告别“纸上谈兵”!万字长文全景剖析AI大模型的终极形态:智能体推理(Agentic Reasoning)
一、论文速览

论文标题: Agentic Reasoning for Large Language Models: Foundations, Evolution, Collaboration(大型语言模型的智能体推理:基础、进化与协作)
论文网址:https://arxiv.org/pdf/2601.12538
作者团队: Tianxin Wei, Ting-Wei Li等(来自伊利诺伊大学香槟分校 UIUC、Meta、亚马逊、Google DeepMind、加州大学圣地亚哥分校、耶鲁大学等顶尖高校与科技巨头)。
核心关键词: Agentic AI(智能体AI)、LLM Agent(大模型智能体)、Agentic Reasoning(智能体推理)、Self-evolving(自我进化)、Multi-agent(多智能体)。
核心主旨: 论文提出,AI大模型正在经历一场从“静态文本生成器”到“动态自主智能体”的范式转变。未来的AI不仅要会“想(推理)”,还要会“做(行动)”,甚至能“自我反思”和“团队协作”。这篇文章为我们描绘了构建下一代超级AI的完整路线图。
二、这篇论文到底解决了什么痛点?
大家有没有发现,我们现在用的ChatGPT、Kimi或者文心一言,虽然很聪明,但它们本质上像是一个 “被关在小黑屋里的超级学霸” 。
传统的大模型(LLM)有几个致命的弱点:
- 静态被动: 你问一句,它答一句(单轮或多轮对话)。你不下达指令,它就静止不动。
- 闭门造车: 它们的知识停留在训练完成的那一刻。虽然能解复杂的数学题,但如果遇到开放的、动态的真实世界问题(比如“帮我规划一个去日本的旅行,订好性价比最高的酒店并付款”),它们往往会抓瞎。
- 一锤子买卖: 传统的推理是一次性生成的,如果中间某一步错了,后面的结果就会“步步错”,它不知道怎么在执行过程中纠正自己。
为了解决这些问题,学术界和工业界提出了一个革命性的概念: 智能体推理(Agentic Reasoning) 。
什么是智能体推理?
说白了,就是给这个“小黑屋里的学霸”装上 眼睛、手脚、记忆和互联网网线 ,并且教它一种全新的做事方法: “思考-行动-观察-反思” 。
