【腾讯云智能体】高中学科教学知识讲解问答
教学帮助并不是把一个问题直接交给模型,再等它生成一段回答那么简单。真正落到高中教学场景里,往往同时涉及学科差异、教材版本、知识范围、核心素养要求和难度层级等多个变量。只要这些条件没有提前约束好,输出就很容易从“基于教材的教学支持”滑向“泛化问答”,最后看起来内容很多,但实际并不适合直接用于教学。
尤其在学科类场景中,回答是否贴合教材、是否符合学段、是否匹配难度,往往比回答得多不多更重要。语文、数学、英语、物理、化学、生物、历史、地理、政治这九个学科本身就存在明显差异,如果再叠加教材版本和教学目标,单纯依赖模型自由发挥,结果很容易出现学科错位、版本不符或表达失焦的问题。因此,教学类智能体不能只追求“能回答”,更要做到“分流准确、知识有据、输出稳定”。
智能体介绍
这套工作流的定位非常明确,它不是一个泛化的教育聊天助手,而是一个围绕“高中学科教学帮助”场景构建的知识约束型工作流。用户输入教学需求后,系统不会直接进入自由问答,而是先根据 subject 判断当前属于哪一门高中学科,再结合 text_book 判断教材版本是否命中支持范围,命中后进入对应知识库检索节点,最后由专项大模型节点结合用户问题、教材配置、核心素养、难度等级和知识检索结果输出答案。整个过程的重点不是“让模型自由发挥”,而是“让模型在正确学科、正确教材和正确知识范围内回答”。
从整体能力来看,这个工作流围绕九个高中学科展开,分别覆盖高中语文、高中数学、高中英语、高中物理、高中化学、高中生物、高中历史、高中地理和高中政治。每个学科都拥有独立的教材判断分支、独立的知识检索节点和独立的大模型输出节点,保证不同学科不会共享同一条模糊链路。也就是说,它处理的不是一个笼统的“教学问答问题”,而是一组被提前标准化定义好的学科化、教材化教学帮助任务集合。
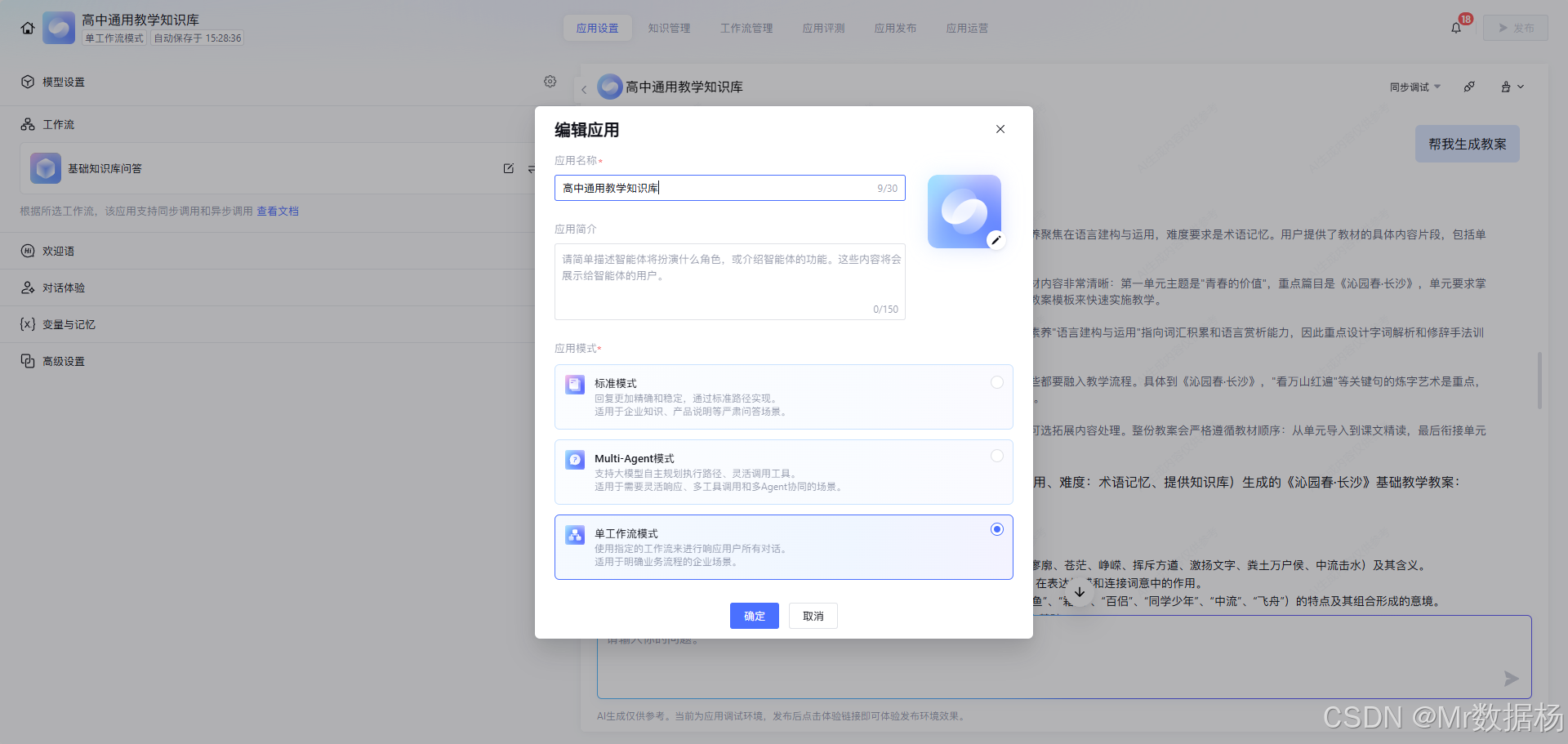
