llm+agent,使用与 OpenAI 兼容的 API 格式
文章目录
- LLM + Agent 是什么
-
- 信息流
-
- LLM 本身是无状态的处理器和Agent 的“记忆“,怎么理解
-
- 网页版的 ChatGPT 或 Claude 本身就是一个封装好的 Agent 系统。
- 如果真的“只有 LLM”会怎样?
- agent 记忆
- Agent 是如何被写出来的。记忆?自动拼接上下文?什么时候查询数据库?什么时候调用”LLM?什么时候不在调用llm?
- MCP(Model Context Protocol,模型上下文协议)
- agent怎么知道有哪些工具?llm怎么知道有哪些工具
- Agent 怎么知道发给哪个 LLM? 给agent配置哪个llm就用哪个
- 怎么实现工具才能让agent调用
- API(Application Programming Interface,应用程序接口)
- API 交互标准,OpenAI 定义了一套如何与大模型对话的接口规范(如 /v1/chat/completions)
- OpenAI 在 2023 年之后给 AI 应用开发定义了一套“事实标准(de-facto standard)”
- 现在 AI 行业的架构是什么样
- Agent框架:典型功能:工具调用,记忆,任务规划等
LLM + Agent 是什么
“LLM + Agent”,其实是目前 AI 领域很火的组合,它把 大语言模型(LLM, Large Language Model) 和 助手/智能体(Agent) 的能力结合起来,让模型不仅“会说”,还“会做”


信息流



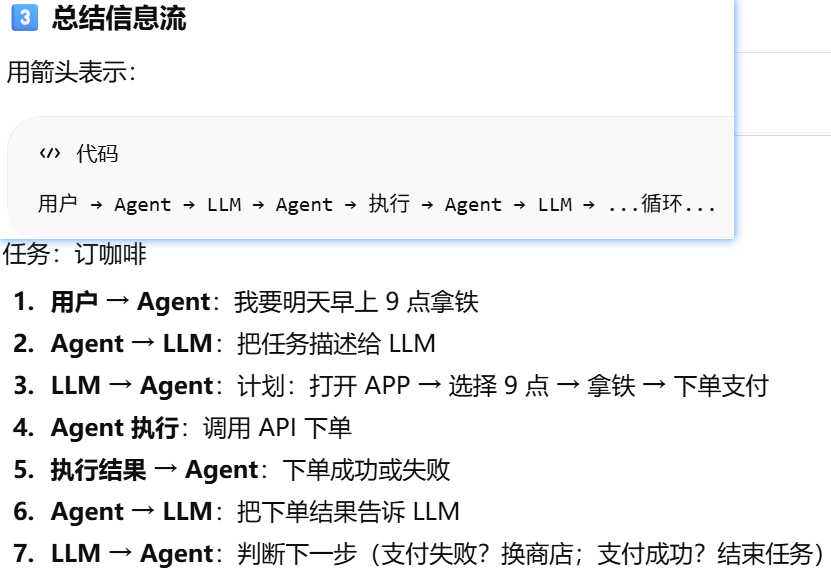
LLM 本身是无状态的处理器和Agent 的“记忆“,怎么理解



网页版的 ChatGPT 或 Claude 本身就是一个封装好的 Agent 系统。



如果真的“只有 LLM”会怎样?

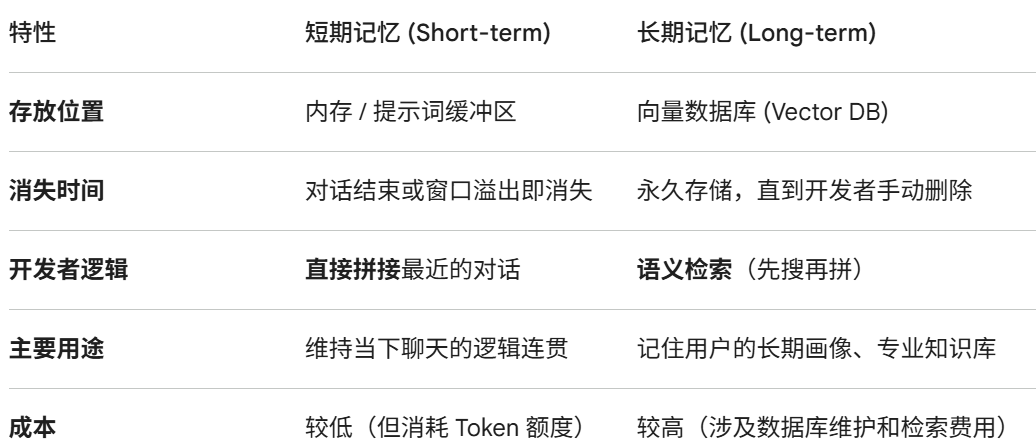
agent 记忆


agent短期记忆和长期记忆




# 1. 接收到用户的新问题
user_input = "我去年在上海买的那把雨伞是什么颜色的?"
# 2. 调取【短期记忆】:看看刚才咱们聊了啥
short_term_context = memory_cache.get_recent_chat(limit=5)
# 结果发现:刚才在聊今天的天气,没提到雨伞。
# 3. 触发【长期记忆】检索:因为短期记忆里找不到“雨伞”
# 开发者逻辑:如果短期没结果,就去翻“向量数据库”这个大档案柜
long_term_record = vector_db.search(query="上海 雨伞 颜色", top_k=1)
# 结果发现:2025年的一条记录显示“在上海买了一把【蓝色】折叠伞”。
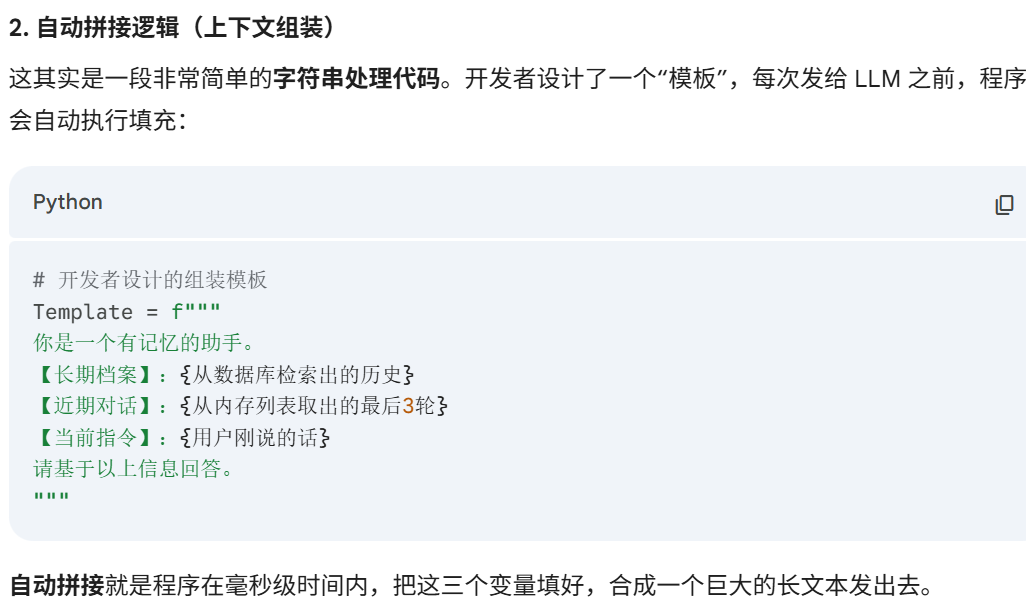
# 4. 【主动管理】:开发者设计的“拼装逻辑”
# Agent 把搜到的档案、刚才的话、和你的新问题拼在一起
final_prompt = f"""
你是 AI 助手。
已知背景(长期记忆):{long_term_record}
最近对话(短期记忆):{short_term_context}
用户的新问题:{user_input}
请根据以上信息回答。
"""
# 5. 最后把这个“大包”发给 LLM(天才厨师)
response = LLM.generate(final_prompt)
# 6. 【存入逻辑】:开发者决定这句话值不值得记一辈子
if "记住" in user_input or "偏好" in user_input:
vector_db.save(user_input) # 存进档案柜

