OpenClaw 的工作原理是什么?怎么让 OpenClaw 更懂你?一文讲透它为什么突然爆火
最近 OpenClaw 很火。很多人第一次看到它,会以为它只是“把大模型接到微信/Telegram/Slack 上”的一个聊天机器人外壳。
但如果你认真看官方资料,就会发现:OpenClaw 本质上不是一个普通 Bot,而是一个运行在你自己设备或服务器上的个人 AI 助手网关。它的核心价值,不只是“能聊天”,而是把消息渠道、模型能力、工具调用、记忆系统、会话路由串成了一整套可长期运行的 Agent 体系。
官方当前把它定义为:你可以在自己的设备上运行 OpenClaw,它会接入你已经在使用的渠道,例如 WhatsApp、Telegram、Slack、Discord、Signal、iMessage、Feishu 等;Gateway 只是控制平面,真正的产品是那个“随时在线的个人助理”。同时,官方推荐的安装方式是直接使用 openclaw onboard 向导完成 Gateway、workspace、channels 和 skills 的初始化。
一、OpenClaw 到底是什么?
先用一句人话解释:
OpenClaw = 一个自托管的 AI Agent 运行底座 + 多聊天渠道入口 + 工具系统 + 可落盘记忆系统。OpenClaw - OpenClaw
它和普通 AI 聊天工具最大的区别在于:
-
它不是只活在一个网页里
你可以从 Telegram、Slack、Discord、Signal、iMessage 等多个入口给它发消息,这些入口最终都会汇总到同一个 Gateway。 -
它不只是回答问题,而是可以“执行”
官方文档里明确提到它有 browser、canvas、nodes、cron 等 first-class tools,也支持技能和插件扩展。也就是说,它的定位不是陪聊,而是“能调用工具去做事”的 Agent。 -
它有“上下文”和“记忆”两层机制
很多人把这两个词混着用,但 OpenClaw 官方专门区分了:-
Context:本轮发给模型的上下文窗口内容
-
Memory:写进磁盘、后续还能重新载入的记忆
这也是它和普通一次性对话产品差异很大的地方。
-
-
它强调 workspace 驱动
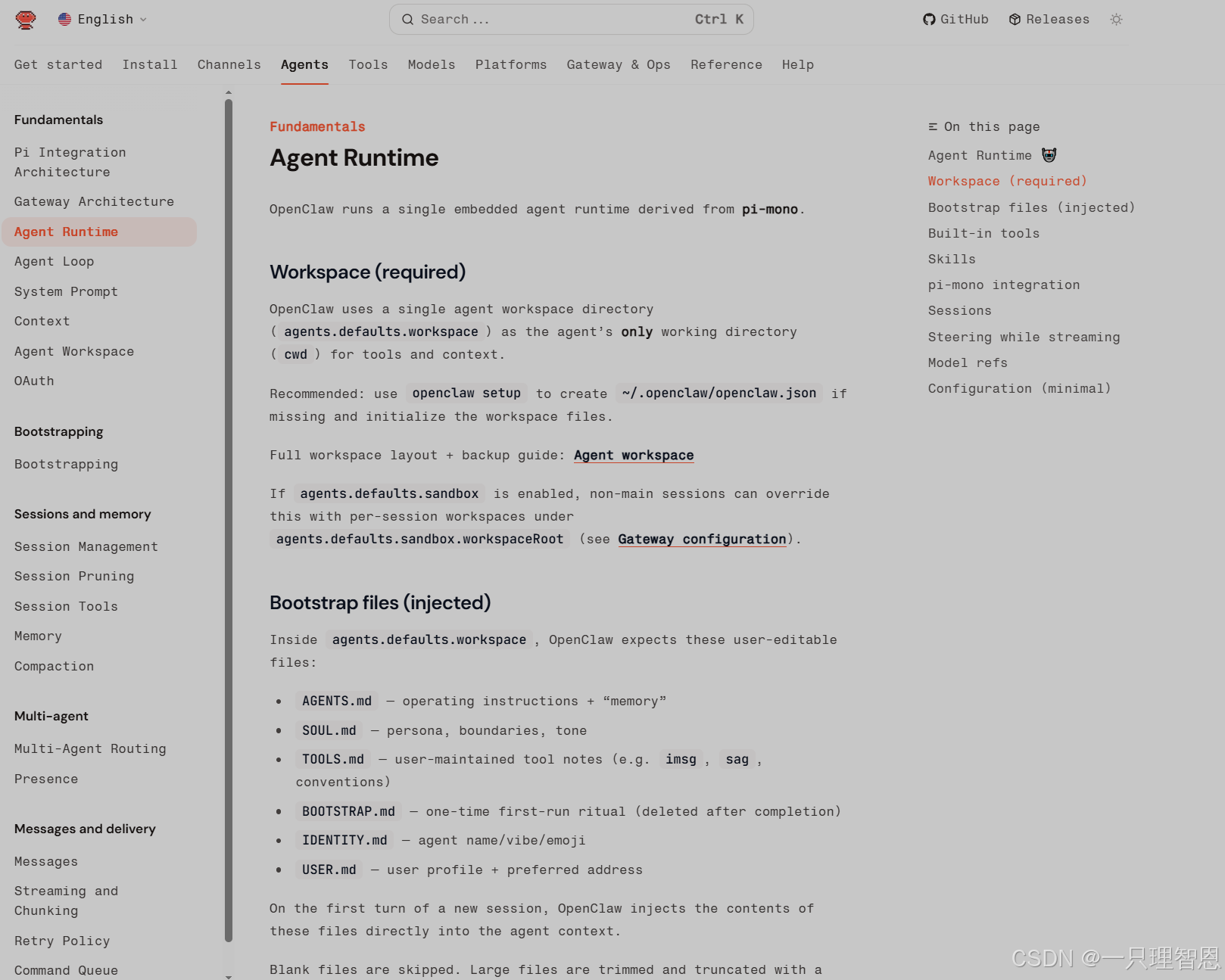
OpenClaw 会围绕一个工作目录运行,里面有AGENTS.md、SOUL.md、USER.md、TOOLS.md、MEMORY.md等文件,这些文件会影响它“是谁、怎么说话、怎么做事、你是谁、该记住什么”。
所以说,OpenClaw 不是一个套壳 AI 应用,而更像是一个可长期驯化、可持续运行、可多通道接入的个人 AI 助手操作系统。
二、OpenClaw 的工作原理,拆开看其实并不复杂
