基于粒子群算法PSO优化长短期记忆网络算法LSTM的数据回归预测 - PSO-LSTM
基于粒子群算法PSO优化长短期记忆网络算法LSTM的数据回归预测 PSO—LSTM 多输入单输出预测 相关指标计算有决定系数R2,平均绝对误差MAE,平均误差ME,均方误差跟RMSE 内涵详细的代码注释
在数据预测领域,长短期记忆网络(LSTM)是一种强大的工具,但有时其性能还可以进一步提升。粒子群算法(PSO)则是一种优化算法,能够帮助我们找到更优的参数组合,从而提升模型的表现。今天就来聊聊基于粒子群算法PSO优化长短期记忆网络算法LSTM的数据回归预测,也就是PSO-LSTM。
1. 相关指标计算
在评估预测模型的性能时,我们常用到几个关键指标,比如决定系数R2、平均绝对误差MAE、平均误差ME、均方误差和RMSE。
1.1 决定系数R2
R2衡量了回归模型对观测数据的拟合程度。其值越接近1,表示模型拟合得越好。计算公式如下:
\[R^{2}=1-\frac{\sum{i=1}^{n}(y{i}-\hat{y}{i})^{2}}{\sum{i=1}^{n}(y_{i}-\bar{y})^{2}}\]
其中,\(yi\)是实际值,\(\hat{y}i\)是预测值,\(\bar{y}\)是实际值的均值。
1.2 平均绝对误差MAE
MAE计算了预测值与实际值之间绝对误差的平均值。它直观地反映了预测误差的大小。公式为:
\[MAE=\frac{1}{n}\sum{i=1}^{n}|y{i}-\hat{y}_{i}|\]
1.3 平均误差ME
ME是预测值与实际值误差的平均值。它能帮助我们了解预测的整体偏差方向。公式是:
\[ME=\frac{1}{n}\sum{i=1}^{n}(y{i}-\hat{y}_{i})\]
1.4 均方误差
均方误差(MSE)衡量了预测值与实际值之间平方误差的平均值。它对较大的误差更为敏感。公式为:
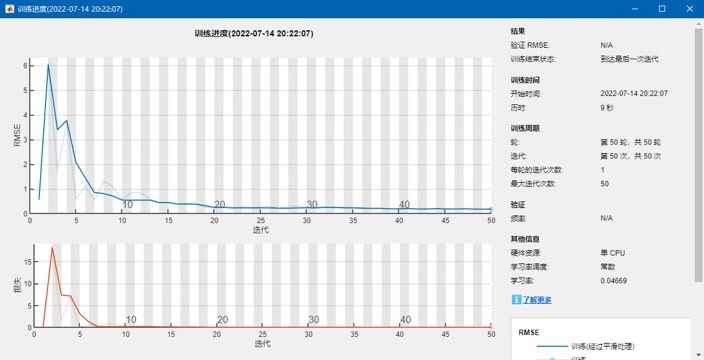
基于粒子群算法PSO优化长短期记忆网络算法LSTM的数据回归预测 PSO—LSTM 多输入单输出预测 相关指标计算有决定系数R2,平均绝对误差MAE,平均误差ME,均方误差跟RMSE 内涵详细的代码注释
\[MSE=\frac{1}{n}\sum{i=1}^{n}(y{i}-\hat{y}_{i})^{2}\]
1.5 均方根误差RMSE
RMSE是MSE的平方根,它将误差的尺度还原到与原始数据相同的尺度,更便于理解误差的实际大小。公式如下:
\[RMSE=\sqrt{\frac{1}{n}\sum{i=1}^{n}(y{i}-\hat{y}_{i})^{2}}\]
2. 代码实现
下面是PSO-LSTM多输入单输出预测的详细代码,并且带有丰富的注释,方便大家理解。
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import LSTM, Dense
from keras.callbacks import EarlyStopping
import random
# 粒子群算法参数
num_particles = 30
num_iterations = 100
c1 = 1.5
c2 = 1.5
w = 0.5
# 初始化粒子位置和速度
def initialize_particles(num_particles, num_params):
positions = np.array([[random.uniform(0, 1) for _ in range(num_params)] for _ in range(num_particles)])
velocities = np.array([[random.uniform(-1, 1) for _ in range(num_params)] for _ in range(num_particles)])
return positions, velocities
# 计算适应度(这里以均方误差作为适应度函数)
def calculate_fitness(model, X, y):
y_pred = model.predict(X)
mse = np.mean((y - y_pred) ** 2)
return mse
# 更新粒子速度和位置
def update_particles(positions, velocities, pbest_positions, pbest_fitness, gbest_position, gbest_fitness):
r1 = np.array([[random.random() for _ in range(len(positions[0]))] for _ in range(num_particles)])
r2 = np.array([[random.random() for _ in range(len(positions[0]))] for _ in range(num_particles)])
velocities = w * velocities + c1 * r1 * (pbest_positions - positions) + c2 * r2 * (gbest_position - positions)
positions = positions + velocities
for i in range(num_particles):
for j in range(len(positions[0])):
if positions[i][j] < 0:
positions[i][j] = 0
elif positions[i][j] > 1:
positions[i][j] = 1
return positions, velocities
# 构建LSTM模型
def build_lstm_model(input_shape, num_units, num_outputs):
model = Sequential()
model.add(LSTM(num_units, input_shape=input_shape))
model.add(Dense(num_outputs))
model.compile(optimizer='adam', loss='mse')
return model
# 数据预处理
def preprocess_data(data, look_back):
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(data)
X, y = [], []
for i in range(len(scaled_data) - look_back):
X.append(scaled_data[i:i + look_back])
y.append(scaled_data[i + look_back])
X = np.array(X)
y = np.array(y)
