大模型知识体系 L3-1 RAG知识库 进阶篇
01
RAG常见痛点分析及建议方案
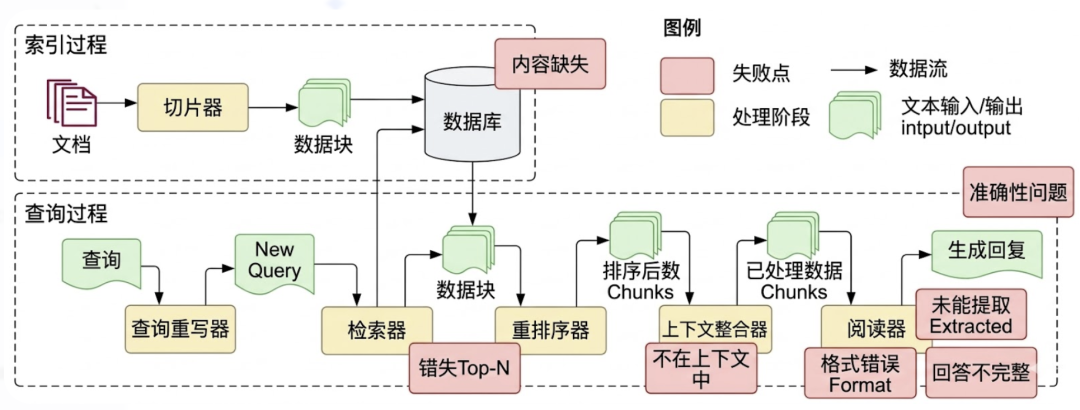
| 失败痛点 | 痛点描述 | 优化建议 / 解决方案 |
| 1. 内容缺失 (Missing Content) | 知识库中不存在回答问题所需的知识。 | 1. 增加知识库:将相关文本加入向量库。 2. 数据清洗与增强:提高输入数据质量。 3. 优化 Prompt:引导模型在无答案时回答“无法回答”,防止胡乱回答。 |
| 2. 文档加载准确性与效率 | 文档格式不一导致读取效果差。 | 1. 优化读取器:针对不同文档格式设计专门的读取器。 2. 数据清洗:对原始数据进行预处理。 |
| 3. 切分粒度问题 | 文档切分方式影响语义连贯性与模型表现。 | 1. 结构化分块:利用 HTML/Markdown 标题段落保持逻辑。 2. 