大模型应用开发新范式:Agent Skills保姆级教程,建议收藏!
在大模型应用开发的早期阶段,我们习惯于通过精细打磨的 Prompt(提示词)来引导模型。然而,随着业务逻辑复杂度的指数级上升,单纯依赖 Prompt 遇到了不可逾怀的瓶颈:Context Window(上下文窗口)虽然在变大,但“拥挤”的上下文会导致模型注意力分散(Lost in the Middle),且难以复用的长文本指令让维护变成了噩梦。
Agent Skills(代理技能) 的提出,标志着 Agent 开发进入了标准化、模块化的新阶段。它不再是一段文本,而是一套基于文件系统的开放标准。
本文将深入拆解 Agent Skills 的技术架构、文件规范、生态协作模式以及自动生成工作流。
一、 范式转移:为什么我们需要 Skills?
在 Agent Skills 出现之前,我们通常采用“专用 Agent”模式:通过硬编码的 Prompt 和特定的工具集构建“金融 Agent”、“编程 Agent”或“营销 Agent”。
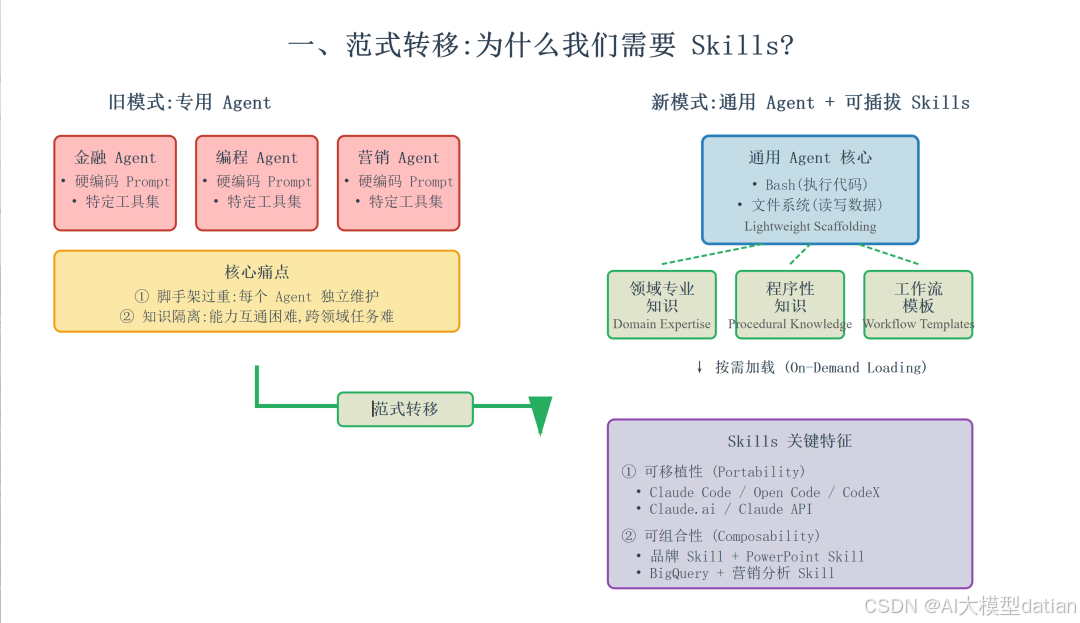
这种模式存在两个核心痛点:
-
- 脚手架过重:每个 Agent 都需要独立的维护框架。
-
- 知识隔离:Agent 之间的能力互通困难,且难以应对跨领域的复杂任务。
新的范式是:通用 Agent + 可插拔 Skills。
Agent Skills 是一种轻量级、开放的格式,用于扩展 AI Agent 的能力。、Skill 是一个包含指令、脚本、资产和资源的文件夹,Agent 可以通过发现这些 Skill 来准确执行特定任务。
通用 Agent 仅保留最基础的脚手架——通常是 Bash(执行代码)和文件系统(读写数据)。通过按需加载 Skill,Agent 可以在瞬间获得特定的领域专业知识(Domain Expertise)和程序性知识(Procedural Knowledge)。
- • 通用 Agent 使用代码作为通用接口
- • 简单的脚手架:bash 和文件系统
- • 但它们需要上下文和领域专业知识才能可靠地完成工作
- • Skills 提供程序性知识和公司/团队/用户特定的上下文,Agent 可以按需加载
这使得 AI 的开发重心从“调教模型”转向了“构建标准化的技能库”。
Skills 能赋能什么
| 类别 | 示例 |
|---|---|
| 领域专业知识 | 品牌指南和模板、法律审查流程、数据分析方法论 |
| 可重复的工作流 | 每周营销活动审查、客户通话准备工作流、季度业务审查 |