在这个新模式下,推理不再仅仅是脑子里的数学推导,而是变成了一个与真实世界互动的循环。AI会自动把大任务拆解成小任务,自己去调用外部工具(比如计算器、搜索引擎),自己验证结果,错了就重新来过。
这篇长达100多页的综述论文,就是把目前全球最顶尖的“智能体推理”技术做了一次史诗级的梳理,构建了一个三层架构模型: 基础能力(单兵作战)、自我进化(经验积累)、集体协作(团队打怪) 。
下面,我们就一层一层地剥开,看看这些前沿技术到底是怎么运作的。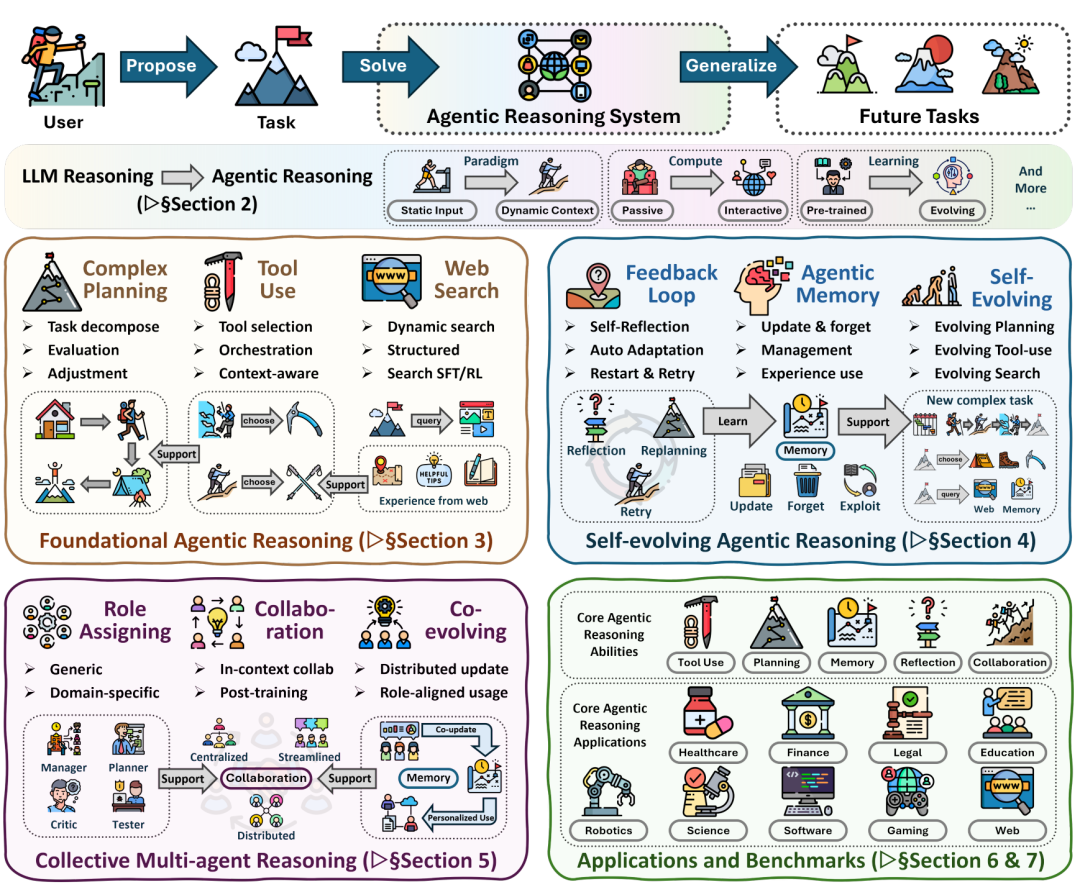
三、核心方法与原理 —— 打造超级AI的三层架构
为了让大家听得懂,我们把构建一个“完美智能体”比作 “培养一个职场超级精英” 。
第一层:基础智能体推理(Foundational Agentic Reasoning)—— 职场新人的三大基本功
要让AI像人一样独立完成任务,它首先得具备三个基础能力: 规划(Planning)、工具使用(Tool Use)和搜索(Search) 。
1. 规划能力(Planning):从“走一步看一步”到“走一步看十步”
大模型经常会犯“猴子掰苞谷”的毛病,想到哪写到哪。规划能力就是要让AI学会列“To-Do List”(待办事项清单)。
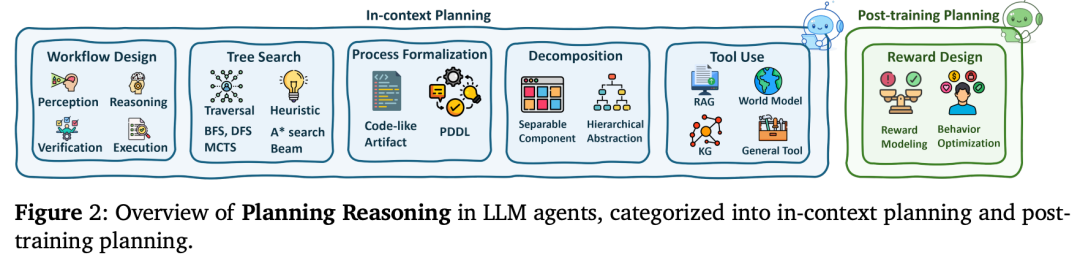
- 工作流设计(Workflow Design): 论文提到,现在的AI被设定成了流程化的思维。比如面对一个复杂问题,AI会先“感知”,再“推理”,接着“执行”,最后“验证”。这就像我们做项目时的PDCA循环。著名的 ReAct框架 就是让AI一边想(Thought),一边做(Action),再看看结果(Observation)。
- 树搜索(Tree Search/MCTS): 这是目前极度火热的技术(也是OpenAI o1模型和DeepSeek-R1背后的核心理念)。面对复杂问题,AI不再只走一条路,而是像下棋一样,同时思考好几种方案(形成一棵决策树),评估哪条路最靠谱,如果走到死胡同就“回溯”退回来重新选路。这让大模型具备了“深思熟虑”的慢思考能力。
2. 工具使用(Tool-Use):给大脑装上手脚
