能力不同:传统检索生成是“一次性检索+一次性生成”,检索和生成是完全解耦的两个环节,生成环节无法影响检索;而RAG是全链路协同的,支持多轮召回、自我修正,比如模型发现召回的内容不足以回答问题,可以自动触发二次检索,调整检索关键词,甚至拆解query做子问题召回,检索和生成深度协同,适配复杂的多轮问答、Agent规划场景。
- 落地能力与优化闭环不同:传统检索生成没有完整的评估与优化体系,只能靠人工调整;而工业级RAG有完整的“检索-生成-评测-优化”闭环,有明确的量化指标,能针对召回率低、幻觉率高等问题,精准定位到分块、嵌入、检索、重排、生成的具体环节,做针对性优化,同时支持多模态、多租户、权限管控、高并发等工业级落地能力,这是传统检索生成完全不具备的。
RAG系统的完整评估体系
评估一个RAG系统是否work,不能只靠人工看,必须有可量化、可自动化、多维度的评估体系,分为三大模块:
- 检索侧评估(核心看“找不找得到”):
核心指标:召回率(Top-K召回的相关片段数/库中所有相关片段总数)、精确率(Top-K召回的相关片段数/Top-K召回的总片段数)、MRR(平均倒数排名,衡量相关片段的排序位置)、NDCG(归一化折损累计增益,衡量排序质量);
- 生成侧评估(核心看“答得对不对”):
核心指标:忠实度(回答与召回上下文的一致性,核心衡量幻觉)、相关性(回答与用户query的匹配度)、有用性(回答是否能解决用户的问题)、可溯源率(回答内容能溯源到召回片段的占比)、流畅度;
- 系统侧评估(核心看“能不能落地”):
核心指标:端到端延迟、吞吐量、知识库更新效率、异常容错率、用户满意度、长期使用的效果稳定性。
落地中,常用的评估方式是:LLM-as-Judge自动化评测为主,人工抽检为辅,通过标准化的评测prompt,让大模型自动对比回答与参考内容,输出量化评分,同时针对复杂场景,做10%-20%的人工抽检,校准评测结果。
5. PPO和DPO在大模型对齐中的主要区别是什么?DPO训练通常有哪些注意事项?用过GRPO么?
核心考点:大模型对齐领域的主流算法,大厂校招的高频题,既考察你对两种算法底层逻辑的理解,也看你对工业级落地注意事项的掌握,同时通过GRPO,考察你对前沿算法的关注程度。
核心踩坑点:只说“DPO比PPO简单,不用奖励模型”,讲不清底层数学逻辑的差异;DPO的注意事项只说数据质量,没有工业级落地的全流程思考;对GRPO完全不了解。
校招满分回答框架:
PPO和DPO的核心区别
PPO(近端策略优化)和DPO(直接偏好优化),都是大模型人类对齐的核心算法,但两者的底层逻辑、训练流程、落地成本有本质区别,核心差异如下:
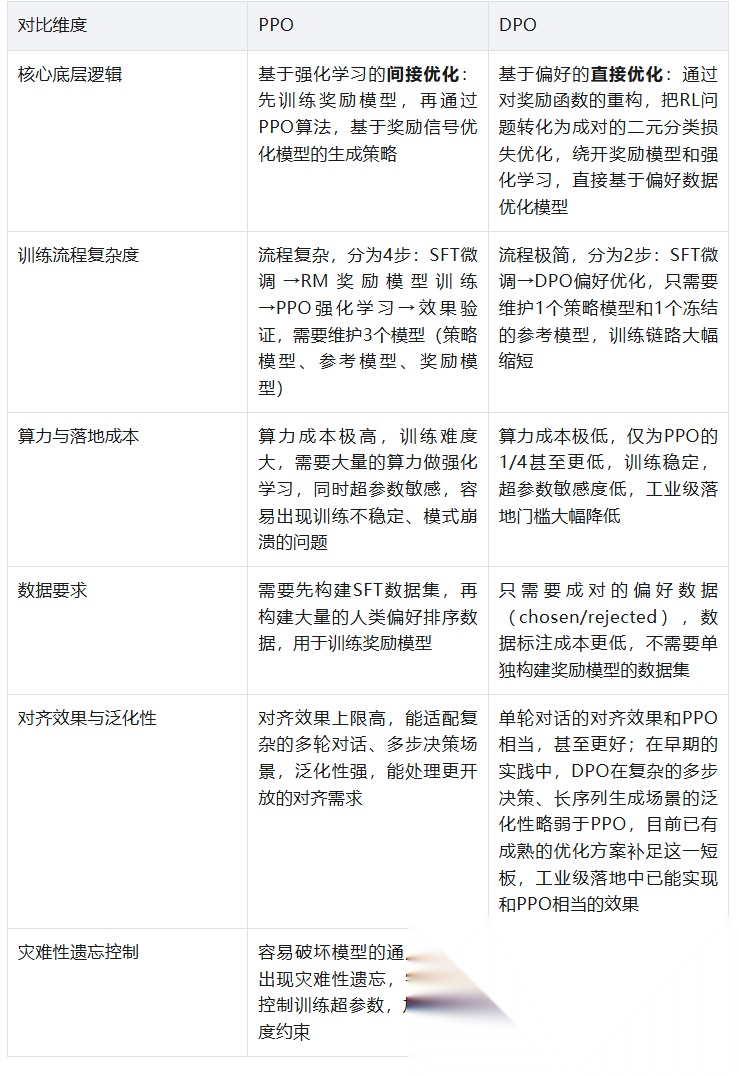
本质区别:PPO是先学习“什么是好的”(奖励模型),再通过强化学习让模型“学着变好”;而DPO是直接通过成对的好坏样本,让模型“直接学会选好的”,绕开了中间的奖励模型和强化学习环节。
DPO训练的核心注意事项
- 成对偏好数据的质量是核心中的核心:
- chosen和rejected样本必须是同一query下的输出,单变量控制,唯一的变量是输出的质量,不能用不同query的输出做配对;
- 两个样本的差异必须足够明显,不能是“都很好,只是风格不同”,必须有明确的好坏之分,否则模型无法学习到有效的偏好信号;
- 数据分布必须和业务场景对齐,比如Agent工具调用场景,偏好数据必须围绕工具调用的准确率、格式正确性,不能用通用对话的偏好数据。
- 参考模型的选择与冻结策略:
- 参考模型必须和SFT完成后的模型完全一致,不能用未经过SFT的底座模型,否则会出现分布偏移,导致对齐效果大幅下降;
- 训练过程中,参考模型必须完全冻结,绝对不能更新参数,否则会破坏KL散度的约束,导致训练失控。
- 温度系数β的精准选择:
β是DPO的核心超参数,控制对齐强度和模型通用能力的平衡:β太小,对齐约束不足,模型无法学习到偏好信号;β太大,约束过强,会严重破坏模型的原生生成能力,出现过拟合。工业级落地中,β通常在0.1-0.5之间,需要通过小范围测试,找到适配业务场景的最优值。
- 训练超参数的控制:
- 学习率必须远低于SFT阶段,通常是SFT学习率的1/10,避免模型过拟合;
- 训练epoch数不能太多,通常1-3个epoch即可,多了很容易出现灾难性遗忘,模型只会输出偏好的固定格式,失去通用生成能力;
- 必须加入足够的通用能力保留样本,避免对齐后,模型在通用场景的效果大幅下降。
- 分布对齐与OOD问题规避:
训练数据的query分布,必须和模型上线后的真实query分布一致,否则会出现分布偏移,训练时效果很好,上线后效果急剧下降,同时要加入一定的边缘场景样本,提升模型的泛化性。