很多人觉得 Agent 很玄,其实 OpenClaw 的工作原理可以理解成下面这条链路:
消息入口 → Gateway 接收 → 会话/Agent 路由 → 组装上下文 → 调用模型 → 必要时调用工具 → 写入记忆/更新文件 → 返回结果到聊天渠道。
这个过程和官方文档里对 Gateway、Context、Memory、Workspace、Multi-Agent 的描述是对应的。
1)消息入口:你从哪里发消息,它就从哪里接
OpenClaw 支持多种聊天入口,像 Telegram、Slack、Discord、Signal、iMessage、Feishu 等都可以作为前端消息入口。
你在这些平台发一句话,本质上是把任务送到了 OpenClaw 的 Gateway。
这意味着一个很关键的能力:
你不需要专门打开某个 AI 页面,而是直接在原有工作流里唤起它。
比如:
-
在 Telegram 里让它查某个项目资料
-
在 Slack 里让它回复某个状态
-
在手机上直接给它发一句“整理一下我今天要做的事”
这就是为什么很多人第一次用 OpenClaw,会觉得它不像“用 AI”,更像“多了个随叫随到的数字助理”。
2)Gateway:真正的中枢,不是简单转发器
官方 README 说得很直接:Gateway is just the control plane — the product is the assistant.
也就是说,Gateway 不是单纯消息中转,而是整个系统的控制中心。它要负责:
-
管理会话
-
连接消息渠道
-
装载工具
-
注入工作区文件
-
管理事件和运行状态
-
路由到正确的 agent/session。
可以把它理解成:
-
聊天软件 = 输入输出层
-
大模型 = 推理引擎
-
工具系统 = 执行器
-
workspace/memory = 长期认知层
-
Gateway = 调度中台
所以 OpenClaw 的“强”,不是只因为接了一个大模型,而是它把这些层真正编排起来。
3)Context:它这一轮“看到”的全部内容
OpenClaw 官方对 Context 的定义非常清楚:
Context 是每次运行时真正发给模型的东西,它受模型上下文窗口限制。 里面通常包括:
-
OpenClaw 生成的系统提示
-
会话历史
-
工具调用结果
-
附件内容
-
workspace 中被注入的文件。
默认情况下,OpenClaw 会把一些 workspace 文件直接注入到上下文里,比如:AGENTS.md、SOUL.md、TOOLS.md、IDENTITY.md、USER.md、HEARTBEAT.md,新工作区首次运行时还可能有 BOOTSTRAP.md。
这一点特别关键,因为它解释了一个现象:
为什么有些人装完 OpenClaw 后,感觉它“很普通”;
而有些人却能把它调成“像自己的第二大脑”?