如果大模型不会用工具,那它就只是个聊天机器人。智能体推理让AI学会了自己调用API。
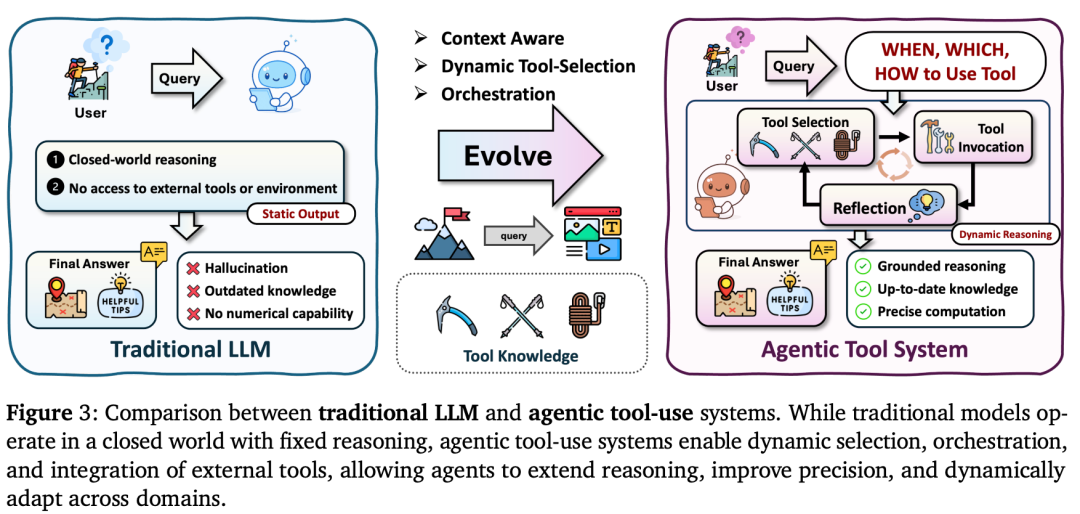
- 怎么教AI用工具? 论文介绍了两种主流门派:
- 上下文引导(In-Context): 就像给员工发一本《工具使用手册》。我们在提示词里告诉AI:“这里有一个天气API,格式是XXX,遇到问天气的你就调它。”AI靠着强大的阅读理解能力,当场现学现卖。
- 后训练(Post-Training): 也就是把使用工具的本领刻进AI的DNA里。通过监督微调(SFT)或强化学习(RL),像训练小狗一样,AI调对了工具就给奖励。论文提到的Toolformer模型,就是让AI自己生成调用API的代码,真正实现了工具自由。有了这个能力,AI就能帮你发邮件、跑Python代码、操作Excel了。
3. 智能体搜索(Agentic Search):主动查阅资料
传统的RAG(检索增强生成)是“开卷考试”,用户提问时,系统强行塞给大模型几篇相关文章让它参考。
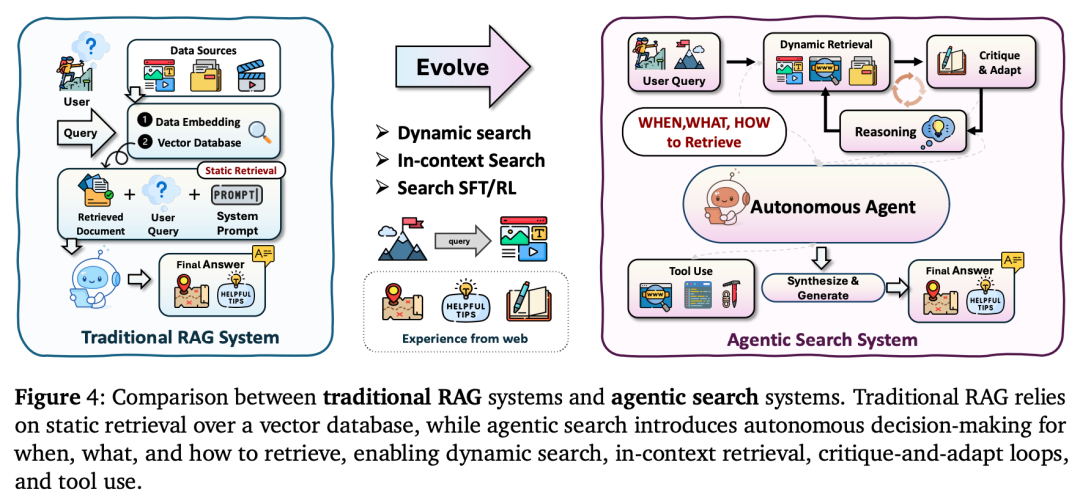
而智能体搜索是 “主动去图书馆查资料” 。AI会自己判断:“这个问题我不知道,我需要写个搜索词去Google一下。”搜出来的结果如果不够好,它还会自己修改搜索词继续搜,直到拼凑出完整的证据链。
第二层:自我进化推理(Self-Evolving Agentic Reasoning)—— 从新手到专家的蜕变
基础打好了,AI能干活了,但它如果总是犯同样的错误怎么办?真正的智能,必须具备 自我纠错 和 长程记忆 的能力。这也是当前AI研究的最前沿。
1. 反馈机制(Feedback):AI的“每日三省吾身”
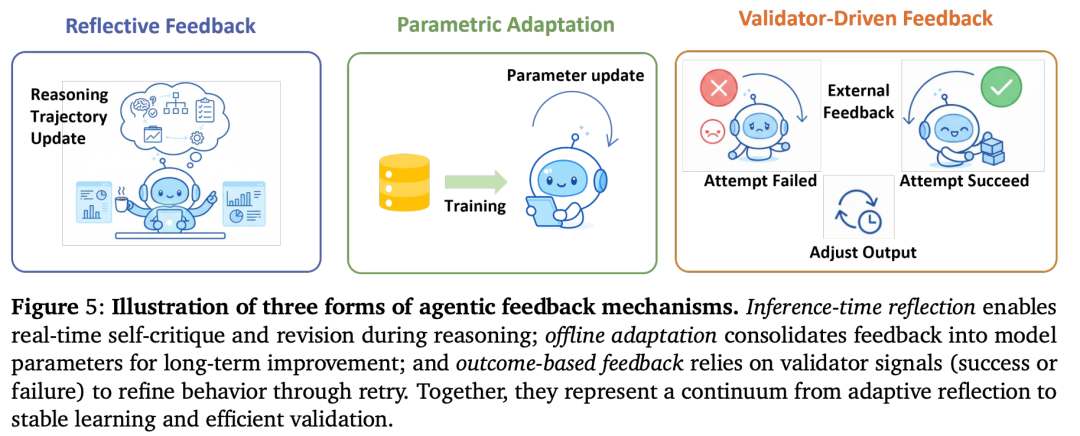
人类学习靠的是“吃一堑长一智”,AI也一样。论文总结了三种反馈机制:
- 内部反思(Reflective Feedback): AI做完题后,自己或者找另一个AI扮演“批评家(Critic)”,检查有没有逻辑漏洞。比如著名的 Reflexion 框架,就是让AI在出错后写下一段“反思日记”:“哦,我刚才那步算错了,下次遇到这类题我得先检查单位。”拿着这本日记,AI再做一次,成功率会大幅提升。