关于GRPO
GRPO(Group Relative Policy Optimization,分组相对策略优化),是DeepSeek深度求索提出的新一代强化学习对齐算法,核心是针对PPO的痛点做了优化,不需要单独训练奖励模型,通过同一query下生成的多个输出结果,计算相对奖励,直接优化模型的策略,大幅降低了PPO的训练复杂度和算力成本,同时保留了强化学习在多步决策场景的优势。
对比DPO,GRPO更适配Agent多步规划、工具调用、多轮对话这类序列决策场景,因为它能基于完整的执行链路,计算全局的奖励信号,优化整个规划过程,而DPO更适合单轮的偏好对齐,对多步序列决策的优化能力弱于GRPO。目前GRPO已经在多个开源Agent框架中落地,是当前大模型对齐领域的热门方向。
二、Agent项目与工程化拷打|从demo到工业级落地的核心差距
6. 项目里的Modular Agent,你能讲讲它是如何实现多步规划的吗?
核心考点:考察你是不是真的做过Modular Agent,还是只是在简历里套了个概念,核心看你对模块化Agent的设计思路、多步规划的全链路落地细节的掌握,这是Agent工程化的核心。
核心踩坑点:只说用了ReAct框架,讲不清“模块化”体现在哪里,也讲不清多步规划的完整实现流程,从目标拆解到执行修正,完全没有细节,面试官会直接判定你是“demo选手”。
校招满分回答框架:
Modular Agent(模块化Agent)的核心设计思路,是把Agent的完整能力,拆分为解耦、可替换、可独立优化的功能模块,避免传统单块Agent的能力耦合、优化困难、泛化性差的问题。我们的项目中,把Agent拆分为6个核心模块:目标解析模块、规划模块、工具调度模块、记忆模块、反思校验模块、生成输出模块,多步规划能力,就是基于这些模块的协同实现的,完整流程分为5个阶段:
- 目标解析与合法性校验阶段
用户query输入后,先由目标解析模块,对用户的复杂目标做拆解和结构化,明确用户的核心需求、输出要求、约束条件,同时做合法性校验,判断目标是否在Agent的能力范围内、是否符合安全规范。如果目标不清晰、缺少关键信息,直接触发追问模块,向用户确认补充信息,避免后续规划出现偏差。
2.分层目标拆解与初始规划生成阶段
校验通过后,规划模块会基于思维树(ToT)+ 任务依赖图谱,把用户的复杂大目标,拆解为多个有明确依赖关系、可独立执行、可验证结果的子任务,同时定义每个子任务的:输入输出要求、执行条件、终止条件、所需工具、优先级。
比如用户的目标是“帮我查询某商品的库存、物流时效,同时计算优惠后的价格,生成下单攻略”,会被拆解为4个子任务:① 查询商品库存与基础信息;② 查询用户地址对应的物流时效;③ 计算商品优惠后的最终价格;④ 基于前三个结果,生成下单攻略。同时明确①②③可以并行执行,④必须等前三个完成后才能执行。
模块化的优势在这里体现的很明显:规划模块可以单独优化,我们可以针对不同的场景,替换不同的规划模型(比如复杂场景用大模型,简单场景用微调后的小模型),不需要改动整个Agent的架构。
3.动态调度与子任务执行阶段
初始规划生成后,工具调度模块会基于子任务的依赖关系、优先级,生成执行链路,串行/并行调度对应的工具执行,同时记忆模块会同步记录每一个子任务的执行过程、工具返回结果、执行状态,同步到全局上下文,保证后续的规划步骤,能基于完整的历史执行信息。
4.执行反馈与规划修正阶段
每一个子任务执行完成后,反思校验模块都会做两层校验:① 子任务的执行结果是否符合预期,是否能满足子任务的目标;② 当前的执行结果,是否能支撑最终的用户目标达成。
如果出现执行失败、结果不符合预期、缺少关键信息的情况,不会直接终止整个链路,而是会触发规划修正:反思模块会把错误原因、缺失的信息反馈给规划模块,规划模块会重新调整子任务、修改执行链路,甚至拆解新的子任务,重新执行,直到子任务符合预期,避免单步错误传递到整个规划链路。
比如工具调用返回的库存信息为空,规划模块会重新拆解子任务,先查询商品的在售状态,再重新查询库存,而不是直接崩盘。
5.目标达成校验与结果汇总阶段
每完成一个子任务,都会触发最终目标达成校验,判断当前的所有执行结果,是否已经能完整满足用户的核心需求。如果达成,规划模块会终止规划流程,把所有子任务的执行结果,同步给生成输出模块,汇总生成符合用户要求的最终回答;如果未达成,继续执行后续的子任务。
整个多步规划流程,所有模块都是解耦的,我们可以单独优化规划模块的目标拆解能力、反思模块的错误校验能力,不需要改动整个Agent的架构,同时整个规划过程可解释、可追溯、可修正,泛化性和鲁棒性,远高于传统的单块ReAct Agent。
7. 项目提到了多个工具调用链路,调度策略是如何设计的?是否有异常fallback策略?
