万字综述深度解析:告别“吃钱”的AI Agent!如何实现极致“降本增效”?(记忆、工具与规划全揭秘)
一、 论文总览

- 论文基础档案
**论文标题:**Toward Efficient Agents: A Survey of Memory, Tool learning, and Planning (迈向高效智能体:关于记忆、工具学习与规划的综述)
论文网址:https://arxiv.org/pdf/2601.14192
核心作者: Xiaofang Yang, Lijun Li, Heng Zhou 等(来自上海人工智能实验室、复旦大学、中国科学技术大学、上海交通大学、清华大学等顶尖科研机构)
发布时间: 2026年1月(注:ArXiv预印本时间标识为2026年,代表该领域极具前瞻性的研究总结)
核心关键词: Agents(智能体)、Efficiency(效率)、Agent Memory(智能体记忆)、Tool Learning(工具学习)、Planning(规划)。
- 为什么会有这篇论文?(它解决了什么痛点)
如果你用过 ChatGPT,你可能会觉得它回答问题挺快的。但是,当我们把大语言模型(LLM)升级为 智能体(Agent) 时,情况就完全不同了。
什么是智能体?如果说普通的 LLM 是一个“只会回答问题的百科全书”,那么 Agent 就是一个“能帮你自动干活的数字员工”。当你要它“帮我调研一下明天去北京的机票、查一下天气,然后定一个最便宜的行程并写成邮件”时,Agent 需要经历一个复杂的 “死循环” :
