计算机毕业设计源码:Python 旅游景点信息采集分析可视化系统 Django框架 selenium爬虫 旅行 出行 数据分析 大模型 大数据 agent(建议收藏)✅
·
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈
Python作为主要开发语言,MySQL作为数据存储数据库,Django作为后端Web框架,selenium用于携程网旅游数据的爬取采集,HTML用于前端页面展示。
功能模块
· 旅游景点信息采集模块
· 注册登录模块
· 系统数据概况模块
· 数据可视化大屏模块
· 景区级别扇形图分析模块
· 评论排名模块
· 热门景区模块
· 景点评分排名模块
· 景区热度词云分析模块
· 后台管理模块
项目介绍
本系统是一个基于Python的旅游景点信息采集分析可视化平台。系统通过selenium爬虫框架对携程网旅游数据进行自动化采集,获取景区名称、等级、评分、热度、评论数等关键信息,并将数据存储于MySQL数据库中。后端采用Django框架进行业务逻辑处理和系统搭建,前端通过HTML页面实现数据可视化展示。系统包含数据采集、用户登录注册、后台数据管理以及多个数据可视化分析模块,能够以地图、词云、条形图、扇形图等多种形式展示景区等级分布、热度指数、评论排名、评分排行等分析结果,为用户提供直观的旅游数据查询与分析工具,帮助用户快速了解旅游市场情况。
2、项目界面
(1)旅游可视化大屏
该旅游数据可视化大屏包含景区等级分布、景区热度指数TOP、景区人次TOP、景区热度和评分关系、全国旅游景点分布地图及旅游景点词云图等功能模块,可多维度展示景区相关数据,为旅游数据分析提供直观可视化支撑。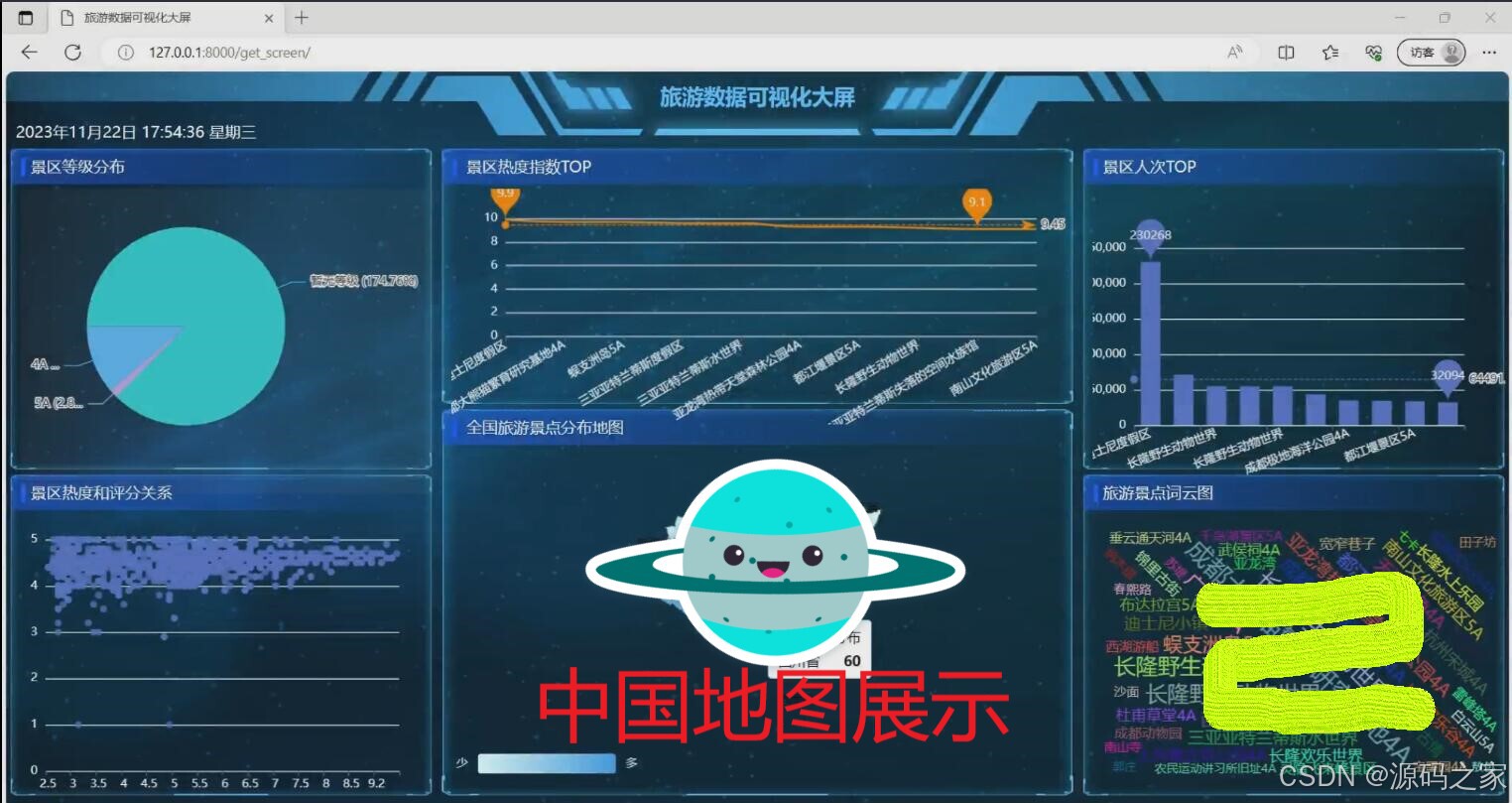
(2)系统首页—数据概况
该旅游景点信息可视化系统控制台页面展示旅游景点数据总量、不同等级景区数量等核心指标,呈现景区所在数量分布的中国地图,还涵盖景区级别扇形图、热门景区排行、评分排行、景区热度词云及后台管理等功能模块,全方位可视化呈现旅游景点相关数据。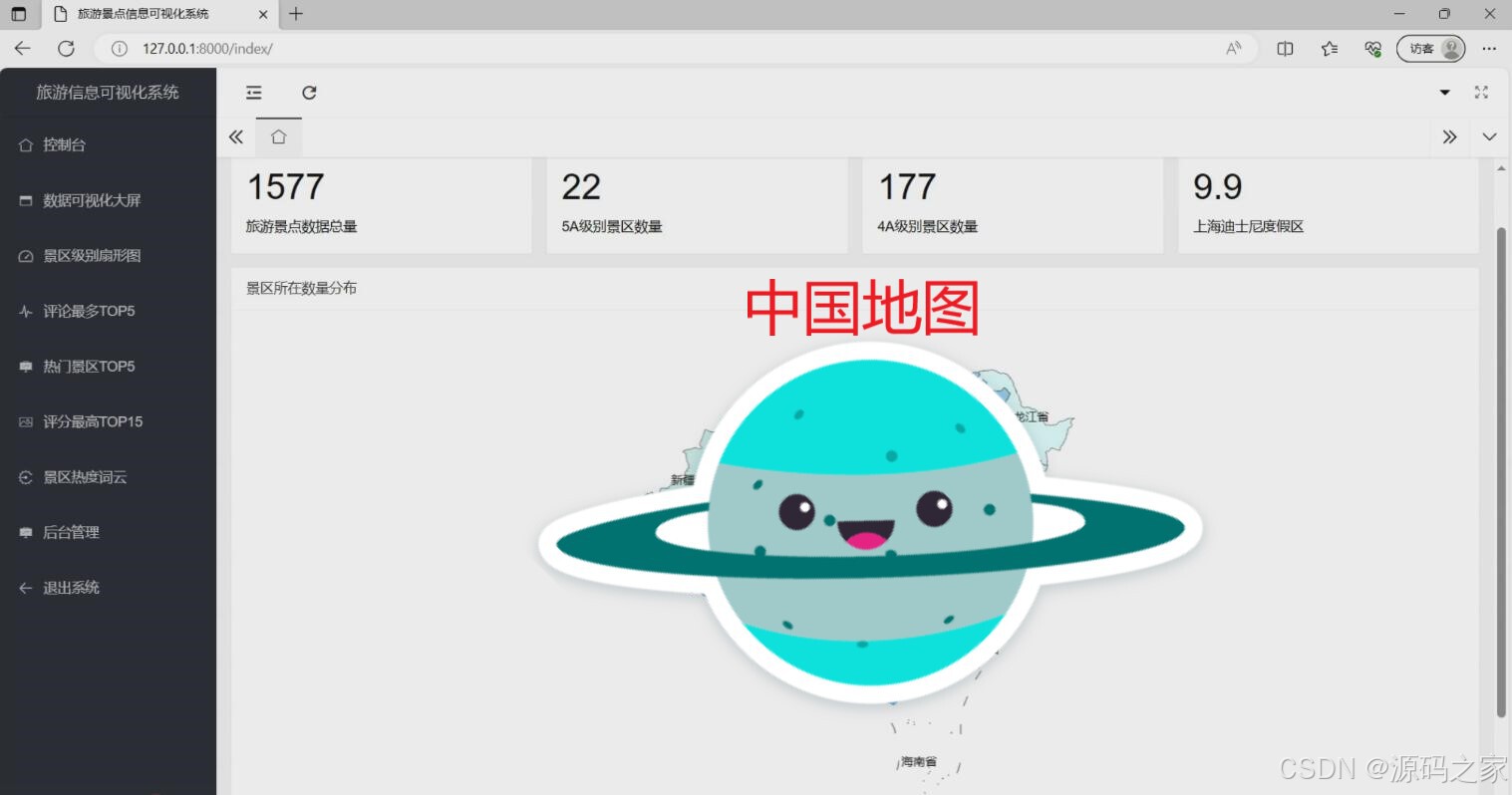
(3)词云图分析
这是旅游景点信息可视化系统的景区热度词云页面,系统整体具备控制台、数据可视化大屏(含景区级别扇形图、评论最多TOP5、热门景区TOP5、评分最高TOP15、景区热度词云)、后台管理等功能模块,当前页面以词云形式直观展示各景区热度分布,可切换不同可视化图表查看旅游数据。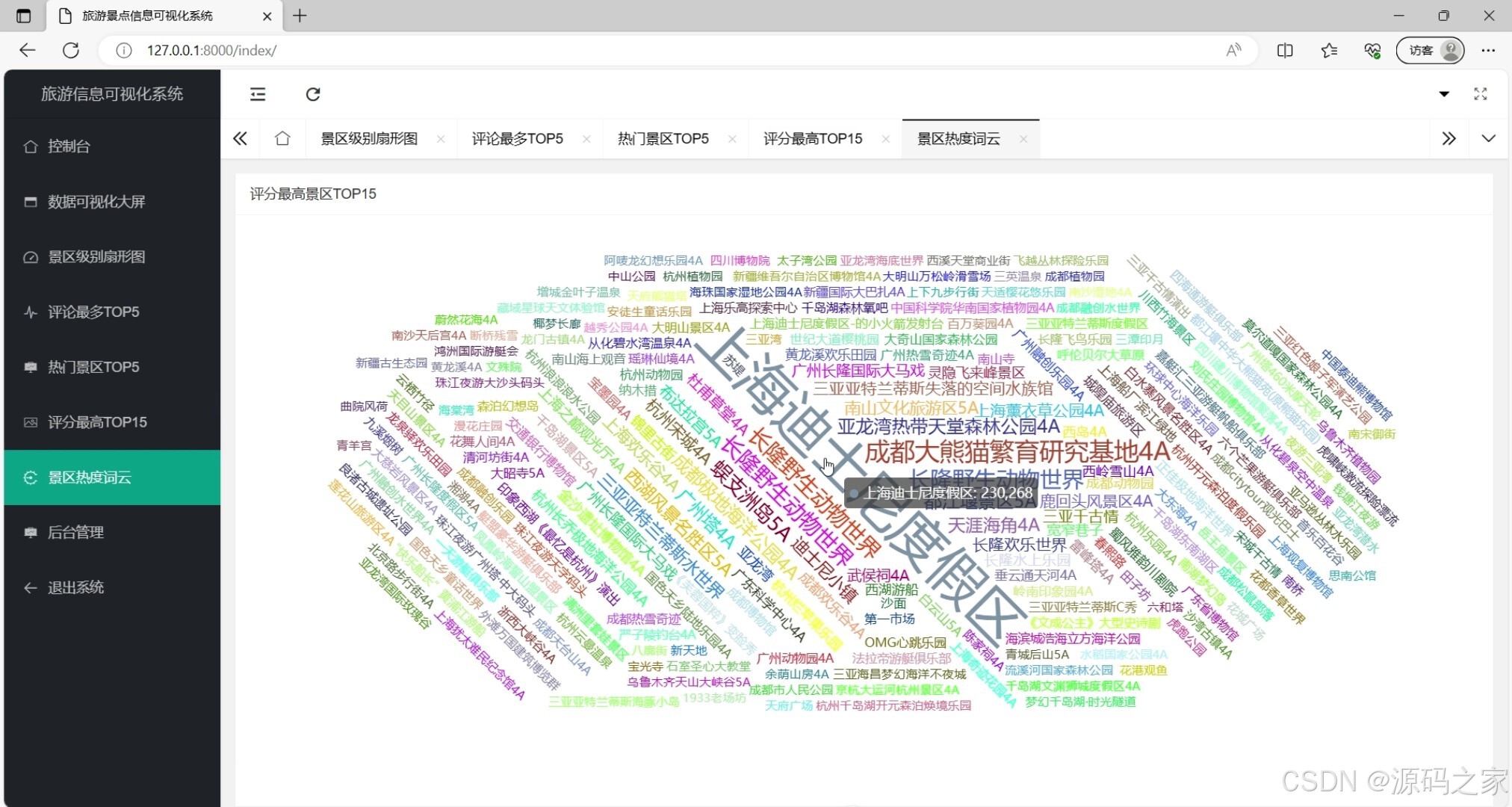
(4)评论前5景区
这是旅游景点信息可视化系统的评论最多景区TOP5展示页面,系统涵盖控制台、数据可视化大屏(含景区级别扇形图、评论最多TOP5、热门景区TOP5、评分最高TOP15、景区热度词云)、后台管理等模块,当前页面以条形图呈现评论量排名,交互显示具体景区评论数据,直观展示热门景区的评论热度。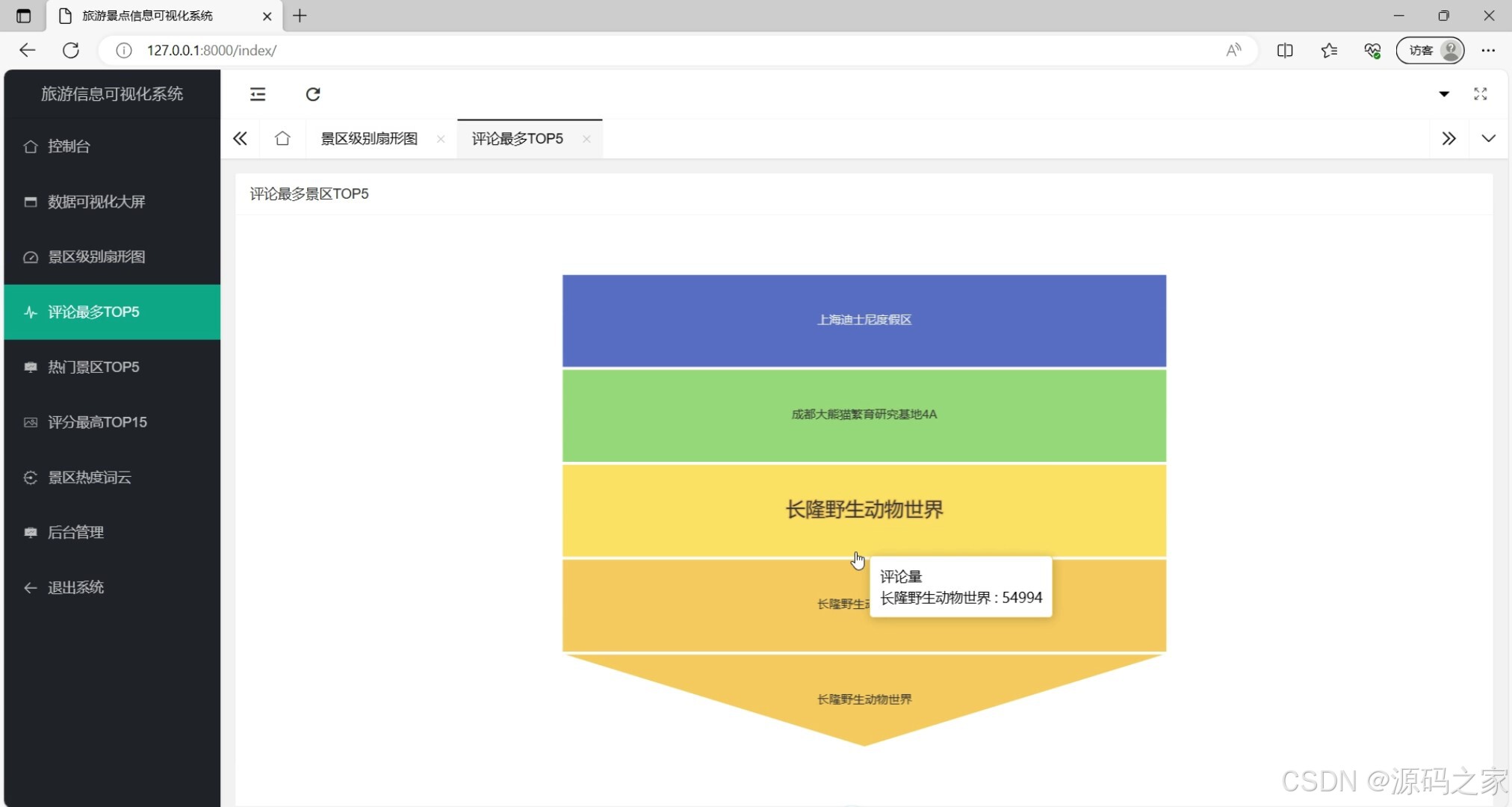
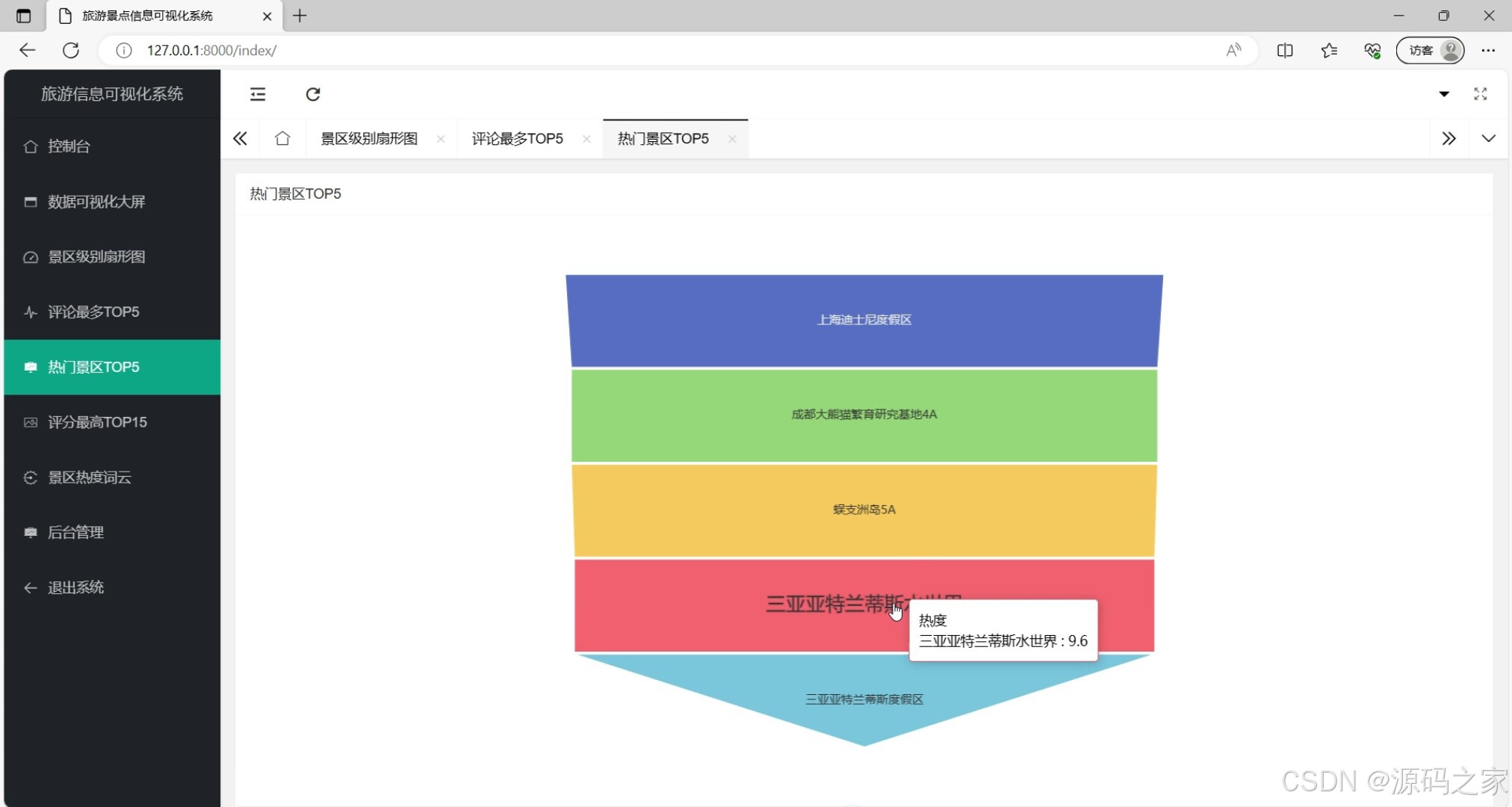