| 新能力 | 创建演示文稿、生成 Excel 表格或 PDF 报告、构建 MCP 服务器 |
如果没有 Skills
- • 每次都要描述你的指令和要求
- • 每次都要打包所有的参考资料和支持文件
- • 手动确保工作流或输出始终一致

Skills 的关键特征
-
- 可移植: 你可以在不同的兼容 Skill 的 Agent 之间重用同一个 Skill:
Agent Skills 现在是一个开放标准,正被越来越多的 Agent 产品采用。
- • Claude Code 、Open Code、CodeX、Gemini CLI
- • Claude.ai
- • Claude Agent SDK
- • Claude API
-
- 可组合: Skills 可以组合起来构建复杂的工作流。例如:
- • 公司品牌 Skill:提供品牌指南(字体、颜色、Logo)
- • PowerPoint Skill:创建幻灯片
- • BigQuery Skill:提供营销相关的 Schema
- • 营销活动分析 Skill:分析营销数据
二、 核心架构:渐进式披露 (Progressive Disclosure)
Agent Skills 的核心设计哲学是对 Context Window 的极致保护。它将上下文视为一种稀缺的公共资源(Public Good),严禁无关信息的侵占。
为此,Skills 采用了一套严密的三级加载机制:
| 层级 | 何时加载 |
|---|---|
| 元数据 (YAML frontmatter: 名称, 描述) | 始终加载 |
| 指令 (主 SKILL.md 内容) | 触发时加载 |
| 资源 (参考文件, 脚本) | 按需加载 |
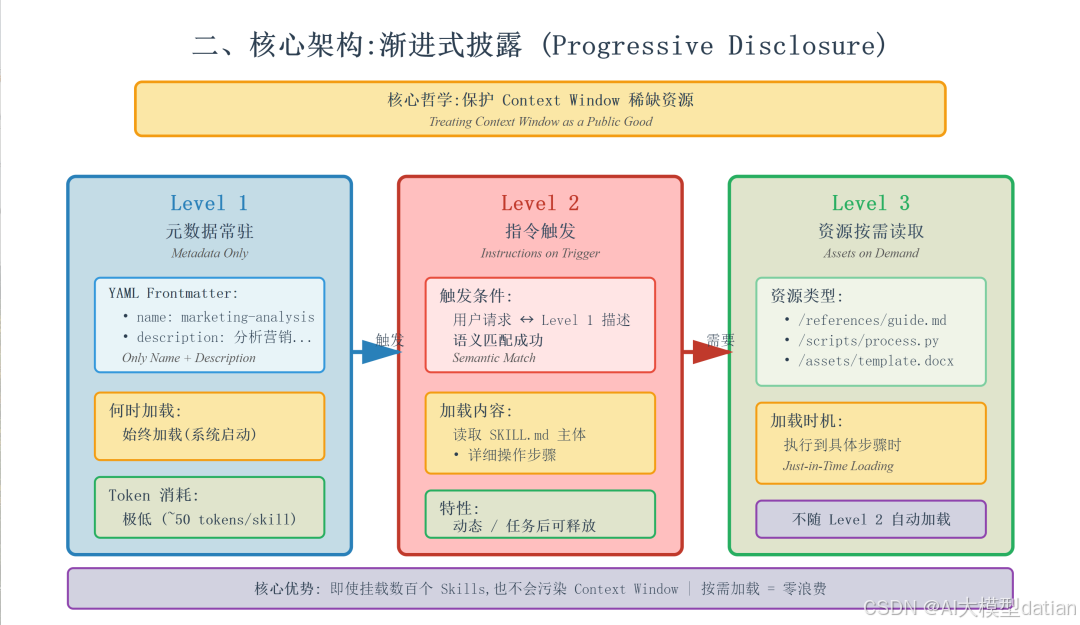
Level 1:元数据常驻 (Metadata Only)
系统启动时,Agent 的上下文中只有技能的名称(Name)和描述(Description)。
- • 目的:让 Agent 知道“我有这个能力”,但不知道“具体怎么做”。
- • 消耗:极低。即使挂载几百个技能,也仅占用少量 Token。
Level 2:指令触发 (Instructions on Trigger)
只有当用户的请求与 Level 1 的描述产生语义匹配时,Agent 才会读取 Skill 文件夹下的核心文件 SKILL.md。
- • 行为:此时,详细的操作步骤被加载进上下文。
- • 特性:这是动态的。任务结束后,这些信息可以被释放(取决于具体的 Agent 实现策略)。
Level 3:资源按需读取 (Assets on Demand)
