动手玩转 AI 工具(1):从大模型到 OpenClaw 的进阶之路
💡 核心思考:
AI 的演进路线,绝不仅仅是“聊天能力”变强了,而是它的“执行能力”在不断进化。从最开始的大模型到当前爆火的openclaw,背后是ai能力的不断下探;从prompt到现在的skill,我们也意识到ai时代最宝贵的财富其实是与ai的长期交互经验。如何与ai协作不断突破自身能力边界或许是当前社会最大的议题。
整个行业正在经历一次大迁徙:从单纯的大模型 (思考) ➡️ Workflow (走流程) ➡️ Agent (定目标) ➡️ MCP/Skill (长出手脚与经验) ➡️ OpenClaw 等平台 (个人自动化执行中枢)。
很多人第一次接触 AI,都是从一个聊天框开始的:问答、总结、写初稿。这容易让人产生一个误解:AI 无非就是一个“更强的搜索引擎”或“聪明的写作助手”。
但当你真的把 AI 引入复杂的日常工作流中,你会发现:真正的工作从来不是“一问一答”就能搞定的。写行业报告需要跨网页搜资料、核对数据源、整理逻辑;做产品方案需要调取历史文档、跨应用协同。大模型能帮你“想一段、写一段”,却不能替你“做完一整件事”。
这篇笔记梳理了过去两三年 AI 工具演进的真正主线。我们将结合真实的代表性工具,看看 AI 是如何从“会回答”一步步走向“会做事”的。
一、大模型时代(ChatBot):AI 的“认知外包”
最先爆发的 AI 革命其实是“认知外包”。这一阶段,AI 展现出了极高的智商,把高质量的文本生成、逻辑推理和复杂问答交给了普通用户。
- 它的本质: 一个无比聪明的“外置大脑”或“超级顾问”。
- 日常痛点: 极度依赖人工推进。你在使用时的真实状态往往是:在系统里提问 ➡️ 得到代码 ➡️ 复制到本地运行 ➡️ 报错 ➡️ 把报错信息粘贴回聊天框 ➡️ 再提问。模型只参与了认知节点,跑腿的还是你。
- 🛠️ 代表性工具:
- ChatGPT (OpenAI) / Claude (Anthropic) / Gemini (Google): 基础的对话与长文本处理。
- Kimi / 秘塔 / DeepSeek: 国内擅长长文档解析和深度搜索的大模型产品。
二、Workflow(工作流):AI 首次进入真实流程
当用户发现“会回答”不够用时,最自然的下一步,就是把 AI 这个“大脑”接到固定的流水线上。
- 它的本质: 按照预设的、确定的逻辑把一系列动作串联起来(If A happens, then do B, finally output C)。
- 应用场景: 假设你运营一个技术博客。以前你需要手动复制粘贴;接入 Workflow 后,变成了:系统定时抓取 RSS ➡️ 调用 OpenAI 总结摘要 ➡️ 自动写入 Notion ➡️ 发送微信/飞书通知。AI 在这里替代了“规则处理”的节点。
- 局限性: 极度依赖预设路径。一旦遇到环境变化、信息缺失或目标模糊,Workflow 就会报错卡死,显得非常僵硬。
- 🛠️ 代表性工具:
- Zapier / Make (原 Integromat) / n8n: 老牌自动化工具全面接入 AI 节点。
- Coze (扣子) / Dify 中的工作流编排功能: 允许用户用拖拽连线的方式,把 AI 和各种插件串起来。
三、Agent(智能体):从“按步骤执行”到“朝目标推进”
如果说 Workflow 是“我提前替你把每一步怎么走规划好”,那么 Agent 就是**“我只给你一个最终目标,你自己去决定该怎么走”** 。
- Workflow vs. Agent 的本质区别:
- Workflow (工作流):发票来了就入账、表单提交后发邮件。(结构稳定,路径唯一)
- Agent (智能体):帮我做一份行业竞品分析。(目标明确,路径不固定)
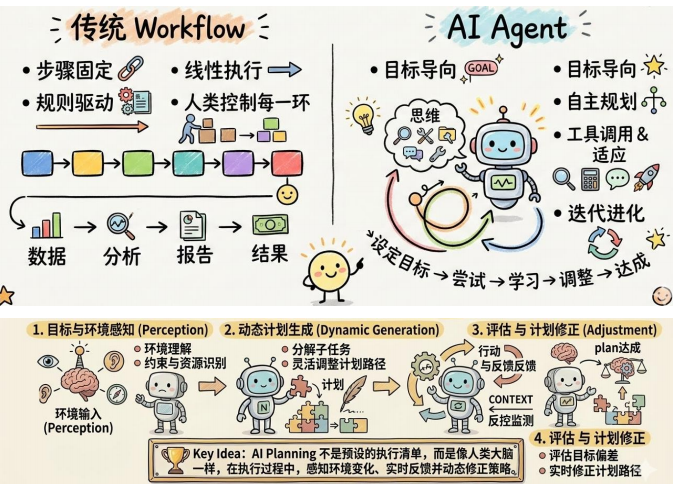
从两者的使用场景其实可以看出两者的区别主要是在workflow中大模型是作为一个工具被调用的,是被动发挥作用,它只是在某一环节接受其他工具传来的数据,处理好之后传递给下一个工具;但是在agent中,大模型是作为大脑,对其他工具进行调用的,是主动发挥作用的。
一个真正能做事的 Agent 是如何运转的?