答案就是:
你给它注入了什么上下文,它就会以什么方式理解你。
如果这些文件是空的,它就只是一台会说话的模型;
如果这些文件写得清楚,它就会更像一个持续懂你习惯的助理。Context - OpenClaw
4)Memory:不是“它记住了”,而是“它写下来了”
这是 OpenClaw 很有代表性的设计思想。
官方文档强调:
Memory 的源事实体是磁盘上的 Markdown 文件,不是模型脑子里的短暂记忆。模型只有在内容被写到磁盘后,后续才算真正“记住”。
默认 memory 分两层:
-
memory/YYYY-MM-DD.md:每天的日记式记录,偏运行过程、当日上下文 -
MEMORY.md:长期记忆,偏稳定偏好、长期事实、重要决策。
官方还特别说了一句很重要的话:
如果你真想让某件事被记住,就让它写进 memory,不要指望“心里记一下”。
这其实就是 OpenClaw 和很多聊天 AI 最大的分野:
-
普通聊天 AI:聊完就散,记忆模糊且不可见
-
OpenClaw:记忆是文件,能看、能改、能沉淀、能迁移
对于开发者来说,这种设计有两个巨大好处:
-
可审计:你知道它记住了什么
-
可调教:你可以手动修改它的长期认知
这就是为什么我会说,OpenClaw 更像一个“可驯化”的 Agent。
5)Workspace 文件:它真正“懂你”的秘密
OpenClaw 的很多能力,并不是来自大模型本身,而是来自你给它的这套 workspace 文件。
SOUL.md
定义它的气质、边界、表达方式。
官方模板里很明确地写到:要真正有帮助,少说客套话;要有观点;先自己想办法,不要上来就追问。
USER.md
记录“你的信息”。包括怎么称呼你、你的时区、你关心什么、你在做什么项目、你不喜欢什么。官方模板还特别提醒:这是为了更好帮助一个人,而不是建立一个令人不适的档案。
TOOLS.md
记录工具使用习惯、环境约定、命令速查、你自己的基础设施说明。官方对它的描述很直白:这是你的 cheat sheet。
AGENTS.md
更像总操作手册,告诉它在这个工作区里应该怎么工作、如何启动、如何写记忆、遇到群聊时怎么克制、什么时候该主动。官方模板甚至明确写了:每次新 session 先读 SOUL.md、USER.md、今天/昨天的 memory,在 main session 下再读 MEMORY.md。
IDENTITY.md
定义这个 Agent 叫什么、什么风格、什么 vibe。它不直接提升推理能力,但会提升一致性和可用感。
所以从机制上说,OpenClaw 更懂你,不靠玄学,靠的是“文件化人格 + 文件化用户画像 + 文件化长期记忆 + 文件化操作规范”。
三、OpenClaw 为什么最近这么火?
从官方公开材料和当前社区生态看,OpenClaw 热起来,不只是因为“它开源”,而是因为它正好踩中了 2026 年 Agent 热潮里最实际的几个点。
原因 1:它解决了“AI 只能在网页里”的割裂感
很多 AI 产品的问题在于:
你明明每天在微信、Telegram、Slack、手机消息里工作,却要为了 AI 单独打开一个网页或 IDE 插件。
OpenClaw 反过来做:
你在原来的沟通入口里发消息,它来接入你的世界。
原因 2:它把“记忆”做成可见、可编辑、可继承
这比“号称有记忆”靠谱得多。
文件就是记忆,workspace 就是人格和操作手册,这种设计对开发者、极客、自动化用户很有吸引力。
原因 3:它更像 Agent,而不是问答机器人
官方已经明确把 browser、canvas、nodes、cron 等能力做成 first-class tools,还支持技能和多 Agent 路由。
这意味着 OpenClaw 的目标从一开始就不是“把 AI 放到聊天框里”,而是“让 AI 在聊天入口里持续执行任务”。
原因 4:它强调 self-hosted 和 own-your-data
OpenClaw 官方首页和 README 都强调 self-hosted、runs on your hardware、your rules 这类定位。
如今大家越来越在意数据可控、长期可迁移、避免平台锁定的背景下,这种定位天然更容易引发关注。
四、怎么使用,才能让 OpenClaw 更懂你?