回忆上下文 -> 思考下一步干嘛 -> 调用搜索工具 -> 看搜索结果 -> 再次思考 -> 调用订票工具 -> 验证结果 -> 写邮件。
这个过程叫做“多步长链条推理”。在这个过程中,问题出现了:
- 太贵了(Token消耗巨大): 每思考一步,都要把之前的历史记录重新读一遍,输入输出的Token数呈指数级爆炸。
- 太慢了(延迟极高): 一步步调用工具、等待外部环境反馈,用户等得花儿都谢了。
- 太占资源(上下文撑爆): 聊着聊着,大模型的“脑容量(Context Window)”就不够用了,开始胡言乱语(迷失在中间)。
目前全网都在追求怎么让 Agent 变聪明,但 这篇论文独辟蹊径,它是全网少有的、专门研究如何让 Agent“降本增效”的重磅综述。 核心目标是: 在不牺牲任务成功率的前提下,极其苛刻地压缩资源消耗(包括Token消耗、运行时间、API调用费用等)。
二、 核心方法与原理:如何给 AI 员工“降本增效”?
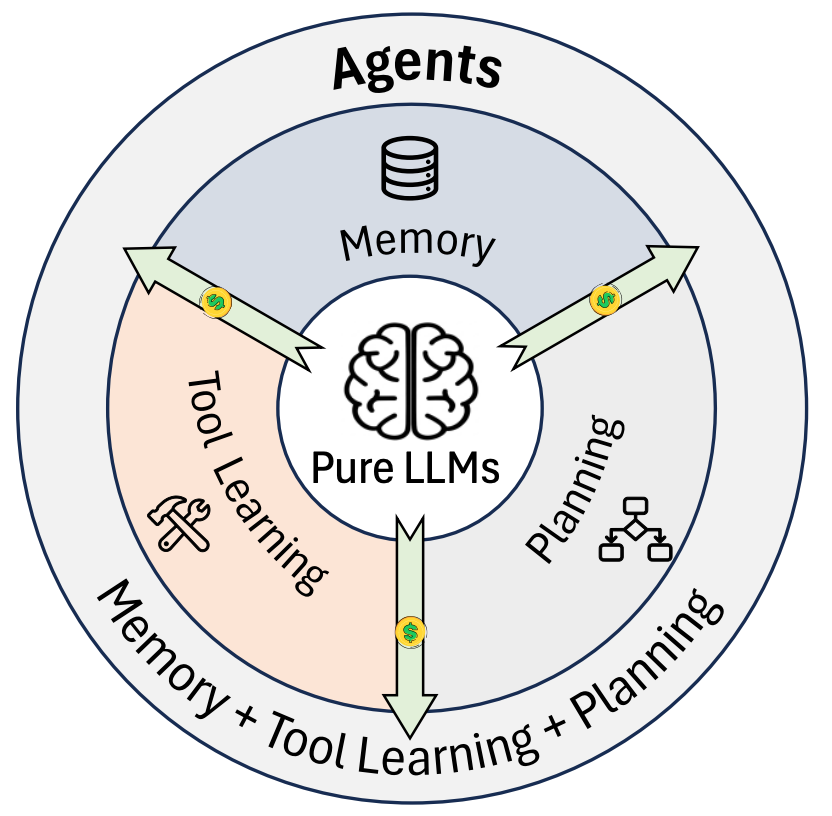
如果你把 Agent 当作一个来你公司上班的员工,那么:
- 记忆(Memory) 就是他的 笔记本和大脑记忆 。
- 工具学习(Tool Learning) 就是他 使用电脑、软件、计算器 的能力。
- 规划(Planning) 就是他 安排工作计划、和其他同事(多智能体)开会 的效率。
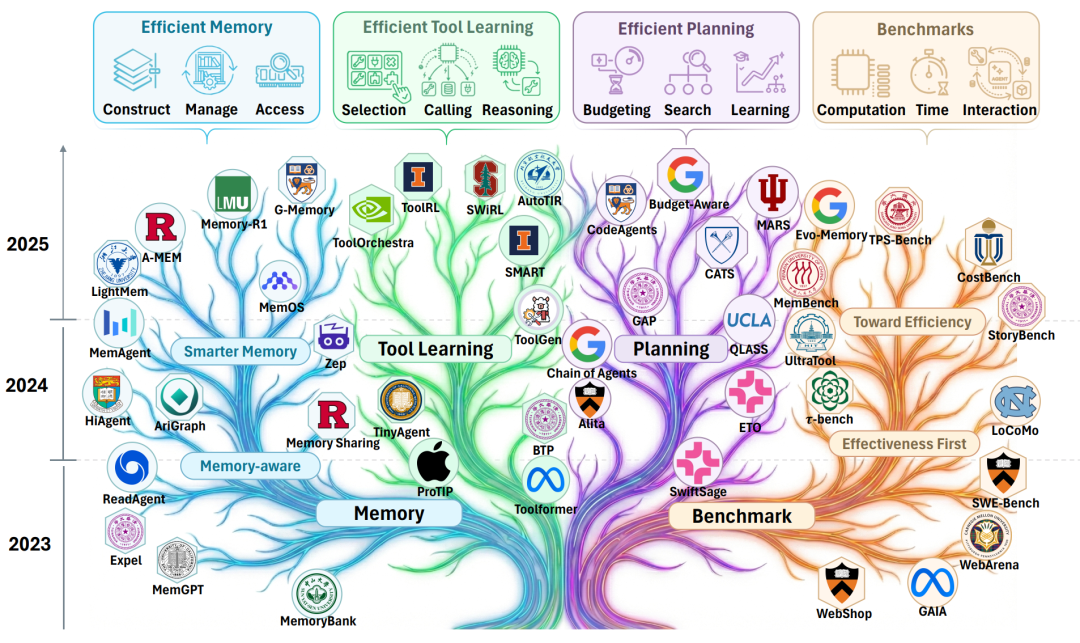
核心一:高效记忆(Efficient Memory)—— 怎么做到“过目不忘”又不“脑容量过载”?
