复杂查询性能优化:连接条件下推的代价模型设计与实践

在企业级业务系统的实际应用中,SQL 语句的编写往往脱离了教科书的简洁范式。随着业务场景的多元化与数据量的爆发式增长,CTE 公用表达式、多层嵌套子查询、窗口函数、多维度聚集计算等高级语法被大量用于组织复杂业务逻辑。这类写法虽大幅提升了 SQL 的可读性与可维护性,却给数据库查询优化器带来了严峻的执行挑战,尤其是在 JOIN 条件无法有效下推至子查询、无法提前过滤数据的场景下,查询性能会出现断崖式下降,成为业务系统的性能瓶颈。
本文将围绕真实客户生产场景中频繁出现的复杂查询因 JOIN 条件下推失败导致的性能问题,系统性拆解该问题的核心痛点与业界解决难点,并详细介绍金仓数据库基于代价模型的连接条件下推(Cost-based Join Predicate Pushdown) 的设计思路、实现细节与落地效果,为复杂查询优化提供可落地的内核级解决方案。
一、问题背景
1.1 客户场景中的典型痛点
在金融、政务、制造等多行业的客户业务系统中,为了贴合复杂的业务逻辑,SQL 通常呈现**“子查询内复杂计算 + 外层多表关联过滤”** 的典型模式:
- 在子查询或 CTE 中完成全量数据的去重、多维度聚集、窗口函数计算等耗时操作
- 在外层将子查询结果与其他业务表进行 JOIN 关联,并通过高选择性过滤条件筛选目标数据
典型示例:
从业务语义层面分析,这条 SQL 完全符合业务逻辑设计,无任何语法与逻辑问题;但从数据库执行层面看,其背后隐藏着严重的性能隐患,核心问题集中体现在过滤时机滞后:
- 子查询 s 需对基表 s1 进行全量扫描并执行 DISTINCT 去重,无法感知外层过滤条件
- 外层
s2.b = 3作为高选择性条件,无法反向约束子查询的扫描与计算范围,导致子查询做“无用功” - 子查询输出超大中间结果集,大幅占用内存与磁盘 IO 资源
- 后续的 JOIN 关联、聚集计算等操作均基于“大数据量”执行,计算效率急剧下降,查询响应时间大幅增加
究其根本,这类性能问题的核心并非 JOIN 操作本身的效率问题,而是数据过滤发生得不够早,未能在数据处理的源头减少数据量,导致后续所有操作都在冗余数据上执行。
1.2 业界普遍面临的两大核心难点
将外层 JOIN 条件下推到子查询内部,从执行逻辑上看是解决上述问题的直观有效优化方向,但在数据库内核的实际实现中,该操作面临两大无法回避的核心难点,也是业界各大数据库厂商的共同挑战。
1.2.1 语义安全性(Equivalence)
JOIN 条件下推的本质,是改变查询谓词的生效位置与执行时机,将原本在外层执行的过滤操作提前至子查询内部。这一操作若处理不当,极易破坏 SQL 的原始语义,导致查询结果失真,尤其是在包含数据聚合、行级计算、集合操作的复杂子查询中,语义破坏的风险更高,典型风险场景包括:
- 聚集操作(GROUP BY / SUM/COUNT 等聚合函数):下推条件可能改变聚合基数,导致聚合结果错误
- 窗口函数(Window Function):下推条件可能破坏窗口分区与排序的完整性,导致计算结果偏差
- 集合操作(DISTINCT / UNION / INTERSECT):下推条件可能过滤掉有效数据,导致集合结果不完整
- 特殊表达式(含有副作用/非确定性函数):如 NOW()、RAND() 等函数,执行时机改变会导致结果不一致
因此,JOIN 条件下推的首要前提是语义等价,并非所有 JOIN 条件都可以安全下推,必须建立严格、完善的等价性判定规则,确保下推后查询结果与原始查询完全一致。
1.2.2 代价评估(Cost)
即便 JOIN 条件通过了语义等价性判定,能够安全下推,也不代表下推操作在执行效率上一定“划算”。在部分场景下,盲目的下推反而会导致查询性能下降,甚至出现灾难性的性能回退,典型问题包括:
- 下推后可能触发参数化执行,子查询的执行依赖外层表的列值,增加执行计划的复杂度