工作流在代码层的入口变量主要围绕教学帮助场景展开,核心贯穿字段包括 subject、text_book、book_name、important_quality、difficulty 以及用户原始问题。其中,subject 用于第一层学科分流,text_book 用于第二层教材版本判断,book_name 用于知识检索时锁定当前教材内容范围,important_quality 用于控制回答所强调的核心素养方向,difficulty 用于约束输出难度层级,而 SYS.UserQuery 则承接用户真实提问。这样的变量设计让整个链路不只是“知道用户问了什么”,还知道“应该以什么学科、什么教材、什么难度和什么教学目标来回答”。
核心模型
在模型配置层面,这套工作流采用的是“逻辑分流模型 + 专项生成模型”配合的设计方式。第一层条件判断节点使用意图识别模型完成学科路由,根据 API.subject 将请求分流到九个固定学科分支之一;第二层学科节点再结合 API.text_book 判断教材版本是否命中支持范围;命中后,由对应大模型节点基于用户问题和知识检索结果生成最终教学帮助内容。这样的设计思路并不是让一个模型从头到尾包办所有判断,而是先通过逻辑路由把问题送到正确链路,再由统一口径的大模型负责内容表达。
更关键的是,这里的大模型并不是孤立工作,而是建立在明确的教学参数和知识库结果之上。每个大模型节点的提示词结构基本一致,都会同时接入用户提问、教材配置、核心素养、难度等级和知识库内容。也就是说,模型在回答时并不是面对一个无边界的问题,而是在“学科 + 教材 + 难度 + 素养 + 检索知识”的多重约束下生成结果。这样做的价值在于,输出不再只是泛化解释,而更像一段可直接用于教学的目标化内容。
从模型分工上看,这套工作流真正追求的不是模型数量,而是模型职责清楚、回答口径稳定。逻辑节点负责判断“应该走哪条链路”,大模型节点负责回答“在当前约束下该如何组织内容”。对于教学场景来说,这种结构比单纯依赖一个大模型自由生成更稳,因为它能有效避免学科混淆、版本跑偏和难度失衡。