- 参数适应(Parametric Adaptation): 这是更长期的学习。把AI自己反思出的“好方法”和“高质量解题过程”,拿来重新训练大模型本身,改变它的神经网络权重。这就像把临时经验转化成了肌肉记忆。
- 验证器驱动(Validator-Driven): 在写代码等场景中,AI把代码扔进编译器跑一下。如果报错了(这就是外部验证器的反馈),AI直接看着报错信息原地修改Bug,直到跑通为止。
2. 智能体记忆(Agentic Memory):告别“金鱼的记忆”
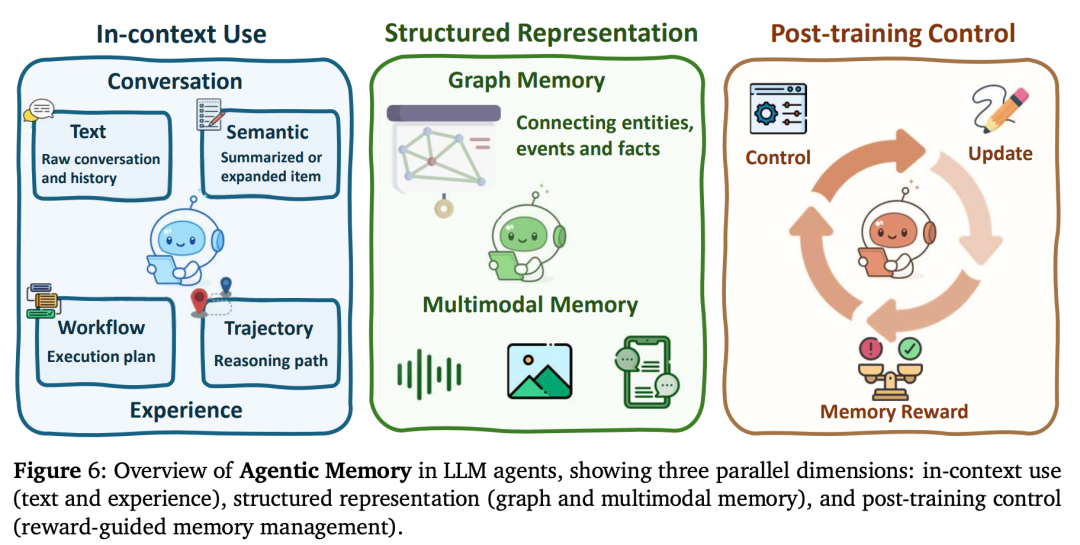
以前我们跟AI聊天,聊久了它就忘了前面说过什么(因为上下文窗口有限)。现在的智能体引入了类似人类大脑的记忆系统:
- 事实记忆与经验记忆: AI不仅记录“我们聊了什么(事实)”,还会记录“我上次是怎么解决这个问题的(经验/技能)”。
- 结构化记忆: 简单的文本堆砌不够用了。现在的AI会把记忆构建成 知识图谱(Graph Memory) 。比如它记得“张三是李四的老板”,当下次你需要找李四的老板时,它能瞬间从庞大的记忆网络中提取出来。
- 后训练记忆控制: 最新的研究甚至让AI通过强化学习自己决定: “这句话太重要了,我要存进长期记忆!”或者“这句是废话,从记忆里删掉吧。” 这种动态的记忆管理,让AI具备了真正意义上的“终身学习”能力。
第三层:集体多智能体推理(Collective Multi-agent Reasoning)—— 打造一个AI超级公司
一个诸葛亮再厉害,也有短板。于是,研究人员把目光投向了 “多智能体系统(MAS)” 。这就好比用AI组建一家公司。
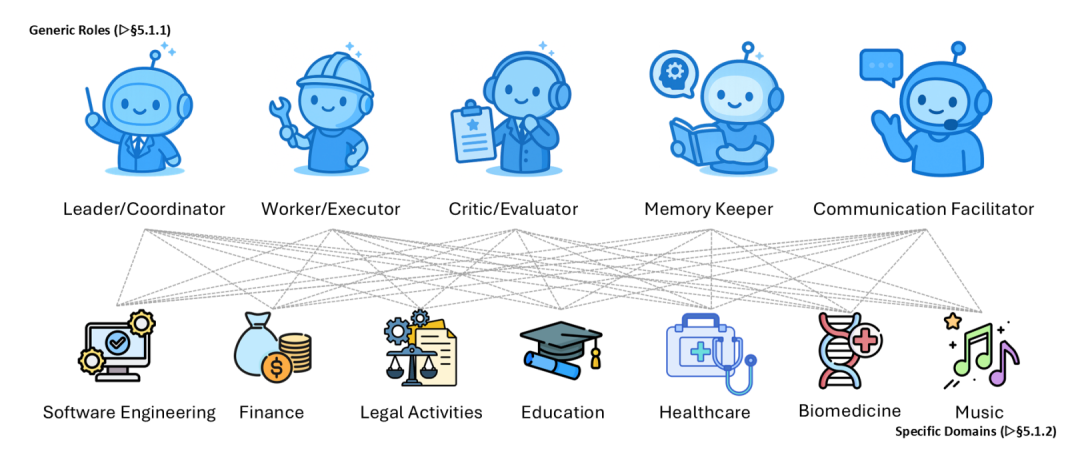
1. 角色分工(Role Taxonomy)
在多智能体系统中,AI们会被分配不同的“人设(Persona)”。
- 通用角色: 比如有负责统筹规划的 经理(Manager) ,有负责干活的 打工人(Worker) ,有专门挑毛病的 质检员(Critic) ,还有负责记录会议纪要的 记忆管理员(Memory Keeper) 。