核心考点:Agent工程化落地的核心能力,大厂非常看重这一点——demo级的Agent只会让大模型选工具,而工业级的Agent,必须有完善的调度策略和异常兜底策略,保证高可用,这也是区分“玩具项目”和“落地项目”的核心。
核心踩坑点:只说“让大模型根据用户问题选工具”,没有完整的调度架构设计;异常fallback只说“重试”,没有分场景的兜底策略,完全没有高可用的思考。
校招满分回答框架:
工具调用的调度策略设计
我们的工具调度策略,核心是**“前置规则过滤+大模型语义路由+后置执行校验”的三级调度架构**,既保证工具选择的准确率,又降低大模型的幻觉,同时提升调度效率,适配高频请求场景,具体设计如下:
- 第一层:前置规则过滤层(先做减法,降低幻觉)
这一层的核心,是先把无效的、不可用的工具过滤掉,缩小大模型的选择范围,从源头减少工具选择错误的幻觉。核心规则包括:
- 场景过滤:基于用户query的意图识别结果,只保留对应场景的工具,比如用户的query是电商订单查询,直接过滤掉非电商相关的工具;
- 权限过滤:基于用户的身份、权限,过滤掉用户无权限调用的工具;
- 状态过滤:过滤掉当前不可用、服务降级、接口超时的工具,只保留可用状态的工具;
- 优先级过滤:给工具设置优先级,官方工具、高可用工具、低延迟工具优先级更高,优先进入候选池。
2.第二层:核心语义路由层(精准匹配,动态调度)
这一层是调度的核心,基于大模型的Function Call能力,实现工具的精准选择和动态调度,核心策略包括:
- 结构化的工具描述:给每个工具定义标准化的描述,包括核心功能、入参要求、出参格式、使用场景、限制条件,让大模型能精准理解每个工具的能力边界;
- Few-Shot示例引导:在prompt中加入高质量的工具调用示例,覆盖单工具调用、多工具串行/并行调用、异常场景处理,引导大模型输出符合要求的工具调用指令,大幅提升工具选择的准确率;
- 串行/并行自适应调度:基于子任务的依赖关系,自动选择调度方式:无依赖的工具,并行调用,降低整体延迟;有强依赖的工具,串行调用,保证执行逻辑正确;
- 工具调用链路的动态调整:支持多轮工具调用,前一个工具的返回结果,可以作为后一个工具的入参,同时支持根据工具返回的结果,动态新增工具调用步骤。
3.第三层:后置执行校验层(提前拦截,避免无效调用)
这一层的核心,是在工具调用执行前和执行后,做两层校验,避免无效的工具调用,提升链路效率:
- 调用前校验:校验大模型生成的工具调用指令,是否存在工具不存在、入参缺失、入参格式错误的问题,如果有问题,直接触发修正,不执行无效调用;
- 调用后校验:校验工具返回的结果,是否有效、格式是否正确、是否符合子任务的要求,如果结果无效,触发二次调用或者fallback策略。
二、全场景异常fallback策略
我们针对工具调用全链路的每一个异常场景,都设计了对应的fallback策略,保证整个Agent链路不会因为单步工具调用异常而崩盘,核心策略分为5类:
- 工具选择错误的fallback
大模型选择的工具和用户query不匹配、选择了不存在的工具,先触发反思修正:把错误原因、可用工具列表重新喂给大模型,让它重新选择工具,重试次数上限设置为2次;超过重试次数,直接终止工具调用,告知用户当前无法通过工具完成需求,转兜底回答,避免无限循环。
2.工具调用执行异常的fallback
针对接口超时、服务不可用、返回报错的场景:先做指数退避重试,重试次数上限3次;重试失败,自动切换同功能的备用工具;没有备用工具的话,告知用户当前该功能暂时不可用,同时记录异常日志,触发告警,不会让模型编造工具返回结果,从源头避免幻觉。
3.入参缺失/错误的fallback
针对入参缺失、入参格式错误的场景:不会直接执行调用,也不会直接报错,而是触发追问模块,让大模型基于缺失的入参,生成自然语言,向用户询问补充关键信息,用户补充后,自动填充入参,重新执行工具调用。
4.工具返回结果无效的fallback
针对工具返回空结果、无相关信息、结果不符合要求的场景:先触发二次调用,让大模型调整入参、查询条件,重新调用工具;二次调用还是无效的话,告知用户没有查询到相关信息,同时给出合理的建议,绝对不允许模型基于空结果编造内容。
5.多步链路异常的fallback
针对多工具串行调用的场景,某一步工具调用异常,不会直接终止整个链路:先判断该步骤是否是核心步骤,非核心步骤直接跳过,继续执行后续链路;核心步骤触发对应的fallback策略,fallback失败后,才终止链路,返回已执行的有效结果,同时告知用户异常环节,不会让整个链路完全崩盘。
