如何让李健唱自己喜欢的歌曲
背景
某天晚上我随手在音乐APP里听歌,突然被一首“李健”的歌狠狠戳中,尤其是一句「我意气风发,像偷了你的年华」,直接刻进我脑子里,循环到停不下来。
第二天我立马全网找原版,翻遍各大音乐平台,甚至跑去问豆包,让它帮我查李健到底什么时候唱过《院子里的花》。结果一盆冷水浇下来:李健本人,根本没唱过这首歌!
我当场愣住,下一秒就反应过来——这歌十有八九是AI合成的。
念头一起,我直接冲去Hugging Face,搜最近有没有新出的SVC歌声合成模型,还真让我挖到了宝:Soul-AILab 的 SoulX‑Singer。
这款模型是Soul App联合天津大学、西北工业大学开源的工业级零样本歌声合成模型,用4.2万小时高质量多语言歌声数据训练,支持MIDI乐谱和F0旋律双模式控制,音高、节奏控得很准,还能跨语言克隆音色、编辑歌词。它用了先进的Flow Matching架构和两阶段训练,在音准、像真度、听感上,都比市面上其他开源方案强一大截,是AI做歌的硬核底座。
找到模型,直接开整!
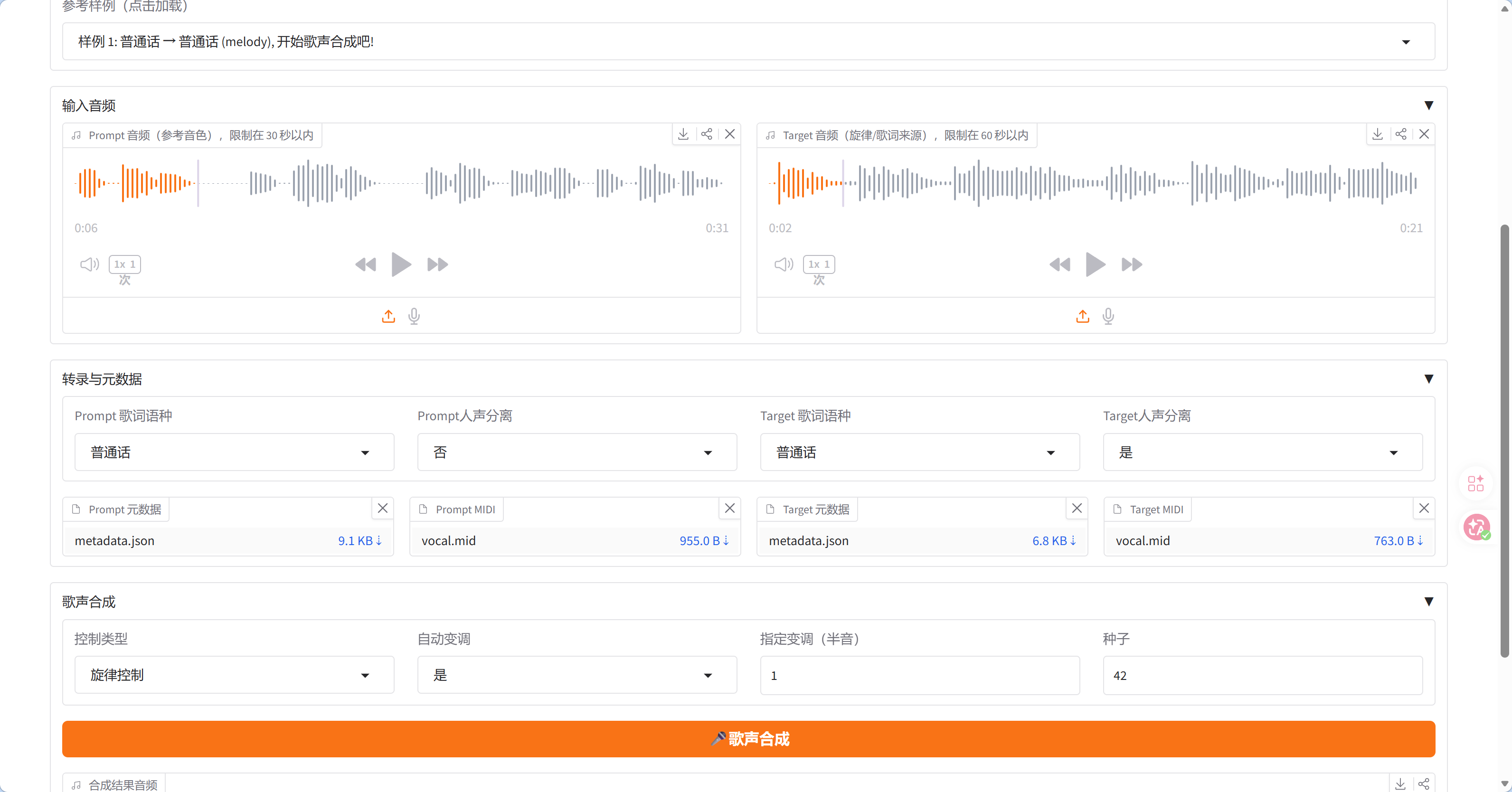
我先下载了李健在春晚上唱的《人间共鸣》和《院子里的花》,用人声分离模型把伴奏和人声拆干净;接着在本地把SoulX‑Singer部署跑起来。
一看代码我就乐了:模型居然加了限制——参考音频不能超30秒,待变声的歌不能超1分钟。
这哪够我整活?我直接顺手把长度限制给解除了,然后开冲:用李健的音色,合成《院子里的花》。
结果,不出意外地出了意外。
合成出来的音色跟李健毫不沾边,之前人声分离没清干净的杂音,变声后直接变成了诡异的电音怪声,直接翻车。
我转头去试官方Demo,效果却好得离谱。
我一开始还怀疑,是不是训练数据里就藏着Demo里的音频?很快就被我自己否定了——我用自己本地的短音频试了试,合成效果也很能打。
我这才恍然大悟:官方设长度限制,是真的有道理!