- 当外层表基数较大时,参数化的子查询会被重复执行 N 次,产生大量的重复计算开销
- 若下推条件的选择性较低,无法有效减少子查询数据量,反而会因执行计划改写增加优化器的计算成本
这意味着,数据库优化器在处理 JOIN 条件下推时,必须建立代价评估体系,实现“能推”与“值得推”的双重判断,让下推操作服务于整体查询性能的提升,而非单纯的规则改写。
二、传统优化方案的核心局限
面对“子查询复杂计算 + 外层关联过滤”的复杂 SQL,传统数据库优化器的执行策略较为单一,整体遵循**“先计算、后关联、再过滤”** 的固定流程,具体执行步骤为:
2.1 完整执行子查询
对包含复杂计算的子查询进行全量执行,依次完成基表扫描、DISTINCT 去重、UNION 集合、窗口函数计算、聚集统计等所有操作,不做任何数据裁剪。
2.2 生成大规模中间结果集
子查询全量执行后,会生成包含所有计算结果的中间数据集,该数据集无任何过滤,数据量通常与基表持平,大幅占用存储与内存资源。
2.3 外层关联与过滤
将子查询生成的大中间结果集与外层表进行 JOIN 关联,再执行 WHERE 过滤条件,筛选出最终目标数据。
这一执行策略的致命问题在于:外层的高选择性 JOIN / WHERE 条件,无法反向约束子查询的扫描与计算范围,形成了“子查询做全量计算,外层做精准过滤”的资源浪费格局。当子查询本身包含复杂计算、基表数据量较大时,这种执行路径会让子查询成为整个查询的性能瓶颈,甚至导致查询超时,无法满足业务系统的响应要求。
传统优化方案的核心缺陷,本质是优化器仅能实现**“规则化的简单改写”**,缺乏“语义等价判定 + 代价驱动决策”的双重能力,无法对复杂查询进行精细化的执行计划优化。
三、金仓数据库基于代价的连接条件下推设计
针对传统优化方案的局限,结合真实客户的性能痛点,金仓数据库在V009R002C014版本中,全新设计并实现了一套**“等价性判定 + 代价模型”双重约束的连接条件下推机制。该机制突破了传统规则化改写的限制,实现了复杂查询下 JOIN 条件的安全、智能、高效下推**,整体设计思路可概括为“先判断能否推,再评估是否值得推”的两步核心逻辑,从根本上解决了复杂查询的性能瓶颈。
3.1 能不能推:严谨的语义等价性判定(Equivalence)
本阶段优化器的核心目标并非“尽可能多地下推条件”,而是只识别并保留绝对安全的下推机会,将语义错误的风险降至为零。为实现这一目标,优化器构建了多层级的等价性判定体系,具体执行步骤为:
- 子查询结构分析:深度解析子查询的语法结构,识别其中是否包含聚集操作、窗口函数、集合操作、非确定性函数等高危元素,划定下推条件的基础范围;
- 复杂结构约束性判定:针对包含高危元素的复杂子查询,制定专属的下推判定规则,例如:聚集子查询仅允许对聚合键的等值条件下推,窗口函数子查询仅允许对分区键的过滤条件下推;
- JOIN 条件拆分:将外层 JOIN 条件拆分为可参数化部分(依赖外层表列值) 和子查询内部列部分(仅依赖子查询基表),分别判定两类条件的下推可行性;
- 谓词改写与注入:将通过等价性判定的 JOIN 谓词,改写为子查询可识别的过滤条件,精准注入到子查询的扫描阶段或过滤阶段,确保条件在数据处理的源头生效。
这一步骤从根本上解决了核心问题:推下去之后,查询结果会不会变? 让 JOIN 条件下推建立在“语义绝对等价”的基础上,保障查询结果的正确性。
3.2 值不值推:智能的代价模型评估(Cost)
通过语义等价性判定,仅代表 JOIN 条件可以安全下推,但不代表下推操作能带来性能收益。因此,金仓数据库优化器在完成等价性校验后,并不会立刻执行下推,而是进入代价模型评估阶段,通过量化计算选择全局代价最低的执行计划,具体评估逻辑为:
- 双执行路径代价估算:分别估算“JOIN 条件下推”和“JOIN 条件不下推”两种执行路径的整体代价,代价评估维度包含:基表扫描行数、IO 开销、CPU 计算开销、中间结果集规模、内存占用等;
- 关键指标对比:重点对比两种路径下子查询的扫描行数、中间结果集大小,评估下推条件对数据量的裁剪能力;
- 额外开销评估:针对参数化执行的场景,量化评估子查询重复执行的计算开销,判断该开销是否能被数据量裁剪带来的收益覆盖;
- 全局最优决策:优化器综合所有代价指标,若下推路径的整体代价低于不下推路径,则执行下推操作;若代价模型判断下推收益不足,甚至可能带来性能回退,则自动放弃下推,选择原有的最优执行路径。
这一步骤从根本上解决了核心问题:推下去之后,查询真的会更快吗? 让 JOIN 条件下推服务于整体性能提升,避免盲眼下推导致的性能问题。
详细工作流程: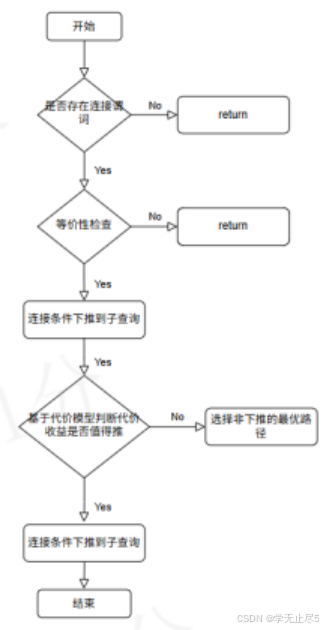
四、效果验证
为充分验证基于代价的连接条件下推机制的实际性能收益,我们分别构建最小化测试用例和复杂业务场景用例,从“简单场景有效性”和“复杂场景适配性”两个维度进行测试验证,同时对比友商数据库的执行效果,突出金仓数据库的优化优势。所有测试均基于相同的硬件环境与数据集,确保测试结果的客观性与可比性。
4.1 最小化用例:验证基础下推能力
测试 SQL:
Select * from (select distinct * from s3)s3 ,s1 where s1.s1a =s3.s3a ;
测试目标:验证简单子查询(含 DISTINCT)场景下,JOIN 条件下推对扫描范围、执行时间的优化效果。
未下推执行效果
- 执行逻辑:子查询对 s3 做全表扫描 + DISTINCT 去重,生成全量中间结果后,再与 s1 进行 JOIN 关联
- 执行计划:
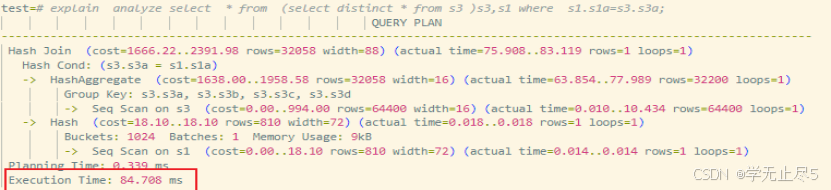
执行时间约 84ms
下推后执行效果
- 执行逻辑:JOIN 条件
s1.s1a = s3.s3a下推至子查询内部,子查询通过索引扫描 s3 表,仅扫描符合条件的数据并去重,大幅减少数据处理量 - 执行计划:
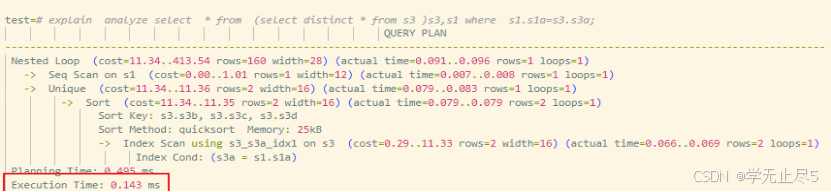
执行时间约 0.14ms
友商数据库对比(D厂商,不支持下推)
执行 SQL:
explain select /*+use_nl (s3 s1)*/*from (select distinct * from s3)s3,s1 where s1.s1a=s3.s3a;
执行计划: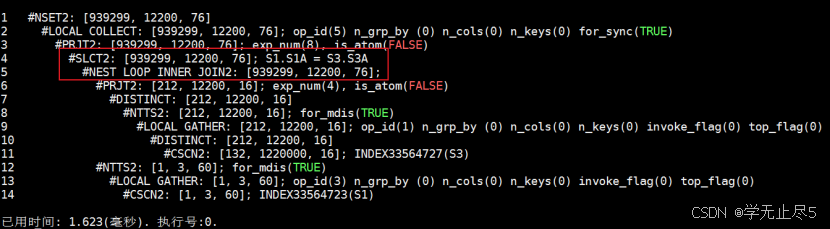
执行时间:约 1.62ms
测试结论
金仓数据库开启连接条件下推后,子查询从“全表扫描”转为“索引选择性扫描”,中间结果集规模显著下降,执行时间从 84ms 降至 0.14ms,性能提升超600倍;即便与友商数据库对比,金仓数据库的执行效率也具备明显优势,充分验证了基础下推机制的有效性。
4.2 复杂场景验证:验证多元素适配能力
测试 SQL:
explain analyze
select *from (select * from (select distinct * from
s3 union select distinct *from s3 a )s3,s1 where s1.s1d=s3.s3a ) s
join (select * from (select s3a ,sum(s3b)
over (partition by s3a) s3d from s3 )s3,s1
where s1.s1a=s3.s3a) j on s.s3d =j.s3a;
测试目标:验证包含UNION 集合、DISTINCT 去重、窗口函数、多层嵌套子查询、多表关联的复杂业务场景下,连接条件下推的适配性与性能收益,贴合真实客户的生产场景。
未下推执行效果