8. Agent评估体系包括哪些维度?如何衡量planning能力 vs hallucination rate?
核心考点:工业级Agent的核心就是可量化、可评估,大厂面试问这个问题,就是看你有没有把Agent项目做闭环,还是只搭了个能跑的demo,同时考察你对Agent核心能力的量化评估方法的掌握。
核心踩坑点:只说“看任务能不能完成”,没有完整的评估维度;对规划能力和幻觉率的衡量,只说人工看,没有可量化的指标和落地方法。
校招满分回答框架:
Agent评估体系的完整维度
Agent的评估体系,必须覆盖“任务完成度、核心能力、内容质量、系统性能”四大维度,形成完整的闭环,具体如下:
- 核心维度:端到端任务完成度
这是评估Agent最核心的指标,衡量Agent能不能最终完成用户的目标,核心指标包括:任务成功率、子任务完成率、目标达成度、平均完成步数、链路执行成功率。
2.核心能力维度:分模块能力评估
针对Agent的各个核心能力模块,做精细化的评估,核心包括:
- 规划能力:目标拆解的合理性、规划链路的正确性、一次规划成功率、异常场景的规划调整能力;
- 工具调用能力:工具选择准确率、入参正确率、调用成功率、异常处理能力;
- 记忆能力:长轮对话的上下文理解准确率、历史信息召回率、关键信息保留能力;
- 反思修正能力:错误识别率、修正成功率、异常场景的容错能力;
- 多轮对话能力:用户意图理解准确率、多轮上下文连贯性、追问合理性。
3.内容质量维度:生成效果评估
核心评估Agent最终输出内容的质量,核心指标包括:幻觉率、忠实度、相关性、有用性、可溯源性、流畅度、安全合规性。
4.系统性能维度:工程化落地能力评估
核心评估Agent的工业级落地能力,核心指标包括:端到端延迟、吞吐量、高并发场景的稳定性、异常fallback成功率、服务可用性、资源消耗。
planning能力的量化衡量方法
planning能力是Agent的核心能力,衡量的是Agent“把复杂目标拆解为可执行步骤,并且能动态调整规划,最终完成目标”的能力,我们从定量指标+定性评估两个维度,做完整的量化衡量:
1. 核心定量指标(可自动化统计,占比70%)
- 目标拆解准确率:拆解的子任务中,和最终目标强相关、无冗余的子任务占比,衡量规划的合理性,公式:
目标拆解准确率 = 有效子任务数 / 总拆解子任务数; - 依赖关系构建准确率:子任务的串行/并行依赖关系构建正确的占比,衡量规划的逻辑正确性,公式:
依赖关系准确率 = 依赖关系正确的子任务对数 / 总子任务依赖对数; - 一次规划成功率:不需要修正规划,一次执行就完成用户目标的任务占比,核心衡量规划的精准度,是评估planning能力最核心的指标;
- 规划修正次数与修正成功率:平均每个任务需要修正规划的次数(次数越少,规划能力越强),以及规划修正后,能完成目标的任务占比,衡量规划的鲁棒性;
- 长链路任务完成率:针对≥5步的复杂长链路任务,任务的成功率,衡量Agent处理复杂规划的能力;
- 规划步数偏差率:实际完成任务的步数,和理论最优步数的偏差率,偏差率越低,规划效率越高。
2. 定性评估(人工标注,占比30%)
针对复杂场景的任务,通过人工标注,评估规划的可解释性、泛化性、鲁棒性,比如:面对突发异常,能不能快速调整规划,而不是直接崩盘;面对模糊的用户目标,能不能合理拆解,而不是无效追问。
hallucination rate(幻觉率)的量化衡量方法
幻觉率衡量的是Agent生成的内容,和真实的工具返回结果、知识库内容、事实信息的不一致程度,核心分为事实性幻觉、工具调用幻觉、上下文幻觉三类,我们的衡量方法分为3层:
1. 核心量化指标
- 端到端幻觉率:存在幻觉的回答数 / 总回答数,这是最直观的指标,公式:
幻觉率 = 有幻觉的任务数 / 总评估任务数; - 细粒度幻觉占比:生成内容中,存在幻觉的片段数 / 总内容片段数,更精准地衡量幻觉的严重程度,避免“一句话有幻觉,就判定整个回答全是幻觉”的极端情况;
- 可溯源率:生成的内容中,能溯源到工具返回结果、知识库内容的片段占比,
可溯源率 = 可溯源的内容片段数 / 总内容片段数,可溯源率越高,幻觉率越低; - 工具调用幻觉率:虚假工具调用、捏造工具返回结果的次数 / 总工具调用次数,专门衡量Agent工具调用场景的幻觉,这是Agent场景最常见的幻觉类型。
2. 自动化衡量方法
核心采用LLM-as-Judge + 规则校验的方式,实现幻觉率的自动化统计:
- 规则校验:针对工具调用幻觉,通过规则校验,判断调用的工具是否存在、入参是否符合要求、生成的内容是否和工具返回的结果一致,直接统计工具调用幻觉;
- LLM-as-Judge:设计标准化的评测prompt,给评测大模型输入「用户query、参考事实(工具返回结果/知识库内容)、Agent生成的回答」,让大模型按照预设的标准,判断回答是否存在幻觉,标注幻觉类型、严重程度,输出量化的幻觉评分,实现批量自动化评测。
3. 人工校准
针对自动化评测中不确定的样本、复杂场景的样本,做10%-20%的人工抽检,校准自动化评测的结果,同时优化评测prompt,提升自动化评测的准确率。
补充:planning能力和幻觉率是强相关的,规划能力越差,多步执行中错误传递的概率越高,幻觉率就越高,所以评估的时候,我们会把两个指标结合起来看,而不是单独评估。
9. 项目里微调Qwen,选择的训练阶段和Loss函数是如何决定的?