agent记忆存在哪里






举例:假设你有一个包含 100 个文件的项目,你想让 AI 帮你改一个登录 Bug




Agent 是如何被写出来的。记忆?自动拼接上下文?什么时候查询数据库?什么时候调用”LLM?什么时候不在调用llm?
记忆

拼接历史上下文
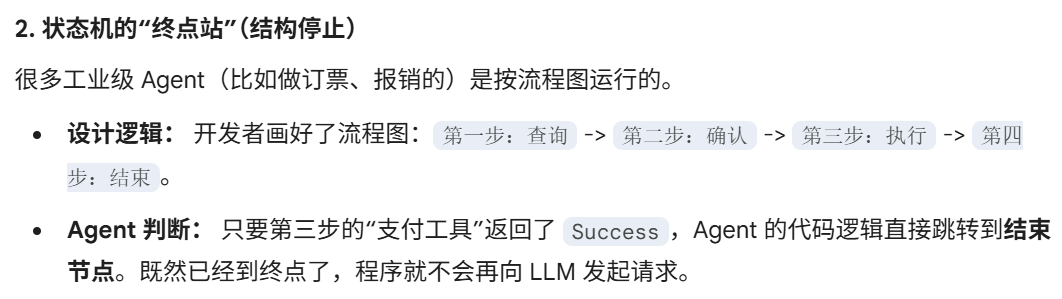
什么时候查询

什么时候调用llm



什么时候不在调用llm





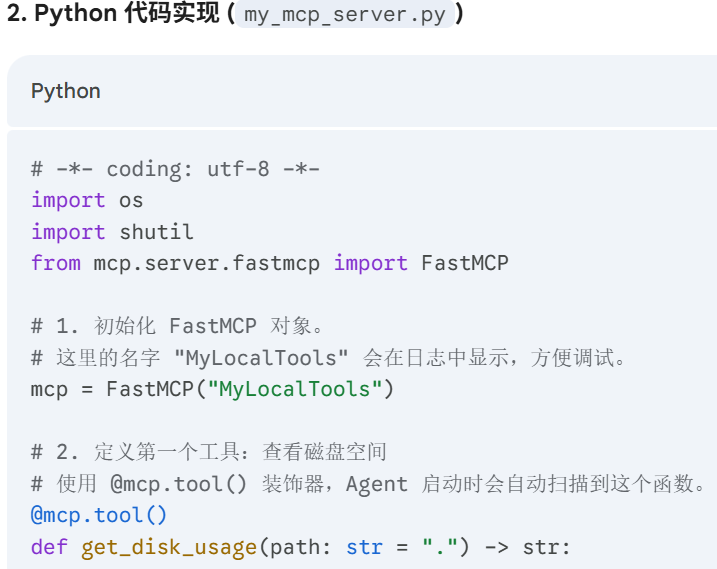
MCP(Model Context Protocol,模型上下文协议)





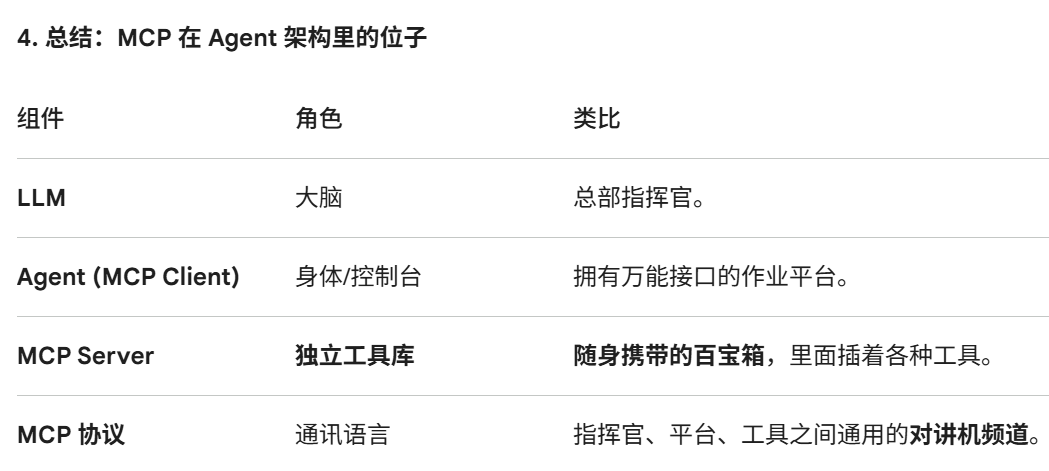
MCP 的核心架构:mcp客户端,mcp服务器,资源


MCP 实际上是一种基于 JSON-RPC 的通信


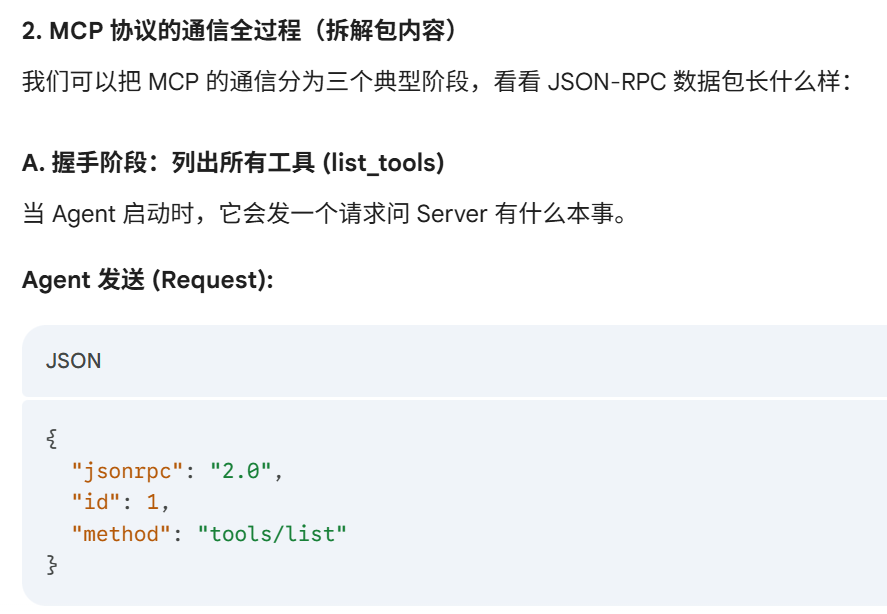
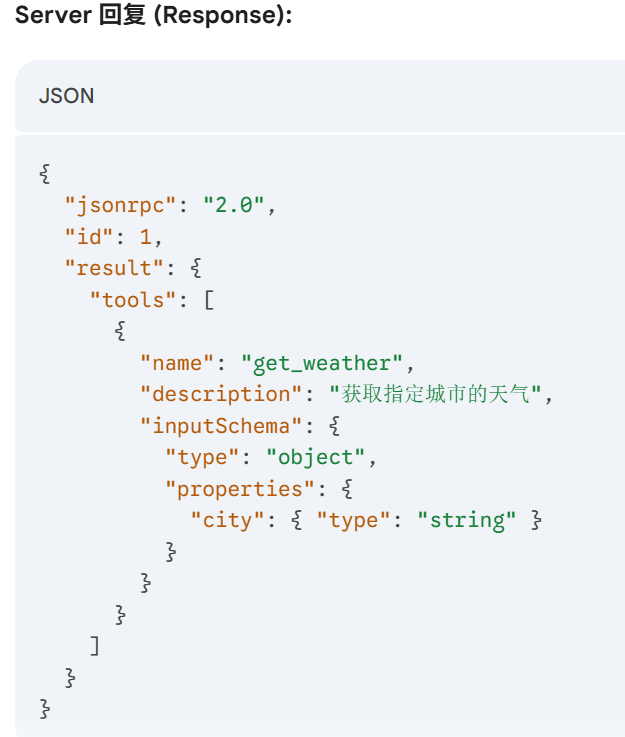
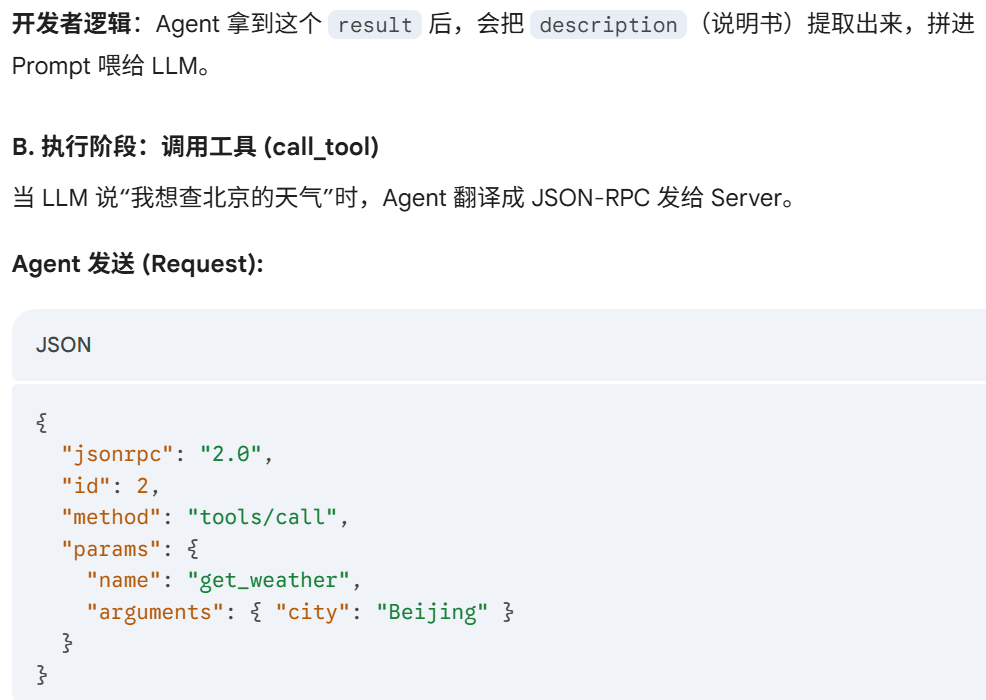



JSON-RPC 是什么




API 和 JSON-RPC 是什么


JSON-RPC 数据包的**“运输方式”**:stdin/stdout 或 HTTP











SSE (Server-Sent Events) 是一种“单向常连”技术。它允许服务器在建立连接后,像源源不断的流水一样,主动把数据推送到客户端(Agent),而不需要客户端反复询问






sse与普通http区别





流式(Streaming)是数据传输方式,SSE 是实现流式的一种技术









判断是否是MCP 客户端 (如支持mcp的Agent):







判定一个服务器是否为 MCP 服务器的“三个标准”



MCP 服务器的作用:MCP 是 Agent 和外部工具之间的桥梁/调度中心。如果工具在 MCP 上:直接调用函数。如果工具在外部服务:通过 HTTP / gRPC / RPC 调用