| 模型名称 | 使用位置 | 主要职责 | 配置价值 |
|---|---|---|---|
| Youtu/youtu-intent-pro | 一级条件判断节点 | 根据 subject 判断请求属于哪一门高中学科 |
提升学科分流准确率,减少错误路由 |
| Deepseek/deepseek-v3.2 | 二级学科判断节点 | 在学科内部根据 text_book 判断教材版本是否命中 |
保证学科链路进一步收束到可支持教材 |
| Deepseek/deepseek-r1-250528 | 九个学科专项 LLM 节点 | 结合问题、教材、素养、难度和知识库结果生成教学帮助内容 | 让输出建立在教学条件和知识依据之上 |
从表格可以看到,这套工作流的核心模型配置并不追求复杂堆叠,而是围绕“分流准确”和“回答有据”两个目标展开。逻辑模型解决的是入口分发问题,专项模型解决的是内容输出问题,二者配合之后,整条教学帮助链路就具备了较强的稳定性和可控性。
Node 节点
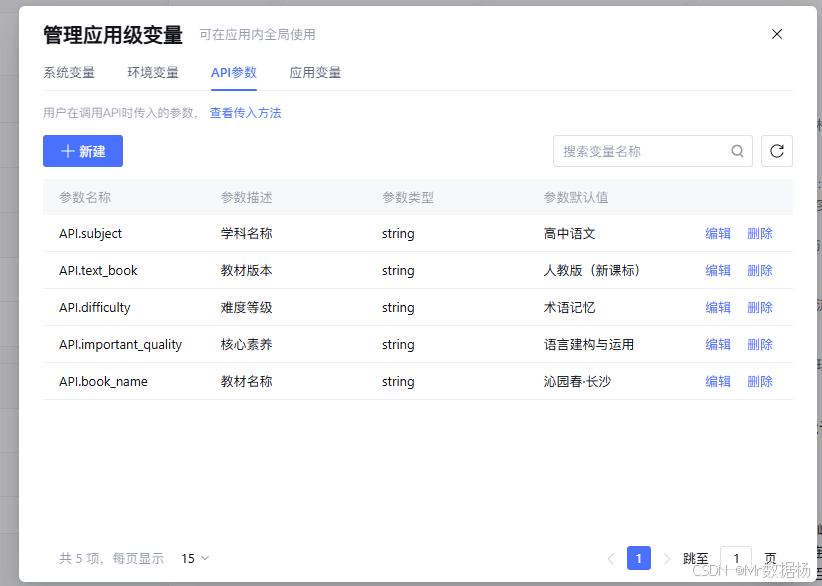
如果从节点编排角度来看,这套工作流采用的是一种很典型的“双层分流 + 学科执行 + 统一收口”结构。开始节点负责接收外部请求,第一层条件判断节点按学科分流,第二层各学科判断节点按教材版本进一步分支,命中后进入对应知识检索节点,再进入专项大模型节点生成结果,最后通过独立回复节点向外回传。这样的结构并不复杂,但层次非常清楚,尤其适合需要先判学科、再判教材、再输出内容的教学场景。
这种节点设计有两个很明显的优势。第一,它把“学科判断”和“教材判断”拆开了,而不是混在一个节点里一次完成,这样更利于维护和扩展。第二,它让每个学科都拥有相对独立的执行闭环,后续如果要补充新的教材版本、替换某一学科知识库或单独优化某个学科提示词,都可以在局部分支内完成,而不需要重构整条流程。对于需要逐步扩充教学能力的系统来说,这种结构非常实用。