(5)热门景区前5
这是旅游景点信息可视化系统的热门景区TOP5展示页面,系统包含控制台、数据可视化大屏(含景区级别扇形图、评论最多TOP5、热门景区TOP5、评分最高TOP15、景区热度词云)、后台管理等功能模块,当前页面以条形图呈现热门景区热度排名,交互可查看对应景区热度信息,直观展现景区热度差异。
(6)评分前10的景区
这是旅游景点信息可视化系统的评分最高景区TOP15展示页面,系统涵盖控制台、数据可视化大屏(含景区级别扇形图、评论最多TOP5、热门景区TOP5、评分最高TOP15、景区热度词云)、后台管理等功能模块,当前页面以条形图呈现评分最高的景区排名,交互可查看对应景区评分信息,直观展现各景区的评分差异。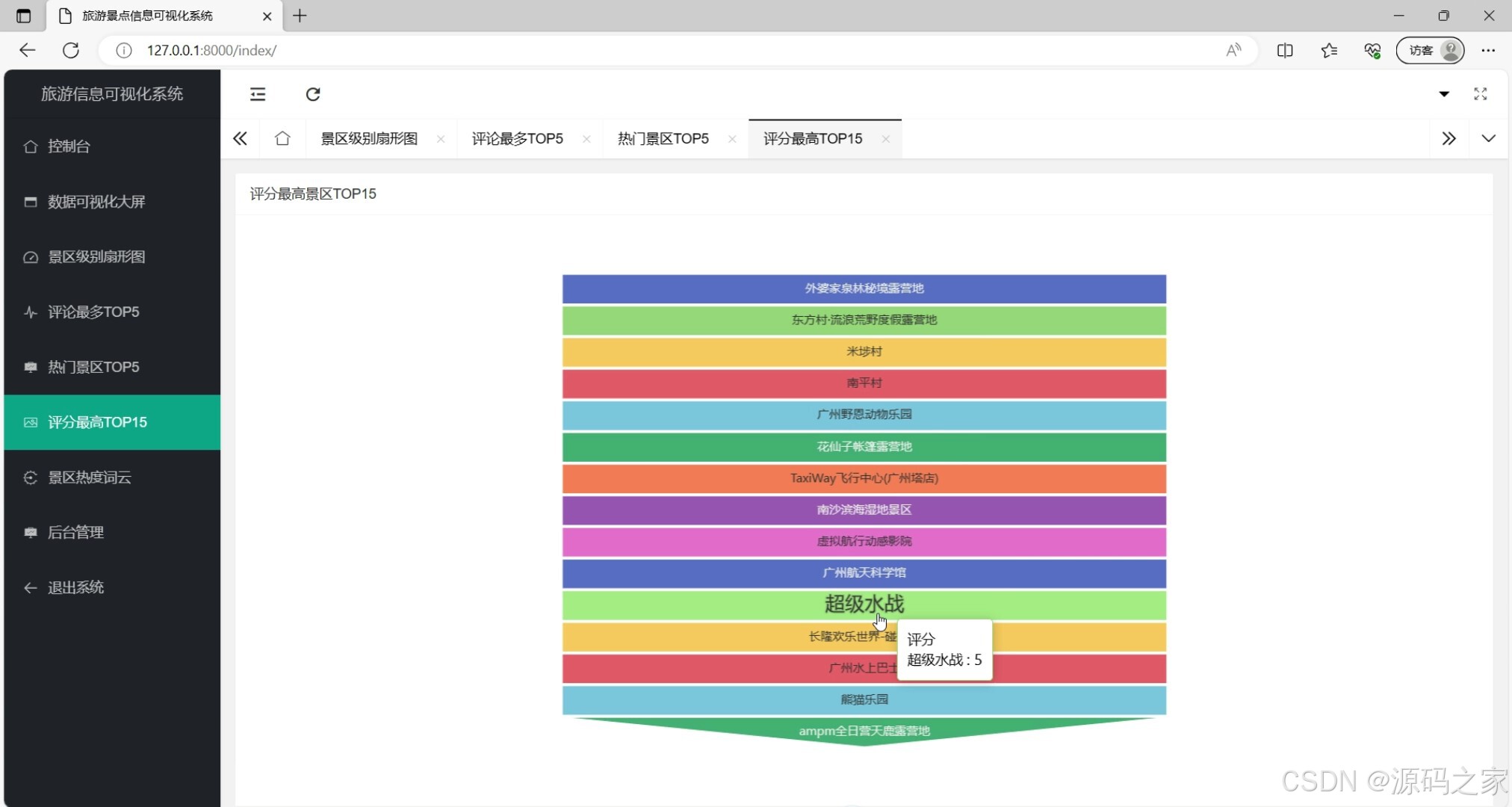
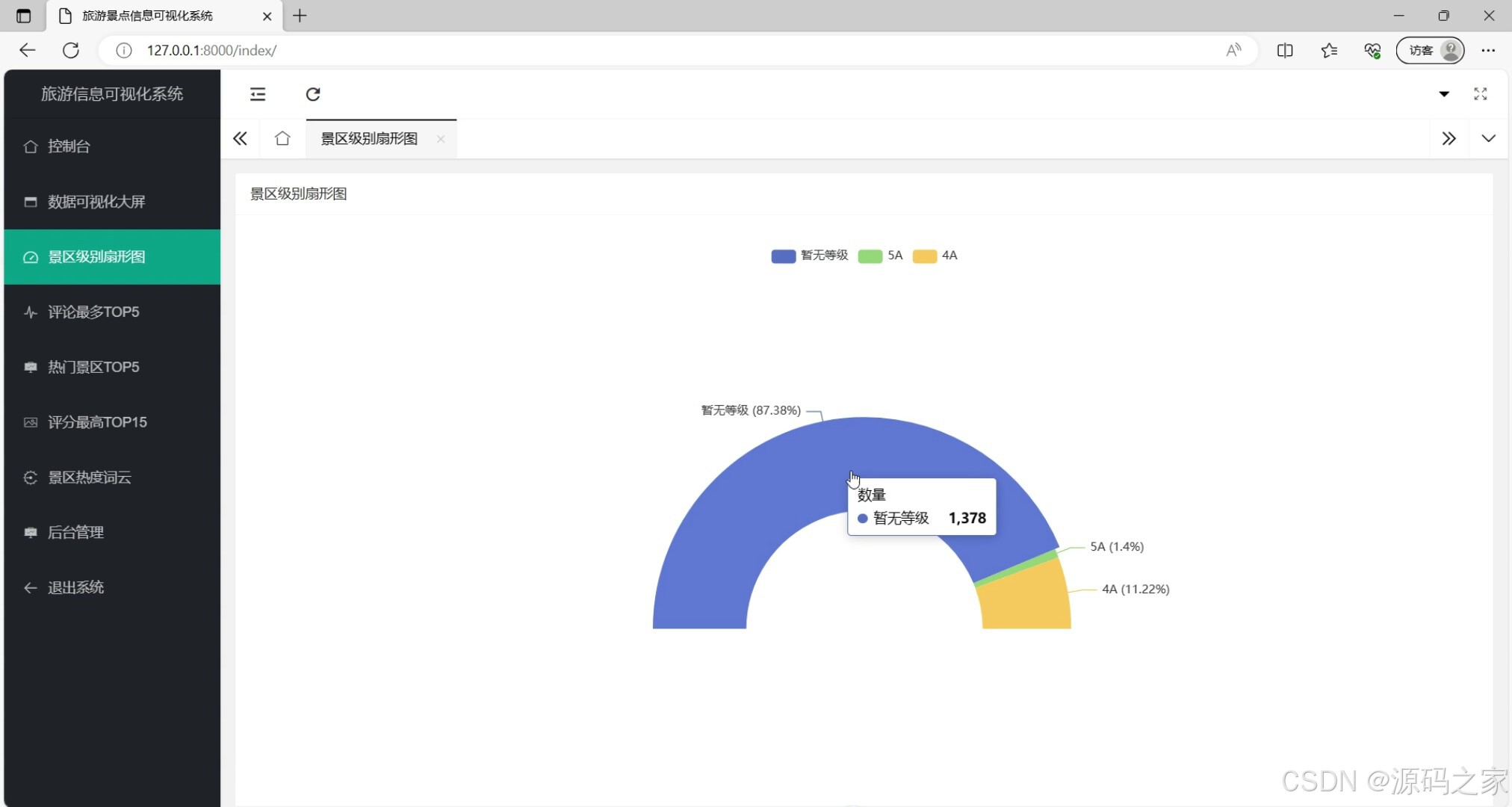
(7)景区评分扇形图
这是旅游景点信息可视化系统的景区级别扇形图展示页面,系统包含控制台、数据可视化大屏(含景区级别扇形图、评论最多TOP5、热门景区TOP5、评分最高TOP15、景区热度词云)、后台管理等功能模块,当前页面以环形扇形图呈现不同级别景区的占比分布,交互可查看对应级别景区的数量信息,直观展现景区等级结构。
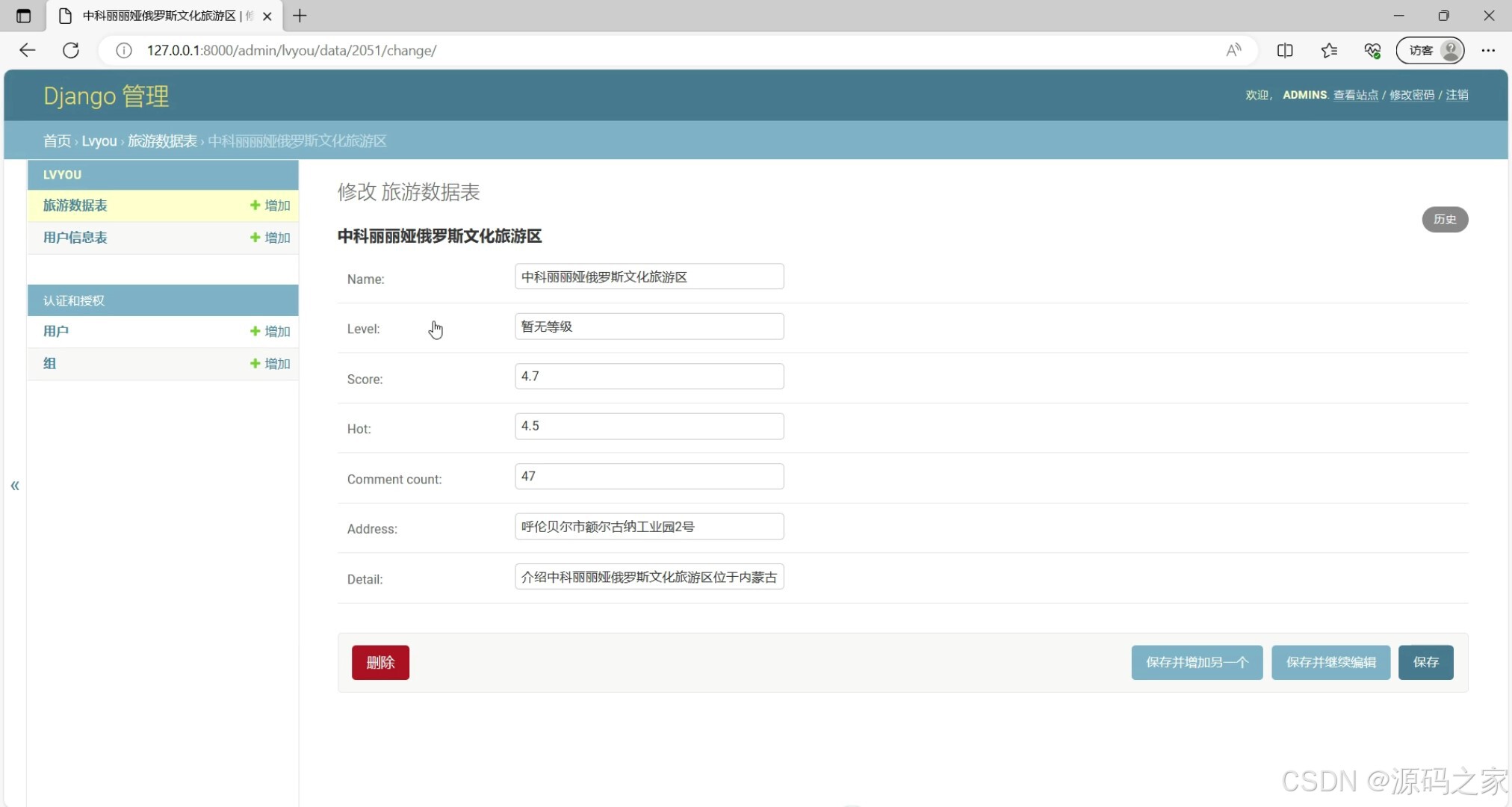
(8)后台数据管理
这是基于Django框架的旅游景点信息可视化系统后台管理页面,系统包含数据可视化大屏和后台管理模块,当前后台页面可对旅游数据表和用户信息表进行增删改操作,同时具备认证和授权功能,能修改景区的名称、等级、评分、热度、评论数、地址及详情等信息,还可进行保存、删除等操作。
(9)数据爬取
这是旅游景点信息可视化系统的数据采集模块页面,系统包含数据采集、后台管理和数据可视化大屏等功能模块,当前页面通过Python爬虫代码读取目标景区URL列表,借助浏览器驱动对旅游网站的景区页面进行数据爬取,可获取景区名称、等级、评分、热度、评论数等相关信息并用于后续数据处理与可视化展示。
3、项目说明
一、技术栈简要说明
本系统基于Python语言开发,采用Django作为后端Web框架,负责业务逻辑处理与系统架构搭建。MySQL数据库用于存储采集到的旅游景点数据,确保数据的持久化与高效管理。前端页面使用HTML进行布局与展示,结合可视化图表库呈现数据分析结果。数据采集方面,运用selenium爬虫框架对携程网旅游页面进行自动化抓取,获取景区名称、等级、评分、热度、评论数等关键信息,为后续分析提供数据基础。
二、功能模块详细介绍
· 旅游景点信息采集模块
该模块通过Python编写的selenium爬虫脚本,读取目标景区URL列表,模拟浏览器访问携程网旅游页面,自动抓取景区详细信息。爬取过程中对网页数据进行解析和过滤,提取景区名称、等级、评分、热度指数、评论数量、地理位置等字段,并将清洗后的数据存入MySQL数据库,为系统提供实时更新的数据来源。
· 注册登录模块
系统设置用户登录验证机制,未注册用户需通过注册页面填写账号信息完成注册,注册成功后即可登录进入系统。该模块保障系统访问的安全性,区分不同用户身份,为后续后台管理功能的权限控制提供支持。