于是我老老实实调整方案:
把李健的参考音频剪到30秒以内,《院子里的花》分成四段,一段一段单独变声;合成时再打开人声分离优化,就像抽卡一样反复试了好几次,终于调出了满意的音色。
最后用剪映把合成好的人声和原版伴奏混到一起,完整版《院子里的花—李健(AI版)》就此诞生。
虽说和真人录制的质感还有差距,但总算是圆了我最开始听到那句歌词时的心动。
SoulX-Singer:面向高质量零样本歌声合成
钱家乐¹* 戴宇航¹,⁴ 刘红梅¹ 尹顺顺¹ 孟浩¹,³* 谢汉克¹,⁴ 文翰林¹ 陶明¹ 郑甜¹ 朱鹏程² 曹文骁¹ 赵健² 魏建国³ 谢磊⁴ 王新生¹† 尚瑞轩¹ 江钟麟² 林浩鹏¹ 吴军¹ 陈勇²
- 1 灵魂人工智能实验室,中国
- 2 吉利汽车研究院(宁波)有限公司人工智能中心,中国宁波
- 3 天津大学视听认知计算团队,中国天津
- 4 西北工业大学语音与语言信息处理研究组,中国西安
摘要
近年来语音合成技术发展迅猛,但开源歌声合成(SVS)系统在工业部署中仍面临诸多关键瓶颈,其中鲁棒性和零样本泛化能力的不足尤为突出。本报告中,我们提出一款面向实际落地场景设计的高质量开源歌声合成系统——SoulX-Singer。该系统支持基于符号乐谱(MIDI)或旋律表征的可控歌声生成,能在实际音乐制作流程中实现灵活且富有表现力的生成控制。模型基于超4.2万小时的人声数据完成训练,支持普通话、英语和粤语三种语言,在不同音乐场景下,各语言的合成质量均达到当前业界最优水平。此外,为实现实际场景下零样本歌声合成性能的可靠评估,我们构建了专用基准测试集SoulX-Singer-Eval,该数据集采用严格的训练-测试解耦设计,为零样本场景下的歌声合成性能提供系统化的评估依据。
演示页面:https://soul-ailab.github.io/soulx-singer
源码地址:https://github.com/Soul-AILab/SoulX-Singer
1 引言
歌声合成(SVS)的目标是基于歌词和乐谱生成富有表现力的人类歌声。尽管近年来语音合成[1-7]和音乐生成[8-10]领域均取得了显著进展,但能在零样本场景下实现灵活控制的高质量歌声生成技术仍未得到有效突破。为填补这一技术空白,我们提出了SoulX-Singer——一款支持多语言高质量零样本歌声生成的合成系统。
早期的歌声合成研究主要聚焦于基于训练集中已见说话人或歌手的歌声生成[11-13]。以DiffSinger[11]为代表的经典系统,训练所采用的数据集规模较小且标注经过精细筛选,因此缺乏对未见歌手的泛化能力,这一局限性极大地限制了此类模型在实际场景中的应用。后续的StyleSinger[14]、TCSinger系列模型[15,16]等研究开始探索零样本歌声合成方向,但这些方法的训练数据仅包含数百小时、少量歌手的歌声数据,难以在实际应用中实现鲁棒的零样本泛化。