从节点职责汇总表可以更直观地看出,整条链路中的每一类节点都只负责一件事。开始节点只承接输入,条件节点只负责分流,知识检索节点只负责召回,大模型节点只负责生成,回复节点只负责返回结果。正是这种低耦合设计,让工作流在面对九个学科分支时,依然能够保持结构清晰和执行稳定。
| 节点类型 | 节点名称 | 节点职责 | 结构作用 |
|---|---|---|---|
| 开始节点 | 开始 | 接收工作流请求并启动链路 | 统一输入入口 |
| 一级分流节点 | 条件判断1 | 根据 API.subject 路由到九个高中学科分支 |
学科路由中枢 |
| 二级分流节点 | 高中语文—高中政治 | 根据 API.text_book 判断是否命中当前学科支持教材 |
教材版本判断 |
| 知识检索节点 | 知识检索1—知识检索9 | 根据 book_name 检索对应学科教材知识内容 |
为教学回答提供知识依据 |
| LLM 节点 | 大模型1—大模型9 | 结合问题、教材、素养、难度和知识库结果生成教学帮助内容 | 学科专项输出 |
| 回复节点 | 回复2—回复10 | 将各学科专项结果统一回传 | 分支收口输出 |
| 回复节点 | 回复1 | 对学科或教材未命中等异常情况返回固定提示 | 异常兜底 |
| 结束节点 | 结束 | 完成流程收口并结束执行 | 统一终点 |
从这张节点汇总表可以发现,这套工作流虽然节点数明显比普通知识库问答多,但复杂度并不来自节点本身,而来自它对教学场景的精细拆分。真正有价值的地方不是“节点很多”,而是每一层节点都在为学科化、教材化和知识约束化服务。
工作流程
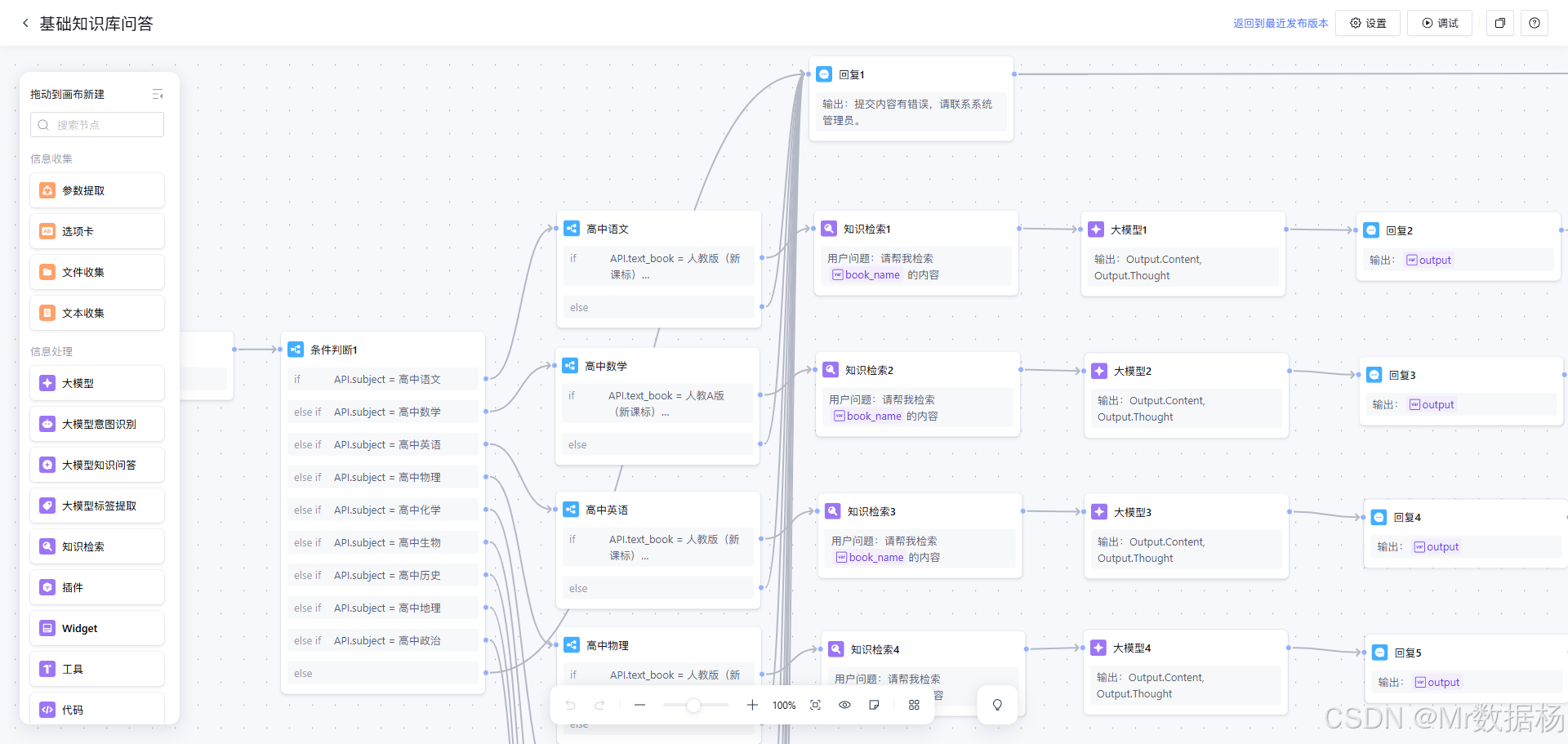
从工作流层面看,这套系统的核心不是“让模型回答教学问题”,而是“先判断学科和教材,再基于对应知识来回答教学问题”。因此,它的重点不在开放式对话能力,而在分流能力、知识命中能力和回答边界控制能力。