即插即用系列 | CVPR 2024注意力机制SCSA:空间与通道的完美协同,吊打CBAM/ECA
论文名称:SCSA: Exploring the Synergistic Effects Between Spatial and Channel Attention
论文原文 (Paper):https://arxiv.org/abs/2407.05128
代码 (code):https://github.com/HZAI-ZJNU/SCSA
哔哩哔哩视频讲解:https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
本论文的完整复现代码(即插即用版)已更新至专栏
即插即用系列(代码实践) | CVPR 2024注意力机制SCSA:空间与通道的完美协同,吊打CBAM/ECA
1. 核心思想
- 本文提出了一种新颖的即插即用注意力模块,名为 SCSA(空间与通道协同注意力)。
- 其核心思想是,现有的混合注意力机制(如 CBAM)只是简单地串联或并联空间和通道注意力,未能充分研究两者之间更深层次的“协同效应”。
- SCSA 创新性地提出了一种**串行(Sequential)**架构,通过两个新颖的模块
SMSA和PCSA来实现这种协同。 SMSA(共享多语义空间注意力)首先从空间维度提取**“多语义”**的特征(例如,一个特征图关注“眼睛”,另一个关注“轮廓”)。- 然后,
PCSA(渐进式通道自注意力)接收这些空间“先验”,并利用通道自注意力来**“缓解”这些不同语义之间的“差异”**(disparities),最终输出一个经过空间引导和通道融合的、高度精炼的特征。
2. 背景与动机
-
在 CNN 架构中,特征提取依赖于卷积层。然而,卷积本身存在梯度流失真、信息丢失或特征冗余等问题。为了解决这些问题,“即插即用”的注意力模块(如通道注意力 SENet、空间注意力、混合注意力 CBAM)被广泛采用,它们通过“激励-抑制”机制来增强有辨识度的特征。
然而,这些现有的混合注意力模块存在两个被忽视的核心问题:
- 缺乏“多语义”空间指导: 现有的空间注意力(如 CBAM)通常将所有通道信息压缩成一个单一的空间注意力图。这种“一刀切”的压缩方式忽视了不同通道(或通道组)本身就携带着不同的“语义”信息。
- 未解决“语义差异”: 正如问题1所述,不同的特征通道可能关注完全不同的事物(例如,一个关注纹理,一个关注轮廓)。现有的注意力机制没有提供一个明确的机制来**“调和”或“融合”这些具有“语义差异”(semantic disparities)**的特征,导致信息交互不足。
因此,本文的动机是:1) 设计一个能提取并利用这种**“多语义空间信息”的模块;2) 设计一个能“缓解”并“融合”**这些不同语义特征的模块。
-
动机图解分析(Figure 1 & 4):
-
图表 A (Figure 1):揭示“多语义信息”和“语义差异”问题

- “看图说话”: 这张图是本文的核心动机。它展示了从不同特征图中提取的注意力热图。
- 分析:
- 上排(鲨鱼): 不同的特征图关注着完全不同的语义区域。一个图(黑圈)关注鲨鱼的眼睛;一个图(白圈)关注鱼鳍的边缘;一个图(红圈)关注身体的高光;一个图(蓝圈)关注尾鳍。
- 下排(家庭): 同样,不同的特征图关注不同的人(红框、黑框、青框…)。
- 结论: 这张图有力地证明了**“多语义信息”**(Multi-Semantic Information)是客观存在的,即不同的通道组承载着不同的语义焦点。