近期,Vevo2[17]和YingMusic-Singer[18]分别依托Transformer[19]和Diffusion Transformer(DiT)[20]架构的规模化能力,将歌声训练数据集的规模拓展至数千小时级别。尽管取得了上述进展,但这两款系统均采用旋律驱动的合成范式,不支持音符级别的时长控制,由此带来两个核心局限性:其一,需要从现有歌曲中提取旋律,无法仅基于乐谱和歌词完成歌曲生成;其二,由于未对音符时长进行显式建模,音节级别的时序控制无法实现,导致合成歌声与原始伴奏出现时间错位,这一问题严重限制了其在音乐制作流程中的实际应用,尤其在混音和编曲环节。
为解决上述问题,我们提出了SoulX-Singer系统。与现有最多采用数千小时训练数据的研究不同,我们构建了包含超4.2万小时歌声音频的大规模人声数据集,大幅提升了模型的零样本泛化能力。在算法设计层面,SoulX-Singer同时支持基于乐谱的可控歌声生成和基于旋律的条件化合成,能在各类实际场景中实现灵活的生成控制。这种双控制模式的设计,让SoulX-Singer既能很好地适配基于符号乐谱的音乐创作流程,也能满足从现有歌曲出发、基于旋律引导的歌声生成需求。
本研究的核心贡献可总结如下:
- 高质量零样本歌声合成模型:提出面向零样本场景设计的高质量歌声合成模型SoulX-Singer。该模型在统一框架内同时支持乐谱输入和旋律输入,可实现高保真的音色克隆、基于参考的歌声风格迁移,以及乐谱和歌词的灵活编辑,适用于各类实际的音乐制作流程。
- 大规模歌声数据处理流水线:设计了一套大规模数据处理流水线,该流水线以带背景音乐的歌曲为输入,可自动生成纯净的人声录音,并匹配对齐后的歌词与乐谱。基于该流水线,我们构建了包含普通话、英语、粤语三种语言,超4.2万小时人声录音的多语言歌声数据集,数据规模较现有歌声合成研究实现了一个数量级的提升。
- 零样本歌声合成专用评估基准:为实现零样本歌声合成性能的系统化、可复现评估,我们构建了专用基准测试集,包含50位未见歌手的普通话和英语歌声数据,并附带精细的音符级乐谱标注。该基准测试集提供了标准化的评估协议,可对合成质量、可控性和泛化能力进行量化评估,也为未来的歌声合成研究提供了可靠的测试平台。
在后续章节中,我们将首先介绍SoulX-Singer的数据集构建方法和模型架构,随后对其在歌声合成任务中的性能进行全面评估。
2 方法
带有对齐MIDI乐谱和歌词标注的纯净人声录音,是训练具备精细乐谱级可控性歌声合成模型的关键。本章节中,我们将首先阐述本研究采用的数据处理流水线,包括从混音歌曲中提取人声、MIDI信息标注和歌词转写;随后详细介绍SoulX-Singer的整体架构和核心算法。