递归分块:按段落、换行、空格等规则不断细分。 3. 优化 Chunk Size:匹配嵌入模型最佳输入大小(如 256/512)。 4. 内容重叠 (Overlapping):保持块间语义连贯。 |
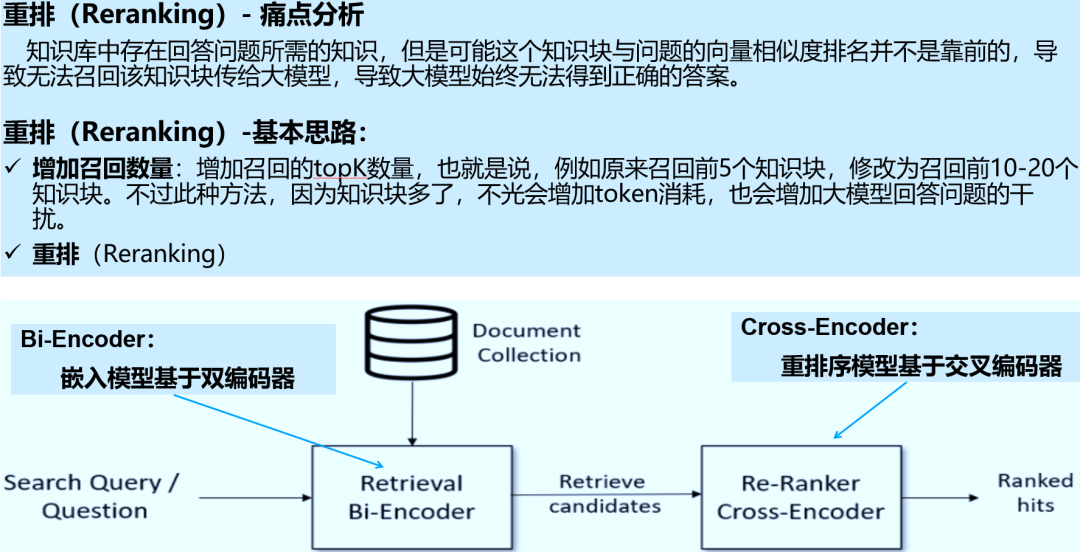
| 4. 错过排名靠前的文档 (Missed Top Ranked) | 知识块存在但向量相似度排名靠后,导致无法召回。 | 1. 增加召回数量:提高 TopK 召回阈值(如从 3 增加到 5)。 2. 重排 (Reranking):利用 Reranker 重新评估候选块的相关性。 |
| 5. 提取上下文与答案无关 (Not in Context) | 召回的内容无法有效支持答案生成。 | 这是“内容缺失”或“错过排名靠前文档”的具体体现。 |