为什么 MCP 可以统一调用工具
统一注册:所有工具在 MCP 上注册,包含名字、接口类型、参数格式
统一调度:agent根据function_call,按照json_rpc格式,发送到mcp服务器,mcp服务器自动路由到对应工具
统一返回:把工具执行结果按照json_rpc的格式返回agent,agent解析后,把工具执行结果封装成 role=function 消息返回 LLM
安全与权限控制:MCP 可以限制哪些工具可调用






api/json-prc

agent怎么知道有哪些工具?llm怎么知道有哪些工具



agent调用工具怎么知道要输入哪些内容,哪些参数
Agent 是通过工具的参数 schema + LLM 语义理解,自动推断并填充工具参数的
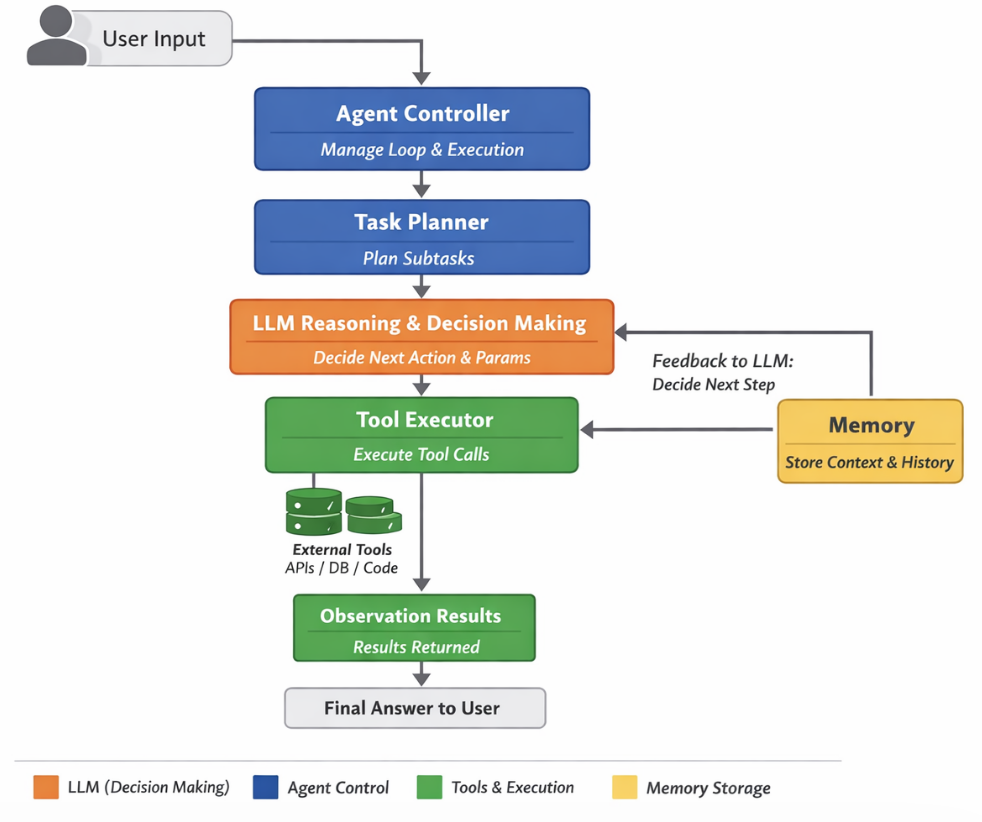
+--------------------+
| User |
+---------+----------+
|
v
+---------+----------+
| Agent Controller | ← 负责循环控制、判断是否继续执行
+---------+----------+
|
+--------+--------+
| Planner / Task | ← 负责拆解复杂任务、生成子任务
+--------+--------+
|
+--------v--------+
| LLM | ← **实际决策者**
| (Reasoning) | - 决定下一步做什么
| | - 选择调用哪个工具
| | - 填充工具参数
+--------+--------+
|
+---------v---------+
| Tool Executor | ← Agent执行层,负责调用工具
+---------+---------+
|
+---------v---------+
| Tools | ← 外部能力(API / DB / Python / File System)
+---------+---------+
|
+---------v---------+
| Observation | ← 工具返回结果,回传给 LLM
+---------+---------+
|
+---------v---------+
| Memory | ← Agent状态管理
| (short/long-term) | 记录上下文、中间结果
+-------------------+
|
+---------------------> 循环回 LLM



例子


{
"name": "get_weather",
"description": "Get weather information for a city",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "city name"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["city"]
}
}









Agent 怎么知道发给哪个 LLM? 给agent配置哪个llm就用哪个

Agent 发送请求到llm,需要 配置LLM 的哪些参数?
一般来说,Agent 通过 API 调用 LLM,需要提供 三个核心参数:
| 参数 | 作用 |
|---|---|
| Provider / Base URL | 就是模型运行在哪个服务器的地址,它通常指 LLM 提供商的 API 接口地址,告诉 Agent 要把请求发送到哪台服务器,让 LLM 收到任务, |
| API Key / Access Token | 身份验证,用来让 Agent 授权访问 LLM ,类似客户端要验证有资格访问服务器 |
| Model ID | 告诉服务器用哪个模型来处理请求,比如 gpt-5.2、claude-instant-1 |
| 可选参数 | max_tokens、temperature、top_p 等生成控制参数 |
Provider / Base URL

API Key / Access Token


Model ID


举例

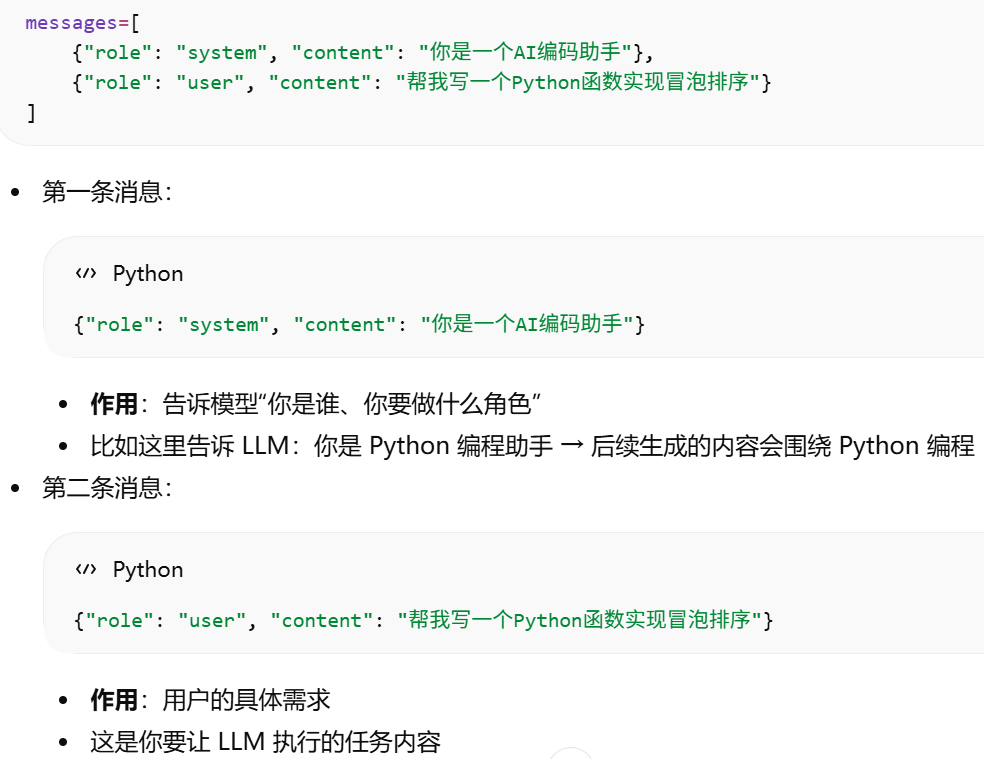
messages 列表 = Prompt,只是格式化成多条消息。system role = 设定模型身份/行为规则。user role = 用户输入/任务。assistant role 也是 Prompt(messages)的一部分,模型自身的角色,主要用于记录 LLM 自己之前的输出,让模型理解上下文、保持连贯性





怎么实现工具才能让agent调用








def mcp_executor(tool_call: dict) -> dict:
tool_name = tool_call["tool_name"]
params = tool_call.get("parameters", {})
# 找到对应工具
tool = next(t for t in mcp_tools if t["name"] == tool_name)
# 执行函数
try:
result = tool["func"](**params)
return {
"tool_name": tool_name,
"status": "success",
"result": result
}
except Exception as e:
return {
"tool_name": tool_name,
"status": "error",
"result": str(e)
}

tool/list 返回的内容,是 Schema 还是工具列表,以及谁生成 Schem






API(Application Programming Interface,应用程序接口)
API 的核心就是提供一套调用规则,让程序可以互相“说话”,互相调用,不管它们是在同一台电脑上,还是分布在不同的电脑、甚至不同城市的服务器上。程序之间沟通的接口和规则
广义理解:任何一种程序可以调用另一个程序功能的方式

本地调用(Local API / 同一台机器)
同一台电脑上的不同程序,本质上就像远程调用

IPC(Inter-Process Communication,进程间通信)