- 执行逻辑:多个子查询均对基表 s3 进行全量扫描,依次完成 DISTINCT 去重、UNION 合并、窗口函数计算,生成多个超大中间结果集;最终多个大结果集进行 JOIN 关联,JOIN 操作成为性能瓶颈
- 执行计划:
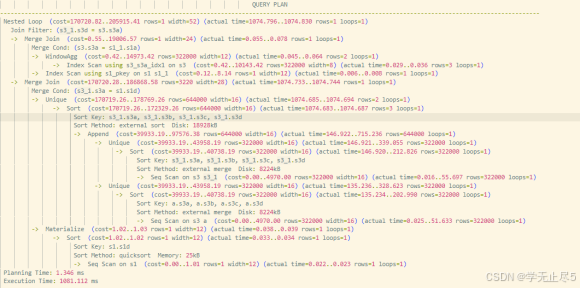
- 执行时间:约 1081ms
下推后执行效果
- 执行逻辑:优化器将多层外层 JOIN 条件分别下推至对应的子查询内部,所有子查询均基于下推条件进行选择性扫描,仅处理符合条件的数据;中间结果集规模大幅收缩,后续 JOIN 操作基于小数据集执行,效率大幅提升
- 执行计划:
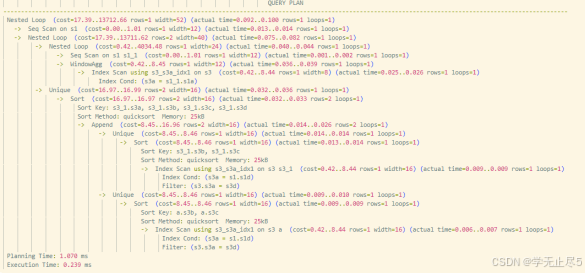
- 执行时间:约 0.23ms
执行逻辑深度解析
- 未下推时:查询遵循“全量计算→生成大结果集→关联过滤”的逻辑,UNION 左右两侧对基表 s3 做全量去重扫描,生成超大结果集 A;结果集 A 与 s1 关联生成结果集 B;右侧子查询对 s3 全量扫描并计算窗口函数,生成结果集 C,再与 s1 关联生成结果集 D;最终大结果集 B 与 D 关联,全量扫描带来的 IO 与计算开销成为性能核心瓶颈。
- 下推后时:JOIN 条件被精准下推至所有子查询的扫描阶段,子查询在数据处理源头就通过索引完成条件筛选,将“全量扫描”转为“选择性扫描”;筛选后的小结果集再进行后续的去重、UNION、窗口函数计算,大幅减少了 IO 开销与计算量;最终小结果集之间的关联操作效率大幅提升,从源头实现了性能优化。
测试结论
在包含多层复杂元素的真实业务场景下,金仓数据库的连接条件下推机制依然能精准适配,实现从全量扫描到选择性扫描的核心转变,执行时间从 1081ms 降至 0.23ms,性能提升超4700倍,充分验证了该机制在复杂场景下的有效性与适配性,能有效解决客户生产环境中的复杂查询性能瓶颈。
五、总结与展望
在企业级复杂查询优化领域,连接条件下推并非简单的“规则化谓词改写”问题,而是典型的成本驱动型智能优化问题,其核心难点在于平衡“语义安全性”与“性能收益性”:
- 若仅依靠规则进行下推,不做代价评估,可能在部分场景下带来灾难性的性能回退,违背优化的初衷;
- 若仅追求代价最优,不建立严格的等价性判定体系,会直接破坏 SQL 语义,导致查询结果失真,影响业务系统的正确性。
金仓数据库设计的**“等价性保障 + 基于代价的决策”** 组合式连接条件下推机制,通过“先判断能否推,再评估是否值得推”的两步核心逻辑,完美解决了上述矛盾,实现了复杂查询的安全、智能优化,核心价值体现在:
- 语义绝对安全:通过多层级的等价性判定体系,确保下推操作不改变原始查询的语义,保障查询结果的正确性;
- 性能收益显著:在安全的前提下,将过滤条件提前至数据处理源头,最大化发挥 JOIN 条件的过滤能力,显著减少子查询的扫描行数与中间结果集规模,实现数量级的性能提升;
- 场景高度适配:对包含聚集、窗口函数、UNION、DISTINCT、多层嵌套的复杂查询具备良好的适配性,贴合企业级生产场景的实际需求。
从数据库技术的演进方向来看,这类基于代价模型的精细化查询优化,对于 OLAP 分析型负载、HTAP 混合负载以及复杂报表型查询尤为关键,也是下一代数据库查询优化器的核心演进方向。未来,金仓数据库将继续基于真实客户的业务痛点,不断迭代代价模型,丰富等价性判定规则,将该优化机制延伸至更多复杂场景,同时结合人工智能、机器学习技术,实现查询优化的自学习、自适配,为企业级业务系统提供更高效、更智能、更稳定的数据库内核支撑。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 46
46 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)