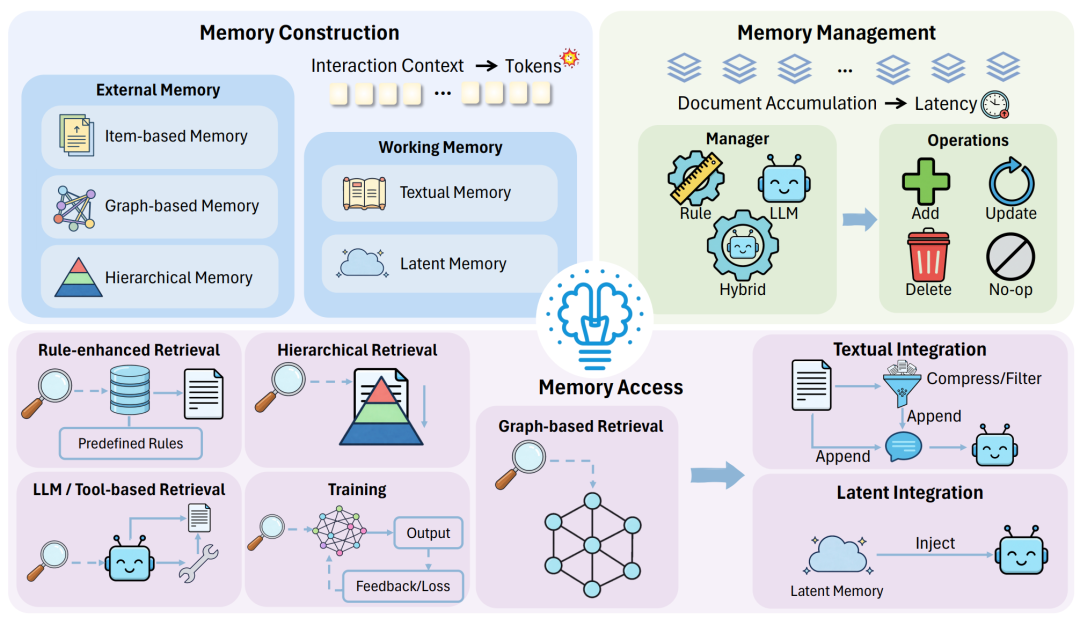
如果不加控制,Agent 每次行动都会把以前聊过的所有废话重新看一遍,这不仅贵,而且效率极低。科学家们把记忆的优化分成了三个阶段:构建、管理和提取。
1. 记忆构建(怎么记笔记?)
- 工作记忆(Working Memory): 这就像员工的 “大脑缓存”或者贴在电脑屏幕上的便签,是直接写在提示词(Prompt)里的。为了高效,科学家提出了文本压缩法 (比如定时把前面的长对话总结成一句话摘要,抛弃原文)和更高级的 隐式记忆法(Latent Memory) 。
- 黑科技原理: 隐式记忆就像“脑电波直连”。它不把历史记录变成文字存起来,而是直接截取大模型在计算过程中的“神经网络激活值(KV Cache 等)”。这样一来,Agent 读取过去的记忆时,根本不需要消耗文字 Token,速度极快!
- 外部记忆(External Memory): 这就像员工的 “资料库” 。不能什么都放在脑子里。
- 条目式记忆(Item-based): 把经历变成一条条精炼的“经验法则”存入数据库。
- 图谱记忆(Graph-based): 把复杂的信息抽成“知识图谱”(谁认识谁,什么东西属于什么分类),这种结构天然就去除了冗余废话,极其紧凑。
- 层级记忆(Hierarchical): 像电脑操作系统一样,分短期内存、中期硬盘、长期云端冷备份。
2. 记忆管理(怎么清理无用笔记?)
你的资料库如果无限变大,搜索起来一样慢。必须有“保洁员”。
- 基于规则(Rule-based): 最便宜的做法。比如模拟人类的“艾宾浩斯遗忘曲线”,时间久了、不重要的事情自动删除;或者设定一个固定容量,满了就把最老的记忆挤掉(FIFO)。这种方法一分钱不花,但容易误删重要信息。
- 基于大模型(LLM-based): 花点钱,请大模型自己来当保洁员,让它自己判断哪些记忆该合并、哪些该删除。虽然花了少量的调用费,但保留下来的记忆更精准。
3. 记忆提取与整合(用的时候怎么找?)