2.1 数据处理
为获取对齐的人声音频、MIDI乐谱和歌词标注,整体数据处理流程包含人声分离、歌词转写和音符转写三个核心环节(如图2所示)。此外,为支持旋律控制的歌声合成,我们还从人声录音中提取了基频(F0)。
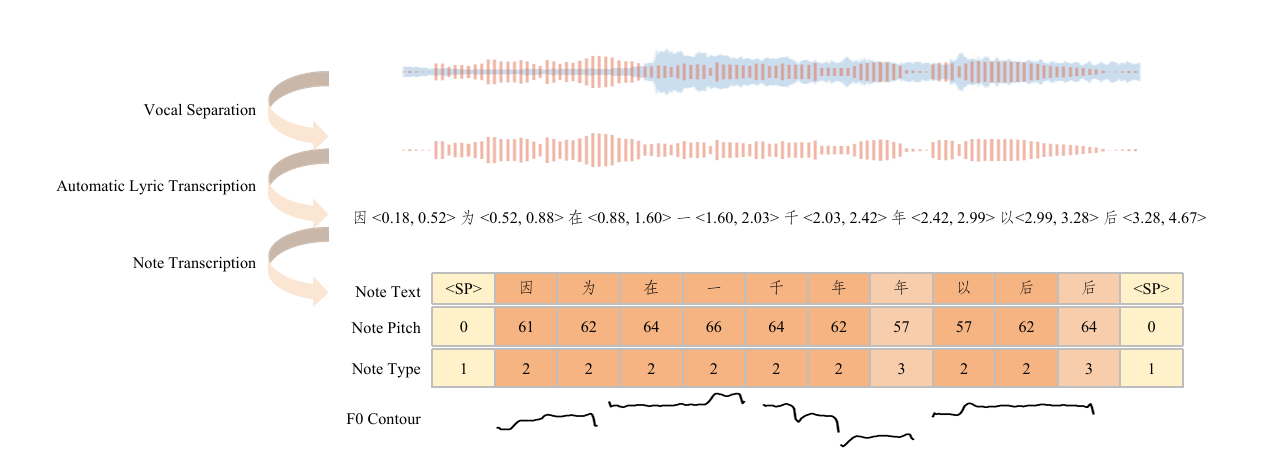
图2:大规模歌声数据构建流水线:从原始音频提取到时序对齐的MIDI乐谱与文本构建
2.1.1 处理流程
人声分离:为获取无背景和声的高纯度干声人声,我们采用两阶段的人声提取方案。具体而言,首先基于预训练的主旋律分离模型³分离主旋律人声并抑制背景和声;由于商业录音在混音过程中通常会加入混响效果,我们随后使用预训练的人声去混响模型⁴对分离后的人声进行处理。上述两款模型均基于Mel-Band Roformer[21]构建,为高保真合成和大规模模型训练奠定了纯净的声学基础。
自动歌词转写:为实现歌词与人声的精准对齐,我们首先进行鲁棒的语言识别。具体采用SenseVoiceSmall⁵作为预训练骨干网络,并在标注有普通话、粤语、英语的歌声数据集上进行微调。完成语言识别后,采用语种专属的ASR模型提取歌词及单词级时间戳:普通话和粤语采用Paraformer⁶模型,英语采用Parakeet-TDT-0.6B-V2⁷模型。为保证数据质量,我们将提取的歌词与句子级标注的参考歌词进行比对,剔除包含插入、删除错误的样本,并利用参考词汇修正替换错误,该流程确保了大规模模型训练所需的语言准确性。
音符转写:为生成与歌词对齐的音符级表征,我们采用ROSVOT模型[24]进行音高类别估计和音符边界检测。具体以前一环节得到的带时间戳歌词为输入,生成包含文本、音高、音符类型和时长的音符级token序列,且所有token在时间轴上实现精准对齐。这些对齐后的token为可控、富有表现力的歌声合成奠定了必要基础。
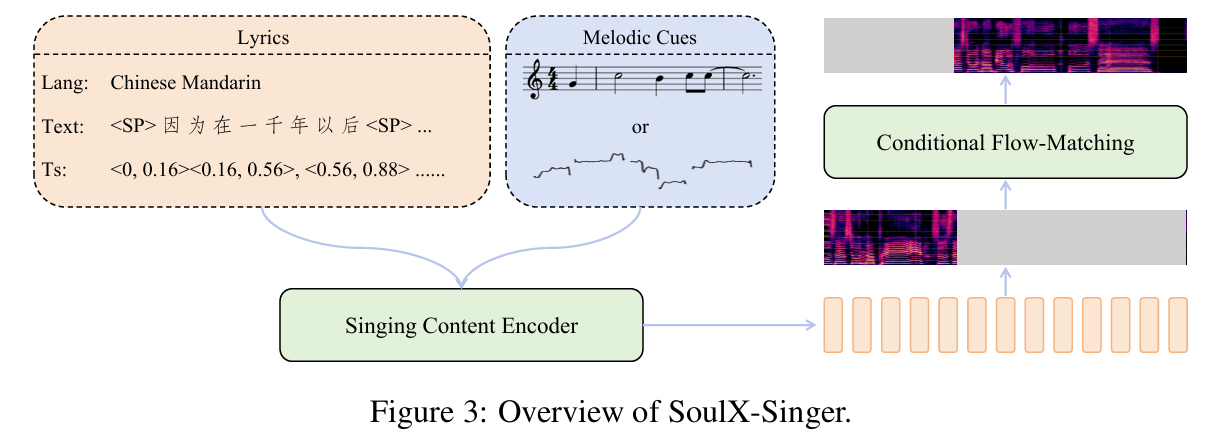
图3:SoulX-Singer模型整体架构
2.1.2 语料库概述
基于上述处理方法,我们共获取约4.2万小时的高质量人声录音,其中普通话和英语各约2万小时,粤语约2000小时。为实现对歌声的精准建模,该数据集以音乐音符为基本单位进行组织,而音符也是模型合成的基础单元。具体而言,每个音符被表示为一个元组,包含对应的文本token、音高类别和音符类型;其中音符类型为类别属性,取值1、2、3分别对应休止符、歌词符和连音符。这种音符级的表征方式实现了语言结构与旋律结构的高精度对齐,为可控且富有表现力的歌声合成提供了坚实基础。
2.2 SoulX-Singer模型