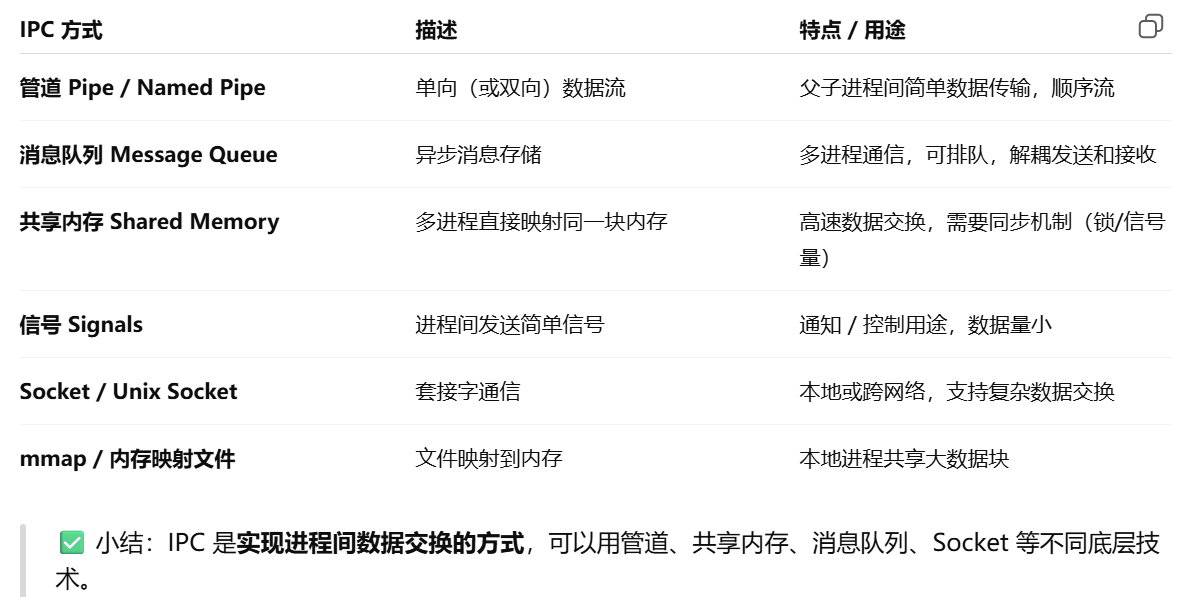
(1) 管道(Pipe / Named Pipe):一条只能本地用的单向通信通道,就像把两个程序用一条水管连起来


stdio 是程序的默认 I/O 接口,管道是操作系统提供的通信通道,它可以把一个程序的 stdio 接到另一个程序的 stdio 上,从而实现数据传递


(2) 共享内存(Shared Memory)

消息队列(Message Queue)

套接字(Socket / Unix Socket)就是 程序之间开通的一条“电话线”,通过它发送和接收数据





网络通信 vs 本地通信


远程调用(Remote API)

API 是怎么实现的?实现 API,本质是定义一套“规则和通道”,告诉其他程序如何访问你的功能。API 技术栈就是3层模型:API设计(接口长什么样)->通信协议->数据格式
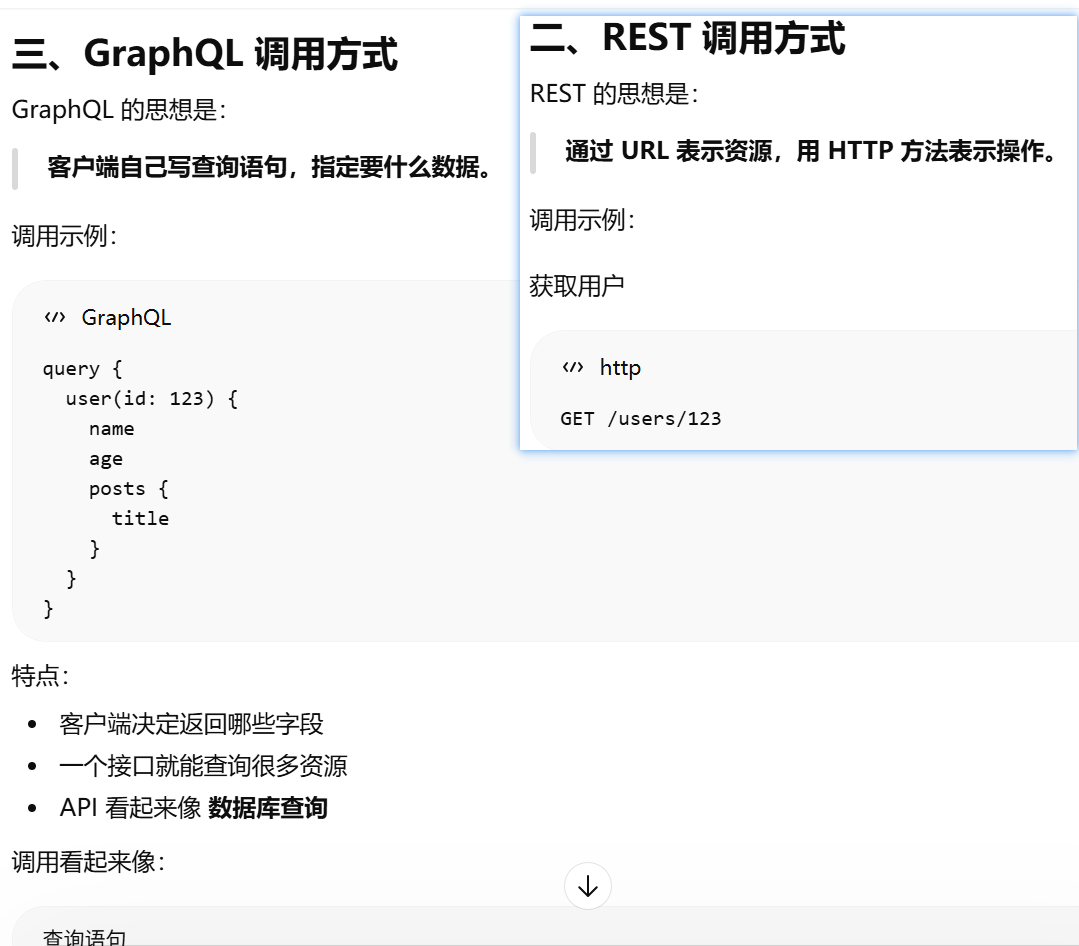
api 设计,接口长什么样。 REST、GraphQL、RPC是 三种 API 思想
REST、GraphQL、RPC是 三种 API 思想。规定 API 应该“怎么组织和表达功能”,但不规定具体技术细节


每种 API 思想对应的实现技术/框架
| API 思想 | 实现技术 / 框架示例 | 特点 |
|---|---|---|
| REST | Django REST Framework(Python)、Flask-RESTful(Python)、Spring Boot(Java)、Express.js(Node.js) | 用框架定义资源和操作接口,快速生成 REST API |
| GraphQL | Apollo Server(JavaScript)、Graphene(Python)、Hasura(自动生成 GraphQL API)、Absinthe(Elixir) | 提供 GraphQL 查询解析和执行能力,实现客户端指定字段的数据请求 |
| RPC | gRPC(Google)、Thrift(Apache)、JSON-RPC、XML-RPC | 提供远程函数调用接口,实现跨语言的服务调用 |

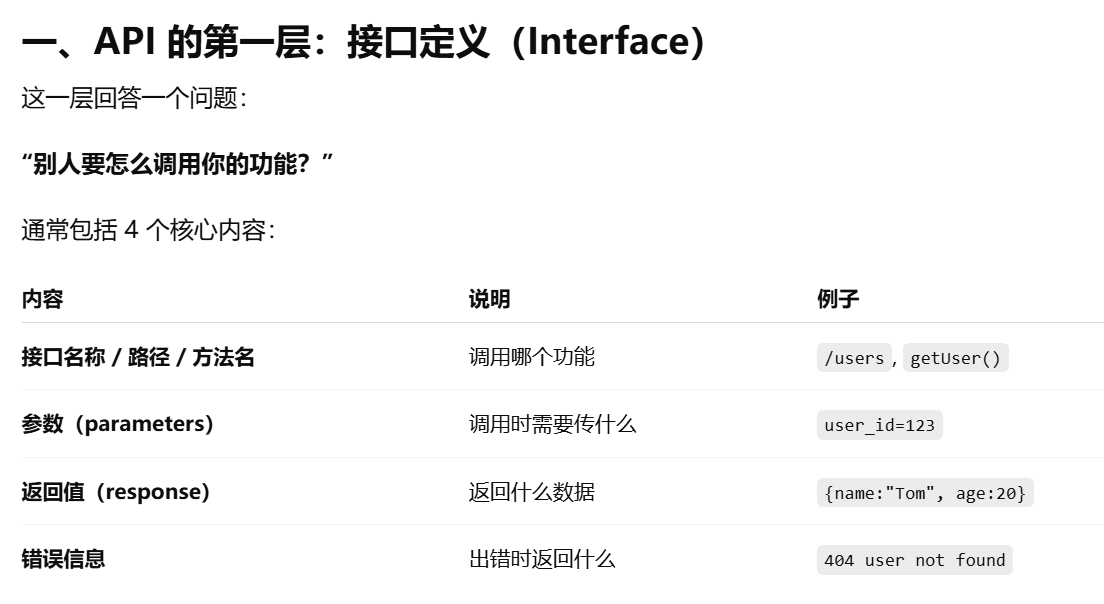
API 的第一层:接口定义(Interface),需要什么参数,返回什么数据等
第二层:通信协议(数据怎么在网络上传输)第三层:数据格式(数据怎么表示)
| API 思想 | 实现技术 / 框架 | 通信协议 | 数据格式 |
|---|---|---|---|
| REST | Django REST Framework、Flask-RESTful、Spring Boot、Express.js | HTTP / HTTPS | JSON / XML / YAML |
| GraphQL | Apollo Server、Graphene、Hasura、Absinthe | HTTP / HTTPS(POST 请求)、WebSocket(订阅)、 SSE | JSON |
| RPC | gRPC、Thrift、JSON-RPC、XML-RPC | gRPC → HTTP/2;Thrift → TCP/HTTP;JSON-RPC / XML-RPC → HTTP/HTTPS;Unix Socket / 管道 | Protobuf(gRPC)、自定义二进制(Thrift)、JSON / XML |