· 系统数据概况模块
作为系统首页控制台,该模块集中展示旅游景点数据总量、5A级景区数量、4A级景区数量、最热门景点等核心指标。页面同时嵌入中国地图,直观呈现景区在全国的数量分布情况,帮助用户快速了解整体数据规模。
· 数据可视化大屏模块
该模块是系统的核心展示区域,包含六个子功能:景区等级分布占比分析,以环形图展示不同级别景区的比例结构;景区热度指数TOP分析,列出热度最高的景区排名;景区人次TOP分析,展示访问量领先的景区;景区热度和评分关系分析,通过散点图或组合图表呈现两者的关联性;全国旅游景点分布地图分析,在地图上标注景区位置及密集程度;旅游景点词云图分析,将景区名称按热度高低以词云形式展现,多维度呈现旅游数据特征。
· 景区级别扇形图分析模块
该模块以环形扇形图的形式,直观展示不同等级景区(如5A、4A、3A等)的数量占比。用户鼠标悬停或点击可查看对应级别景区的具体数量,清晰反映景区等级结构分布。
· 评论排名模块
模块以条形图展示评论数量最多的TOP5景区,按照评论量从高到低排序。图表支持交互操作,点击可查看具体景区的评论数据详情,直观呈现热门景区的评论热度差异。
· 热门景区模块
该模块通过条形图呈现热度指数最高的TOP5景区排名,热度指数综合考量搜索量、关注度等指标。图表支持交互查看对应景区的热度信息,帮助用户快速定位当前最受欢迎的旅游目的地。
· 景点评分排名模块
模块以条形图展示评分最高的TOP15景区,按照评分分值从高到低排列。用户可交互查看各景区的具体评分信息,直观对比不同景区的评分差异,为出行选择提供参考。
· 景区热度词云分析模块
该模块将景区名称按照热度高低生成词云图,热度越高的景区名称显示字号越大、颜色越突出。用户可通过词云快速感知当前热门景区分布,并支持切换不同可视化图表查看详细数据。
· 后台管理模块
后台管理页面基于Django框架开发,提供旅游景点信息管理和用户信息管理两大功能。管理员可对景点数据进行增、删、改、查操作,包括修改景区名称、等级、评分、热度、评论数、地址、详情等字段;同时可管理注册用户信息,具备认证和授权功能,确保系统数据的安全性与可维护性。
三、项目总结
本系统是一个集数据采集、存储、分析、可视化于一体的旅游信息平台。通过selenium爬虫框架实现对携程网旅游数据的自动化采集,解决了传统方式获取旅游信息滞后、检索效率低的问题。采集到的数据经过清洗后存入MySQL数据库,后端采用Django框架进行业务逻辑处理,前端通过HTML页面结合多种可视化图表进行数据展示。系统涵盖了数据概况、可视化大屏、排名分析、词云展示、后台管理等多个功能模块,能够从景区等级分布、热度指数、评论数量、评分排行等多个维度对旅游数据进行深度分析。用户可以通过直观的图表界面快速了解旅游市场情况,获取热门景区信息,为出行决策提供数据支持。同时,系统为旅游相关企业和机构提供了便捷的数据分析工具,有助于了解市场需求、优化产品和服务。整个项目实现了从数据采集到可视化展示的完整闭环,具有较强的实用性和可扩展性。
4、核心代码
def login(request):