核心考点:考察你对大模型微调的底层理解,不是只会调用微调脚本,而是知道“为什么这么选”,每一个选择都有明确的业务依据,这是大厂校招非常看重的——知其然,更要知其所以然。
核心踩坑点:只说“选了SFT阶段,用了交叉熵损失”,讲不清选择的依据,不知道为什么不选其他阶段、其他Loss,面试官会直接判定你是“调包侠”,没有自己的思考。
校招满分回答框架:
微调的训练阶段和Loss函数的选择,核心是由微调的业务目标、场景特性、数据情况、底座模型的状态共同决定的,不是随便选的,所有的选择,都要服务于最终的业务效果。
我们的项目,是让通用的Qwen底座,适配电商场景Agent的工具调用、多轮对话、用户需求理解的业务场景,核心目标是:提升模型在垂直场景的任务完成率、工具调用准确率,同时最大程度保留模型的通用能力,基于这个目标,我们做了对应的选择。
训练阶段的选择,以及核心决策依据
我们最终选择了 「轻量继续预训练(Continue Pre-Training,简称CPT)+ 有监督微调(SFT)」的两阶段训练方案**,没有直接做SFT,也没有做后续的RLHF/DPO对齐,决策依据如下:
- 第一阶段:轻量继续预训练(CPT)
选择这个阶段的核心原因:Qwen的通用底座,对电商领域的专属术语、业务规则、工具接口定义、场景化指令的语义理解不足,如果直接做SFT,模型缺乏对应的领域知识,很容易出现过拟合,工具调用的准确率、场景适配能力都达不到要求。
所以我们先通过电商领域的无监督文本(包括电商业务文档、工具说明、用户历史对话语料、商品详情规范等),做轻量的继续预训练,核心目标是给模型注入领域知识,对齐电商场景的语义分布,让模型先“懂这个领域的内容”,为后续的SFT打好基础。
同时,我们选择了“冻结底层Transformer层,只微调顶层8层Transformer”的轻量训练策略,而不是全量训练,核心是为了避免灾难性遗忘,最大程度保留模型的通用语义理解能力,只让模型学习领域专属的知识。
2.第二阶段:有监督微调(SFT)
选择这个阶段的核心原因:继续预训练只是给模型注入了领域知识,教模型“懂了”,但没有教模型“怎么做”——也就是怎么遵循Agent场景的指令、怎么正确调用工具、怎么处理多轮对话、怎么输出符合格式要求的内容。
所以我们通过高质量的场景化指令数据集(包括工具调用指令对、多轮对话样本、异常场景处理样本、电商问答样本),做SFT微调,核心目标是对齐模型的行为,让模型符合Agent业务场景的输出要求,提升任务完成率。
3.为什么不选择其他阶段?
没有做全量预训练:全量预训练需要海量的领域数据,算力成本极高,同时很容易破坏模型的通用能力,我们的业务场景不需要完全重构模型的能力,只需要做领域适配,轻量CPT完全足够;
没有在SFT后做RLHF/DPO对齐:项目初期的核心目标,是提升模型的场景任务完成率,让模型“能把事做对”,而对齐是解决“做得好不好、符不符合偏好”的问题,是后续的优化方向;同时对齐阶段需要大量的成对偏好数据,初期我们的标注数据储备不足,所以优先完成CPT+SFT的核心能力适配,后续再做对齐优化。
Loss函数的选择,以及核心决策依据
我们针对两个训练阶段,选择了不同的Loss函数,核心决策依据是:每个阶段的训练目标不同,需要Loss函数能精准匹配训练目标,提升训练效率和效果。
- 继续预训练阶段:标准自回归语言模型损失(Next Token Prediction Loss)
本质是针对全序列的交叉熵损失,公式为:
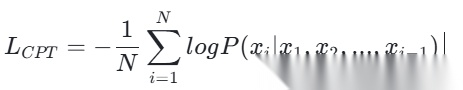
选择的核心原因:继续预训练的目标,是让模型学习电商领域的文本分布,拟合领域内的语义和语法规律,而Next Token Prediction的交叉熵损失,是自回归语言模型预训练的标准损失,能最直接地让模型学习到领域文本的分布规律,没有引入额外的约束,不会破坏模型的原生生成能力,完全匹配我们的训练目标。
2.SFT阶段:带掩码的自回归交叉熵损失(Masked Causal LM Loss)
本质是只针对回答部分的交叉熵损失,通过掩码,把指令部分的loss完全屏蔽,只计算回答部分的token损失,公式为:

其中m_i是掩码,指令部分为0,回答部分为1,M是回答部分的token总数。
选择的核心原因:
- SFT的数据集是「指令-回答」对,我们的目标是让模型学习“根据指令,输出符合要求的回答”,而不是学习指令本身的内容。如果用全序列的交叉熵损失,模型会把大量的训练资源,浪费在学习指令部分的token上,训练效率极低,还容易过拟合;
- 带掩码的交叉熵损失,只计算回答部分的loss,能让模型完全聚焦于学习“怎么根据指令输出符合要求的内容”,大幅提升训练效率,同时减少过拟合的风险,完美匹配SFT的训练目标。
3.针对性优化:工具调用场景的加权Loss
针对我们的核心场景——Agent工具调用,我们在SFT的Loss中,加入了格式权重约束:对工具调用的函数名、入参格式、JSON结构的关键token,提升了loss的权重,让模型更聚焦于学习正确的工具调用格式,减少工具调用的格式错误,最终把工具调用的格式准确率提升了12%。
4.为什么不选择其他Loss函数?