SoulX-Singer是一款基于流匹配的非自回归(NAR)歌声合成模型,专为高质量、可控的歌声生成设计。模型的核心骨干网络是基于Diffusion Transformer(DiT)[25]构建的流匹配解码器,该解码器以歌词和旋律特征为输入,预测梅尔频谱,并通过神经声码器将预测的梅尔频谱转换为音频波形。
为对歌声合成所需的多模态异构信息(歌词、乐谱、音符类型、F0)进行有效编码,SoulX-Singer引入了歌声内容编码器。该编码器将输入特征转换为丰富且时序对齐的表征,为解码器提供结构化、信息丰富的隐空间,保障梅尔频谱的精准生成。通过将基于流的非自回归建模与专用内容编码相结合,SoulX-Singer既实现了对歌声表现的表现力控制,又达成了高效、高保真的合成效果。
2.2.1 特征表征
文本表征:对于普通话和粤语,建模单元为字级拼音;对于英语,建模单元为音素。为显式区分不同单词间的音素边界,每个英语单词对应的音素序列均通过专用边界token包裹,以开头、结尾。为进一步区分普通话和粤语的拼音表征,我们在拼音token后添加语种专属标签,让模型能够识别不同语言的发音规律。文本嵌入通过线性嵌入层获取。
旋律表征:旋律输入由离散的音符音高序列和连续的F0序列组成。两类序列首先经过二元门控层处理,再分别通过线性投影生成音符音高嵌入和F0嵌入。门控机制可调节各韵律特征的贡献度:训练阶段,随机丢弃音符音高或F0输入,促使模型从单一模态中提取鲁棒的特征;推理阶段,模型可灵活开启对应门控,实现基于旋律或基于乐谱的生成。
长度调节与特征融合:为在解码前将异构表征统一至相同的时间分辨率,我们采用长度调节器作为核心的特征融合机制。具体而言,将音符类型、音符音高和文本token对应的嵌入,按照每个音乐音符的时长进行扩展,使所有音符级表征与梅尔频谱的时间尺度对齐。完成长度扩展后,各类嵌入的时间维度和特征维度保持一致,通过按元素相加进行融合,生成统一的条件序列并输入至解码器。通过显式实现音符到梅尔频谱的对齐,长度调节器让语言内容与旋律结构实现精准同步,这是实现可控、富有表现力歌声合成的关键。
2.2.2 训练
SoulX-Singer的训练分为两个阶段进行,逐步提升模型的鲁棒性和长序列生成能力。
第一阶段,模型基于较短的音频片段训练,片段时长为2秒至16秒。该阶段中,提示梅尔频谱刻意从目标音频的非相邻片段中采样,这一设计促使模型减少对局部声学连续性的依赖,更多地利用输入的语言和音乐条件信息,从而提升模型在不同提示条件下的鲁棒性和泛化能力。
第二阶段,训练策略向长序列歌声建模转变。将相邻的音频片段拼接,构建时长为30秒至90秒的长训练样本,让模型能够捕捉歌声表演中的长距离时间依赖关系。为进一步强化模型的提示跟随能力,该阶段的提示音频从目标音频的紧邻前序片段中采样。
通过这种从短片段、非相邻提示到长片段、上下文相邻提示的两阶段训练策略,SoulX-Singer既实现了鲁棒的条件化生成,又能对长时长歌声音频进行有效建模。