"""登录函数"""
if request.method == "POST":
user = request.POST.get('user')
pass_word = request.POST.get('password')
print('user------>', user)
users_list = list(models.UserList.objects.all().values("user_id"))
users_id = [x['user_id'] for x in users_list]
print(users_id)
# print(students_num)
ret = models.UserList.objects.filter(user_id=user, pass_word=pass_word)
if user not in users_id:
return JsonResponse({'code': 1, 'msg': '该账号不存在!'})
elif ret:
# 有此用户 -->> 跳转到首页
# 登录成功后,将用户名和昵称保存到session 中,
request.session['user_id'] = user
user_obj = ret.last()
user_name = user_obj.user_name
request.session['user_name'] = user_name
return JsonResponse({'code': 0, 'msg': '登录成功!'})
else:
return JsonResponse({'code': 1, 'msg': '密码错误!'})
else:
return render(request, "login.html")
def register(request):
"""注册函数"""
if request.method == "POST":
user = request.POST.get('user')
pass_word = request.POST.get('password')
user_name = request.POST.get('user_name')
users_list = list(models.UserList.objects.all().values("user_id"))
users_id = [x['user_id'] for x in users_list]
if user in users_id:
return JsonResponse({'code': 1, 'msg': '该账号已存在!'})
else:
models.UserList.objects.create(user_id=user, user_name=user_name, pass_word=pass_word)
request.session['user_id'] = user # 设置缓存
request.session['user_name'] = user_name
return JsonResponse({'code': 0, 'msg': '注册成功!'})