实战重点。
很多人以为“更懂你”靠的是疯狂聊天。
其实不是。
OpenClaw 更懂你,核心靠结构化喂养,而不是随缘闲聊。
下面是最有效的几种方法。
方法 1:先把 USER.md 写清楚,而不是靠它猜
你可以把 USER.md 理解成“给 Agent 的用户说明书”。
建议至少写这几类内容:
Name: 李四
What to call them: 四哥
Timezone: Asia/Tokyo
Notes:
- 做技术内容创作,偏 AI Agent、技术、AI、工具
- 喜欢中文输出,风格要清晰、能落地、少空话
- 写文章时更偏 新闻 风格:标题明确、结构清楚、实操导向
- 不喜欢太泛的回答,更喜欢有步骤、有原理、有建议为什么这一步很重要?
因为官方明确说明 USER.md 会作为用户资料在新 session 初始时注入上下文。它不是“备忘录”,而是直接影响 Agent 如何理解你。
方法 2:把长期偏好写进 MEMORY.md
很多人每次都重复说:
-
我喜欢中文
-
文章别写太学术
-
代码注释要多一点
-
回答要偏实操
-
我做的是某个行业
-
默认按某个平台方案来
这些都不该每次重说。
OpenClaw 官方建议把决策、偏好、稳定事实写进 MEMORY.md。
比如你可以这样写:
# MEMORY.md
## 输出偏好
- 默认用中文回答
- 优先给可执行方案,不要只讲概念
- 写技术时尽量兼顾原理 + 实操 + 总结
- 给教程时适合小白,步骤要完整
## 用户长期方向
- 正在关注 OpenClaw、AI Agent、人工智能、无人机、WebGIS
- 经常需要写文章、做方案、整理面向甲方的材料
## 协作习惯
- 先给结论,再展开原因和步骤
- 遇到方案对比时,要明确优缺点和适用场景这样做的意义是:
OpenClaw 下次再工作时,不是“重新认识你”,而是“在已有认知基础上继续帮你”。
方法 3:把“怎么做事”写进 AGENTS.md
如果 USER.md 解决的是“你是谁”,
那 AGENTS.md 解决的就是“它应该怎么服务你”。
可以写:
# AGENTS.md
## 工作原则
- 优先给直接可执行结果
- 少说空泛客套话
- 文章输出要有标题、小节、总结
- 遇到教程类需求,默认按小白可操作方式组织
## 文章类任务
- 标题要能抓人
- 先解释是什么,再讲为什么,再讲怎么做
- 适合发表文章,兼顾传播性和技术含量
## 技术方案类任务
- 先给架构图思路
- 再拆功能模块
- 最后给周期、成本、注意事项官方模板本身就强调 AGENTS.md 是工作区的操作手册,而且每次 session 启动都应该优先读取。AGENTS.md Template - OpenClaw
这意味着:
你越明确告诉它“怎么帮你”,它越像一个训练好的助理;你不写,它就只能临场猜。
方法 4:把工具环境和命令习惯写进 TOOLS.md
如果你平时有固定环境,比如:
-
项目目录在哪
-
常用命令是什么
-
服务器怎么连
-
哪些脚本能跑,哪些不能碰
-
输出表格时用什么格式
-
你常用的部署方式是什么
那就不要指望它每次问你。
直接写进 TOOLS.md。官方也把它定位为用户自己的工具速查和环境说明。
例如:
# TOOLS.md
## 常用约定
- 默认输出 markdown
- 脚本优先给 Windows PowerShell + macOS shell 两版
- 文件路径尽量写绝对路径
- 讲部署方案时优先考虑小白可执行性
## 项目习惯
- 前端默认 React + TS
- 服务端默认 Go / Python
- 本地模型优先考虑 Ollama这会显著减少它的误判成本。
方法 5:遇到“记住这个”,真的让它写下来
这是最容易忽略、但最有效的一步。
官方文档说得非常直接:
如果有人说“remember this”,就把它写进对应 memory 文件,不要只存在 RAM 里。
所以你在用 OpenClaw 时,别只是说:
以后按这个风格来
而要说:
把这个写进 MEMORY.md,以后写文章默认按这个风格输出。
这两个效果完全不一样。
前者只是一次提示;
后者才是长期训练。
方法 6:控制上下文长度,别把它喂成一锅粥
官方明确提到,Context 是受模型上下文窗口限制的;文件太大时会被裁剪、截断。还提供了 /context list、/context detail、/status、/usage 这类命令来查看上下文和 token 使用情况。
所以让 OpenClaw 更懂你,不是无限堆资料,而是要做两件事:
-
长期稳定内容放进
MEMORY.md -
当前任务内容放进当天
memory/YYYY-MM-DD.md或当前会话
这样它既不会失忆,也不会被垃圾上下文稀释。
方法 7:给它明确角色边界,尤其是多群聊场景
官方默认对 Telegram、WhatsApp、Signal、iMessage、Slack、Discord 等 DM 做了 pairing 和 allowlist 等安全策略;安全文档也提醒,如果多个不可信用户共享一个 tool-enabled agent,隐私隔离不等于权限隔离。
这意味着什么?