不能每次遇到问题就把资料库翻底朝天。
- 检索策略: 除了常规的“关键词/语义搜索”,高效的做法是引入“时间衰减因子”或“重要性评分”,或者沿着知识图谱的节点顺藤摸瓜。
- 多智能体记忆(团队共享文档): 在多 Agent 合作时,如果每个人都记一份笔记,太浪费了。现在流行做 共享记忆池(Shared Memory) ,大家把验证过的正确结论放到池子里,别的 Agent 直接拿来用,避免重复造轮子。
核心二:高效工具学习(Efficient Tool Learning)—— 怎么“快准狠”地使用工具?
Agent 最大的魅力是能调用外部工具(比如浏览器、代码沙箱、天气API)。但在现实中,如果一个难题需要搜几十次网页,API 调用费和等待时间是灾难性的。
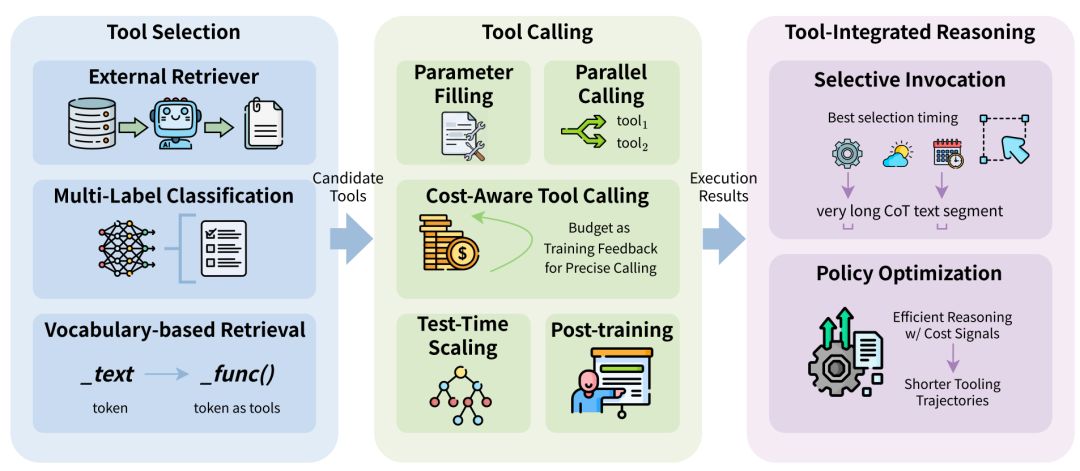
1. 工具选择(Tool Selection)—— 面对一万个工具,怎么秒选?
以前的做法是把所有工具的说明书都丢给大模型,让它选。如果工具箱里有几千个工具,Prompt 会直接炸掉。
- 外部检索器(External Retriever): 给工具建个外挂搜索引擎,遇到问题先搜出最相关的 Top-5 工具,再把这 5 个工具喂给大模型。
- **词表级别检索(Vocabulary-based Retrieval):**这是个奇招。 科学家把特定的工具直接变成了大模型词典里的“一个专属生僻字”(Token)。模型只要生成这个 Token,系统就瞬间知道它要用工具了。这几乎没有任何额外的理解成本,速度飙升。
2. 工具调用(Tool Calling)—— 怎么用得又快又省钱?
- 并行调用(Parallel Tool Calling): 以前 Agent 查北京天气、上海天气、广州天气,是串行的,查完一个再查下一个。现在引入了“编译器思维”,让 Agent 先规划好,然后 同时发起 三个地的天气查询,极大缩短了等待时间。
- 成本感知调用(Cost-Aware Tool Calling): 给大模型心里装个“算盘”。在训练时加入惩罚机制(如果调用了没用的工具,就扣分)。让模型学会在“有把握”的时候直接回答,只有“没把握”时才去花钱调用工具。比如简单的算术题“1+1”,它自己就答了,坚决不用计算器 API。
3. 整合推理(Tool-Integrated Reasoning)—— 治好“强迫症”
有些传统 Agent 有“工具强迫症”,啥都要去搜一下。高效的做法是通过强化学习(RL),让大模型学会 “适可而止” 。这就像训练一个极其精明的员工,不仅要把事情办对,还要用最少的步骤把事情办对。
核心三:高效规划(Efficient Planning)—— 怎么用最少的步数解决问题?