协议(Protocol)是什么?规定了两台计算机或程序之间如何通信、交换信息。怎么传输
通信协议按传输方式分为非流失传输和流失传输
| 分类 | 协议示例 | 特点 |
|---|---|---|
| 非流式 / 请求-响应 | HTTP / HTTPS、JSON-RPC / XML-RPC | 客户端发请求,服务器返回响应,通信一次结束 |
| 流式 / 持久连接 | WebSocket、SSE、gRPC(流模式) | 建立连接后可以持续传输数据,多次收发 |
| 协议 | 通信方向 | 持久连接 | 用途 | 特点 |
|---|---|---|---|---|
| WebSocket | 双向(客户端 ↔ 服务器) | 是,连接建立后一直保持 | 聊天、游戏、实时通知 | 客户端和服务器都可以随时发送消息;建立连接后数据传输开销小 |
| SSE | 单向(服务器 → 客户端) | 是,服务器可以持续推送 | 实时通知、新闻更新 | 客户端只能接收服务器推送,不能直接发数据;基于 HTTP |

三种 API 思想实现的api的调用方式
| API 思想 | API 长什么样 | 调用方式示例 | 核心特点 |
|---|---|---|---|
| REST | 资源 + URL | GET /users/123 |
操作资源 |
| GraphQL | 查询语句 | query { user(id:123){name} } |
查询数据结构 |
| RPC | 函数调用 | getUser(123) |
调用远程函数 |

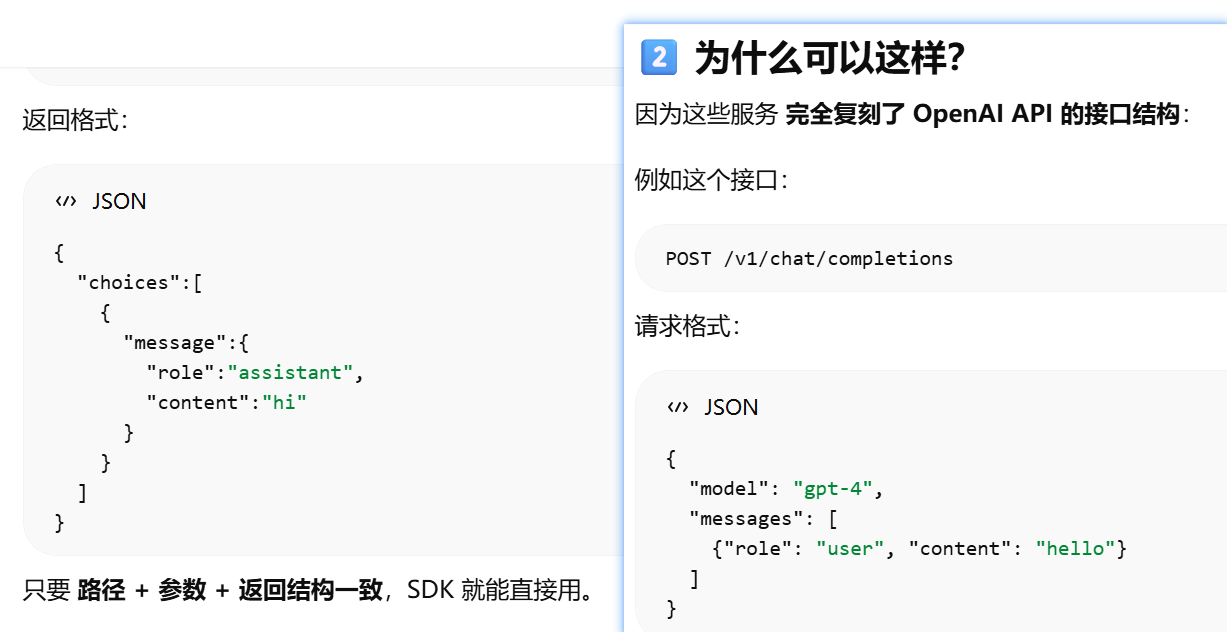
API 交互标准,OpenAI 定义了一套如何与大模型对话的接口规范(如 /v1/chat/completions)
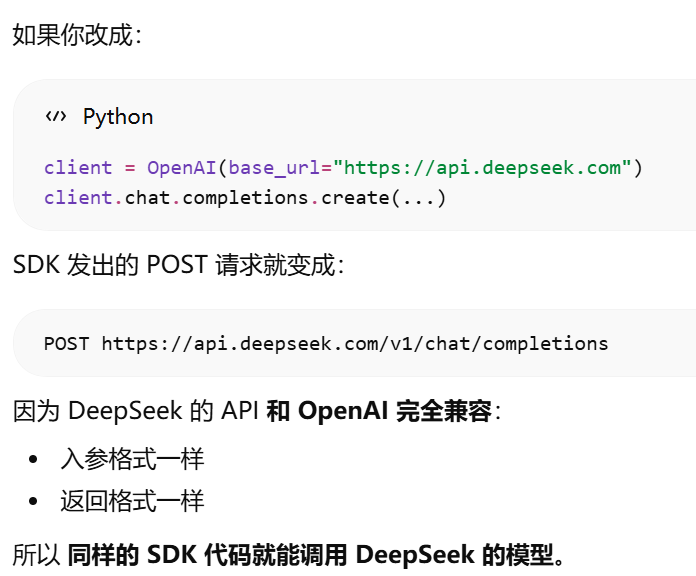
OpenAI 定义了一种“程序怎么调用大模型”的 API 写法,后来几乎所有模型公司都照着做了。
所以它被称为 事实标准(de facto standard)。