如果 Skill 的指令中引用了外部文件(如 /references/guidelines.md)或脚本(如 /scripts/process_data.py),这些内容不会随 Level 2 自动加载。
- • 行为:只有当 Agent 执行到需要该资源的具体步骤时,才会通过文件系统工具去读取它。
三、 工程规范:解剖 Skill 文件夹
一个合规的 Skill 是一个包含特定结构的文件夹。为了确保 Agent 能够准确理解,开发者需严格遵循以下规范。
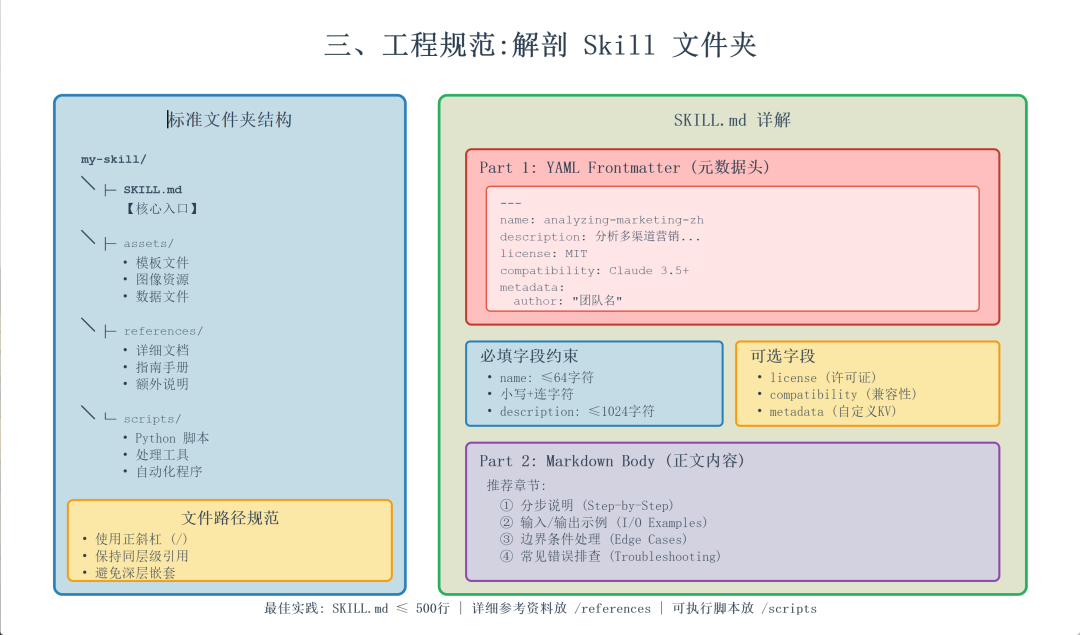
核心入口:SKILL.md
这是 Skill 的大脑,由 YAML Frontmatter 和 Markdown 指令 组成。
-
- YAML Frontmatter — 顶部的元数据
-
- 正文内容 — 下方的 Markdown 指令
A. YAML Frontmatter(元数据头)

必须位于文件顶部,用于 Agent 的索引和路由。
---
name: analyzing-marketing-campaign-zh
description: 分析每周多渠道营销活动的绩效数据。用于分析多渠道数字营销数据,计算漏斗指标(CTR、CVR)并与基准对比,计算成本和收益效率指标(ROAS、CPA、净利润),或根据绩效规则获取预算重新分配建议。
---
Frontmatter 必填字段
| 字段 | 约束 |
|---|---|
| name | 最多 64 个字符;仅限小写字母、数字和连字符;不得以连字符开头/结尾;必须与父目录名称匹配;推荐:动名词形式(动词±ing) |
| description | 最多 1024 个字符;非空;应描述 Skill 做什么以及何时使用它;包含特定关键字以帮助 Agent 识别相关任务 |
Frontmatter 可选字段
| 字段 | 约束 |
|---|---|
| license | 许可证名称或对许可证文件的引用 |
| compatibility | 最多 500 个字符;指示环境要求 |
| metadata | 任意键值对(例如,作者、版本) |
| allowed-tools | 预先批准的 Tool 的空格分隔列表(实验性) |
B. 正文内容
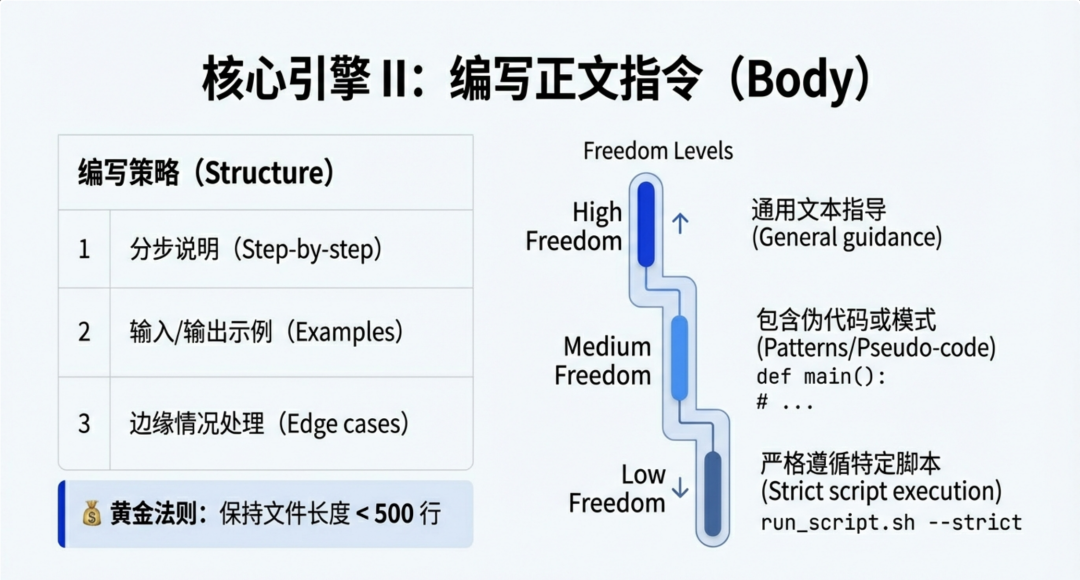
没有格式限制,但这里有一些建议:
推荐部分
- • 分步说明
- • 输入格式 / 输出格式 / 示例
- • 常见边缘情况
实践指南
- • 保持在 500 行以内