2.2.3 推理
推理阶段,SoulX-Singer支持两种互补的生成模式,可根据可用的韵律控制信号无缝切换,具备高度的灵活性。
旋律控制模式:适用于已有目标旋律的场景。该模式下,模型以目标歌词和从参考音频中提取的连续F0轮廓为主要输入,能忠实保留细粒度的旋律细节和富有表现力的演唱技巧,同时仍支持歌词的灵活修改和音色转换。
乐谱控制模式:专为创意合成场景设计。该模式下,输入仅包含MIDI乐谱信息和目标歌词,模型在乐谱的约束下自主预测符合自然性的声学特征。由于摆脱了对预录制旋律线的依赖,该模式为创作者提供了更高的艺术创作自由度,实现高保真的零样本歌声合成。
3 SoulX-Singer的性能评估
3.1 评估数据集
目前歌声合成领域尚无被广泛采用的标准化基准测试集,因此我们构建了两个互补的评估数据集,以全面评估SoulX-Singer在开源数据集和零样本场景下的性能,分别为GMO-SVS和SoulX-Singer-Eval。
GMO-SVS:该数据集基于多个公开的歌声合成语料库构建,包括GTSinger[26]、M4Singer[27]和Opencpop[28]。对于M4Singer和Opencpop,我们直接采用其官方测试集划分:M4Singer包含4位歌手演唱的8首普通话歌曲,覆盖四种音域;Opencpop包含1位专业女歌手演唱的5首普通话歌曲;GTSinger包含5位歌手演唱的25首英、普双语歌曲,涵盖多种演唱技巧和表现风格。
GMO-SVS数据集共包含802个样本,对于每首歌曲,取第一句话作为声学提示,剩余内容由待评估模型合成。重要的是,该数据集保留了提示歌手的真实录音,可对发音准确性、韵律一致性和整体合成质量进行全面评估。需要特别强调的是,SoulX-Singer的训练过程未使用上述任何开源数据集,确保了评估的公平性和无偏性。
为进一步评估模型在歌声编辑场景中的性能,我们对目标歌词进行改写:利用DeepSeek-V大语言模型重写每首歌曲的原始歌词,同时严格保证单词数量与原文一致。该设置可评估模型在歌词修改后,保持旋律和表现特征的能力。
SoulX-Singer-Eval:这是一个全新采集的数据集,专为评估模型对未见说话人的零样本泛化能力设计。数据集包含50位不同说话人(25位普通话、25位英语)的100个歌声片段,每位说话人对应2个片段。其中普通话数据来自招募的专业和业余歌手,所有歌手均同意将其声音数据开源用于学术研究;英语片段从多音轨Mixing Secrets数据集[29]中切分并筛选得到。关键的是,SoulX-Singer-Eval中的所有片段均经过精细的人工旋律标注,满足各类零样本歌声合成模型的提示输入要求。合成所用的目标歌词和旋律从GMO-SVS的15首普通话、15首英语曲目中原型选取。该数据集引入了所有基线模型均未见过的说话人,为模型的音色克隆和风格迁移能力提供了严格的评估基准。