else:
return render(request, "register.html")
# 退出(登出)
def logout(request):
# 1. 将session中的用户名、昵称删除
request.session.flush()
# 2. 重定向到 登录界面
return redirect('login')
def index(request):
return render(request, "index.html", locals())
def get_screen(request):
# city_list = ['金安区', '裕安区', '叶集区', '霍邱县', '舒城县', '金寨县', '霍山县']
# city_list = ['荔湾区', '越秀区', '海珠区', '天河区', '白云区', '黄埔区', '番禺区', '花都区', '南沙区', '从化区', '增城区']
city_list = ['北京市', '天津市', '河北省', '山西省', '内蒙古自治区', '辽宁省', '吉林省', '黑龙江省', '上海市', '江苏省',
'浙江省', '安徽省', '福建省', '江西省', '山东省', '河南省', '湖北省', '湖南省', '广东省', '广西壮族自治区',
'海南省', '重庆市', '四川省', '贵州省', '云南省', '西藏自治区', '陕西省', '甘肃省', '青海省', '宁夏回族自治区',
'新疆维吾尔自治区', '台湾省', '香港特别行政区', '澳门特别行政区', '']
# 等级占比图
level_list = list(set([x[0] for x in list(models.Data.objects.all().values_list('level'))]))
l_1_data = []
for level in level_list:
l_1_data.append({'name': level, "value": models.Data.objects.filter(level=level).count()})
# print(l_1_data)
# 散点图
hot_score = list(models.Data.objects.all().values_list('hot', 'score'))
hot_score = [[float(x[0]), float(x[1])] for x in hot_score if x[1] != '0']
hot_score = sorted(hot_score, key=lambda x: x[0])
# print(hot_score)
# 处理中间柱形图数据
c_1_data = list(models.Data.objects.all().values_list('name', 'hot').distinct().order_by('-hot'))[0:10]
# print(c_1_data)
c_1_x = [x[0] for x in c_1_data]
c_1_y = [float(x[1]) for x in c_1_data]