- • 将详细的参考资料移至单独的文件(展示基本内容,链接到高级内容)
- • 保持参考资料与 SKILL.md 同一层级(避免嵌套文件引用)
- • 清晰简洁,使用一致的术语
- • 在文件路径中使用正斜杠,即使在 Windows 上也是如此
自由度
| 级别 | 描述 |
|---|---|
| 高自由度 | 通用的基于文本的指导;多种方法均有效 |
| 中等自由度 | 指令包含可定制的伪代码、代码示例或模式;存在首选模式,但允许一定变体 |
| 低自由度 | 指令引用特定脚本;必须遵循特定顺序 |
复杂工作流
- • 将复杂操作分解为清晰、顺序的步骤
- • 如果工作流变得很大且步骤很多,请考虑将它们放入单独的文件中
可选目录
/assets
- • 模板: 文档模板、配置模板
- • 图像: 图表、Logo
- • 数据文件: 查找表、Schema
/references
- • 包含 Agent 在需要时可以阅读的额外文档
- • 保持单个参考文件专注
- • 注意: 对于超过 100 行的参考文件,请在顶部包含目录,以便 Agent 可以看到完整范围
/scripts
- • 清晰记录依赖关系
- • 脚本应有清晰的文档
- • 错误处理应明确且有帮助
- • 注意: 在指令中明确说明 Claude 应该执行脚本还是将其作为参考阅读
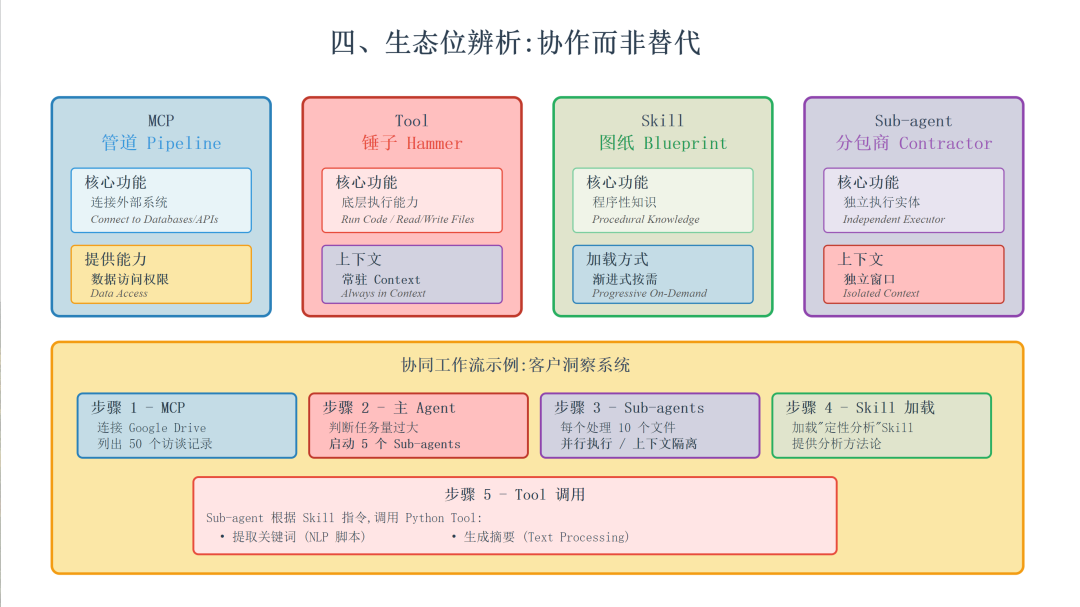
四、 生态位辨析:Skill, MCP, Tool, Sub-agent
在构建复杂系统时,清晰区分这四个概念至关重要。它们不是替代关系,而是协作关系。
Skills vs MCP
| 特性 | MCP | Skills |
|---|---|---|
| 目的 | 将你的 Agent 连接到外部系统和数据(数据库、API、服务) | 教你的 Agent 如何使用这些数据 |
| 示例 | MCP 服务器连接到数据库 | Skill 指示“使用该表的 A 列和 B 列计算指标 X” |
MCP 提供访问权限,Skills 提供专业知识。
Skills vs Tools
| 特性 | Tools | Skills |
|---|---|---|
| 目的 | 为 Agent 提供完成任务的基本能力 | 用专业知识扩展 Agent 的能力 |
| 上下文 | Tool 定义(名称、描述、参数)始终存在于上下文窗口中 | Skills 根据需要动态加载 |
| 灵活性 | 固定的能力集 | Skills 可以包含脚本作为 Tool,在需要时使用(“按需工具”) |
Skills vs Subagents