- 引出的问题(“语义差异”): 既然特征图之间存在如此巨大的**“语义差异”(semantic disparities),那么像 CBAM 那样粗暴地将它们全部压缩(AvgPool/MaxPool)成一个空间图,或像 SENet 那样压缩成一个通道向量,必然会导致严重的信息丢失**。模型需要一种新机制,既能利用这些多语义信息,又能解决它们之间的冲突和差异。
-
图表 B (Figure 4):验证 SCSA 的“协同”效果

- “看图说话”: 这张图对比了多种SOTA注意力方法和 SCSA(本文方法)的 Grad-CAM 可视化结果。
- 分析:
CBAM,ECA,CA,FCA等现有方法的注意力热图都比较**“弥散”**(diffuse)。它们能大致定位到物体(如水塔或树干),但激活区域很大,包含了大量背景,不够精确。 - 本文方案:
SMSA(SCSA 的第一部分)生成的图(第5列)已经比其他方法更聚焦。PCSA(第二部分)生成的图(第6列)也相对集中。 - 协同结果: 当两者结合成
SCSA-50(最后一列)时,激活图变得极其锐利和聚焦。它几乎完美地勾勒出了水塔的结构和树干的轮廓,几乎没有背景激活。 - 结论: Figure 4 证明了本文的“协同”理念。
SMSA提取的多语义空间信息(如 Figure 1 所示)作为“先验”指导了PCSA,而PCSA则通过通道自注意力融合并精炼了这些信息,最终产生了远比“单打独斗”的注意力机制更精确、更紧凑的特征表示。
-
3. 主要贡献点
- 提出 SCSA 协同注意力框架: 创新性地提出了一个由
SMSA和PCSA串行组成的协同注意力模块。它明确地将注意力分为两个阶段:1) 多语义空间指导(SMSA) 和 2) 语义差异缓解与通道融合(PCSA)。 - 发明 SMSA 模块:
- 维度解耦: 首先在空间上(H 和 W 维度)将特征解耦为两个 1D 序列。
- 多语义提取: 将通道分为 4 组( K = 4 K=4 K=4),并使用**不同尺度(3, 5, 7, 9)的深度共享 1D 卷积(MS-DWConv1d)**来分别提取 4 种不同的“语义”空间信息。
- 组归一化(GroupNorm): 使用
GroupNorm(而非 BatchNorm)来独立归一化 4 组语义特征,防止了语义信息之间的干扰。
- 发明 PCSA 模块:
- 渐进式压缩: 接收来自 SMSA 的特征图后,PCSA 不像 SENet 那样直接压缩到 1 × 1 1 \times 1 1×1,而是先通过一个 7x7 的
AvgPool进行“渐进式压缩”,以保留更丰富的空间先验来指导后续的通道注意力。 - 通道自注意力 (CA-SHSA): 核心是使用了一个通道维度的单头自注意力(Single-Head Self-Attention)。
- 语义差异缓解: “单头”设计是关键。它强制所有来自 SMSA 的 4 组不同语义特征在同一个自注意力矩阵( C × C C \times C C×C)中进行交互和信息融合,从而缓解了它们之间的“语义差异”。
- 渐进式压缩: 接收来自 SMSA 的特征图后,PCSA 不像 SENet 那样直接压缩到 1 × 1 1 \times 1 1×1,而是先通过一个 7x7 的
4. 方法细节
-
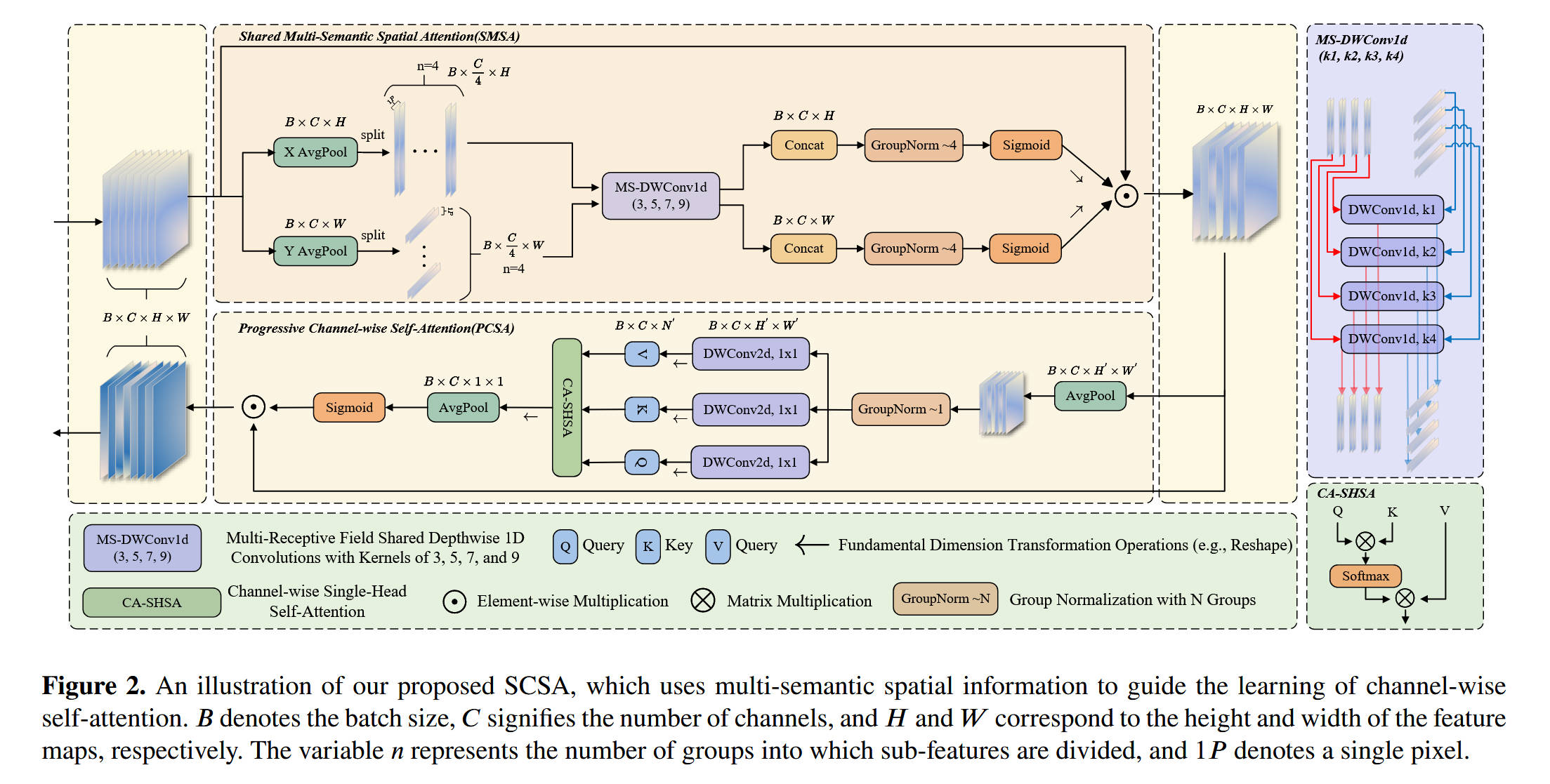
整体网络架构(Figure 2):
- 模型名称: SCSA (Spatial and Channel Synergistic Attention)
- 数据流: 这是一个**串行(Sequential)**的、两阶段的注意力模块,设计为即插即用的。
- 输入: X X X ( B × C × H × W B \times C \times H \times W B×C×H×W)