它绝不仅仅是一个聪明的模型,而是一套包含 5 个组件的闭环系统:
Agent = 会思考的大脑(LLM) + 会拆解任务的能力(Planning) + 会用外部工具的手和脚
(Tool Use) + 会记住信息的记忆(Memory) + 会边做边改的自我纠偏机制(Feedback Loop)
- 🧠 LLM (大脑): 核心驱动力,负责理解你的意图和逻辑推理。
- 🗺️ Planning (规划): 面对复杂任务(如竞品分析),它不会立刻瞎写,而是先在脑海中拆解:第一步查什么,第二步对比什么指标,第三步怎么排版。
- 🛠️ Tool Use (工具调用): 它的手和脚。它能自己决定何时去搜索网页、何时去读取本地文档、何时去跑一段 Python 代码。
- 💾 Memory (记忆): 保证它“不失忆”。它记得你们昨天的讨论,也记得上一个步骤查到的数据,跨轮次维持上下文。
- 🔄 Feedback Loop (反馈与纠偏): 这是它最像人的地方。如果在搜索中发现某个竞品倒闭了,它会自我纠偏:“哦,这个数据作废,我得换个搜索词重新查”,而不是傻傻地报错停下。
Agent = 会思考的大脑(LLM) + 会拆解任务的能力(Planning) + 会用外部工具的手和脚
(Tool Use) + 会记住信息的记忆(Memory) + 会边做边改的自我纠偏机制(Feedback Loop)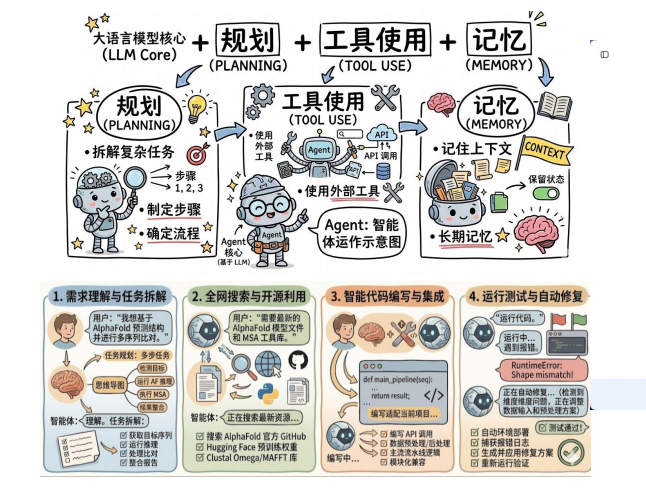
- 🛠️ 代表性工具:
- AutoGPT / Minmax: 早期探索自主目标的开源先驱。
- Claude code / Cursor / GitHub Copilot Workspace: 软件开发领域的顶尖 Agent,能自己读需求、改代码、修 Bug。
- Microsoft Copilot Studio / 钉钉 AI 助理: 面向企业,能够自主调用企业数据库完成任务的智能体平台。
四、基础设施的进化:Function Calling、MCP 与 Skill
Agent 凭什么能“触碰”真实世界?凭什么能越来越老练?这得益于底层技术的三个关键跨越:
-
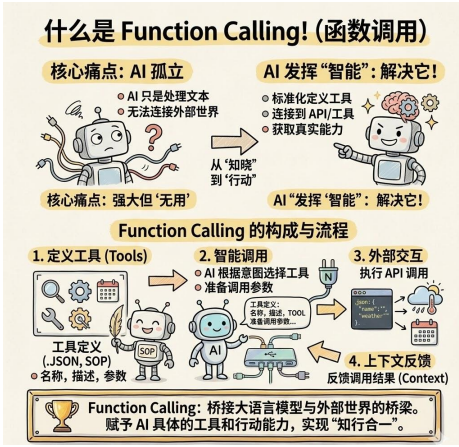
Function Calling(赋予手脚): 以前大模型只能用文字说“建议你查一下天气”,有了 Function Calling 这个标准动作接口,模型可以直接向系统发送指令:“现在,请执行查询天气的函数 API”。AI 真正从“动嘴”变成了“动手”。