# 处理地图数据
map_data = []
for x in city_list:
map_data.append({'name': x, 'value': models.Data.objects.filter(address__icontains=x[0:2]).count()})
print("map_data------>", map_data)
# 评分排行
comment_list = list(models.Data.objects.all().values_list('name', 'comment_count').distinct())
# print(comment_list)
comment_list = [[x[0], int(x[1].replace('条点评', ''))] for x in comment_list]
comment_list = sorted(comment_list, key=lambda x: x[1], reverse=True)[0:10]
r_1_x = [x[0] for x in comment_list]
r_1_y = [float(x[1]) for x in comment_list]
# 词云图
r_2_data = list(models.Data.objects.all().values_list('name', 'comment_count').distinct())
# print(comment_list)
r_2_data = [[x[0], int(x[1].replace('条点评', ''))] for x in r_2_data]
r_2_data = [{"name": x[0], "value": x[1]} for x in r_2_data]
return render(request, "screen.html", locals())
def welcome(request):
"""此函数用于处理控制台页面"""
all_data = models.Data.objects.all().count()
data_5a = models.Data.objects.filter(Q(level__icontains='5A') | Q(name__icontains='5A')).count()
data_4a = models.Data.objects.filter(Q(level__icontains='4A') | Q(name__icontains='4A')).count()
hot_data = [[x[0], float(x[1])] for x in list(models.Data.objects.all().values_list('name', 'hot').distinct())]
hot_data = sorted(hot_data, key=lambda x: x[1], reverse=True)[0]
hot_data_name = hot_data[0]
hot_data_hot = hot_data[1]