- 领域定制角色: 如果是开发软件(如MetaGPT、ChatDev项目),就会有AI产品经理、AI架构师、AI程序员和AI测试员。如果是看病,就会有AI分诊护士、AI专科医生和AI药剂师。
2. 协作与博弈(Collaboration and Division of Labor)
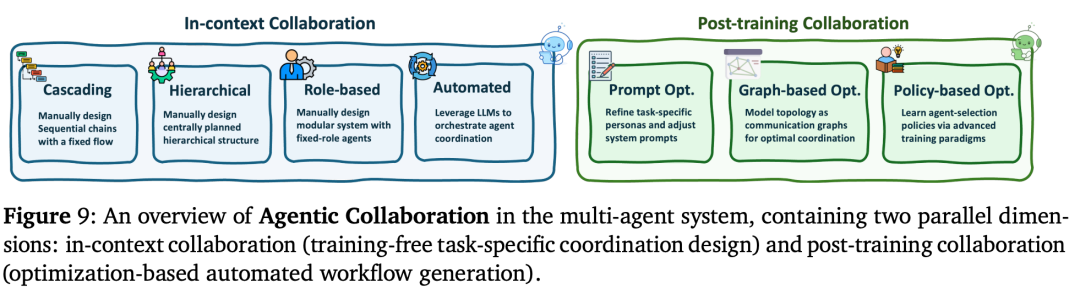
这些AI不是各干各的,它们需要交流:
- 静态流水线: 像工厂流水线一样,产品经理写好需求给程序员,程序员写完代码给测试员。
- 动态讨论(Debate): 遇到难题时,几个AI会像开会一样进行“头脑风暴”甚至“激烈辩论”。比如三个AI针对一个法庭案件进行辩论,真理越辩越明,最后得出的结论往往比单个AI强得多。
- 心理理论(Theory of Mind): 这是非常高级的能力。研究人员在尝试让AI能够“猜透另一个AI的心思”,从而更好地在合作游戏(如《胡闹厨房》)或谈判博弈中取得胜利。
3. 多智能体共同进化(Multi-Agent Evolution)
不仅单个AI在学习,整个AI团队也在进化。它们通过分享同一个“公共记忆池”,不断优化彼此间的沟通协议和合作网络。今天这四个AI配合得磕磕绊绊,训练几万次之后,它们就能形成绝佳的默契,这被称为“集体智能的涌现”。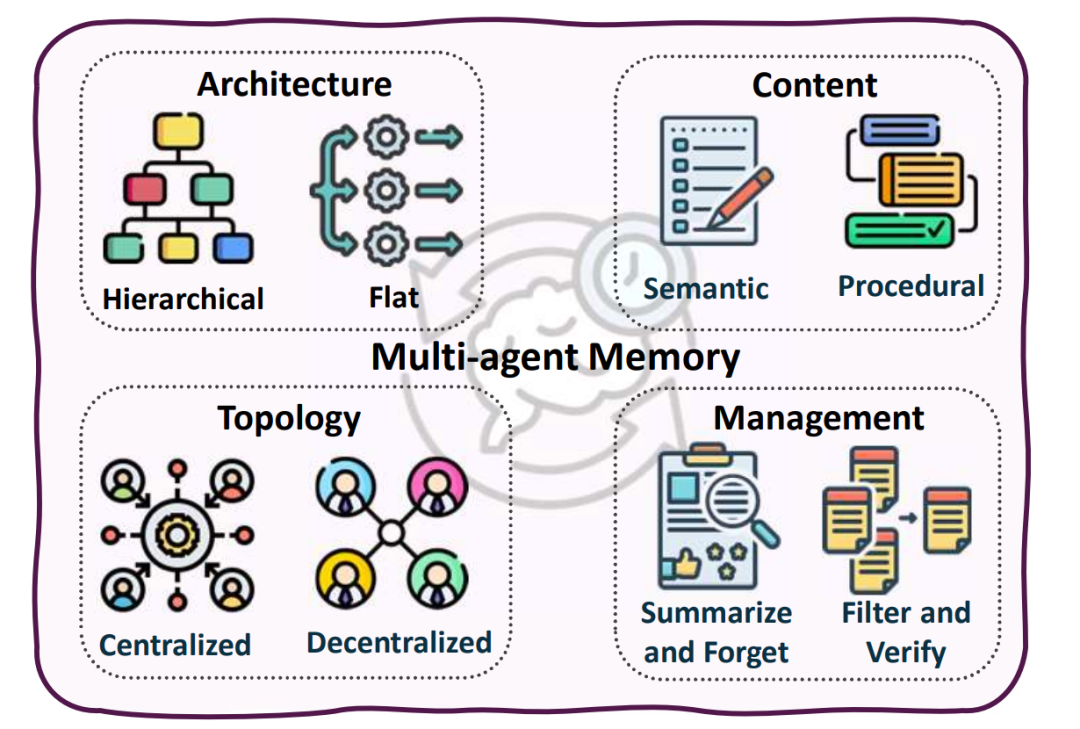
四、驱动智能体的两大引擎(内力与外功)
在了解了三层架构后,论文非常敏锐地指出了目前实现这些能力的两种核心路径,我称之为AI修炼的“内力”与“外功”。理解这一点,有助于我们看懂当今大模型市场的竞争格局。
- 语境中推理(In-context Reasoning)—— 巧用提示词的“外功”
- 原理: 大模型本身的参数(脑子)冻结不改变,完全靠在用户提问时,给它设置巧妙的提示词框架、外部工作流(比如上面说的思维树、给它挂载搜索工具),让它在推理阶段(Inference-time)展现出智能体的特质。
- 优势: 灵活、成本低、不需要昂贵的显卡去重新训练模型。
- 代表: 早期基于GPT-4搭建的各种Agent框架(如AutoGPT、HuggingGPT)。
