【YOLOv10 目标检测使用详细基础教程】——数据集制作+模型训练+部署rk3588
(一)YOLOv10-main项目工程获取
去GitHub下载开源项目工程,直达链接:GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection [NeurIPS 2024] · GitHub
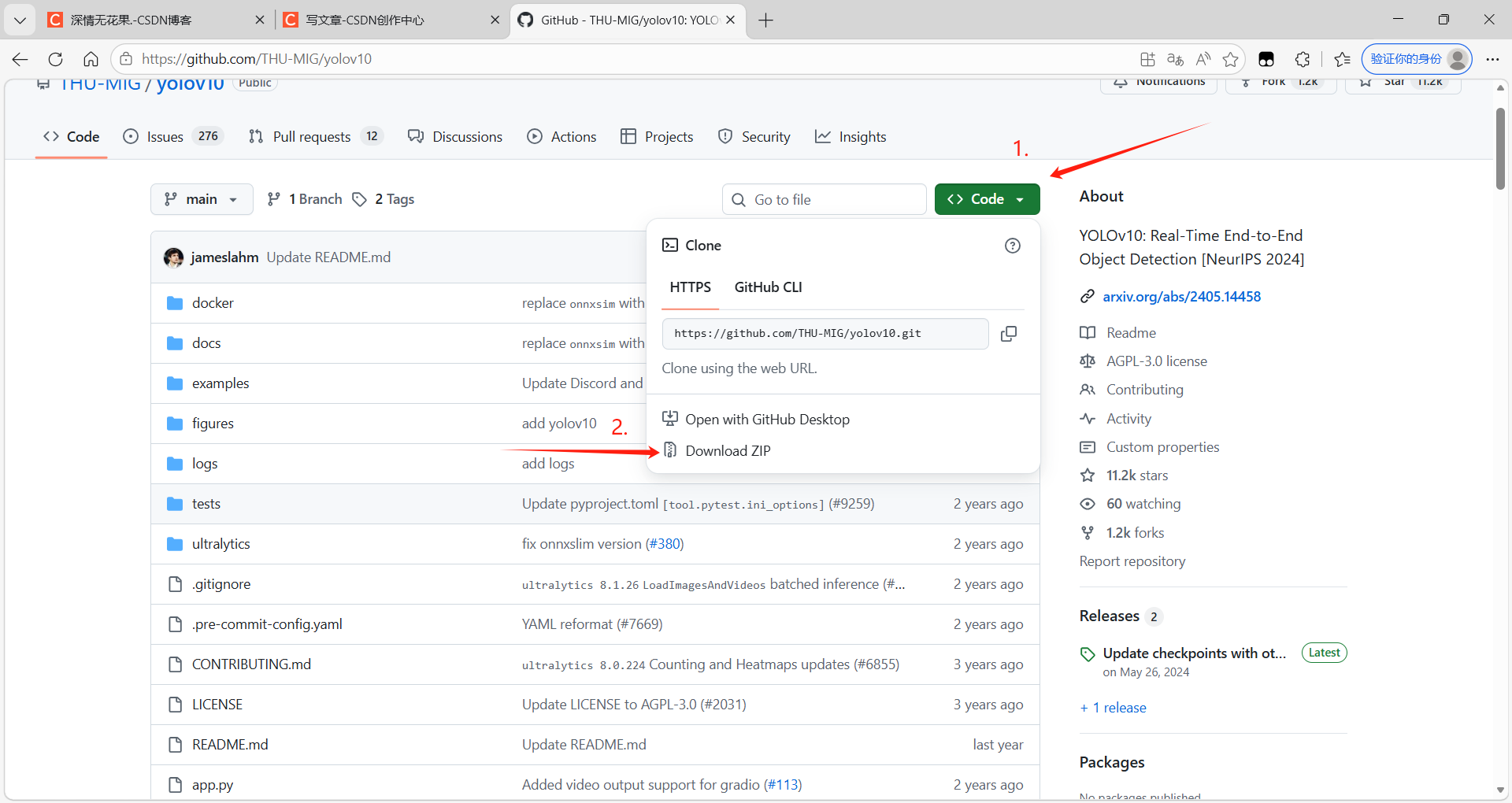
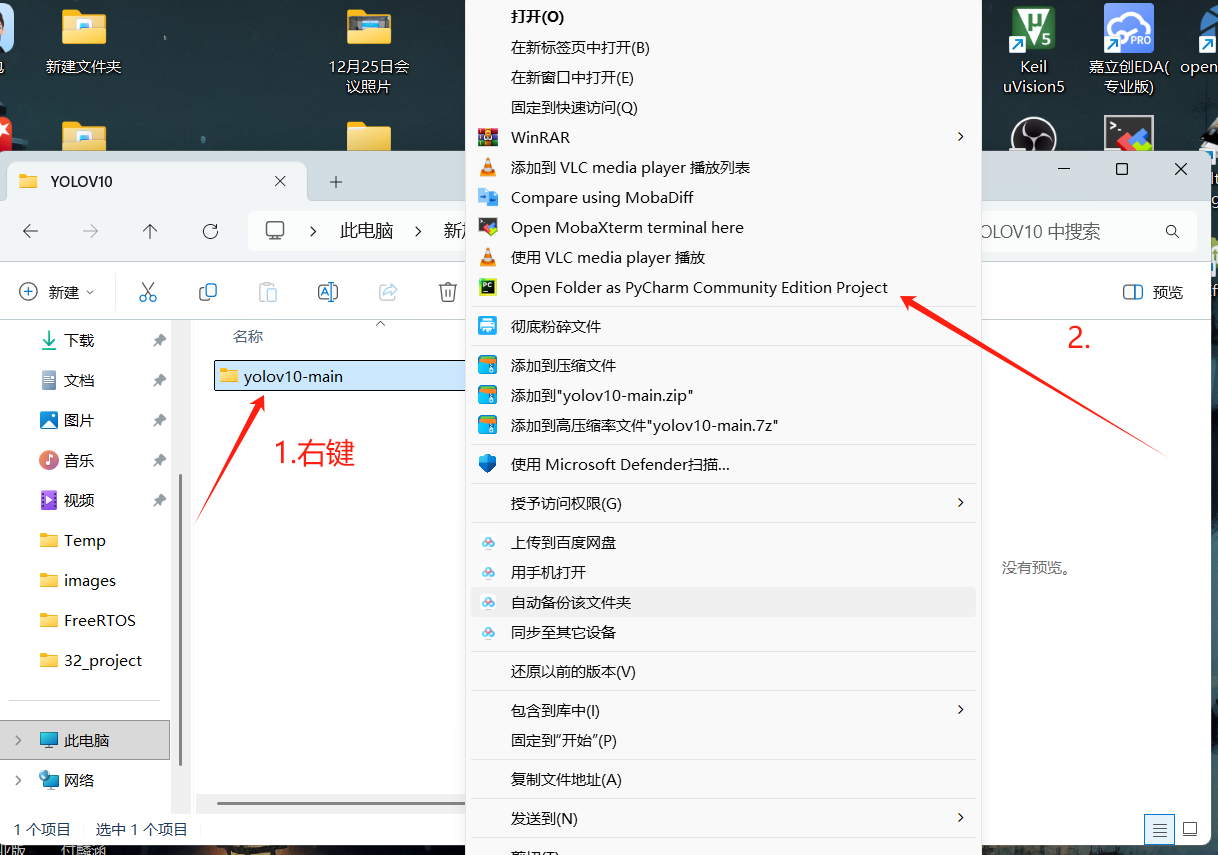
因为Github是国外的网站,网页会很卡,有条件可上