规划是 Agent 的大脑中枢。高效的规划不仅关乎大模型生成文字的速度,更关乎它“控制行为”的效率。如果一步走错,后面全是无用功。
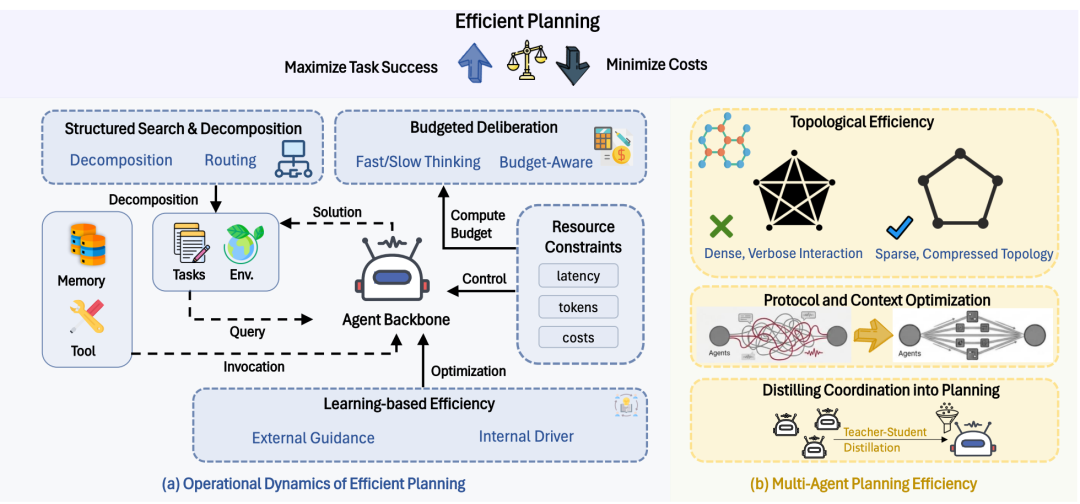
1. 单智能体的高效规划(一个人怎么高效干活)
- 自适应控制(快慢思考切换): 借鉴人类大脑的“快思考(系统1)”和“慢思考(系统2)”。遇到常规问题,直接靠直觉(模型自带知识)快速输出;遇到复杂数学或逻辑题,才开启昂贵的“树状搜索(Tree Search)”慢速推演。好钢用在刀刃上。
- 结构化搜索与剪枝: 在推演未来的可能性时(比如下棋),尽早发现哪条路走不通,提前“剪去”错误的树枝(搜索或成本感知剪枝),避免探索大量没用的步骤。
- 学习与技能固化(Skill Acquisition): Agent 千辛万苦写好了一段代码解决了一个问题,不能做完就扔了。高效的方法是把它存入“技能库”。下次遇到类似问题,直接把现成的代码掏出来用,省去了思考和试错的过程。
2. 多智能体协作效率(一个团队怎么高效开会)
“多智能体(Multi-Agent)”现在很火,比如三个模型分别扮演程序员、测试员、产品经理。但这会导致通讯成本呈现平方级爆炸(大家互相疯狂发消息,Token 费嗖嗖涨)。
- 网络拓扑优化: 不要让所有人都在群里七嘴八舌。把通讯结构改成“流水线(线性)”或者“有向无环图(DAG)”。而且引入“沉默机制”——只有当大家意见出现严重分歧时,才允许发起“激烈辩论”,平时能闭嘴就闭嘴。
- 沟通协议压缩: 强制要求 Agent 之间不能用大白话聊天,必须用精简的“伪代码”或严格的格式传递关键信息,把沟通的上下文压缩到极致。
- **知识蒸馏(Distilling Coordination):**这是最釜底抽薪的一招。 让一群庞大的多智能体团队先去解决问题,把它们讨论、纠错的优质过程记录下来。然后用这些记录去训练(微调)一个单体小模型。最后上线时, 直接开除整个团队,只留下那个学成归来的“小超人” 。既保留了群体的智慧,又享受了单人的极速成本!