- 后训练推理(Post-training Reasoning)—— 改变模型权重的“内力”
- 原理: 发现光靠外部套壳还是不稳定后,科学家们开始通过强化学习(RL)和监督微调(SFT),把“如何规划、如何使用工具、如何反思”这些能力,直接烧录到大模型的神经网络参数里。
- 核心方法(如GRPO): 论文中提到了GRPO(组相对策略优化),这是近期大火的强化学习算法(DeepSeek-R1正是用了它)。给AI出同一道题,让它给出好几个不同的推理过程。然后不去刻意算一个绝对分数,而是比较这几个解法哪个更好,好的就奖励,差的就惩罚。久而久之,大模型在“顿悟”中学会了长逻辑推理。
- 优势: 极其稳定、泛化能力极强。AI是真的“懂”了怎么思考,而不是在生搬硬套模板。
目前业界的趋势是: 内力与外功相结合 。先通过强化学习练好长链条思考的“内力”,再在实际应用时配上好用的工具(外功)。
五、五大现实应用场景 —— 智能体正在如何改变世界?
理论说得再好,也得落地。这篇论文全面梳理了智能体推理在当今最前沿的五大应用领域。看了这些,你会感受到一种强烈的“未来已来”的震撼。
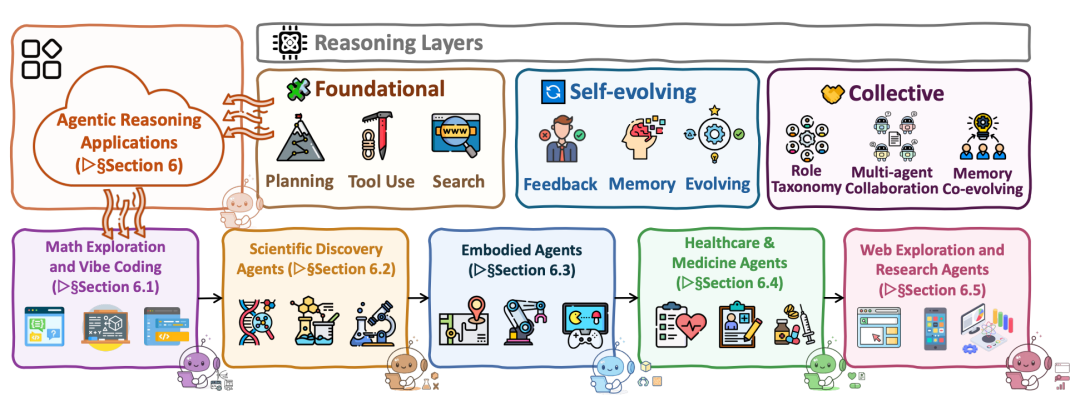
- 数学探索与“随性编程”(Math & Vibe Coding)
- 数学领域: AI不再仅仅是做做高考题。如今的数学Agent已经能够参加国际奥林匹克数学竞赛(IMO)并达到银牌水平(如AlphaGeometry)。更有甚者,AI正在充当科学家的助手,去推导人类还没证明出的数学猜想,探索全新的定理结构。
- Vibe Coding(氛围编程): 这个词最近在程序员圈子里很火。有了编程Agent(如Devin、Cursor),程序员不再需要一行行敲代码。你只需要用自然语言说出需求(“我要一个贪吃蛇游戏,风格是赛博朋克的”),AI就会自动规划架构、写代码、运行测试、报错了自己Debug,全程你只需要把握“氛围(Vibe)”和方向。编程的门槛被彻底打破了。
- 科学发现智能体(Scientific Discovery Agents)