| 6. 格式错误 (Wrong Format) | 模型输出未遵循要求的格式。 | 1. Prompt 调优:明确格式要求。 2. 格式验证:使用 Pydantic 等工具进行校验。 3. 自修复 (Auto-Fixing):对不合规格式进行自动修正。 |
| 7.答案不完整 (Incomplete) | 回答遗漏部分信息或过于片面。 | 1. 引导用户:鼓励一次提问一个问题。 2. 问题拆分:将复杂问题拆分为子问题,汇总后再回复。 |
| 8.提取到答案 (Not Extracted) | 模型在提供的上下文中未能找到正确答案。 | 1. 更换模型:使用推理能力更强的大模型。 2. 增强聚焦:在 Prompt 中强调必须基于上下文,或对关键句加粗。 |
| 9.答案太具体或太笼统 (Incorrect Specificity) | 回答的详略程度不符合预期。 | 1. 改善提示词:在 Prompt 中明确要求的特异性程度。 2. 提升基座能力:使用更高水平的底座模型。 |
02
高级RAG
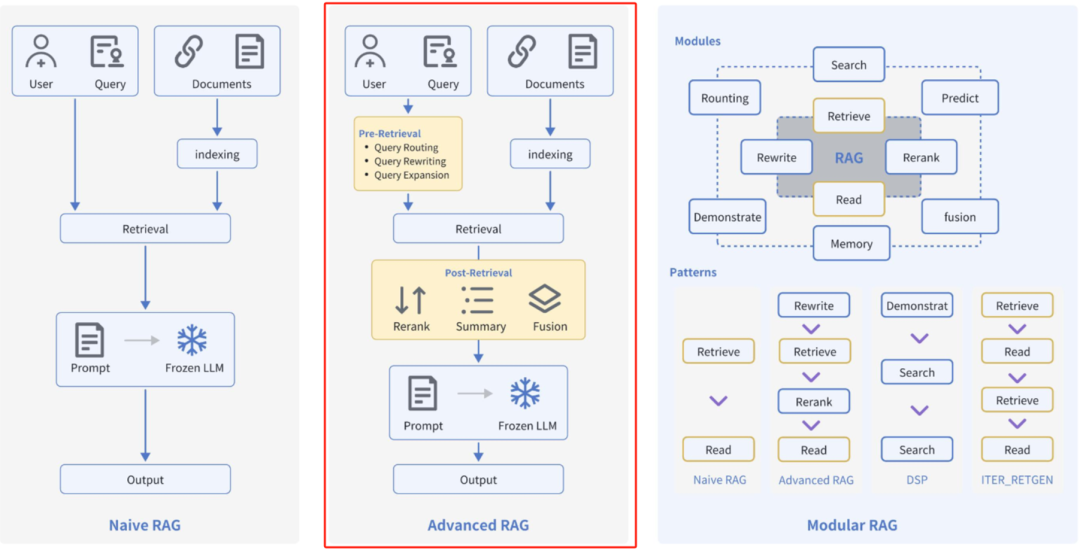
Advanced RAG重点聚焦在检索增强,即优化Retrieval阶段。增加了Pre-Retrieval预检索和Post-Retrieval后检索阶段,同时对检索本身也有优化。
- 预检索过程优化/检索前优化(Pre-Retrieval)
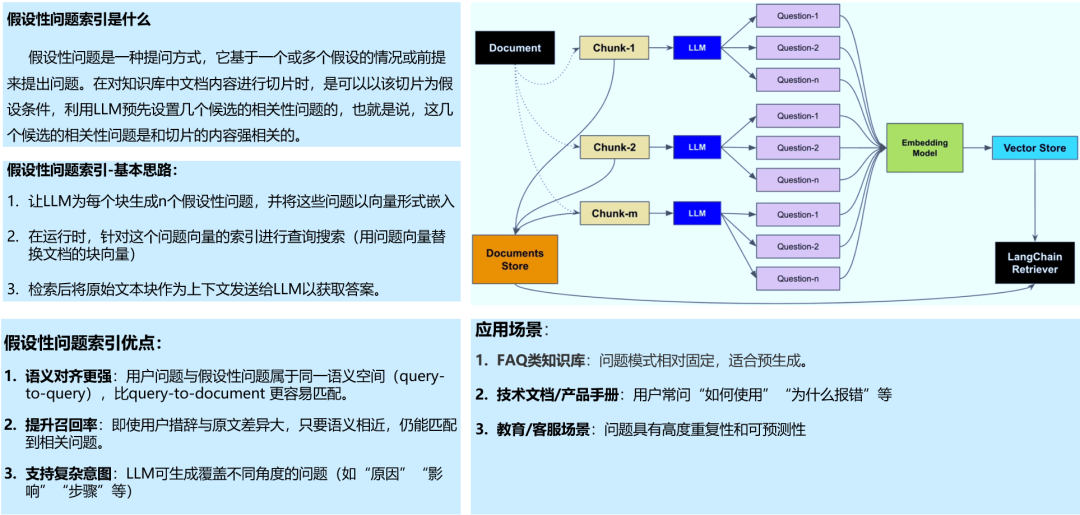
高级RAG着重优化了索引结构和查询的方式。优化索引旨在提高被索引内容的质量,包括增强数据颗粒度、优化索引结构、添加元数据、对齐优化等策略。查询优化的目标则是明确用户的原始问题,使其更适合检索任务,使用了查询重写、查询转换、查询扩展等技术。下面讲述索引优化和查询优化的方式:
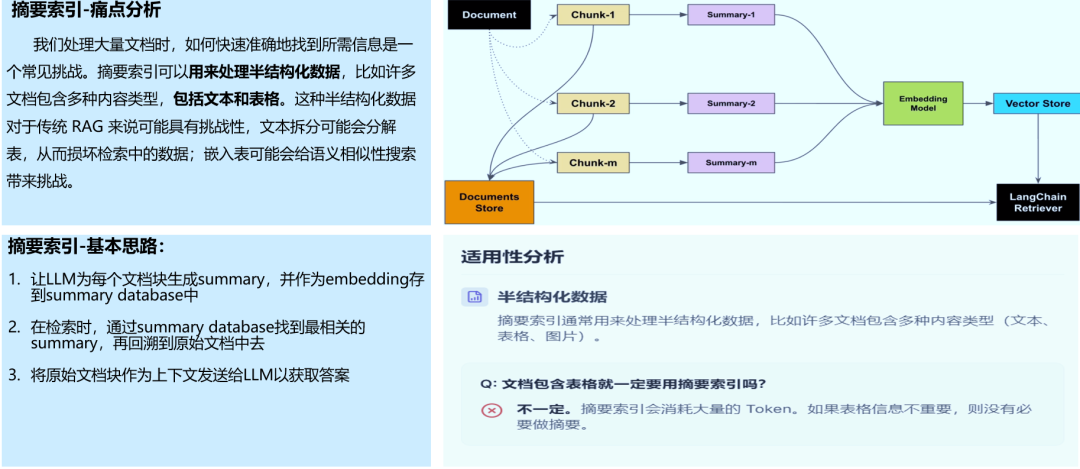
1.1 摘要索引
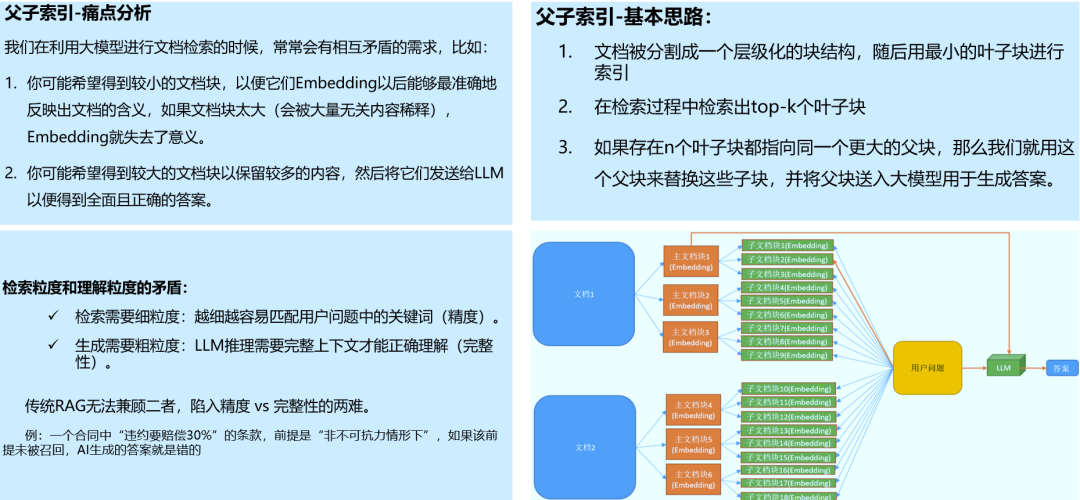
