【LLM】LitBench:创意文本评估Benchmark
·
note
- 创意写作虽然主观,但仍然可以通过高质量的人类偏好数据训练出可靠的 reward model;而且这种专门训练的 reward model,比直接拿强闭源 LLM 当 judge 更准。
- 做了一个专门评测创意写作 judge 的 benchmark:LitBench。数据来自 Reddit 的 r/WritingPrompts,本质上利用社区 upvote 作为“人类偏好”的弱监督信号。他们构建了:
- 2,480 对 去偏置、人工标注的测试集
- 43,827 对 pairwise 训练集,用来训练 verifier / reward model
- 引入LitBench基准和数据集,展示了在创意写作评估中使用学习奖励模型的潜力。研究表明,经过微调的领域特定模型在创意写作评估中表现优异,尤其是在没有昂贵的人类偏好数据的情况下,专有LLM评委可以作为训练有素的验证器的可行替代品。未来的工作可以利用强大的验证器来提高潜在的创意写作生成能力。
- 相关实验结论:
- 训练出来的 reward model 明显强于 zero-shot LLM judge:最强的零样本 judge 是 Claude-3.7-Sonnet,和人类偏好一致率大约 73%。而训练后的 BT RM 和 GenRM 都能到 78%,超过所有零样本 judge。
- 创意写作评判不是那种“显式逐步推理能越想越对”的任务。
加入 CoT 后,模型会生成很多解释性文本,但这些文本未必真的帮助判断,反而可能带来噪声。- 在数学、代码里,CoT 往往能增强 verifier;但在这篇论文里,GenRM + CoT 比不带 CoT 的 GenRM 更差,准确率反而掉到 72% 左右。
- 训reward模型,质量大于数量
一、研究背景
- 研究问题:这篇文章要解决的问题是如何评估大型语言模型(LLMs)生成的创意写作的质量。由于创意写作的开放性和主观性,缺乏客观的真值标签,这使得自动化评估变得具有挑战性。
- 研究难点:该问题的研究难点包括:创意写作的主观性和多样性使得难以找到可靠的真值标签;现有的零样本语言模型在评估创意写作时表现不佳,且存在偏见和内部不一致性。
- 相关工作:该问题的研究相关工作包括:在数学和编码生成任务中使用自动化验证方法取得的进展;在创意写作领域,现有工作主要依赖于人类专家评估或简单的自动评估指标(如BLEU和ROUGE分数),但这些方法在开放式的创意写作生成任务中效果有限。
二、LitBench
1、LitBench评测基准
这篇论文提出了LitBench,第一个标准化的创意写作验证基准和数据集。具体来说,
- 数据收集:从Reddit的r/WritingPrompts子版块收集写作样本,使用Reddit API筛选出100个最受欢迎的帖子,共5000多个帖子ID。测试集包含2480对个人故事比较,训练集包含43827对故事比较。
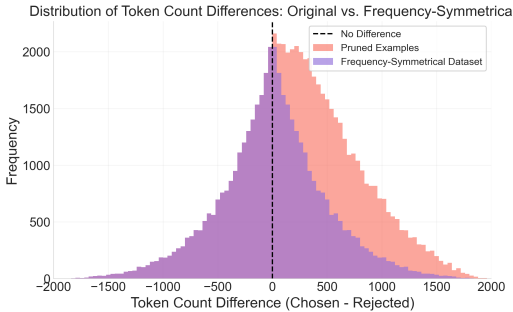