- 自动驾驶实验室: AI正在重塑生物、化学和材料学。论文提到的Agent,比如AI Scientist,能够端到端地完成科研:它会自己去知网/arXiv检索最新文献,提出一个没人做过的假设,写代码或操控自动化机械臂去做化学实验,然后收集数据,甚至最后还能自动写出一篇学术论文。这极大地加速了新药研发和新材料发现的过程。
- 具身智能(Embodied Agents,即机器人)
- 把聪明的大脑装进物理世界的机器人身体里。
- 传统的机器人只能执行死板的指令。而现在的具身Agent拥有了“常识推理”。比如你跟机器人说“我不小心把可乐撒在桌上了”,它能推理出:需要先去洗手间找到抹布,避开地上的障碍物,然后回来擦桌子。论文中提到,通过多模态(视觉+语言)大模型,机器人能看懂周围的环境,并不断调整自己的运动轨迹。
- 医疗与临床智能体(Healthcare & Medicine Agents)
- 医疗领域的容错率极低,因此极度考验Agent的 安全边界和严谨推理 。
- 现在的医疗Agent能够读取患者几十页的复杂电子病历(EHR),调取医学知识图谱,像人类医生会诊一样,由“多个AI专家”针对疑难杂症进行会诊讨论,最后给出一个带有明确文献出处(基于智能体RAG)的诊断建议。
- 自主网页与研究智能体(Web & Research Agents)
- GUI智能体: 这是让你彻底解放双手的神器。AI可以直接接管你的电脑或手机屏幕,像人一样点击鼠标、敲击键盘。比如你说“帮我把昨天的会议录音整理成PPT发给老板”,GUI Agent会自己打开本地文件夹,使用转写软件,排版PPT,最后打开微信发送。
- 深度研究智能体: 像DeepResearch这样的系统,当你给它一个宽泛的课题(比如“帮我分析2025年全球AI芯片市场格局”),它会在接下来的几小时内,疯狂在几千个网页中穿梭、搜索、提取、对比数据,最终吐出一份几十页的高质量专业研究报告。
六、创新价值与未来挑战(我们距离《流浪地球》里的MOSS还有多远?)
论文的创新价值总结
这篇综述的伟大之处在于,它没有仅仅停留在“Prompt提示词工程”这种表面现象,而是 把“推理(Reasoning)”从大模型大脑内部的一个黑盒计算,提升到了“与外部世界交互、适应、演化”的系统工程高度。