| 特性 | Subagents | Skills |
|---|---|---|
| 目的 | 拥有自己独立的上下文和 Tool 权限 | 为主 Agent 或其任何 Subagent 提供专业知识 |
| 操作 | Agent 将任务委派给专门的 Subagent,Subagent 独立工作(可能并行)并返回结果 | Skills 告知工作应如何完成 |
| 示例 | 代码审查员 Subagent | 特定语言或框架的最佳实践 Skill |
Skills 可以用专业知识同时增强主 Agent 和 其 Subagents。
Skills 与 Tools、MCP 和 Subagents 的对比
| 组件 | 核心隐喻 | 功能定义 | 上下文管理 |
|---|---|---|---|
| MCP | 管道 (Pipeline) | 连接外部世界(数据库、API)。负责“拿数据”。 | 提供数据源,不提供逻辑。 |
| Tool | 锤子 (Hammer) | 底层的执行能力(如运行代码、读写文件)。 | 工具定义常驻上下文。 |
| Skill | 施工图纸 (Blueprint) | 封装好的程序性知识。教 Agent “怎么做”。 | 渐进式加载(按需)。 |
| Sub-agent | 分包商 (Contractor) | 独立的执行实体。负责并行处理和上下文隔离。 | 拥有独立的上下文窗口。 |
协同工作流示例:客户洞察系统
-
- MCP 负责连接 Google Drive,列出所有的访谈记录文件。
-
- 主 Agent 发现有 50 个文件需要分析,任务量过大,于是启动 Sub-agents。
-
- Sub-agents 被分派任务,每个负责 10 个文件(并行执行,且互不干扰上下文)。
-
- 每个 Sub-agent 加载同一个 Skill(例如“定性分析技能”),该 Skill 包含具体的分析方法论。
-
- 在执行 Skill 的过程中,Sub-agent 调用底层的 Tools(Python 脚本)来提取关键词并生成摘要。
五、 开发提效:利用 Skill Creator 编写Skill
手动编写符合上述所有规范的 Skill 依然繁琐。Anthropic 提出了 Skill Creator 的概念,即利用 AI 来编写 AI 的技能。
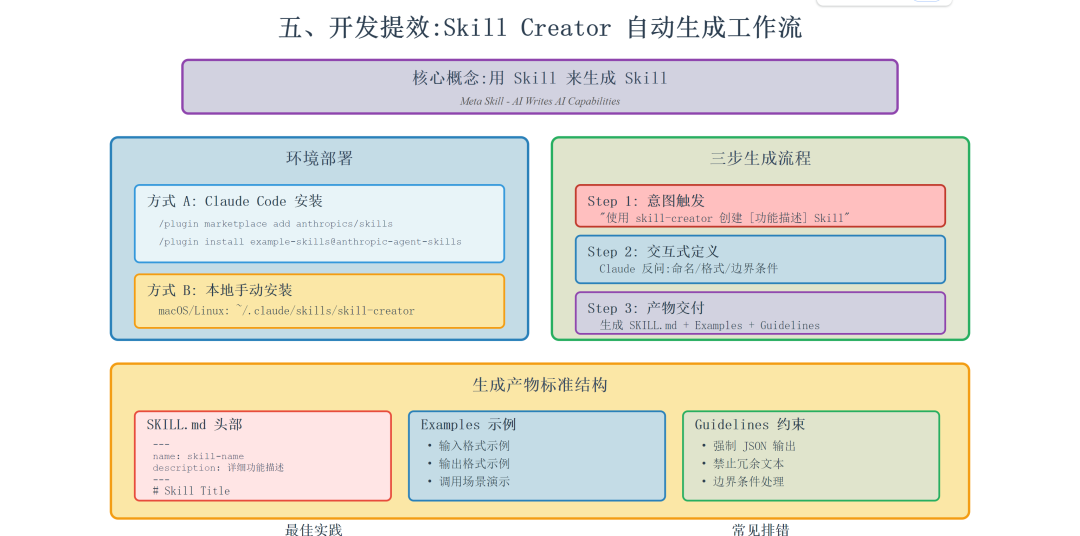
1. 核心概念:什么是 skill-creator?