X = np.reshape(X, (X.shape[0], X.shape[1], 1))
return X, y, scaler
# 主函数
def main():
# 读取数据
data = pd.read_csv('your_data.csv')
data = data.dropna() # 去除缺失值
# 数据预处理
look_back = 10
X, y, scaler = preprocess_data(data.values, look_back)
num_params = 2 # 假设LSTM有两个可调整参数(这里可根据实际情况修改)
positions, velocities = initialize_particles(num_particles, num_params)
pbest_positions = positions.copy()
pbest_fitness = np.array([calculate_fitness(build_lstm_model((look_back, 1), int(positions[i][0]), 1), X, y) for i in
range(num_particles)])
gbest_index = np.argmin(pbest_fitness)
gbest_position = pbest_positions[gbest_index]
gbest_fitness = pbest_fitness[gbest_index]
for _ in range(num_iterations):
positions, velocities = update_particles(positions, velocities, pbest_positions, pbest_fitness, gbest_position,
gbest_fitness)
fitness_values = np.array([calculate_fitness(build_lstm_model((look_back, 1), int(positions[i][0]), 1), X, y) for i in
range(num_particles)])
improved_indices = fitness_values < pbest_fitness
pbest_positions[improved_indices] = positions[improved_indices]
pbest_fitness[improved_indices] = fitness_values[improved_indices]
current_best_index = np.argmin(pbest_fitness)
if pbest_fitness[current_best_index] < gbest_fitness:
gbest_position = pbest_positions[current_best_index]
gbest_fitness = pbest_fitness[current_best_index]
best_model = build_lstm_model((look_back, 1), int(gbest_position[0]), 1)
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
best_model.fit(X, y, epochs=100, batch_size=32, validation_split=0.2, callbacks=[early_stopping])
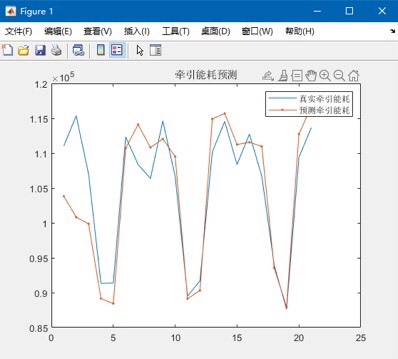
# 预测
last_sequence = data.values[-look_back:].reshape(1, look_back, 1)
last_sequence = scaler.transform(last_sequence)
prediction = best_model.predict(last_sequence)
prediction = scaler.inverse_transform(prediction)
print("预测结果:", prediction)
# 计算指标
y_pred = best_model.predict(X)
y_pred = scaler.inverse_transform(y_pred)
r2 = 1 - np.sum((y - y_pred) ** 2) / np.sum((y - np.mean(y)) ** 2)
mae = np.mean(np.abs(y - y_pred))
me = np.mean(y - y_pred)
mse = np.mean((y - y_pred) ** 2)
rmse = np.sqrt(mse)
print("R2:", r2)
print("MAE:", mae)
print("ME:", me)
print("MSE:", mse)
print("RMSE:", rmse)
if __name__ == "__main__":
main()
3. 代码分析
3.1 粒子群算法部分
initialize_particles函数用于初始化粒子的位置和速度。位置在0到1之间随机生成,速度也在-1到1之间随机生成。这里的范围设置是为了让粒子在搜索空间内有足够的探索范围。update_particles函数是粒子群算法的核心更新部分。通过引入随机数\(r1\)和\(r2\),根据公式更新速度和位置。同时,对位置进行边界处理,确保其在0到1之间,因为我们假设的参数范围是在这个区间内。
3.2 LSTM模型构建与训练部分
buildlstmmodel函数构建了一个简单的LSTM模型,包含一个LSTM层和一个全连接层。输入形状根据数据预处理后的情况设置,输出单元数也根据实际需求确定。- 在主函数中,通过PSO找到最优参数后构建最佳模型,并使用提前停止回调函数
EarlyStopping来防止过拟合。训练时划分了验证集,根据验证集的损失来决定是否停止训练并恢复最佳权重。
3.3 数据预处理与预测部分
preprocessdata函数对数据进行归一化处理,并将其转换为适合LSTM输入的格式。这里设置了lookback参数,用于确定输入序列的长度。- 最后通过训练好的模型进行预测,并计算各项性能指标。
通过这样的PSO-LSTM结合,我们可以在数据回归预测任务中获得更优的结果,希望这篇文章能帮助大家理解和应用这个方法!
这样的代码实现和分析是不是很清晰易懂呀😃 大家可以根据自己的数据和需求进一步调整和优化代码哦🧐
以上就是这篇关于PSO-LSTM数据回归预测的博文啦,希望对大家有所帮助!
你可以根据实际情况修改代码中的数据读取路径等部分,以适应你自己的数据。如果在运行过程中有任何问题,欢迎随时交流呀😄

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)