比如对比学习Loss、MSE Loss、CTC Loss,这些Loss函数,更多适用于嵌入模型训练、语音识别、分类任务,而我们的核心目标是自回归生成、指令遵循,交叉熵损失是最适配自回归大模型微调任务的,其他Loss函数无法很好地匹配我们的训练目标。
10. Prompt自动推荐模块用了哪些优化策略?有没有尝试过Prompt压缩或embedding表示的方式?
核心考点:考察你对Prompt工程的工程化落地能力,不是只会手写提示词,而是能做自动化、规模化的Prompt优化,同时看你对前沿的Prompt优化技术的了解程度,这也是大厂Agent岗的核心考察点。
核心踩坑点:只说用了Few-Shot示例,让大模型生成推荐的Prompt,没有完整的自动化优化策略;对Prompt压缩和embedding表示完全不了解,没有做过相关的尝试。
校招满分回答框架:
我们做Prompt自动推荐模块的核心目标,是解决两个痛点:一是人工手写Prompt,无法适配海量的用户query和多样化的业务场景,效率极低;二是不同的Prompt,对大模型的输出质量、任务成功率影响极大,人工很难为每一个query找到最优的Prompt。
这个模块的核心,是针对不同的用户query、不同的Agent子任务(规划、工具调用、反思、生成),自动推荐最优的Prompt模板,提升大模型的任务完成率,降低人工成本。
Prompt自动推荐模块的核心优化策略
我们围绕“准确率、效率、自迭代”三个核心,做了4层优化策略:
- 场景化分层路由策略,缩小推荐范围,提升准确率
我们先对所有的Prompt模板,做了场景化分类,分为:通用对话、工具调用、多步规划、知识问答、内容生成、反思校验6大类,每一类对应Agent的一个子任务模块。
用户query输入后,先通过意图识别模型,做场景分类和任务类型判断,直接路由到对应的Prompt模板库,先做粗粒度的过滤,缩小推荐范围,避免工具调用的query,匹配到通用对话的Prompt,从源头提升推荐的准确率。
2.基于语义匹配的动态Few-Shot推荐策略,适配长尾query
我们构建了高质量的Prompt效果示例库,每个示例包含:query场景、对应的最优Prompt、任务类型、效果指标(任务成功率、幻觉率、延迟)、业务场景标签。
推荐的时候,通过嵌入模型,把用户query和示例库中的query,生成对应的embedding向量,做语义相似度匹配,召回Top-K最相似的场景示例,把对应的最优Prompt,按照历史效果权重做组合,生成适配当前query的个性化推荐Prompt。
同时,我们给历史效果好、任务成功率高的Prompt,设置了更高的权重,优先推荐经过验证的、效果稳定的Prompt,避免推荐无效的Prompt。这个策略,让我们的长尾query的任务成功率,提升了18%。
3.A/B测试与自迭代优化闭环,让推荐效果持续提升
我们搭建了完整的Prompt效果自动化评估体系,对每一个推荐的Prompt,自动跟踪对应的任务成功率、幻觉率、输出格式准确率、推理延迟等核心指标。
基于这些指标,我们做了自迭代优化:效果好的Prompt,提升权重,加入核心示例库;效果差的Prompt,降低权重,逐步淘汰;同时,我们会定期用效果好的Prompt,自动生成新的变体Prompt,做小流量的A/B测试,把效果更优的变体,加入推荐库,形成完整的“推荐-评估-优化-迭代”闭环,不需要人工干预,就能持续提升推荐效果。
4.结构化Prompt模板的参数化适配,提升落地效率
我们把所有的Prompt模板,都拆分为「固定结构模块」和「可变参数模块」,固定模块包括:角色设定、任务目标、约束规则、输出格式;可变参数模块包括:工具列表、场景信息、Few-Shot示例、上下文内容。
自动推荐的时候,会根据用户query的场景、当前可用的工具、上下文信息,自动填充可变参数模块,生成完全适配当前场景的Prompt,不需要人工修改,大幅提升了Prompt的适配效率,同时保证了Prompt的结构一致性,降低大模型的输出错误。
关于Prompt压缩和embedding表示的尝试
这两个方向,我们都做了针对性的尝试和落地,效果非常明显,尤其是在Agent多轮对话的长上下文场景。
1. Prompt压缩的尝试
我们做Prompt压缩的核心目标,是减少Prompt的token占用,降低大模型的推理延迟,同时避免多轮对话后,上下文窗口被Prompt占满,核心做了3个方向的落地:
- 结构化冗余信息压缩:针对Prompt中的固定规则、角色设定、约束条件,我们做了极简优化,去掉所有冗余的修饰词、重复的描述,只保留核心的、必须的约束规则,同时用结构化的Markdown格式,让大模型能快速识别核心信息,最终在不降低效果的前提下,把基础Prompt的长度压缩了32%;
- 基于蒸馏的Prompt压缩:针对长Few-Shot示例,我们用大模型把多个示例的核心逻辑、规则要求,蒸馏成简短的结构化说明,替换掉冗长的示例,在保留引导效果的前提下,大幅减少了Prompt的token占用,比如原本5个长示例,占用800个token,蒸馏后的规则说明,只占用150个token,同时效果几乎没有下降;
- 多轮对话的动态Prompt压缩:针对Agent多轮对话场景,我们不会把完整的历史对话全部放入Prompt,而是用大模型对历史对话做摘要压缩,只保留和当前query强相关的核心信息、关键工具返回结果,注入Prompt,既保证了上下文的连贯性,又避免了多轮对话后Prompt长度爆炸,在10轮以上的长对话场景,能把Prompt长度压缩60%以上。
2. Prompt的embedding表示的尝试
我们主要做了两个方向的落地,分别用于Prompt推荐和模型推理:
- 基于Prompt embedding的相似度检索:我们把所有的Prompt模板,都通过嵌入模型,生成对应的固定维度的embedding向量,存入向量库。用户query进来后,先生成query的embedding,和Prompt模板的embedding做余弦相似度匹配,召回最适配当前query的Prompt。对比纯文本匹配,这种方式的语义匹配准确率更高,尤其是针对长尾、口语化的用户query,适配性提升非常明显;
- 基于软Prompt(Soft Prompt)的embedding表示:针对Agent的固定子任务,比如工具调用、规划模块,我们训练了对应的软Prompt前缀embedding——把离散的Prompt文本,转化为连续的embedding向量,直接注入模型的输入层,和正常的token embedding一起输入模型。
这种方式的优势非常明显:一是完全不占用上下文窗口的token空间,解决了硬Prompt长度受限的问题;二是训练后的软Prompt,效果比手写的硬Prompt更好,我们的工具调用模块,用软Prompt后,准确率提升了6%,同时完全不占用上下文token,非常适配Agent多轮对话的长上下文场景。
三、场景题与算法基础|大厂校招的必过门槛
11. 场景题:假如一个Agent 推理链路包含3个工具+高频请求,系统整体延迟较高,你会如何优化?