tizi,也可以用加速器,下载完解压到电脑,右键使用pycharm打开整个工程
(二)conda环境搭建
1.创建yolov10环境
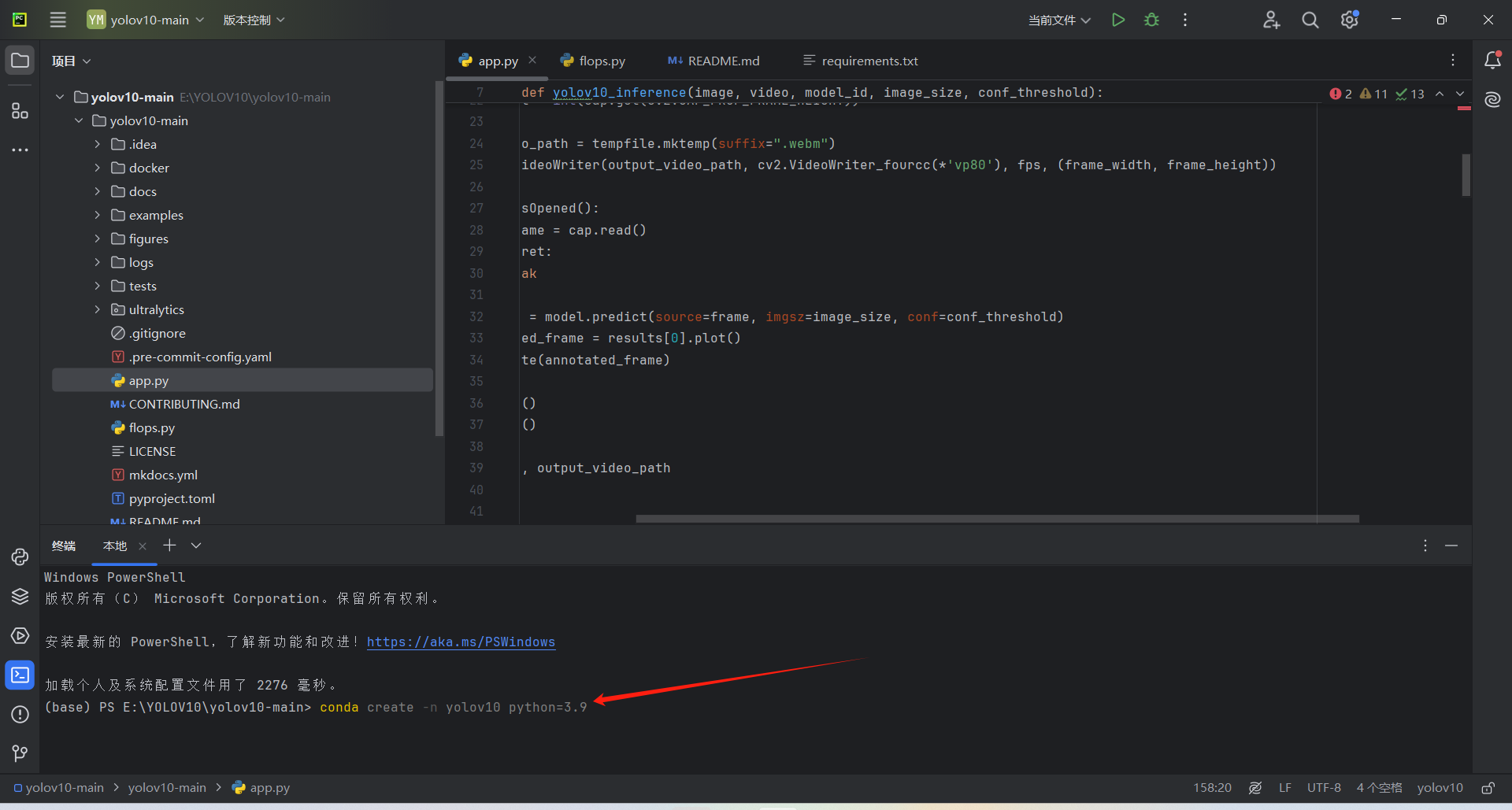
conda create -n yolov10 python=3.9