三、 评估与标准:怎么才算真的“高效”?
这篇论文非常强调一点: “便宜但愚蠢”绝不是高效 。如果为了省 Token 导致任务失败,那就毫无意义。真正的效率必须在 “任务成功率”和“资源消耗” 之间找到最佳平衡点(帕累托前沿)。
科学家们总结了衡量智能体效率的核心指标体系:
- Token 消耗量与 API 花费: 这是最直接的“真金白银”指标。有的研究甚至直接换算成美金(USD)来对比。
- 延迟与运行时间(Latency & Time): 包含检索时间、大模型推理时间、工具响应时间。
- 交互步骤数(Steps/Turns): 越聪明的 Agent,越能用极少的步数直击要害,完成任务。
- 硬件资源(GPU 内存等): 尤其在那些把长文本压缩成底层向量特征(隐式记忆)的方法中,节约显存也是关键。
当前的评测基准(Benchmarks)正在发生转变,从以前只看“模型能不能答对题”,转变为像 TPS-Bench 这样的综合基准——不仅看对不对,还要算出 “每次成功完成任务的预期金钱成本(Cost-of-pass)” 。这就非常接地气了,符合大厂和企业落地的核心诉求。
四、 创新价值与未来方向
这篇综述的巨大价值在于,它为狂热的“智能体造神运动”泼了一盆理性的冷水,指明了通往商业化落地的必经之路—— 工程化与经济性 。
在此基础上,作者对未来提出了几个极具启发性的前瞻方向:
-
Agent的“隐式推理”(Agentic Latent Reasoning)
- 目前 Agent 思考过程还要把字打出来(Chain-of-Thought),这很浪费。未来的 Agent 会像人类一样,在脑子里(隐含的连续向量空间里)默默转念头,不需要把推理过程全变成文字。这将彻底颠覆目前的 Token 计费和推理速度。
-
注重“落地部署”的系统设计
- 为了处理长上下文,不要总迷信加机器、搞庞大的多智能体。有时候,一个精心调优的单体模型,配合好的底层系统工程架构,在性价比上能远超一堆模型在那儿相互“过家家”。
-
多模态智能体(MLLM-based Agents)的效率噩梦
- 未来的 Agent 是要看图、看视频、操作电脑和手机界面的。相比于纯文本,图片和视频的计算量是核弹级的。如果看一眼屏幕就要把整个截图传入大模型,系统会瞬间崩溃。如何在视觉处理上做到只关注关键特征,将是下一个蓝海挑战。
五、 总结
综上所述,这篇万字重磅综述《迈向高效智能体》为我们描绘了一幅清晰的 AI 进化路线图:
AI 正在从“纯文本的聊天机器人”进化为“能在现实世界中干活的智能体”,而为了让这些员工真正进入千行百业,我们必须经历一次从“能用”到“好用且用得起”的巨大跨越。
在这场效率革命中:
- 在记忆层面 ,我们通过文本压缩、图谱化和潜变量技术,让 Agent 拥有了低功耗的过目不忘之能;
- 在工具层面 ,我们通过并行处理、成本惩罚和特定词表映射,让 Agent 变成了快准狠的数字极客;
- 在规划层面 ,我们通过快慢思考切换、网络拓扑修剪甚至把团队智慧“蒸馏”到单体模型中,打造出了运筹帷幄的高效大脑。
大航海时代,算力固然是船只的引擎,但那些关于 “记忆、工具和规划”的精妙算法设计,才是决定这艘巨轮能否低耗油、无延迟地驶抵终点的风帆。 对于企业、开发者和热爱 AI 的人来说,理解了这篇综述中的“降本增效”秘籍,就是在未来的 AI 生产力大爆发中,掌握了核心密码。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献190条内容
已为社区贡献190条内容

所有评论(0)