核心考点:考察Agent系统的全链路工程化优化能力,这是大厂非常看重的点——面试中能讲清原理,落地中能解决实际问题,尤其是淘天这种高并发的电商场景,延迟直接决定了用户体验和系统成本,这道题能完全区分“懂理论的学生”和“能落地的工程师”。
核心踩坑点:只说加缓存、提升机器配置,没有全链路的瓶颈定位思路,也没有分优先级的优化方案,讲不清每个优化方案的适用场景和投入产出比。
校招满分回答框架:
针对这个场景,我的核心优化思路是:先定位延迟瓶颈,再分优先级优化,优先做投入产出比最高的优化,整体分为「瓶颈定位→分阶段优化→兜底保障」三个部分,完整方案如下:
第一步:先做全链路延迟瓶颈定位,避免盲目优化
优化的前提,是先找到延迟的根因,我会通过链路追踪(Trace)工具,把整个Agent推理链路的每个环节的耗时,做全量拆解,拆分出每个环节的耗时占比:
用户query输入→意图识别与路由→规划推理→工具1调用→工具2调用→工具3调用→结果汇总→生成回答
核心定位两个问题:一是延迟瓶颈到底在大模型多次推理环节,还是工具调用环节,或是链路调度环节;二是高频请求下,有没有出现请求排队、服务实例不足、GPU利用率不足的问题。
定位清楚瓶颈后,再做针对性的优化,而不是盲目加机器、加缓存。
第二步:分优先级做全链路优化,优先做投入产出比最高的优化
按照投入产出比从高到低,分为6个层面优化,覆盖从业务链路到基础设施的全流程:
1. 最高优先级:业务链路与调度逻辑优化(零成本,效果立竿见影)
这一步不需要改代码、加资源,只需要优化业务链路逻辑,就能带来最直接的延迟下降,核心优化点:
- 串行改并行,压缩链路耗时:拆解3个工具的依赖关系,如果工具之间没有强依赖(不需要前一个工具的返回结果作为后一个工具的入参),直接把串行调用改为并行调用。比如3个工具串行调用,每个耗时200ms,总耗时600ms,并行后总耗时直接降到200ms左右,这是最直接的延迟优化;
- 前置短路逻辑,避免无效执行:在链路最前端,加入规则过滤和意图识别,判断用户query是否需要调用全部3个工具,比如只需要调用1个工具就能完成的任务,直接短路后续的工具调用和推理环节,完全跳过无效的链路执行;
- 链路轻量化裁剪,适配高频场景:针对高频的标准化场景,去掉链路中不必要的反思、多轮校验环节,用轻量化的固定模板,替代完整的Agent规划推理链路。比如高频的查询场景,直接用固定的工具调用模板,不需要大模型做多次规划推理,直接调用工具返回结果,把大模型的推理次数从多次降到1次,甚至0次。
2. 第二优先级:缓存策略优化(高频场景核心优化,成本极低,效果显著)
针对高频请求场景,缓存是降低延迟的核心手段,我会设计三级缓存架构,覆盖全链路的可缓存节点:
- 第一级:端到端结果缓存:针对高频的、标准化的、数据实时性要求不高的用户query,直接缓存最终的回答结果,用户请求进来后,直接返回缓存结果,完全跳过整个推理和工具调用链路,延迟从几百ms降到几ms;
- 第二级:大模型推理结果缓存:针对相同的query、相同的场景,把大模型生成的规划链路、工具调用指令缓存起来,不需要大模型重新推理,直接复用规划结果,减少大模型的推理耗时;
- 第三级:工具调用结果缓存:把相同入参的工具调用结果缓存起来,TTL根据数据的实时性要求设置,比如实时性要求不高的场景,TTL设为5分钟,高频请求下,工具调用的缓存命中率能到80%以上,直接跳过工具调用环节。
同时,针对热点query,做缓存预热,提前把热点结果预热到缓存中,避免缓存击穿,提升高峰期的缓存命中率。
3. 第三优先级:大模型推理环节优化(针对推理耗时高的核心瓶颈)
如果定位到延迟瓶颈在大模型推理环节,核心优化点:
- 模型轻量化,用小模型替代大模型:针对Agent的规划、工具调用环节,不用大尺寸的通用大模型,换成经过场景微调的轻量化小模型,比如用7B的微调模型,替代72B的通用模型,推理耗时能降低70%以上,同时因为做了场景微调,工具调用、规划的准确率不会下降,甚至更高;
- 推理框架与参数优化:用vLLM、TensorRT-LLM等高性能推理框架,替代原生的Transformers推理,能把推理吞吐量提升几倍,延迟降低50%以上;同时降低大模型的推理温度(Temperature)、Top-P、Max Tokens,减少模型的推理采样耗时,开启KV缓存,针对多轮对话场景,复用之前的KV缓存,减少重复计算;
- 批量推理优化:针对高频请求,用批量推理(Batching)的方式,把多个用户的请求合并成一个batch,一起做推理,大幅提升GPU的利用率,降低单请求的平均延迟;
- Prompt轻量化优化:用前面提到的Prompt压缩、软Prompt的方式,减少Prompt的token长度,token长度越短,推理耗时越低。
4. 第四优先级:工具调用环节优化(针对工具调用耗时高的瓶颈)
如果定位到延迟瓶颈在工具调用环节,核心优化点:
- 工具接口性能优化:和工具提供方配合,优化工具接口的性能,比如给接口加本地缓存、优化数据库查询语句、建立索引、提升接口的并发能力,降低接口的响应耗时;
- 网络传输优化:把Agent服务和工具接口,部署在同一个可用区、同一个内网集群,减少跨区域、跨公网的网络传输耗时,比如跨区域调用耗时100ms,同区域内网调用能降到10ms以内;
- 工具返回结果轻量化:针对高频调用的工具,做轻量化改造,让工具只返回Agent需要的核心字段,去掉无关的冗余字段,减少数据传输和解析的耗时。
5. 第五优先级:基础设施与架构优化(兜底优化,针对高并发场景)
- 服务弹性扩缩容:针对高频请求的高峰期,做服务的自动弹性扩缩容,避免服务实例不足,导致请求排队延迟;