在终端输入以上命令,回车
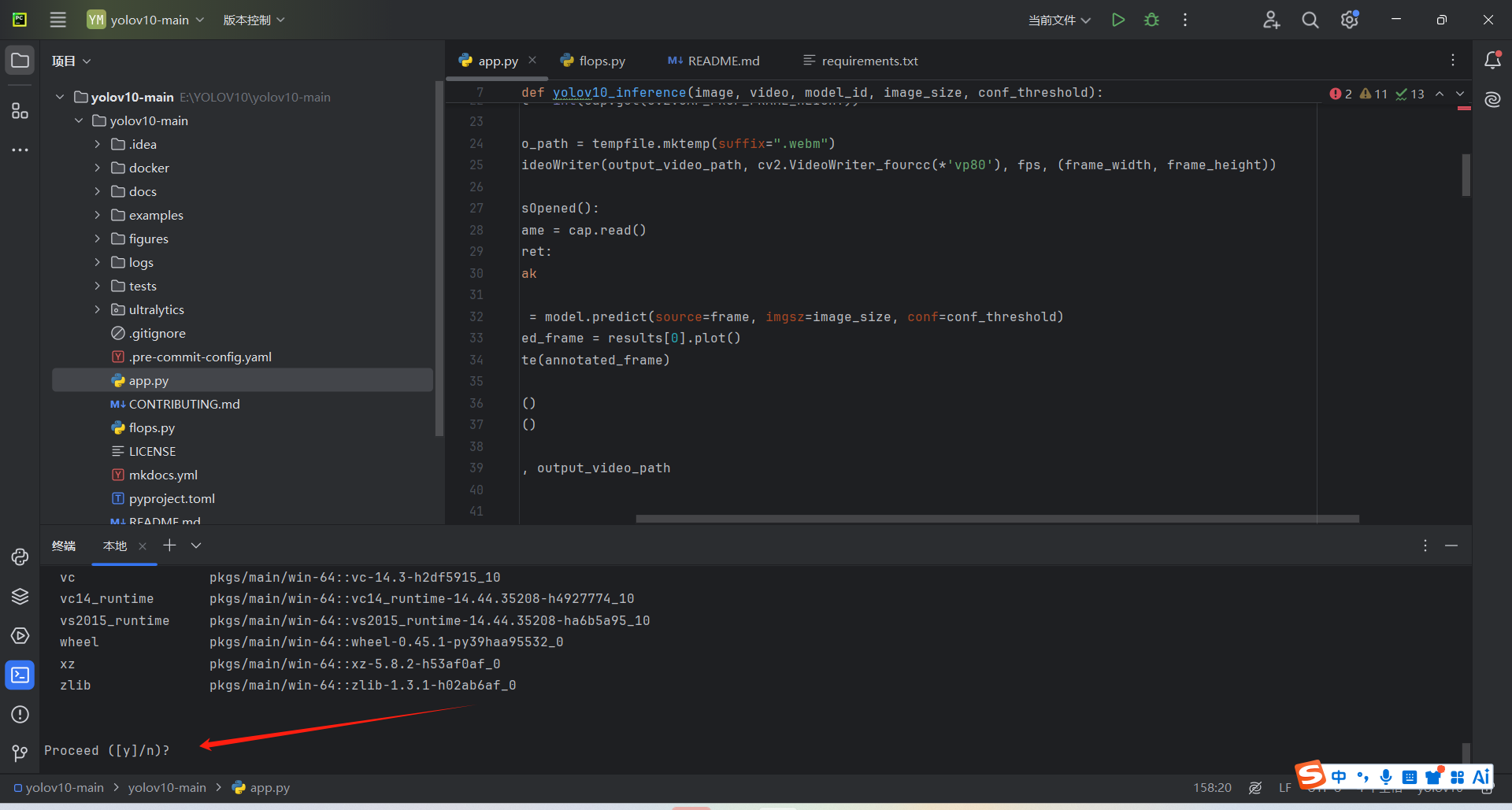
根据指引输入y
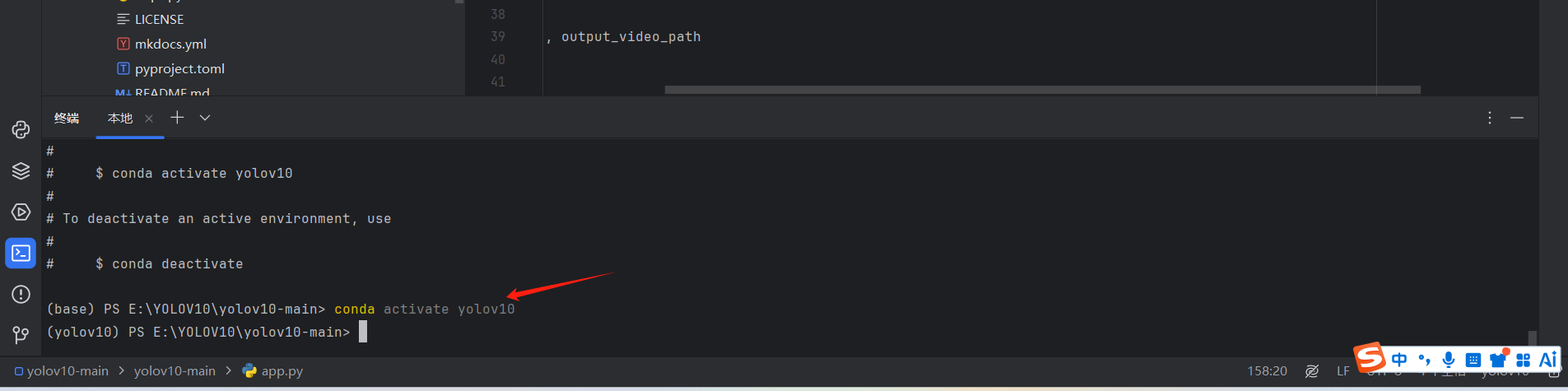
创建完成后输入以下指令激活环境,当出现(yolov10)则说明创建并激活成功