如果你在多个群、多个团队、多个渠道都让同一个 OpenClaw 工作,最好做到:
-
私人 Agent 负责个人事务
-
工作 Agent 负责团队事务
-
不同边界最好拆不同 agent/workspace
官方的 Multi-Agent 文档也明确说,一个 agent 是完整隔离的一套 brain,拥有自己的 workspace、状态目录和 session store。
所以“让它更懂你”的前提,是先别让它人格混乱。
五、我建议的新手使用方式:别一上来就折腾高级功能
如果你刚开始用 OpenClaw,我建议按照这个顺序:
第一步:先跑通官方向导
官方当前最推荐的方式就是:
npm install -g openclaw@latest
openclaw onboard --install-daemonREADME 里明确写了 onboarding wizard 是推荐路径,会一步步带你设置 gateway、workspace、channels 和 skills。
第二步:先只接一个聊天入口
比如先接 feishu 或你最常用的一个入口。
不要一开始全接满,不然定位问题会很乱。官方 CLI 也说明了,当配置多个 channel 时,消息发送需要明确指定 channel。
第三步:先把 workspace 文件养好
个人认为这比花时间挑模型还重要。
OpenClaw 官方当然支持多模型/多认证方式,但 README 里也提醒:为了更好的体验和更低的 prompt injection 风险,优先使用更强的新一代模型。
但模型强,不等于它就天然懂你。
真正决定“像不像你的助理”的,还是前面说的那些文件:USER.md、MEMORY.md、AGENTS.md、TOOLS.md。
第四步:让它从一个固定场景开始
比如只让它做其中一种:
-
帮你写小说
-
帮你整理待办
-
帮你处理某个项目资料
-
帮你做日常自动化提醒
不要一开始就希望它“无所不能”。
OpenClaw 适合的是从单一高频场景起步,再逐步把记忆和流程养出来。这个路径更稳。这个结论属于基于官方机制做出的使用建议。Memory - OpenClaw
六、OpenClaw 的优势和局限,也要看清楚
优势
1. 数据更可控
自托管、workspace 可见、记忆可落盘。
2. 更适合长期驯化
通过 USER.md、MEMORY.md、AGENTS.md 等文件长期塑形。
3. 多渠道接入很实用
你在哪说话,它就在哪服务。
4. 不是只会答题,而是能调工具做事
browser、canvas、nodes、cron、skills 都是为了执行而不是纯聊天。
局限
1. 上手门槛比普通聊天产品高
你要理解 Gateway、workspace、channel、memory、agent 这些概念。
2. 不写 workspace 文件,就很难体现它真正价值
装好了不等于用好了。这个结论是基于其官方上下文注入和 memory 机制推导出来的。
3. 多渠道、多工具意味着也要更重视安全边界
官方安全文档已经提醒了共享 agent、群聊、DM 策略等风险。openclaw/openclaw: Your own personal AI assistant. Any OS. Any Platform. The lobster way. 🦞
七、我的结论:OpenClaw 真正厉害的,不是“能接大模型”,而是“能被你养成一个助理”
如果只把 OpenClaw 当成一个聊天机器人,你会觉得它也就那样。
但如果你理解它的工作原理,就会发现它真正有意思的地方在于:
-
它有统一的消息入口
-
有 Gateway 作为调度中枢
-
有上下文注入机制
-
有文件化记忆
-
有 workspace 驱动人格和操作逻辑
-
有多 Agent 隔离和工具执行能力。
所以,OpenClaw 更像什么?
它更像一个你可以持续训练、持续修正、持续积累经验的“个人 AI 员工”。
而“让 OpenClaw 更懂你”的答案也并不复杂:
不要只跟它聊天,要给它写说明书、写记忆、写规则、写工具环境。
你给它的结构越清楚,它就越不像随机 AI,越像真正长期协作的数字助理。
这一点,恰恰是 OpenClaw 最值得玩、也最值得深入研究的地方。Agent Runtime - OpenClaw
结尾
真正让 OpenClaw 懂你的,从来不是多聊几句,而是你有没有把自己的习惯、规则、偏好和记忆,系统地交给它。
如果文章对你有帮助请点点赞,感谢

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)