skill-creator 是 Anthropic 官方推出的一个 Meta Skill(元技能),其核心作用是“用 Skill 来生成 Skill”。它通过引导式对话,帮助开发者自动生成符合规范的目录结构、SKILL.md 配置文件以及使用示例,是构建 Agent 能力最快捷的路径。
2. 环境部署
前提条件
- • 支持平台:Claude Code、Claude.ai 或本地环境(OpenCode/腾讯云)。
- • 权限要求:需在设置中开启 Skills 功能,并具备文件上传或本地文件系统读写权限。
安装方式
-
• **方式 A:Claude Code 命令行安装(推荐)**在聊天框执行以下指令,从市场拉取并安装:
/plugin marketplace add anthropics/skills /plugin install example-skills@anthropic-agent-skills此操作会将包括
skill-creator在内的示例技能库集成到当前环境。 -
• 方式 B:本地手动安装
-
- 从 GitHub 下载
skill-creator目录。
- 从 GitHub 下载
-
- 将其放置于本地配置路径:
- • macOS/Linux:
~/.claude/skills/skill-creator - • Windows:
%USERPROFILE%/.claude/skills/skill-creator
-
- 注意:首次安装可能需要手动创建
skills文件夹,安装后需重启环境以加载。
- 注意:首次安装可能需要手动创建
3. 构建流程:三步生成 Skill
Step 1: 意图触发
直接向 Claude 发送指令,明确使用 skill-creator 及目标。
- • Prompt 范式:“使用 skill-creator 帮我创建一个新的 Claude Skill。目标是:[具体功能描述]”。
Step 2: 交互式定义
Claude 会根据目标反问关键细节,包括:
- • Skill 命名规范。
- • 输入/输出格式(推荐结构化数据)。
- • 边界条件与特殊逻辑。
Step 3: 产物交付
执行完成后,会生成一个包含以下内容的完整文件夹:
- •
SKILL.md:核心配置文件,含 YAML 头和逻辑指令。 - •
Examples:具体的调用示例。 - •
Guidelines:约束模型的行为准则。
4. 工程规范与最佳实践
文件结构标准
生成的 SKILL.md 遵循 YAML Frontmatter + Markdown Body 的标准格式:
---
name: skill-name
description: 详细的功能描述
---
# Skill Title
具体逻辑...