- 质量控制:独立过滤故事,确保每个故事有足够的参与度(至少10个赞),长度不超过2048个词,且至少有50个词。通过逐步过滤和匹配方法构建成对样本,确保真实偏好被捕捉,并解决长度偏差问题。
2、系统比较三类评测器
- Bradley-Terry 判别式 reward model(BT RM),Bradley-Terry判别奖励模型:使用Bradley-Terry公式对每对故事进行评分,损失函数定义为:
L B T = − log σ ( r chosen − r rejected ) , \mathcal{L}_{BT} = -\log \sigma(r_{\text{chosen}} - r_{\text{rejected}}), LBT=−logσ(rchosen−rrejected),
其中, r chosen r_{\text{chosen}} rchosen 和 r rejected r_{\text{rejected}} rrejected 分别是偏好故事和拒绝故事的奖励得分。 - Generative Reward Model(GenRM),生成奖励模型:训练两个版本的生成奖励模型,GenRM-预测单个令牌的选择,GenRM-CoT-结合GPT4.1生成的理由进行推理选择。
- 不带 CoT
- 带 CoT 的版本
- 零样本LLM judge:使用未经标记的故事对LLM评委进行测试,要求评委在生成裁决前形成解释。为了解决位置偏差问题,对两组故事对进行平均性能评估。
三、实验结果
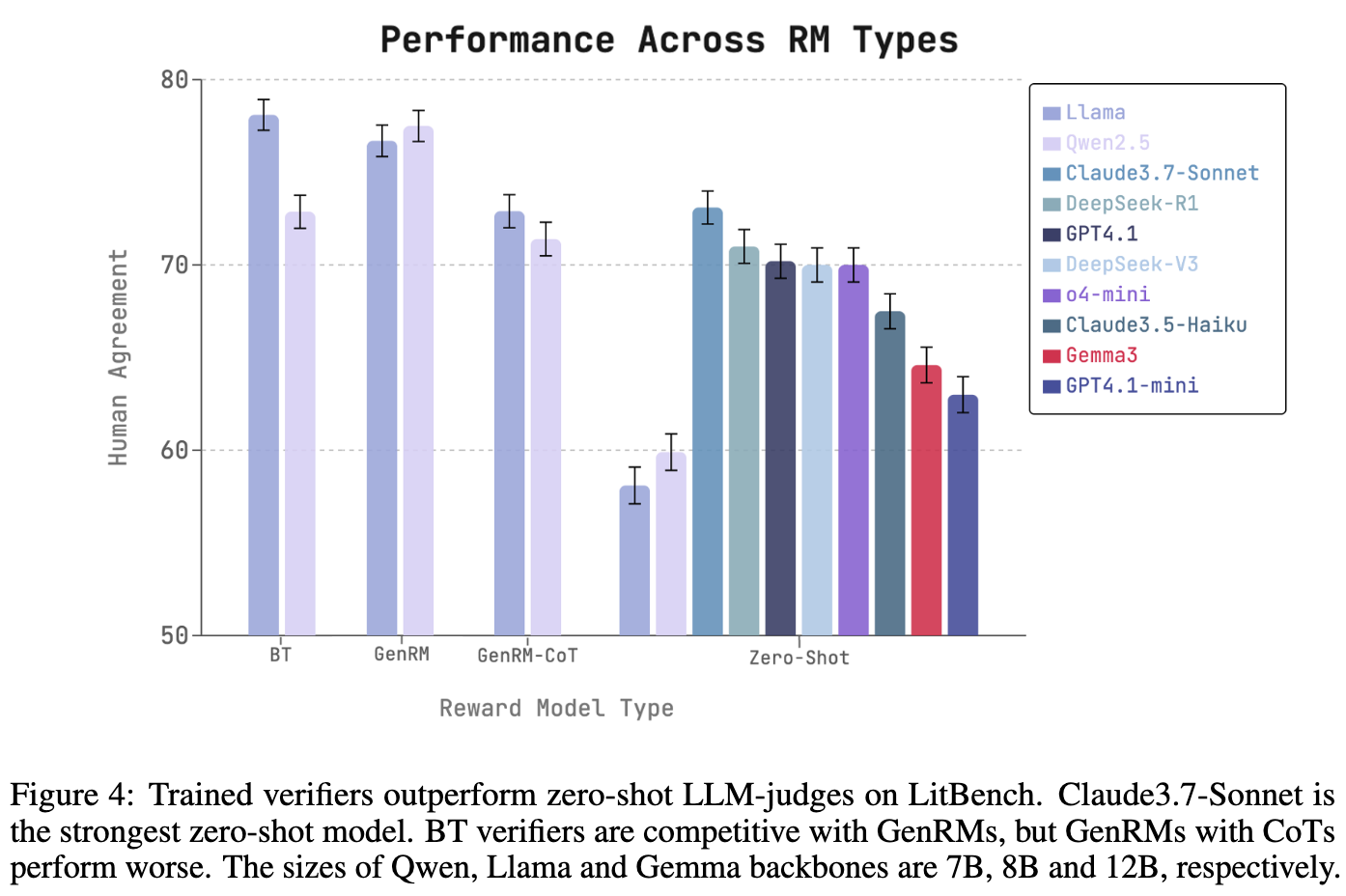
- 模型性能:Bradley-Terry最佳奖励模型(Llama-8B)在LitBench训练集上的准确率为78%,生成奖励模型(GenRM-Qwen)也达到了78%,均优于所有零样本LLM评委(Claude-3.7-Sonnet为73%)。加入链式思维推理的生成奖励模型(GenRM-CoT)准确性下降至72%。
- 特征分析:解释文本中的情节讨论对裁决准确性影响最大,尤其是对于Anthropic模型,相关性提高了+14.8%。
- 模型规模:生成奖励模型在较小模型(1B或1.5B)上就能达到相似的性能,而Bradley-Terry模型在较小模型上的性能提升显著。
- 数据过滤方法:通过不同过滤策略训练的消融Bradley-Terry奖励模型在LitBench测试集上的性能表明,严格的时间戳和长度过滤显著提高了模型性能。
- 人类实验:在线人类研究表明,基于LitBench训练的偏好微调的奖励模型在新创意写作提示上的表现优于最佳LLM评委,但仍有40%的不一致率,表明需要更丰富的监督信号(如基于标准的反馈或理由蒸馏)来进一步对齐自动奖励与人类文学品味。
Reference
[1] LitBench- A Benchmark and Dataset for Reliable Evaluation of Creative Writing

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)