messages 里的角色有哪些
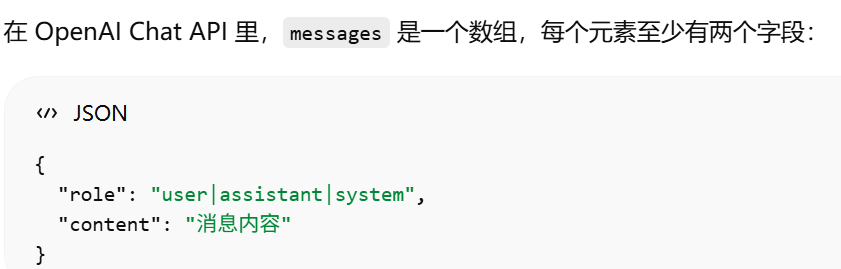
system

user

assistant

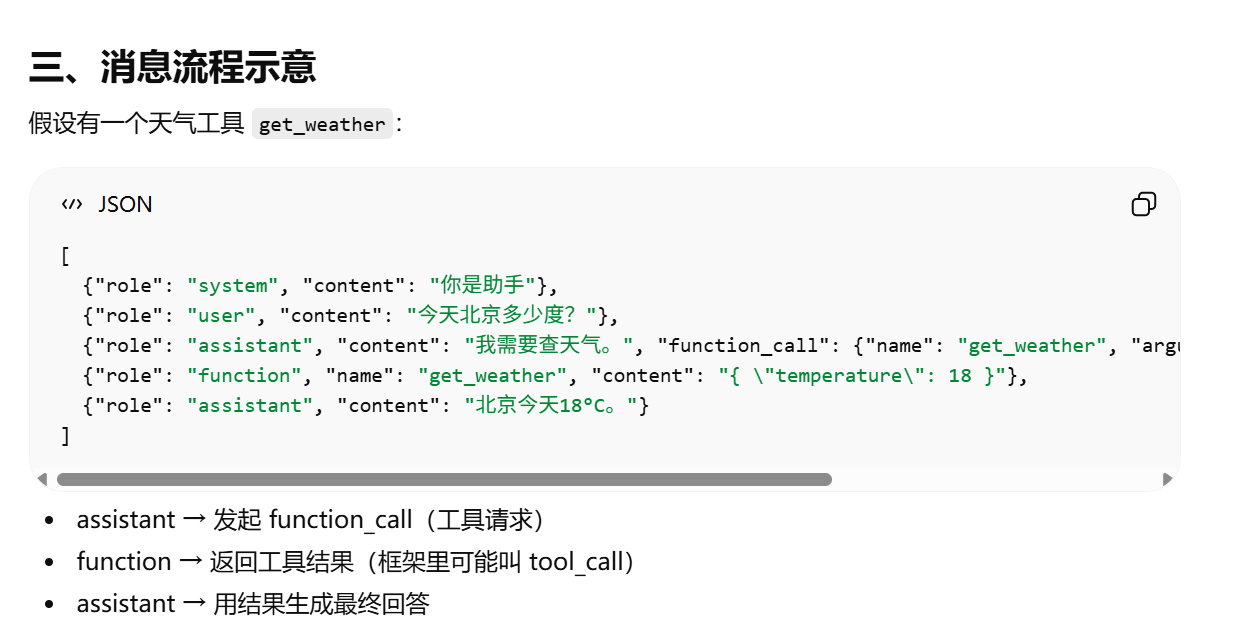
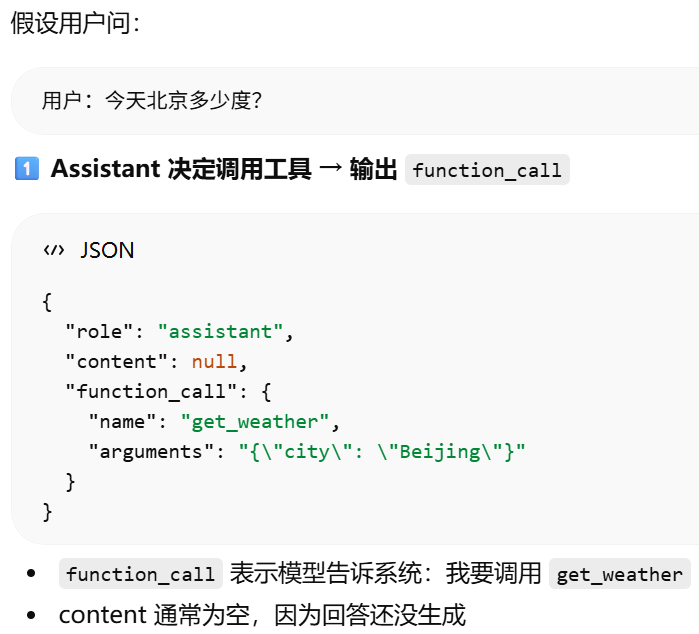
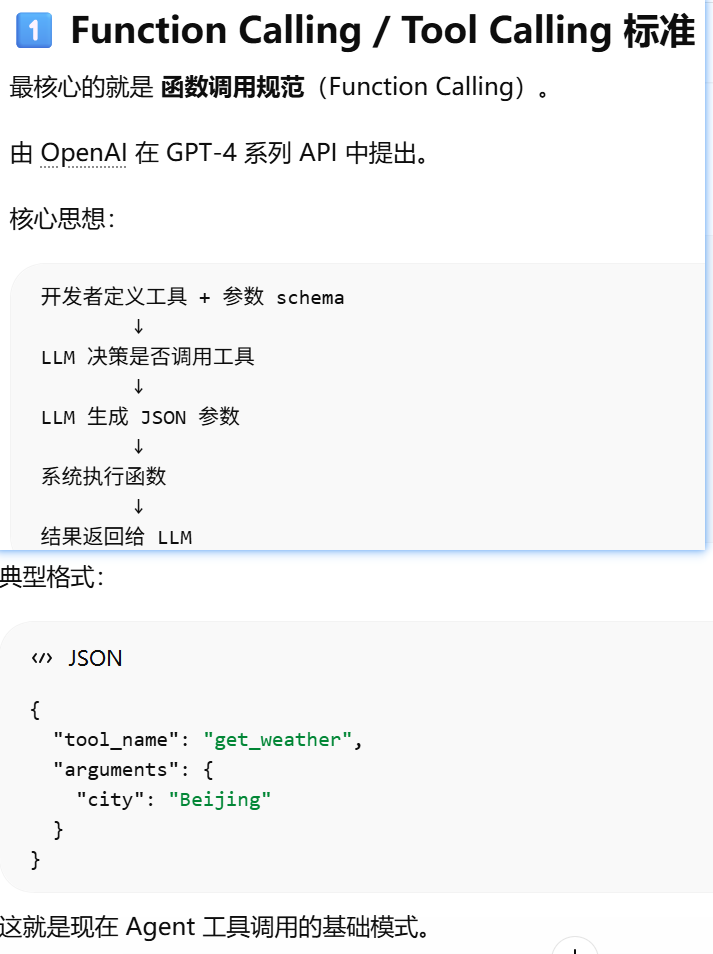
Function Call 的本质
{"role": "assistant", "content": "我需要查天气。",
"function_call": {"name": "get_weather",
"arguments": "{ \"city\": \"Beijing\" }"}},



role: function(可选) → 标识这是工具调用结果
工具调用的结果在 OpenAI 的 Chat API 里会以 role = “function” 的消息形式返回给模型,模型再根据这个内容生成回答。
工具调用的结果不是直接文本,而是 role=function 的消息传回给模型,模型再把它整理成用户可读的回答。



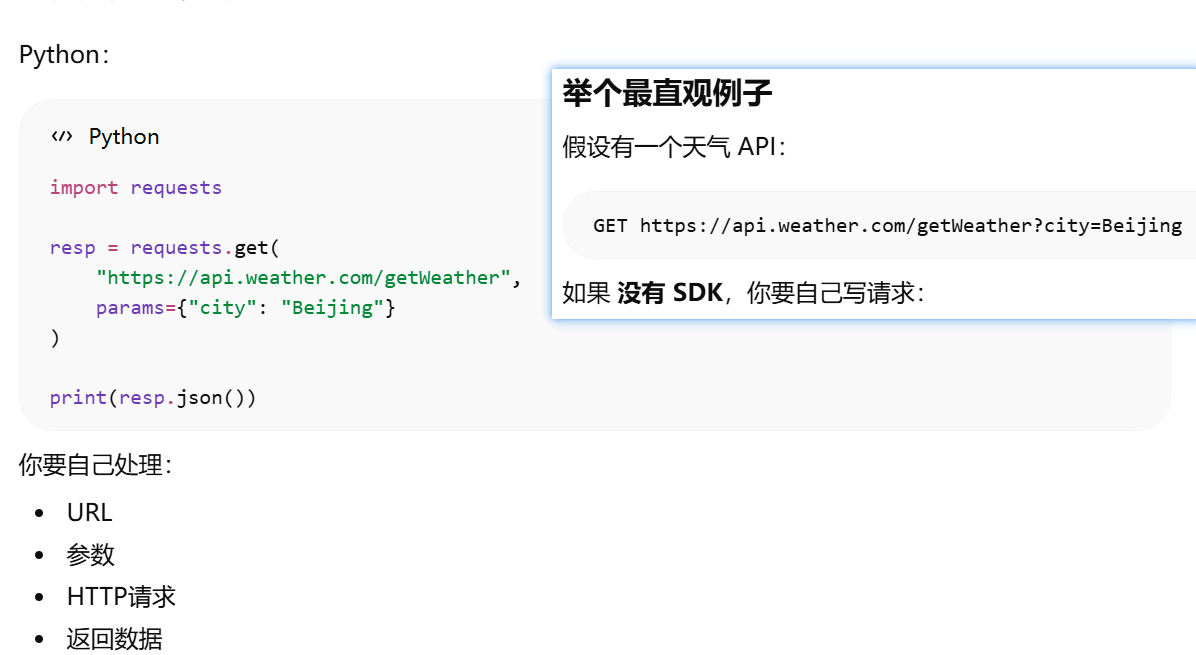
什么是 SDK Software Development Kit(开发工具包)


什么叫 “兼容 OpenAI API”?使用与 OpenAI 兼容的 API 格式,什么意思?OpenAI API标准?




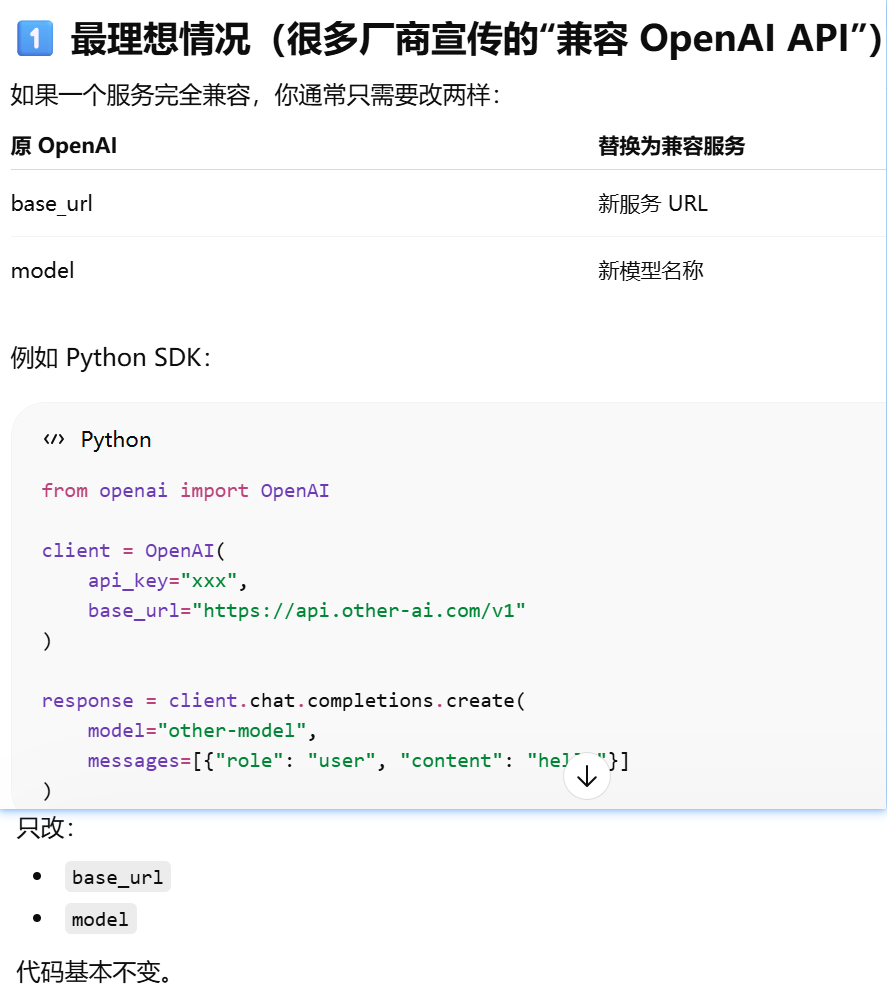

Model(模型参数)