conda activate yolov10
2.安装所需软件包
执行以下命令安装软件包
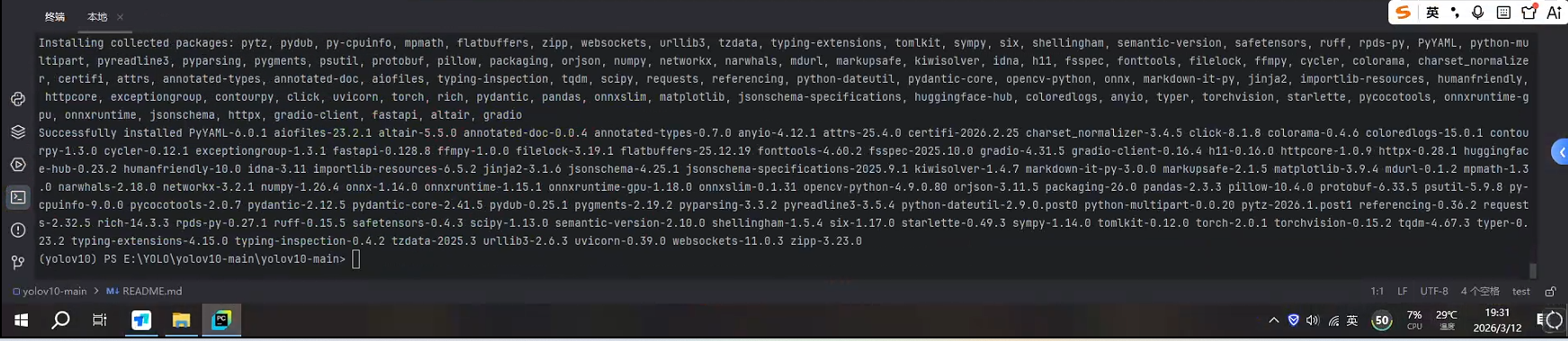
pip install -r requirements.txt
pip install -e .