## Examples
- 示例输入...
## Guidelines
- 强制使用 JSON 格式...
开发建议
-
- 结构化输出:强制要求输出为 JSON 或 CSV,而非自然语言,以便于下游系统集成。
-
- 详细约束:在 Prompt 中明确输入输出的边界条件和格式要求,描述越具体,生成的 Skill 质量越高。
-
- 迭代测试:生成后应立即测试,若效果不佳,可再次调用
skill-creator进行补充说明和迭代。
- 迭代测试:生成后应立即测试,若效果不佳,可再次调用
常见排错
- • 未识别 Skill:检查目录路径是否正确(如
~/.claude/skills),并尝试重启 Claude Code。 - • 输出格式错误:检查
Guidelines部分是否明确禁止了无关文本。
六、 总结与展望
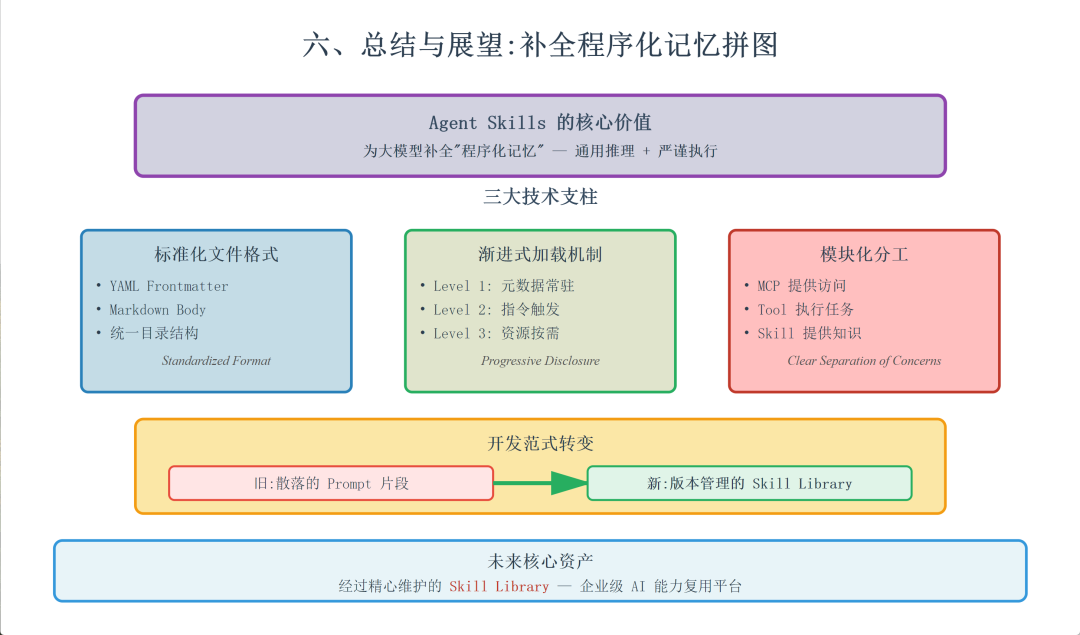
Agent Skills 实际上是为大模型补全了“程序化记忆”的拼图。
通过标准化的文件格式、渐进式的加载机制以及清晰的模块化分工,我们终于能够构建出既具备大模型通用推理能力,又拥有传统软件般严谨执行逻辑的复杂业务工作流。对于技术团队而言,现在的核心资产将不再是散落在各处的 Prompt 片段,而是经过版本管理和精心维护的 Skill Library。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)