工作流由开始节点接入请求后,首先进入一级条件判断节点,根据 API.subject 在九个学科中命中一个固定分支;命中后再进入对应学科的二级判断节点,根据 API.text_book 判断教材版本是否符合当前支持范围;教材命中后进入知识检索节点,以“请帮我检索 {{book_name}} 的内容”为统一查询模板完成召回;随后专项大模型节点结合 SYS.UserQuery、text_book、important_quality、difficulty 和检索知识生成结果;最后通过回复节点统一回传并在结束节点收口。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 请求接入 | 接收用户教学需求及相关参数并启动工作流 | 开始 |
| 2 | 学科分流 | 根据 subject 将请求路由到九个高中学科之一 |
条件判断1 |
| 3 | 教材判断 | 在目标学科内根据 text_book 判断教材版本是否命中 |
高中语文—高中政治 |
| 4 | 知识检索 | 根据 book_name 检索当前学科教材相关内容,统一查询模板为“请帮我检索 {{book_name}} 的内容” |
知识检索1—知识检索9 |
| 5 | 教学生成 | 结合问题、教材配置、核心素养、难度等级和知识库结果生成回答 | 大模型1—大模型9 |
| 6 | 结果回传 | 将模型结果作为最终输出返回给调用端 | 回复2—回复10 |
| 7 | 异常兜底 | 当学科或教材未命中支持范围时返回固定提示 | 回复1 |
| 8 | 流程收口 | 结束执行并完成输出闭环 | 结束 |
结合链路结构来看,这套流程本质上是在把“教学帮助”拆成两层判断和一层生成。第一层解决“你问的是哪门学科”,第二层解决“这门学科下是不是支持当前教材”,第三层才是“在这些前提下该如何回答”。这样的设计非常关键,因为它让回答的前提条件都在流程层提前确定下来,而不是全部交给模型在提示词里临场理解。