- 阶段 1:SMSA(共享多语义空间注意力)
- X X X 进入
SMSA模块(Figure 2 上半部分)。 - SMSA 模块对 X X X 进行处理,提取多语义空间先验,并将其施加回 X X X 上。
- 输出 X s = S M S A ( X ) X_s = SMSA(X) Xs=SMSA(X)( B × C × H × W B \times C \times H \times W B×C×H×W)。
- X X X 进入
- 阶段 2:PCSA(渐进式通道自注意力)
- X s X_s Xs(来自 SMSA 的输出)作为输入进入
PCSA模块(Figure 2 下半部分)。 - PCSA 模块利用 X s X_s Xs 提供的空间先验,执行通道维度的自注意力。
- 输出 X c = P C S A ( X s ) X_c = PCSA(X_s) Xc=PCSA(Xs)( B × C × H × W B \times C \times H \times W B×C×H×W)。
- X s X_s Xs(来自 SMSA 的输出)作为输入进入
- 输出: X c X_c Xc 是 SCSA 模块的最终输出,它是一个在空间和通道维度上都被精炼过的特征图。
-
核心创新模块详解(Figure 2):
-
对于 模块 A:SMSA (共享多语义空间注意力)
- 理念: 解决“多语义信息”提取和“语义干扰”问题。
- 数据流:
- 维度解耦 (Decoupling): 输入 X X X ( B × C × H × W B \times C \times H \times W B×C×H×W) 首先被解耦为两个 1D 特征序列:
X AvgPool(沿 W 压缩):得到 X H X_H XH ( B × C × H B \times C \times H B×C×H)Y AvgPool(沿 H 压缩):得到 X W X_W XW ( B × C × W B \times C \times W B×C×W)
- 多语义分组 (Split): X H X_H XH 和 X W X_W XW 都在通道维度被等分为 4 组( K = 4 K=4 K=4),每组 C / 4 C/4 C/4 个通道。
- 多尺度卷积 (
MS-DWConv1d): 这是核心。这 4 组特征(H 和 W 上的)被并行送入 4 个不同核大小( k = 3 , 5 , 7 , 9 k=3, 5, 7, 9 k=3,5,7,9)的深度共享 1D 卷积中。这使得 4 组特征分别学习了 4 种不同尺度(即不同“语义”)的空间关系。 - 防干扰归一化 (
GroupNorm-4): 4 组处理完的 1D 特征被Concat(拼接)回 B × C × H B \times C \times H B×C×H (和 B × C × W B \times C \times W B×C×W)。然后使用GroupNorm(G=4) 进行归一化。这是关键设计:它确保了 4 组不同语义的特征在各自的组内被归一化,避免了它们之间的统计数据相互干扰。 - 注意力图生成: 归一化后的特征通过
Sigmoid生成两个 1D 的注意力图: A t t n H Attn_H AttnH ( B × C × H B \times C \times H B×C×H) 和 A t t n W Attn_W AttnW ( B × C × W B \times C \times W B×C×W)。 - 应用: 最终,这两个 1D 注意力图被广播(broadcast)并**逐元素相乘( ⊗ \otimes ⊗)**到原始的 3D 输入 X X X 上,得到 X s X_s Xs。