# city_list = ['金安区', '裕安区', '叶集区', '霍邱县', '舒城县', '金寨县', '霍山县']
# city_list = ['荔湾区', '越秀区', '海珠区', '天河区', '白云区', '黄埔区', '番禺区', '花都区', '南沙区', '从化区', '增城区']
city_list = ['北京市', '天津市', '河北省', '山西省', '内蒙古自治区', '辽宁省', '吉林省', '黑龙江省', '上海市',
'江苏省',
'浙江省', '安徽省', '福建省', '江西省', '山东省', '河南省', '湖北省', '湖南省', '广东省',
'广西壮族自治区',
'海南省', '重庆市', '四川省', '贵州省', '云南省', '西藏自治区', '陕西省', '甘肃省', '青海省',
'宁夏回族自治区',
'新疆维吾尔自治区', '台湾省', '香港特别行政区', '澳门特别行政区', '']
# 处理地图数据
map_data = []
for x in city_list:
map_data.append({'name': x, 'value': models.Data.objects.filter(address__icontains=x[0:2]).count()})
# print(map_data)
return render(request, "welcome.html", locals())
def chart_1(request):
level_list = list(set([x[0] for x in list(models.Data.objects.all().values_list('level'))]))
l_1_data = []
all_value = 0
for level in level_list:
a = models.Data.objects.filter(level=level).count()
all_value += a
l_1_data.append({'name': level, "value": a})
# print(l_1_data)
return render(request, "echarts_1.html", locals())
def chart_2(request):
comment_list = list(models.Data.objects.all().values_list('name', 'comment_count').distinct())
# print(comment_list)
comment_list = [[x[0], int(x[1].replace('条点评', ''))] for x in comment_list]
comment_list = sorted(comment_list, key=lambda x: x[1], reverse=True)[0:5]
c_1_data = [{'name': x[0], 'value': x[1]} for x in comment_list]