- 分布式部署与负载均衡:把Agent服务、推理服务、工具服务做分布式部署,通过负载均衡,把请求均匀分发到各个实例,避免单实例压力过大,导致延迟升高;
- 服务降级与熔断:针对高峰期的极端场景,设计服务降级策略,比如关闭非核心的反思、校验环节,用轻量化的链路替代完整链路;同时加入熔断机制,当某个工具调用耗时过高、失败率过高时,直接熔断,用兜底策略返回结果,避免整个链路被拖垮。
第三步:优化效果验证与持续迭代
每做一个优化动作,都要通过全链路压测,验证延迟优化的效果,同时监控任务成功率、准确率有没有下降,不能为了降延迟,牺牲核心效果。同时建立持续的监控体系,跟踪全链路的延迟变化,持续优化。
12. 代码:岛屿数量
核心考点:大厂校招算法题的超高频题,中等难度,核心考察图的遍历、DFS/BFS算法的掌握,边界条件的处理能力,阿里、腾讯、字节等大厂的校招算法面,几乎都会考这道题。
校招面试满分解答:
题目描述
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。此外,你可以假设该网格的四条边均被水包围。
解题核心思路
这道题的本质,是求二维网格中连通的’1’的块的数量,连通的定义是上下左右四个方向相邻,属于图的连通分量问题,标准解法有两种:深度优先搜索(DFS)、广度优先搜索(BFS)。
核心逻辑:遍历网格中的每一个单元格,如果遇到’1’,说明找到了一个岛屿的起点,岛屿数量+1,然后通过DFS/BFS,把和这个’1’连通的所有’1’都标记为’0’(淹没),避免重复计数,直到遍历完整个网格。
解法一:深度优先搜索(DFS)(面试最常用,代码最简洁)
class Solution:
def numIslands(self, grid: list[list[str]]) -> int:
if not grid or not grid[0]:
return 0
rows, cols = len(grid), len(grid[0])
island_count = 0
# 深度优先搜索,把当前连通的陆地全部淹没(标记为0)
def dfs(r, c):
# 边界条件:超出网格范围,或者当前位置不是陆地,直接返回
if r < 0 or r >= rows or c < 0 or c >= cols or grid[r][c] == '0':
return
# 把当前陆地标记为0,避免重复遍历
grid[r][c] = '0'
# 遍历上下左右四个方向
dfs(r + 1, c)
dfs(r - 1, c)
dfs(r, c + 1)
dfs(r, c - 1)
# 遍历整个网格
for r in range(rows):
for c in range(cols):
if grid[r][c] == '1':
# 找到一个岛屿,数量+1
island_count += 1
# 淹没整个岛屿
dfs(r, c)
return island_count
解法二:广度优先搜索(BFS)(避免DFS的栈溢出问题,适合超大网格)
from collections import deque
class Solution:
def numIslands(self, grid: list[list[str]]) -> int:
if not grid or not grid[0]:
return 0
rows, cols = len(grid), len(grid[0])
island_count = 0
# 上下左右四个方向
directions = [(1, 0), (-1, 0), (0, 1), (0, -1)]
for r in range(rows):
for c in range(cols):
if grid[r][c] == '1':
island_count += 1
# 把当前陆地标记为0,加入队列
grid[r][c] = '0'
q = deque()
q.append((r, c))
# 广度优先搜索
while q:
cur_r, cur_c = q.popleft()
# 遍历四个方向
for dr, dc in directions:
new_r, new_c = cur_r + dr, cur_c + dc
# 判断是否是有效陆地
if 0 <= new_r < rows and 0 <= new_c < cols and grid[new_r][new_c] == '1':
# 标记为0,加入队列
grid[new_r][new_c] = '0'
q.append((new_r, new_c))
return island_count
复杂度分析
- 时间复杂度:O(M×N),其中M是网格的行数,N是网格的列数,每个单元格最多被遍历一次;
- 空间复杂度:O(M×N),最坏情况下,整个网格都是陆地,DFS的递归栈深度/BFS的队列长度,会达到M×N。
面试注意事项
- 先处理边界条件:网格为空、网格行为空的情况,直接返回0;
- 标记访问过的陆地:必须把遍历过的’1’标记为’0’,不能用额外的visited数组,否则会增加空间复杂度,面试官会追问优化;
- 四个方向的遍历:不要漏掉任何一个方向,同时注意边界判断,避免数组越界;
- 面试官大概率会追问:DFS和BFS的区别?什么情况下用BFS?(答案:DFS代码简洁,但是网格过大时,会出现递归栈溢出;BFS用队列实现,不会有栈溢出问题,适合超大网格)
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献193条内容
已为社区贡献193条内容

所有评论(0)