1.2 父子索引
1.3 假设性问题索引
1.4 元数据索引

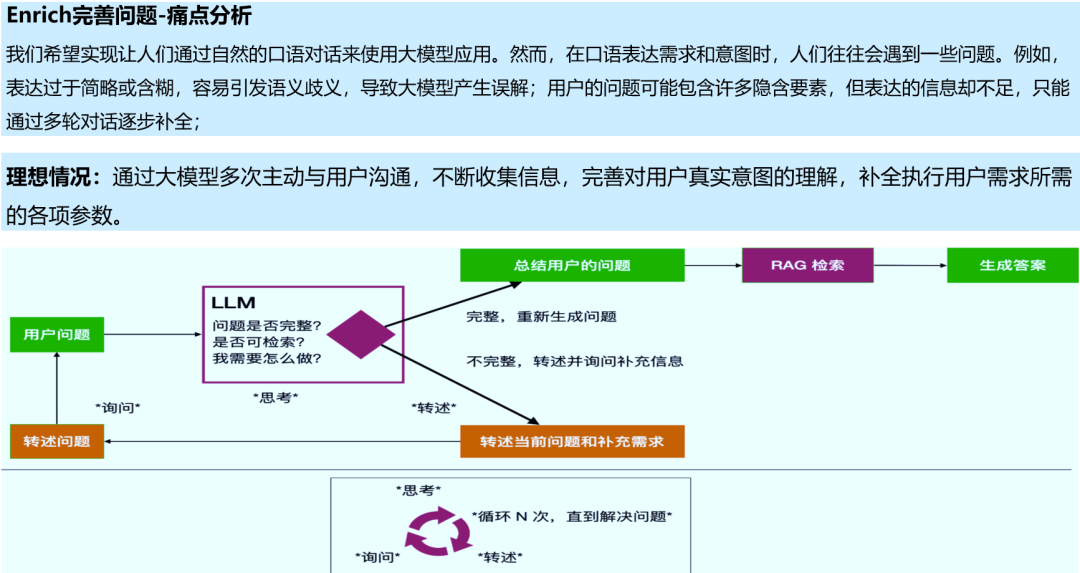
1.5 Enrich完善问题
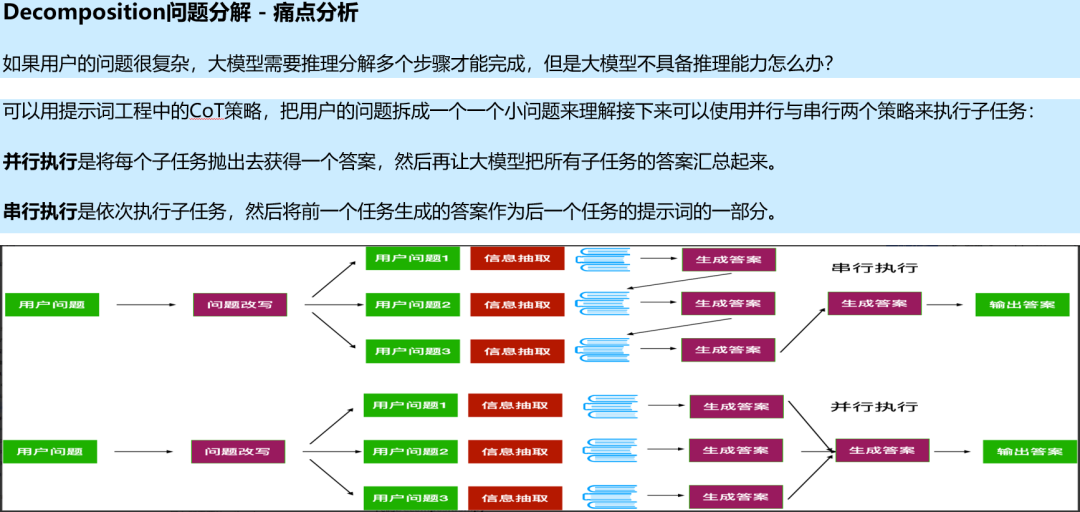
 1.6 多路召回
1.6 多路召回

1.7 多路召回
- 检索优化(Retrieval)
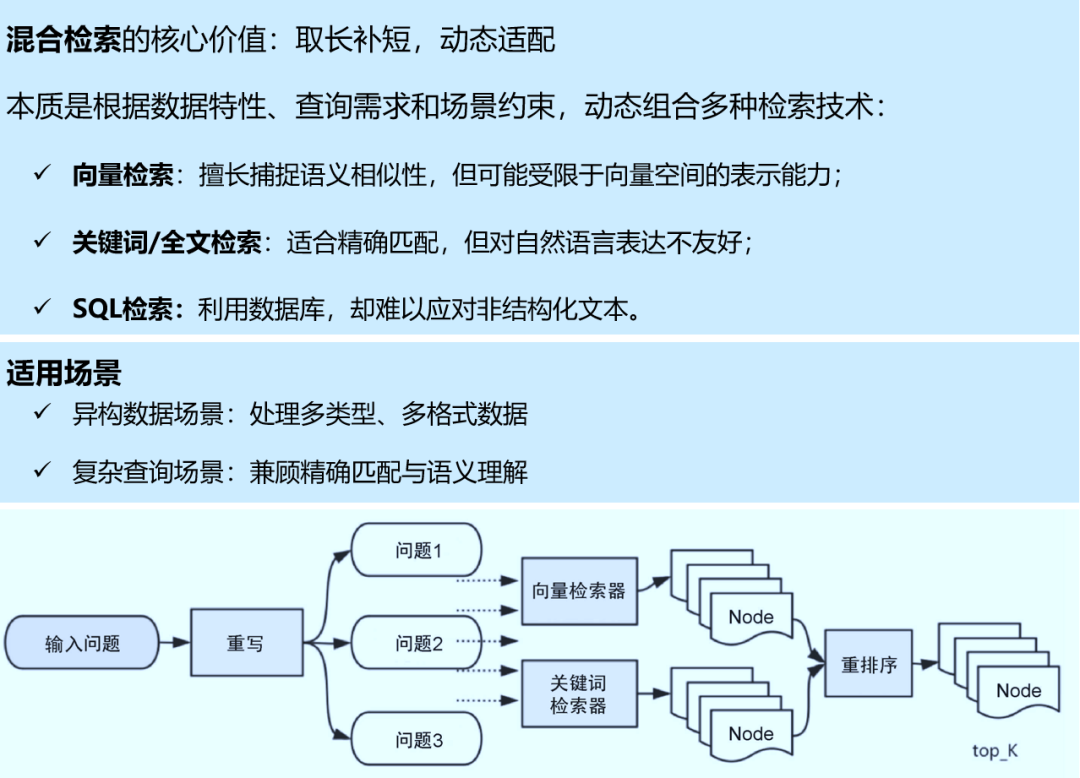
检索阶段的目标是确定最相关的上下文。通常,检索基于向量搜索,它计算查询与索引数据之间的语义相似性。因此,大多数检索优化技术都围绕嵌入模型展开,比如微调嵌入模型,将嵌入模型定制为特定领域的上下文,特别是对于术语不断演化或罕见的领域。还有其他检索技术,例如:混合搜索,通常是指将向量搜索与基于关键字的搜索相结合的概念。
- 后检索过程优化/检索后优化(Post-Retrieval)