- 维度解耦 (Decoupling): 输入 X X X ( B × C × H × W B \times C \times H \times W B×C×H×W) 首先被解耦为两个 1D 特征序列:
-
对于 模块 B:PCSA (渐进式通道自注意力)
- 理念: 解决“语义差异”问题,并执行高效的通道注意力。
- 数据流:
- 输入: X s X_s Xs(来自 SMSA 的输出)。
- 分支 1:空间先验(Spatial Prior)生成:
- X s X_s Xs 经过一个 7 × 7 7 \times 7 7×7 的
AvgPool(渐进式压缩,保留了 H ′ × W ′ H' \times W' H′×W′ 的空间维度)和一个Sigmoid,生成一个空间权重图。
- X s X_s Xs 经过一个 7 × 7 7 \times 7 7×7 的
- 分支 2:通道自注意力 (CA-SHSA):
CA-SHSA(通道单头自注意力)模块被激活。- X s X_s Xs 被重塑(Reshape)并投影(
DWConv1d 1x1)为 Q , K , V Q, K, V Q,K,V。注意:这里的自注意力是在通道维度( C C C)上计算的( B × C × N ′ B \times C \times N' B×C×N′ → \rightarrow → C × C C \times C C×C 注意力图)。 - Q , K , V Q, K, V Q,K,V 经过
GroupNorm-1(即 LayerNorm)归一化。 - Q , K , V Q, K, V Q,K,V 执行**单头(Single-Head)**自注意力(
Matrix Mul→ \rightarrow →Softmax→ \rightarrow →Matrix Mul),得到 X a t t n X_{attn} Xattn。
- 融合:
- X a t t n X_{attn} Xattn(来自 CA-SHSA)与 X s X_s Xs(残差)相加( ⊕ \oplus ⊕)。
- 相加的结果,与分支 1 生成的“空间先验”图进行逐元素相乘( ⊗ \otimes ⊗)。
- 输出: 最终结果经过一个
AvgPool(压缩到 1 × 1 1 \times 1 1×1)和Sigmoid,生成一个 B × C × 1 × 1 B \times C \times 1 \times 1 B×C×1×1 的通道注意力向量,并将其乘回( ⊗ \otimes ⊗)到 X s X_s Xs 上,得到最终输出 X c X_c Xc。
- 设计目的: “渐进式压缩”保留了空间先验。“单头”自注意力强制来自 SMSA 的 4 组不同语义在 C × C C \times C C×C 的空间中交互,从而“缓解”了它们的差异。最后,PCSA 将空间先验(来自 Pool)和通道注意力(来自 CA-SHSA)协同地施加到特征图上。
-
-
理念与机制总结:
- SCSA 的协同作用 (Synergistic Effects):
- SMSA → \rightarrow → PCSA(指导):
SMSA首先从空间维度提取了**4 种不同尺度(语义)**的先验,并将这些“多语义”特征( X s X_s Xs)传递给PCSA。 - PCSA ← \leftarrow ← SMSA(融合/缓解):