-
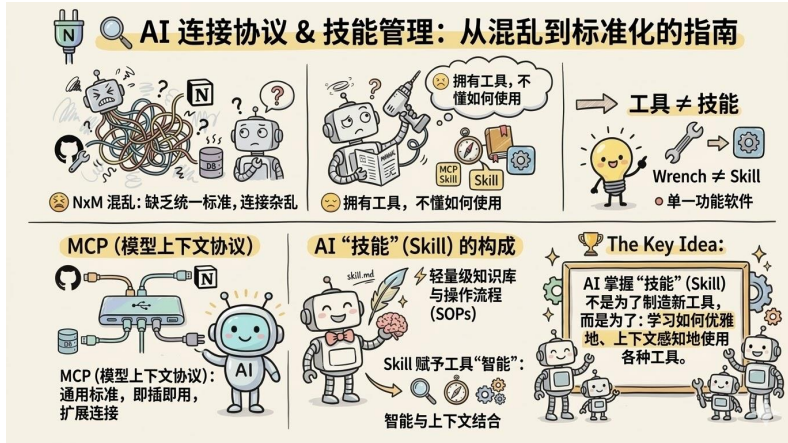
MCP(统一连接标准): 当 Agent 需要连接的工具成百上千(数据库、日历、邮箱、内部 ERP)时,每个接口的格式都不同。MCP (Model Context Protocol) 就像是 AI 时代的“USB 接口标准”。它解决的是:“当工具多到爆炸时,我们该怎么有秩序地把它们接入大模型”。
-
Skill(沉淀专家经验): 真正拉开 AI 差距的,不是你接了多少工具,而是你有没有把“做成一件事的经验”沉淀下来。比如“写技术博客”,不仅是搜索+打字,还需要知道术语密度如何控制、何时该举例。把这套人类的高级认知和工作法封装成可复用的模块,就是 Skill。
五、OpenClaw 时代:个人 AI 执行平台的真正落地
经历了前几个阶段的演进,当 AI 工具试图从“单点任务响应”走向“本地化、规模化的复杂任务跑动”时,单兵作战的 Agent 开始显露疲态。于是,我们迎来了 OpenClaw 时代。
为什么需要它?它解决了上一个阶段的什么痛点?
过去,即使我们用上了 Agent,依然面临几个无法跨越的障碍:
- 单 Agent 的能力瓶颈: 试图让一个 AI 既当程序员、又当产品经理、还要做测试,它很容易“幻觉”或顾此失彼。
- 每次都要“从头教起”: 专家经验很难在系统中沉淀为可复用的能力模块。
- 本地控制权与隐私: 核心代码、私密财务文档不敢完全交给云端 Agent 去处理。
OpenClaw 的技术架构与核心能力(它凭什么能做到?)
在 GitHub 的官方定义中,OpenClaw 是“Your personal, open source AI assistant”。它不是一个简单的套壳网页,而是一个需要通过命令行(如 openclaw onboard)在 macOS、Linux 或 Windows (WSL2) 本地部署的底层系统。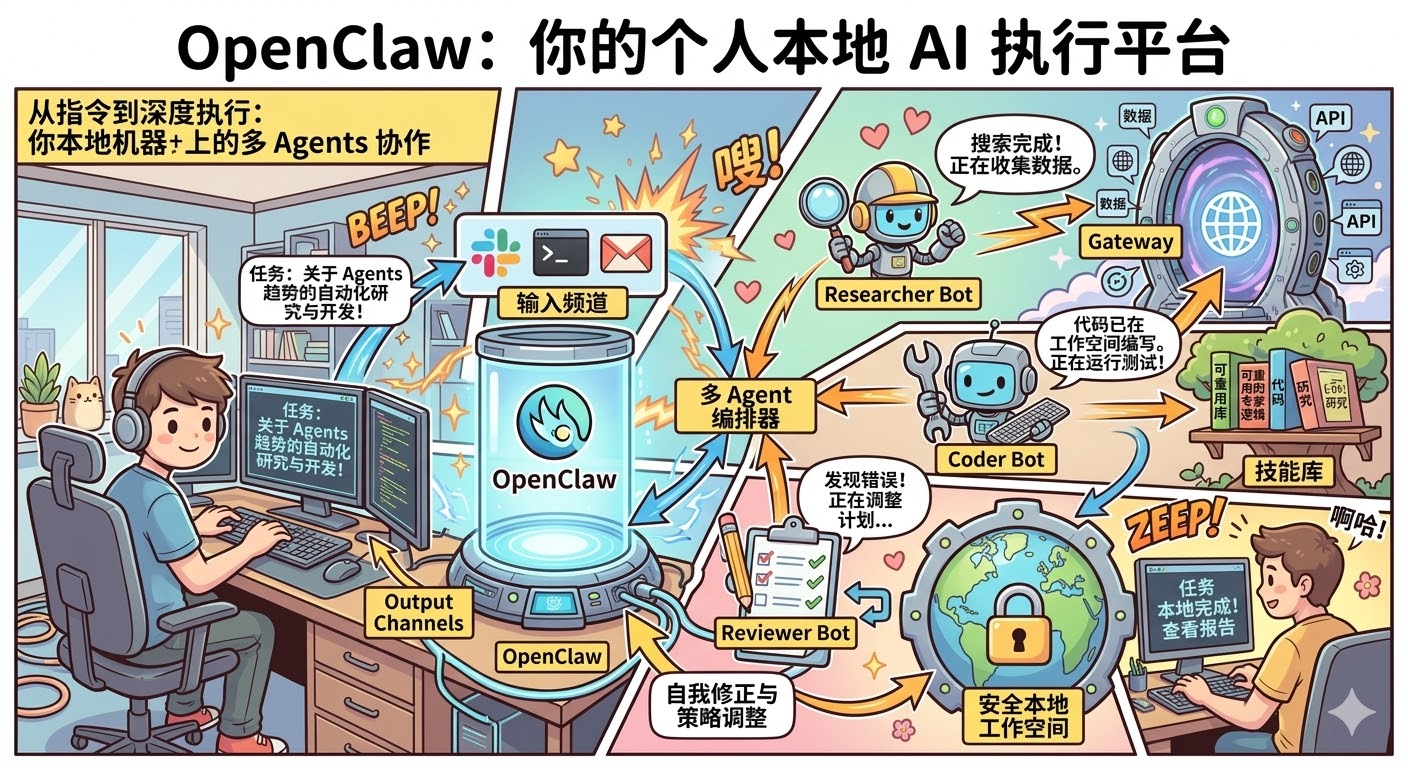
它的强大,得益于以下五大核心技术模块的支撑:
🔌 Gateway(网关层)—— 解决“连接与越界”: 系统的咽喉。它打破了聊天框的限制,通过标准 API,安全地接入你的本地文件系统和第三方网络服务。