知识检索节点在这条链路里承担的是整个回答的内容基础。每个学科都有独立的知识检索节点,查询模板统一为“请帮我检索 {{book_name}} 的内容”,检索策略统一采用文档与 QA 混合检索,其中文档召回数为 3、文档置信度阈值为 0.2,QA 召回数为 2、QA 置信度阈值为 0.9。这样的配置说明,流程既希望覆盖足够的教材内容,又希望对问答类知识保持更高的准确性门槛,兼顾可召回性和回答可靠性。
从参数贯穿方式来看,这套流程不只是根据学科做静态问答,而是把教学上下文也一起传入了大模型节点。除了用户原始提问以外,模型还会同时接收教材配置、核心素养和难度等级。这意味着最终输出并不是单纯复述知识点,而是会在既定教学约束下组织内容,更适合用于备课支持、课堂说明、教学设计参考等正式场景。
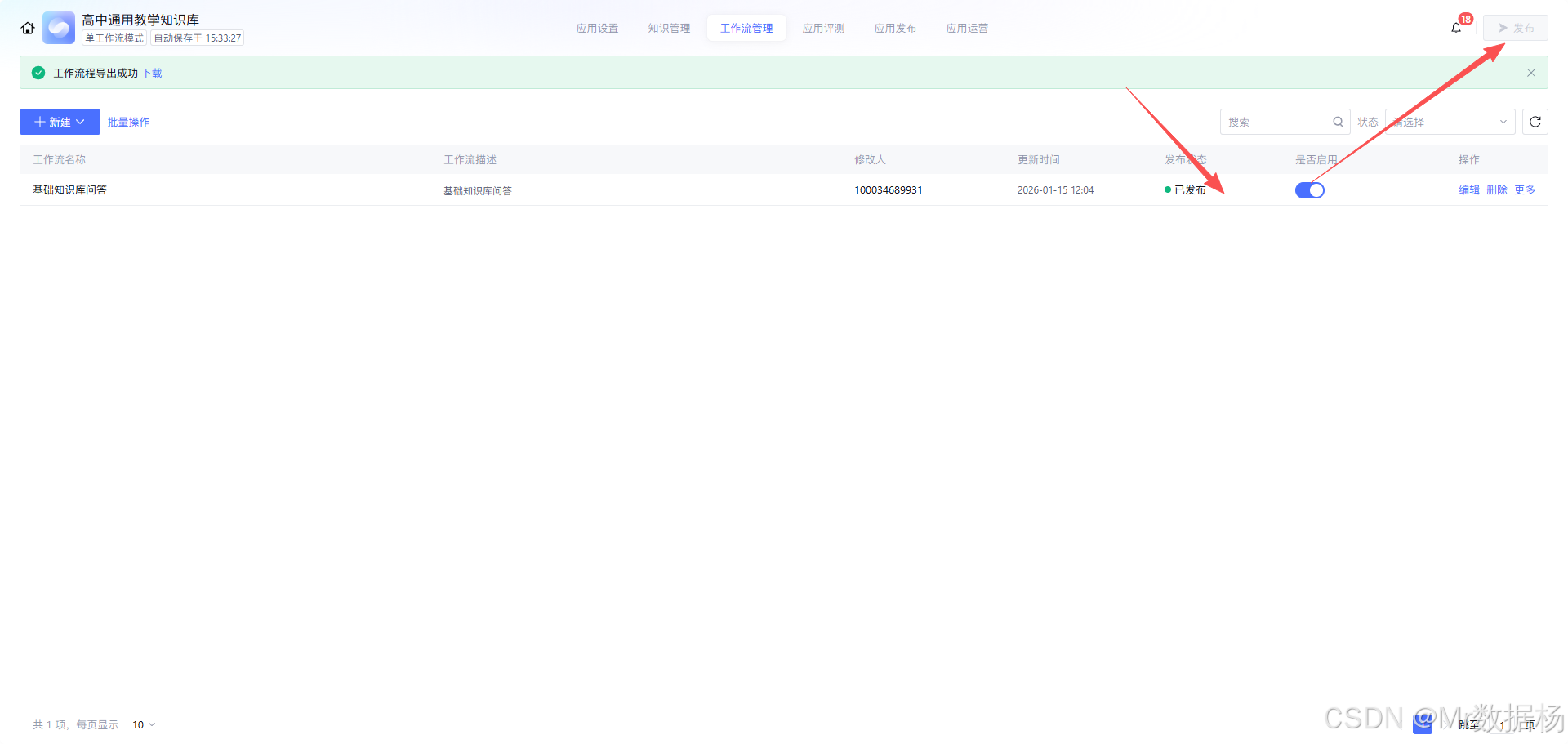
工作流启用与发布属于整条链路上线前的最后一步。这里真正需要确认的,不只是流程能跑通,而是学科分支、教材判断、知识库配置、提示词变量和兜底回复都已经固定下来。只有这样,外部调用时才能持续得到学科正确、教材匹配、知识有据的教学帮助结果,避免上线后出现“走错学科”“命不中教材”或“回答脱离知识库”的问题。
应用场景
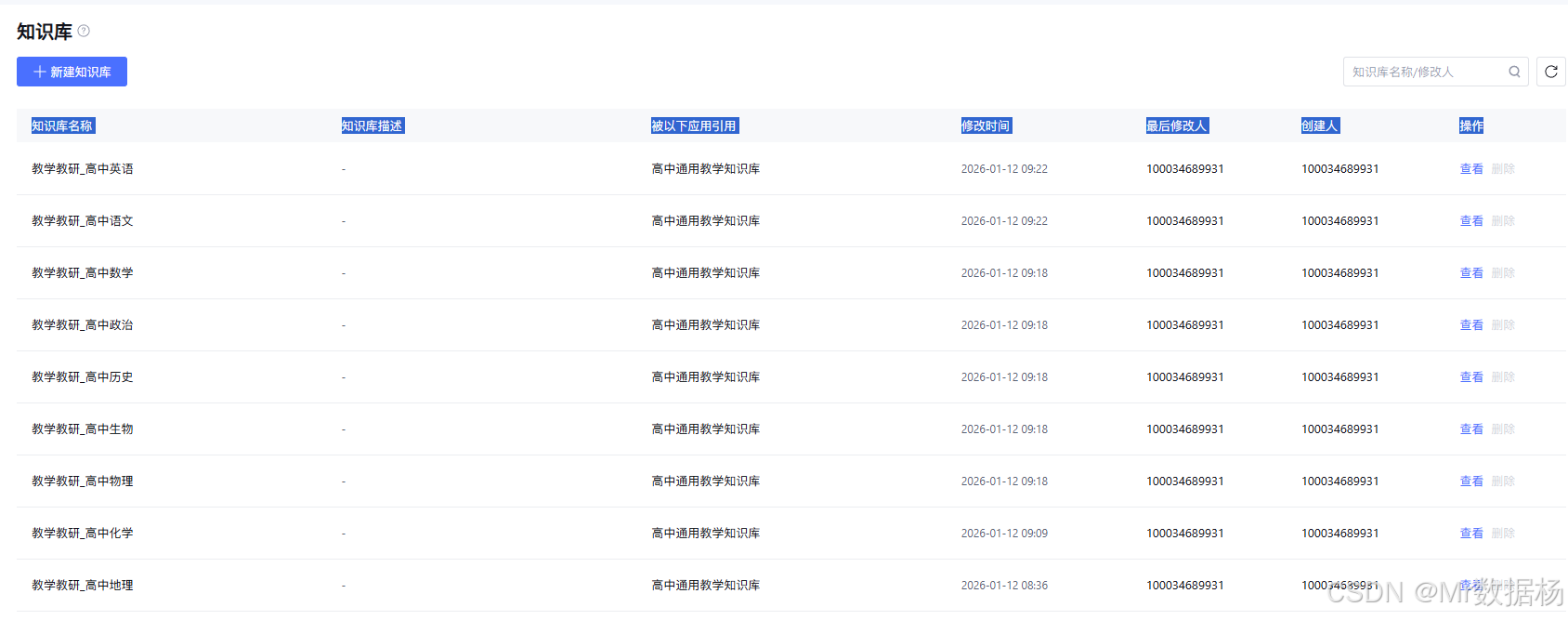
这个工作流最适合的场景,是需要“学科边界清楚、教材范围明确、输出可直接用于教学支持”的高中教学帮助产品形态。由于它把问题先按学科和教材做了分流,再结合知识库与教学参数生成结果,因此既可以嵌入教师备课系统,也可以接入题目生成辅助、课堂讲解支持、教研资料整理或学生答疑类场景。对于同一套平台来说,语文、数学、英语等不同学科虽然共用一套流程骨架,但每次实际执行时都会进入对应分支,最终得到贴合当前学科和教材的内容,不会出现跨学科混答或教材版本错位的问题。结合后续知识库补充和分支扩展,这套结构也很适合逐步从单一教材支持扩展到更多版本和更多教学任务。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 教师备课辅助 | 根据学科、教材和难度生成贴合课堂的教学帮助内容 | 一线教师、备课组教师 | 知识讲解、教学组织思路、课堂说明内容 | 提升备课效率,减少泛化回答 |