3.2 评估指标
为全面评估歌声合成性能,我们从旋律准确性、音色相似度、可懂度和整体歌唱质量四个核心维度对SoulX-Singer进行评估,每个指标均经过精心选取,用于量化合成歌声在保真度和表现力不同维度的表现。
旋律准确性:采用基频帧误差(FFE)衡量音高精度,其定义为预测音高与真实F0偏差超过20%的帧占总帧的比例。
音色相似度:为评估零样本场景下模型还原声学提示音色的能力,我们计算合成音频与对应提示的说话人嵌入之间的余弦相似度(SIM),说话人嵌入由基于WavLM的说话人验证模型[30]提取。
可懂度:通过词错误率(WER)评估发音准确性,计算方式为将目标歌词与合成音频的自动语音识别(ASR)转写结果进行比对。普通话样本的标准评估指标为字错误率(CER),但为简化计算并保证跨语言评估的一致性,本研究所有结果均采用WER表示:普通话采用Paraformer[23]模型转写,英语采用Whisper-large-v3[31]模型转写。
歌唱质量:采用两种基于学习的客观指标评估整体感知质量:SingMOS[32]是专为歌声设计的质量评估指标,其训练目标与人类主观感知高度对齐;Sheet-SSQA(Sheet)[33]基于MOS-Bench框架构建,适用于零样本场景的感知质量评估,且对未见说话人具备良好的泛化能力。
3.3 实验结果
3.3.1 GMO-SVS数据集上的性能
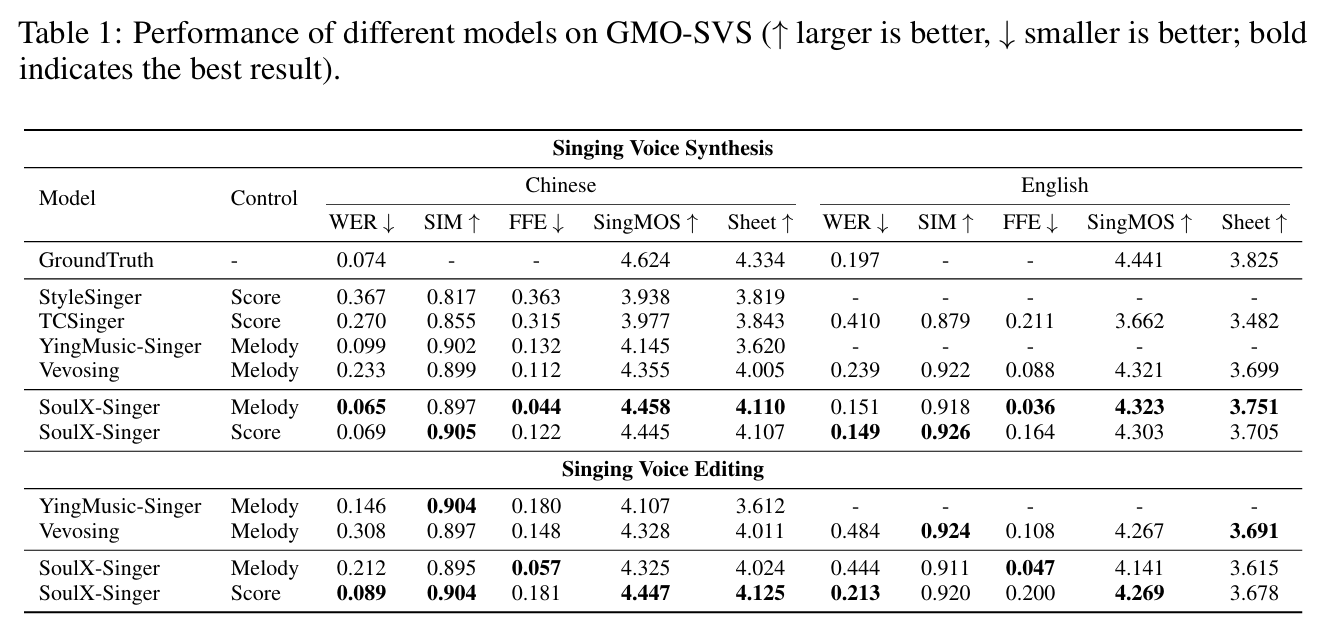
表1展示了SoulX-Singer与其他基线方法在GMO-SVS数据集上的性能对比,其中“歌声编辑”表示歌词经过重写。在基础歌声合成任务中,SoulX-Singer在普通话和英语上的性能均优于所有基线模型:采用连续F0轮廓控制(旋律控制模式)时,模型取得了最低的FFE,显著超越性能最优的基线模型YingMusic-Singer,这表明显式的声学特征能引导流匹配解码器生成精准的音高轨迹;采用离散MIDI音符驱动(乐谱控制模式)时,SoulX-Singer的WER最低,优于Vevosing和TCSinger,说明基于MIDI的时序约束有助于稳定发音和节奏,对复杂音素的效果尤为明显。在两种模式下,SoulX-Singer的SingMOS和SIM指标均达到业界最优,验证了该架构在音高条件和乐谱条件合成场景下的鲁棒性和泛化能力。
歌声编辑场景下的实验结果,反映了歌词修改后不同模型的性能表现。如表所示,与原始歌词场景相比,基于旋律的方法在可懂度上出现明显下降,这是因为原始旋律与歌词存在内在关联(例如音高轮廓与原始单词对齐),歌词修改会导致二者出现一定程度的失配。相比之下,支持MIDI乐谱控制的SoulX-Singer在歌词修改后仍能保持较好的性能,由于模型依赖显式的乐谱而非原始声学旋律,能在不损失发音准确性和节奏一致性的前提下,有效适配改写后的歌词。