等待所需软件包下载完成
(三)数据集制作
1.创建datasets文件夹
创建datasets文件夹于yolov10的根目录下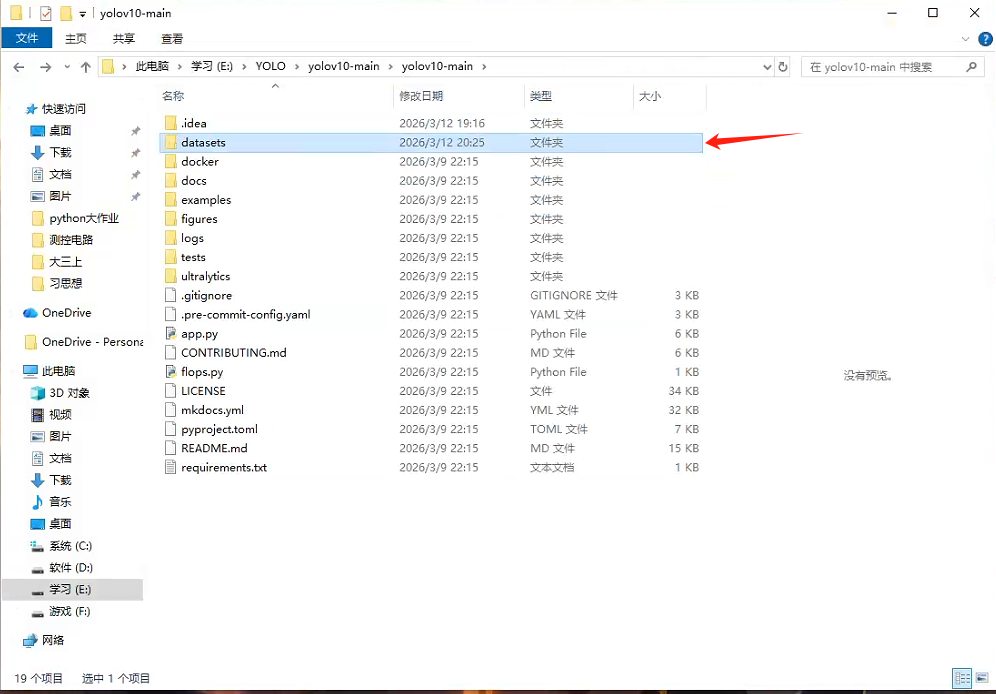
文件结构为:
--datasets
--E-bike(文件的命名根据自己情况写项目名称,我训练对象只有电动车所以写E-bike)
--images:存放图片
--train:训练集图片
--val: 验证集图片
--labels:存放标签
--train:训练集标签文件,要与训练集图片名称一一对应
--val:验证集标签文件,要与验证集图片名称一一对应
--classes.txt(可以没有):这个文件是标注的类型文件
2.搜集训练所需图片
一般来说,训练集与验证集的数据比例是8:2,即如果有100张图片,那么80张作为训练集放在,20张作为验证集,一般普通场景的数据集图片要训练1000张以上准确率才比较可观,我这里为了方便理解只在网上找了100张图片,把数据集的图片按照train_ebike_001.jpg 至 train_ebike_080.jpg(放入images/train),val_ebike_001.jpg 至 val_ebike_020.jpg(放入images/val)的命名来训练
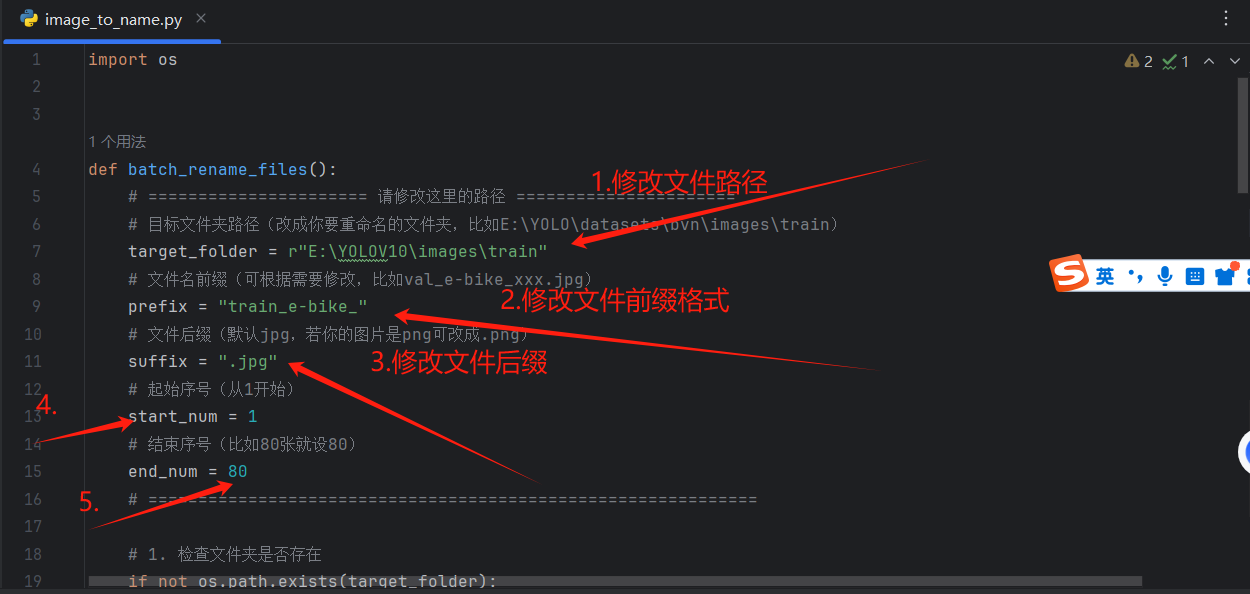
附:批量命名.py文件
import os
def batch_rename_files():
# ====================== 请修改这里的路径 ======================
# 目标文件夹路径(改成你要重命名的文件夹,比如E:\YOLO\datasets\bvn\images\train)
target_folder = r"E:\YOLOV10\images\train"
# 文件名前缀(可根据需要修改,比如val_ebike_xxx.jpg)
prefix = "train_e-bike_"
# 文件后缀(默认jpg,若你的图片是png可改成.png)
suffix = ".jpg"
# 起始序号(从1开始)
start_num = 1
# 结束序号(比如80张就设80)
end_num = 80
# =============================================================
# 1. 检查文件夹是否存在
if not os.path.exists(target_folder):
print(f"错误:文件夹 {target_folder} 不存在!")
return
# 2. 获取文件夹内的所有文件,筛选出图片文件(仅处理jpg/jpeg/png)
image_extensions = ('.jpg', '.jpeg', '.png')
files = [f for f in os.listdir(target_folder)
if os.path.isfile(os.path.join(target_folder, f))
and f.lower().endswith(image_extensions)]