“调用 API 不一定要写 URL”,URL 只是使用 HTTP REST 思想,定义的api的调用方式
为什么“写了 URL 就是调用 API”。属于http rest思想设计api后的调用方式

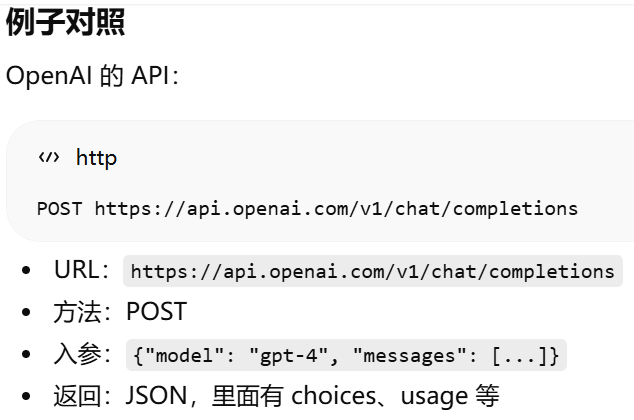
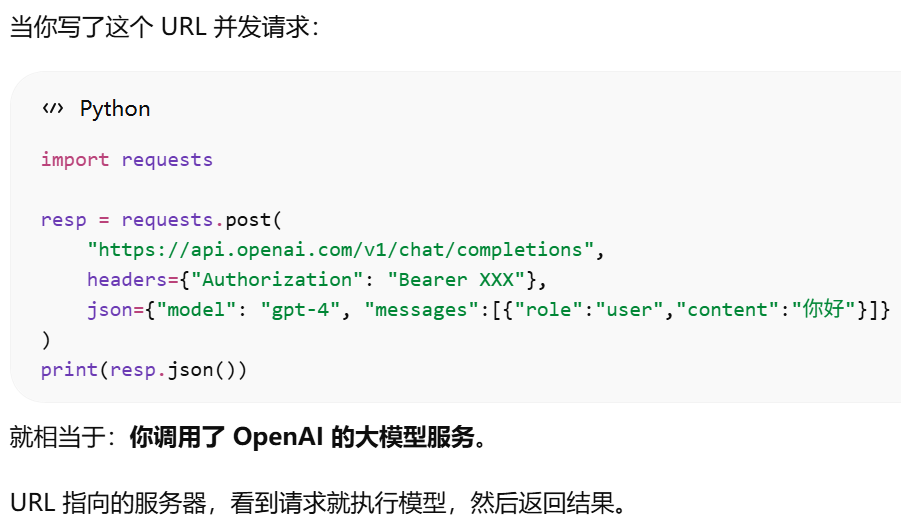
为什么 OpenAI SDK 换 URL 就调用别的 API?http rest形式调用api时,换url就是换api了。还可以使用openai sdk是因为别人的api的参数和返回结果与openai一样
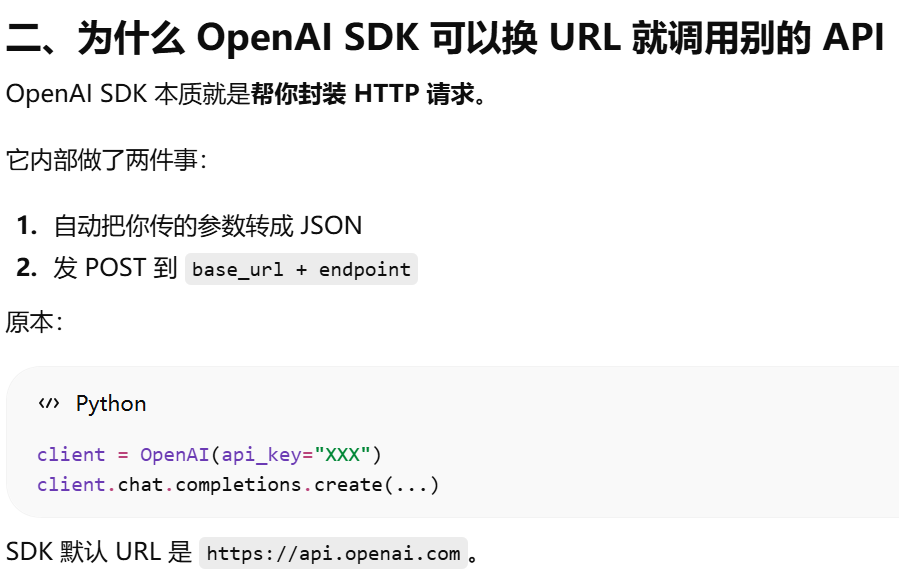

OpenAI 在 2023 年之后给 AI 应用开发定义了一套“事实标准(de-facto standard)”

OpenAI 推动的“工具调用(Tool Calling / Function Calling)接口标准”
Function Calling / Tool Calling 标准

JSON Schema 作为工具参数标准
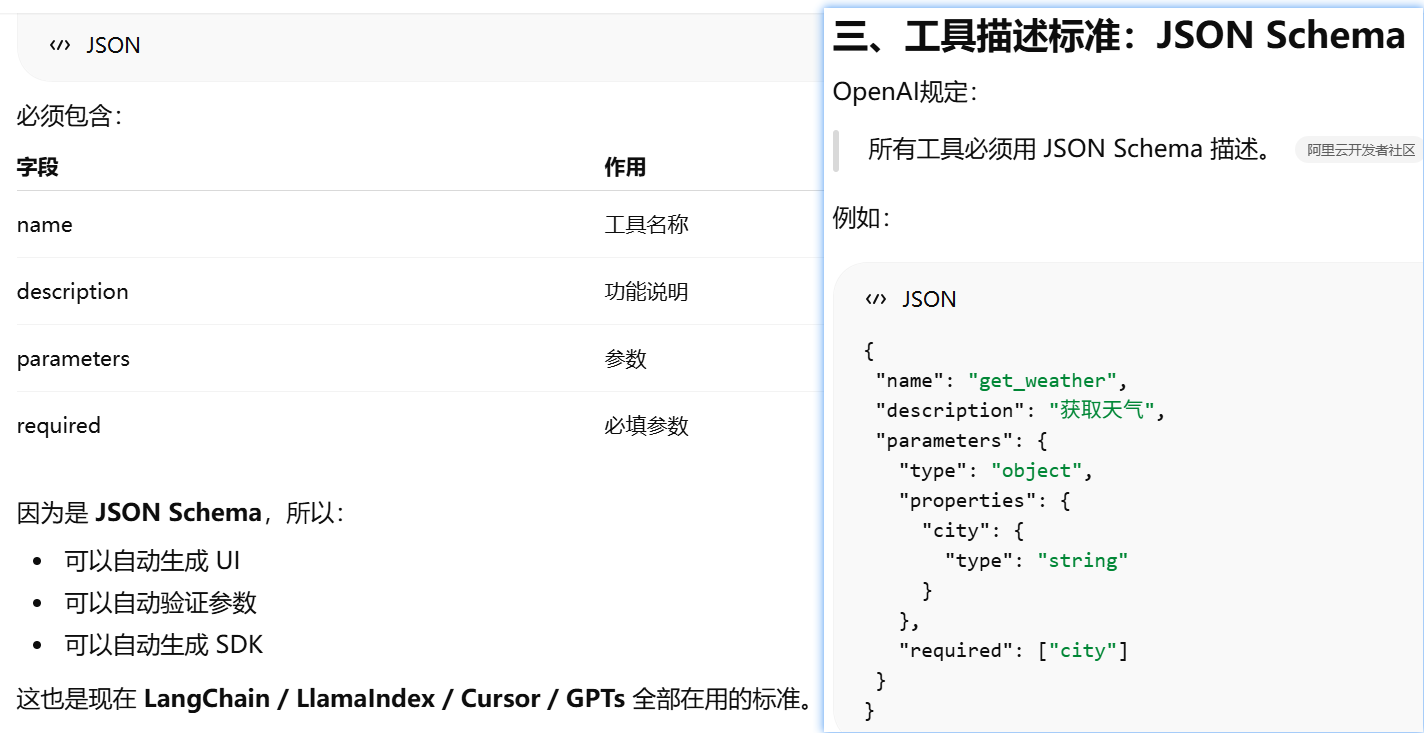
JSON Schema 在工程里的三个典型用途。很多人第一次看到会懵,因为它其实是在说 Schema = 一种机器可读的接口说明书