PCSA接收到这 4 种混杂的语义特征。它通过通道维度的单头自注意力(CA-SHSA),强制这 4 组(总共 C C C 个)通道相互“对话”和比较。这使得模型能够理解这 4 种语义之间的关系(例如,知道“眼睛”和“鳍”都是“鲨鱼”的一部分),从而缓解(mitigate)了它们最初的语义差异,并将它们融合成一个统一的、更精炼的特征表示。
- 协同 = 空间指导 + 通道融合。
-
图解总结:
- Figure 1 揭示了问题:特征图包含**“多语义信息”(鲨鱼眼、鳍、身体),这导致了“语义差异”**。
- Figure 4(左侧) 证实了后果:现有的“单语义”注意力(如 CBAM, ECA)无法处理这种差异,导致注意力弥散。
- Figure 2(上半部分 SMSA) 提供了解决方案的第一步:设计
SMSA,通过 4 种不同大小的 1D 卷积核(k=3,5,7,9)来显式地提取这 4 种“多语义”空间特征,并使用GroupNorm-4来保护它们不相互干扰。 - Figure 2(下半部分 PCSA) 提供了解决方案的第二步:设计
PCSA,利用通道自注意力(CA-SHSA)作为一个“熔炉”,将SMSA传递过来的 4 种不同语义强制融合,缓解它们之间的差异。 - Figure 4(右侧 SCSA) 展示了最终结果:这种“先分离提取(SMSA),再引导融合(PCSA)”的协同策略,产生了比所有SOTA方法都更锐利、更精确的注意力图。
- Figure 3 则展示了 SCSA 作为一个即插即用的模块,可以被灵活地嵌入到各种标准 CNN 块(如
BasicBlock,Bottleneck)中。
5. 即插即用模块的作用
- 本文的核心创新 SCSA 是一个**即插即用(Plug-and-play)**的注意力模块。
- 作用: 它可以作为积木块(building block),无缝嵌入到现有的 CNN 架构(甚至 Transformer 架构)中,以替代标准的卷积块或注意力块。
- 适用场景:
- 1. 替换标准残差块(Figure 3): SCSA 可以直接替换 ResNet 中的
BasicBlock或Bottleneck块(图 3b, 3c),或 MobileNetV2 中的Inverted Residual Block(图 3a)。这能为这些经典骨干网络带来强大的多语义特征提取和融合能力。 - 2. 升级现有注意力模型: SCSA 可以替代现有的 SOTA 注意力模块,如
SENet,CBAM,ECA,CA等。如 Table 2 所示,在 ResNet-50 上,SCSA (77.49%) 比所有这些模块(77.05% ~ 77.43%)性能都强。 - 3. 混合 Transformer 架构: SCSA 甚至可以与 Swin Transformer 结合(如 Table 2 所示),在 Swin-T 基础上带来 0.7% 的显著提升,证明了其在 CNN 和 Transformer 架构中均具有良好的泛化性。
- 1. 替换标准残差块(Figure 3): SCSA 可以直接替换 ResNet 中的
- 具体应用:
- 高层视觉(分类、检测、分割): 如本文实验所示,在 ImageNet 分类、MSCOCO 检测和 ADE20K 分割任务上,SCSA 都能带来一致的性能提升。
- 复杂场景(小目标、低光照): SCSA 在 VisDrone(小目标)和 ExDark(低光照)等更具挑战性的数据集上也表现出色,证明了其强大的鲁棒性和泛化能力。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。
6. 获取即插即用代码关注 【AI即插即用】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)