| 教学设计支持 | 围绕核心素养与教材内容输出更有目标感的教学材料 | 教师、教研员 | 素养导向表达、教材重点说明、难度匹配内容 | 让输出更贴近教学目标 |
| 学科答疑辅助 | 在明确学科与教材前提下回答具体教学问题 | 教师、助教、学生 | 问题解析、知识点说明、学习帮助内容 | 降低跨学科误答和版本偏差 |
| 教材知识检索问答 | 围绕指定教材内容快速召回并生成可读答案 | 教师、教辅运营人员 | 教材章节相关解释、内容提炼 | 让教材内容检索更可用 |
| 校内教研知识助手 | 为不同学科提供统一结构的知识库问答能力 | 教研组、学科负责人 | 分学科、分教材的教学支持内容 | 便于统一部署和长期迭代 |
总结
该工作流通过“学科分流 + 教材判断 + 知识检索 + 专项生成 + 统一回复”的方式,将原本容易泛化的教学帮助任务拆解为九个学科化、教材化的独立执行链路。每条链路都在固定节点和统一变量体系下运行,使模型只在当前学科、当前教材和当前教学约束内生成内容,不跨学科、不脱离教材,也不完全脱离知识库自由发挥。这样一来,输出结果就具备了更清晰的边界、更稳定的结构和更强的教学场景适配性。
从工程实现角度看,这套工作流真正解决的,不只是“模型能不能回答教学问题”,而是“如何让教学帮助结果可控、可复用并适合产品化接入”。在现有结构基础上,后续还可以通过新增教材版本、扩充学科知识库、细化难度等级或补充更多教学变量,持续增强系统能力。随着知识库内容和使用数据不断积累,这类“先分流、再检索、后生成、再收口”的工作流模式,也会比单纯依赖大模型自由问答更适合长期落地,尤其适合面向高中教学支持平台、教研系统和智能备课产品的持续迭代。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)