3.3.2 SoulX-Singer-Eval数据集上的性能
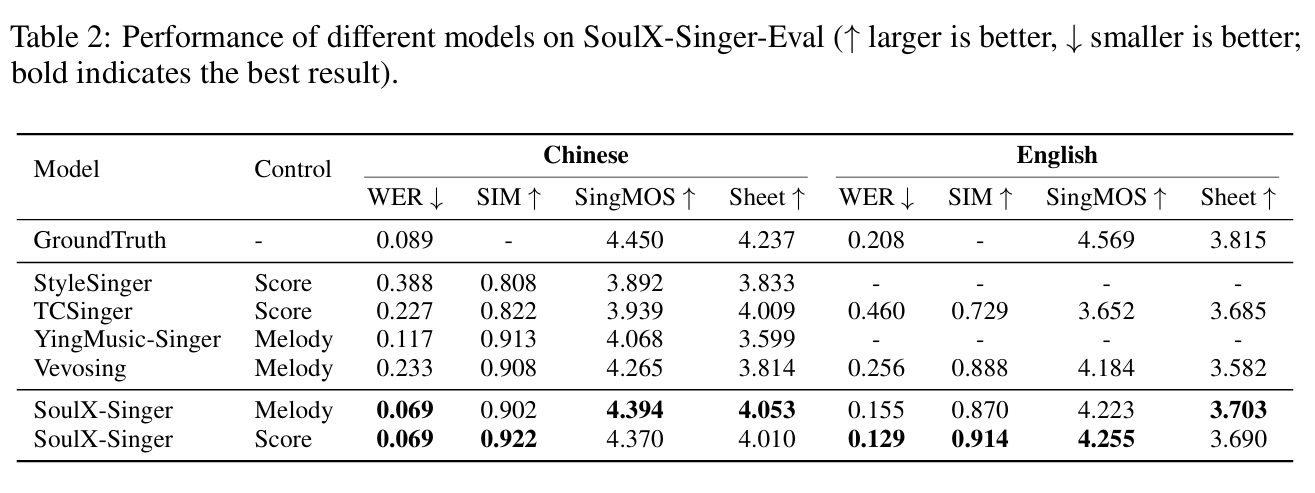
为评估模型的音色克隆和风格迁移能力,我们在SoulX-Singer-Eval数据集上开展实验,该数据集包含所有对比方法在训练中均未见过的说话人。表2结果显示,即便面对未见目标说话人,SoulX-Singer的性能仍持续优于所有基线模型;其中基于乐谱控制的SoulX-Singer取得了最高的SIM值(普通话0.922、英语0.914),证明了其鲁棒的零样本语音克隆能力。
3.3.3 跨语言合成评估
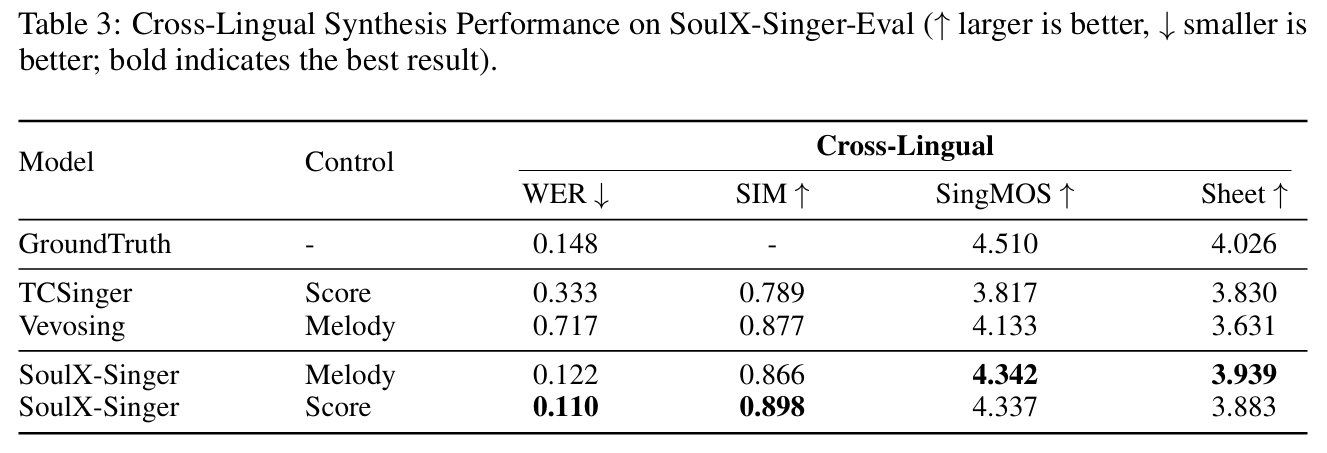
为进一步评估模型的跨语言合成能力(例如以普通话为提示,合成英语歌声),该任务要求模型将说话人身份与语言内容进行严格解耦,实验结果如表3所示。基线模型Vevosing的可懂度出现严重下降,WER高达0.717,说明提示的语言模式泄露至生成结果中;而SoulX-Singer在保持0.898的高SIM值的同时,WER仅为0.110,证明其能在跨语言场景下稳定保留说话人身份。上述结果充分验证了歌声内容编码器的有效性,该编码器成功将与语言无关的音色特征和与语言相关的内容特征分离,实现了高保真的跨语言风格迁移,且不会损失发音准确性和人声身份特征。
4 结论
本研究提出了一款高保真的零样本歌声合成模型——SoulX-Singer。该模型基于超4.2万小时的音符级对齐数据集训练,支持旋律和乐谱的双重灵活控制,同时能忠实还原多样的音色特征。在多个基准测试集上的大量评估结果表明,SoulX-Singer在音高准确性、可懂度、音色相似度和整体歌唱质量等维度,均持续优于当前业界最优的基线模型。通过将显式的声学和符号特征与大规模数据相结合,SoulX-Singer为个性化歌声合成、音乐制作、多语言声乐内容生成等创意应用奠定了坚实的技术基础,也为未来零样本表现力歌声合成和歌声编辑的研究指明了方向。
5 伦理声明
SoulX-Singer的研发与开源带来了重要的伦理考量。作为一款零样本歌声合成系统,该模型仅需一段短参考提示,即可生成高度逼真的歌声,这可能带来语音冒充和滥用的风险。因此,我们强烈建议SoulX-Singer的用户在生成歌声内容时,遵守知识产权、隐私保护和个人知情同意的相关规定。该系统不得用于未经授权的个人声音冒充,也不得用于制作具有欺骗性、误导性的音频内容。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)