它指出:大模型本身只是一个“引擎”,而 “智能体推理(Agentic Reasoning)”才是整辆汽车的“底盘和方向盘” 。只有将大模型的算力转化为在不确定环境下的连续决策能力,我们才能通往真正的通用人工智能(AGI)。
未来的六大终极难题(Open Problems)
当然,当前的智能体还远非完美,论文在最后指出了几大亟待解决的挑战,这也是未来几年各大AI公司拼命砸钱研发的方向:
- 个性化与用户为中心(Personalization): 现在的Agent往往是一本正经的“公事公办”。未来的Agent需要能记住你的喜好、脾气,通过长期的相处,真正成为“最懂你的私人助理”,在完成任务和提供情绪价值之间找到平衡。
- 超长周期的信用分配(Long-horizon Reasoning): 这是目前最大的痛点。让AI做个5步的任务它能行,让它连续干1000个步骤的任务(比如开发一个大型软件),中间只要错一步,就会像“蝴蝶效应”一样全面崩盘。如何让AI在长周期任务中不迷失方向,准确知道是哪一步做错了?这依然是个世界级难题。
- 世界模型(World Models): 人类之所以能做长期规划,是因为我们在脑子里能模拟物理世界的运行规律。AI现在还缺乏这种“内化模拟器”。未来的智能体需要和“世界模型”结合,在真正行动前,先在脑子里“彩排”一遍。
- 多智能体的规模化训练: 现在的多智能体协作多半还是人工设计的规则。如何让成百上千个不同类型的AI像人类社会一样,完全自发地进行强化学习,涌现出合理的社会分工和经济规律?
- 潜在空间推理(Latent Reasoning): 现在的AI在思考时,必须得用人类的自然语言把步骤“说出来”(Chain of Thought)。但实际上,人类很多直觉思考是潜意识的,不可言说的。未来的AI能否在它的“内部高维神经验空间”里默默完成极其复杂的推理,从而大幅提升计算效率?
- 治理与安全(Governance): 给AI赋予了思考、使用工具乃至花钱的权力后,风险急剧上升。如果一个自主探索网页的Agent不小心触发了黑客留下的恶意指令,或者删除了数据库,谁来负责?我们需要一套全新的针对智能体级别的安全护栏。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献157条内容
已为社区贡献157条内容

所有评论(0)