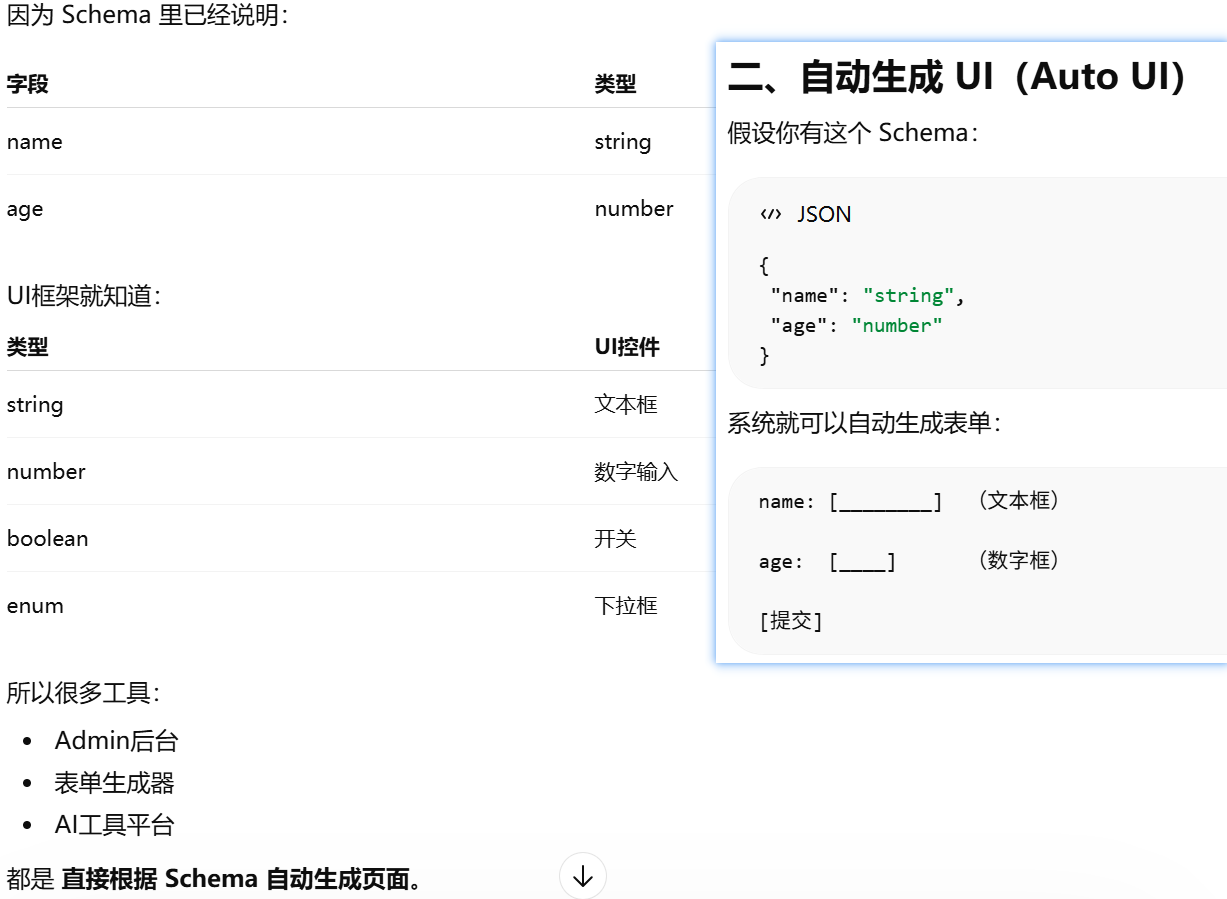
SDK = Software Development Kit(软件开发工具包)





Chat Message 协议,OpenAI 还定义了 对话消息结构标准

后来 Anthropic 提出了 Model Context Protocol (MCP)。把 OpenAI Function Calling 的思想扩展成跨工具协议

OpenAI后来又加了一条标准:模型输出必须符合指定 JSON Schema

现在 AI 行业的架构是什么样

AI应用层
(ChatGPT / AI产品 / AI SaaS)
↓
Agent框架层
(LangChain / LlamaIndex / CrewAI / AutoGPT)
↓
Agent协议层
(OpenAI Tool Calling / JSON Schema)
↓
模型层
(OpenAI / Anthropic / Google / Meta)
↓
算力层
(Nvidia GPU / 云计算)

目前 AI 行业形成了 两套标准体系:

Agent框架:典型功能:工具调用,记忆,任务规划等
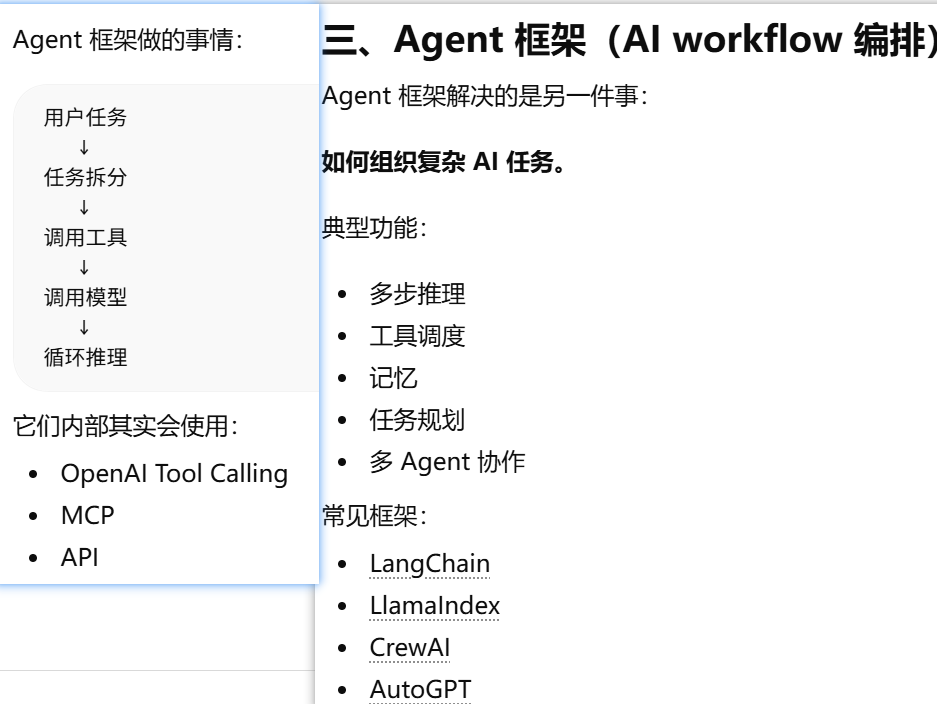
Agent 框架里的 任务规划(Planning)和任务拆分(Task Decomposition),核心其实不是复杂算法,而是 让 LLM 先当“规划器”再当“执行器”



任务拆分实现方式:Prompt-based Planning(最常见)


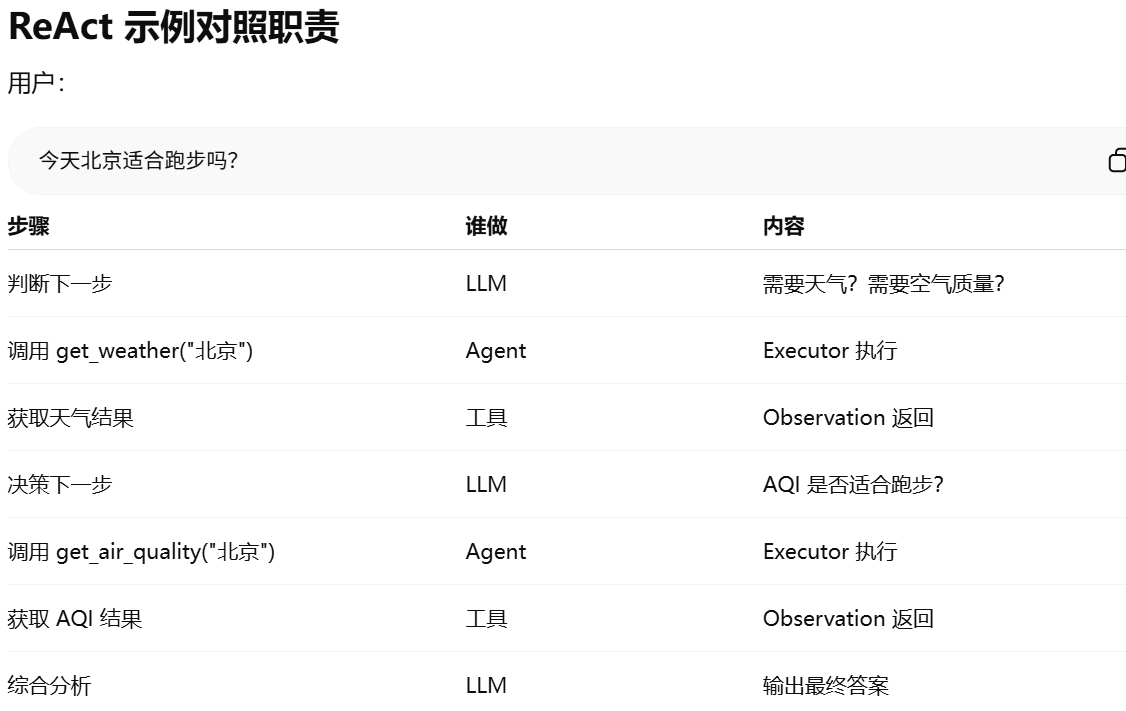
任务拆分实现方式:ReAct(最经典 Agent 方法)。Thought → Action → Observation
在 Thought → Action → Observation(ReAct 模式) 里:
Thought = LLM 内部生成的意图 / 下一步计划
Action = 调用工具(role=function)
Observation = 工具执行结果返回模型(role=function)
Observation 就是把 Action 执行后的结果返回给 LLM,让 LLM“看到”这个结果,再继续推理。




Agent 框架里的真实代码结构


任务拆分方式:Plan-and-Execute(更稳定)



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)