对于由问题检索得到的一系列上下文,后检索策略关注如何优化它们与查询问题的集成。这一过程主要包括重新排序、RAG-Fusion和压缩上下文。重新排列检索到的信息,将最相关的内容予以定位标记,这种策略已经在LlamaIndex2、LangChain等框架中得以实施。有时直接将所有相关文档输入到大型语言模型(LLMs)可能导致信息过载,为了缓解这一点,后检索工作集中选择必要的信息,强调关键部分,并限制了相应的上下文长度。
3.1 重排(Reranking)
3.2 RAG-Fusion 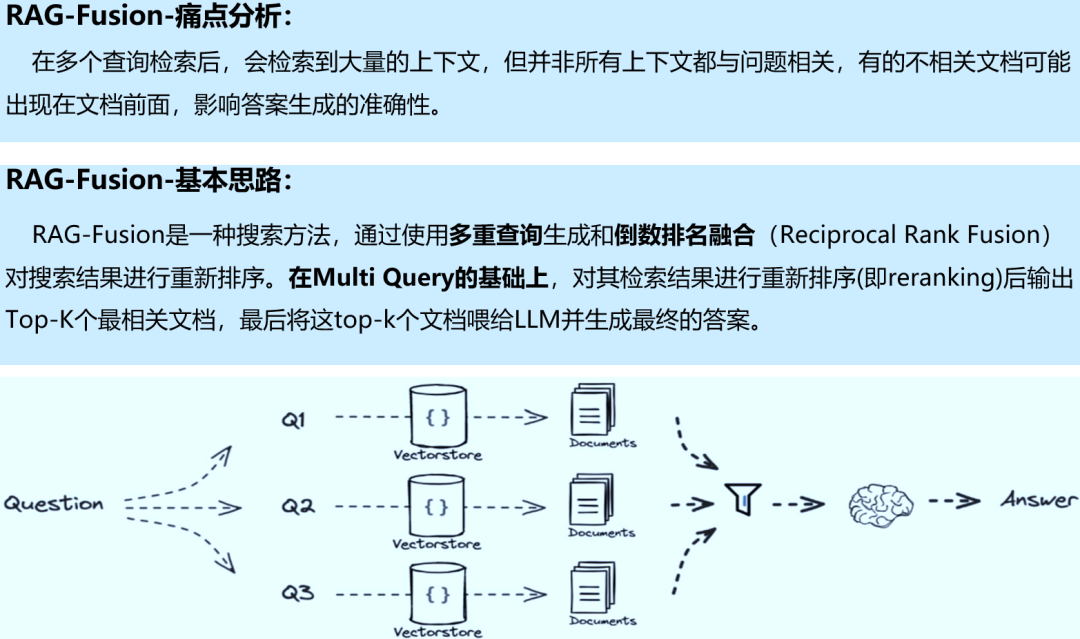 3.3 压缩上下文
3.3 压缩上下文 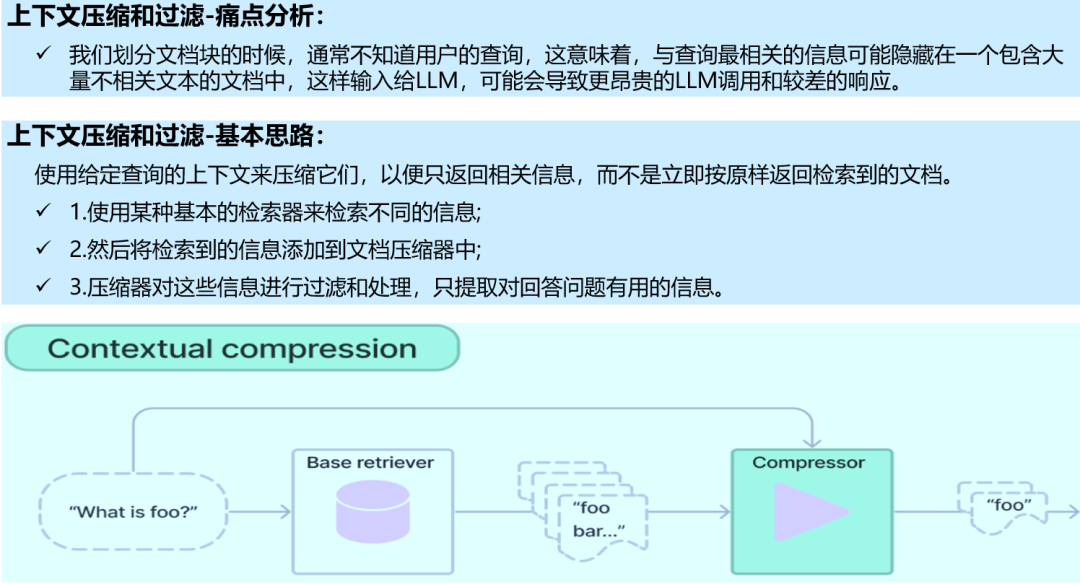
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献135条内容
已为社区贡献135条内容

所有评论(0)