le_data = [x[0] for x in comment_list]
return render(request, "echarts_2.html", locals())
def chart_3(request):
comment_list = list(models.Data.objects.all().values_list('name', 'hot').distinct())
# print(comment_list)
comment_list = [[x[0], float(x[1].replace('条点评', ''))] for x in comment_list]
comment_list = sorted(comment_list, key=lambda x: x[1], reverse=True)[0:5]
c_1_data = [{'name': x[0], 'value': x[1]} for x in comment_list]
le_data = [x[0] for x in comment_list]
return render(request, "echarts_3.html", locals())
def chart_4(request):
comment_list = list(models.Data.objects.all().values_list('name', 'score').distinct())
# print(comment_list)
comment_list = [[x[0], float(x[1].replace('条点评', ''))] for x in comment_list]
comment_list = sorted(comment_list, key=lambda x: x[1], reverse=True)[0:15]
c_1_data = [{'name': x[0], 'value': x[1]} for x in comment_list]
le_data = [x[0] for x in comment_list]
return render(request, "echarts_4.html", locals())
def chart_5(request):
# 词云图
r_2_data = list(models.Data.objects.all().values_list('name', 'comment_count').distinct())
# print(comment_list)
r_2_data = [[x[0], int(x[1].replace('条点评', ''))] for x in r_2_data]
r_2_data = [{"name": x[0], "value": x[1]} for x in r_2_data]
return render(request, "echarts_5.html", locals())
5、源码获取方式

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)