📡 Channels(多端分发)—— 解决“交互入口”: AI 助理不再只活在浏览器里,它可以化身为终端命令行里的脚本,或者 Slack、微信里的一个后台监听机器人。
📂 Workspace(本地工作区)—— 解决“数据主权”: 强依赖本地环境。它在你的电脑里划出一块安全区域处理数据,确保隐私不泄露,同时保持极长的任务上下文。
🧩 Skills(技能库模块化)—— 解决“经验沉淀”: 彻底改变“靠 Prompt 驱动机器”的方式。你可以将“如何按特定格式清洗运营数据”固化为可插拔的模块(Skill),系统能力会随着 Skill 的积累产生复利。
🤖 Multi-Agent(多智能体协同)—— 解决“单兵作战的局限”: 这是它处理复杂任务的杀手锏。OpenClaw 的底层架构支持多 Agent 编排。你可以配置一个负责搜集资料的“调研员 (Researcher)”、一个负责写代码的“程序员 (Coder)”和一个负责找 Bug 的“审查员 (Reviewer)”。平台负责在它们之间传递上下文、调度优先级,让它们像一个小型数字团队一样自我辩论、互相纠错、协作交付。
- 它能解决哪些具体的真实问题?(应用场景)
结合上述架构,特别是多 Agent 的加入,OpenClaw 将 AI 的能力边界推向了深度执行:
-
本地复杂自动化(单人变团队): 以前你只能让 AI “帮我写一段爬虫”。现在你可以给 OpenClaw下达宏大任务:“帮我开发一个小工具”。底层的 Multi-Agent 会自动分工:Agent A 去网上查最新的 API 文档,Agent B 负责在本地 Workspace 写代码,Agent C 负责运行测试并把报错丢回给 B。全过程在本地无缝运转。
-
跨应用的持续监听与流转: 让它作为后台服务监听指定频道。比如收到一封包含竞品动态的邮件,调度 Agent 提取关键信息,接着唤醒分析Agent 对比历史数据,最后让写作 Agent 生成简报存入本地知识库。
它的行业意义:
OpenClaw 折射出 AI 正在从“局部场景生成代码/文字”走向“规模化、本地化地跑任务”。它代表了一条清晰的路线:AI 不再只存在于网页侧边栏,而是开始深入你的本地操作链、消息链和技能链。
(部分图片来自深势科技课程,课程链接: https://www.bohrium.com/courses/4832783200/?tab=courses)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)