# 检查文件数量是否匹配
file_count = len(files)
if file_count != end_num - start_num + 1:
print(
f"警告:文件夹内有 {file_count} 张图片,但你设置的序号范围是 {start_num}-{end_num}(共{end_num - start_num + 1}个)!")
confirm = input("是否继续重命名(剩余/超出文件会被跳过)?(y/n):")
if confirm.lower() != 'y':
return
# 3. 按原文件名排序(避免乱序,若想按修改时间排序可注释这行)
files.sort()
# 4. 批量重命名
rename_count = 0
for i, old_filename in enumerate(files):
# 计算当前序号,超过end_num则停止
current_num = start_num + i
if current_num > end_num:
print(f"已达到结束序号 {end_num},停止重命名")
break
# 生成新文件名(补零成3位,比如1→001,10→010)
new_filename = f"{prefix}{current_num:03d}{suffix}"
old_path = os.path.join(target_folder, old_filename)
new_path = os.path.join(target_folder, new_filename)
# 避免覆盖已有文件
if os.path.exists(new_path):
print(f"跳过:{new_filename} 已存在,避免覆盖")
continue
# 执行重命名
try:
os.rename(old_path, new_path)
print(f"成功:{old_filename} → {new_filename}")
rename_count += 1
except Exception as e:
print(f"失败:{old_filename} 重命名出错 → {e}")
# 5. 输出结果
print(f"\n重命名完成!共处理 {rename_count} 个文件")
if __name__ == "__main__":
# 重要提示:运行前建议备份文件夹内的文件!
print("⚠️ 重要提醒:运行前请先备份目标文件夹内的所有文件,避免误操作!")
confirm = input("确认要执行重命名吗?(y/n):")
if confirm.lower() == 'y':
batch_rename_files()
else:
print("已取消重命名操作")
修改相关参数,运行py文件
3. 打标签labelimg工具安装
在第二步中创建的yolov10环境中安装lebelimg标注软件,用于制作自己的数据集
conda activate yolov10
pip install labelimg
安装完成之后输入命令labelimg打开软件
labelimg
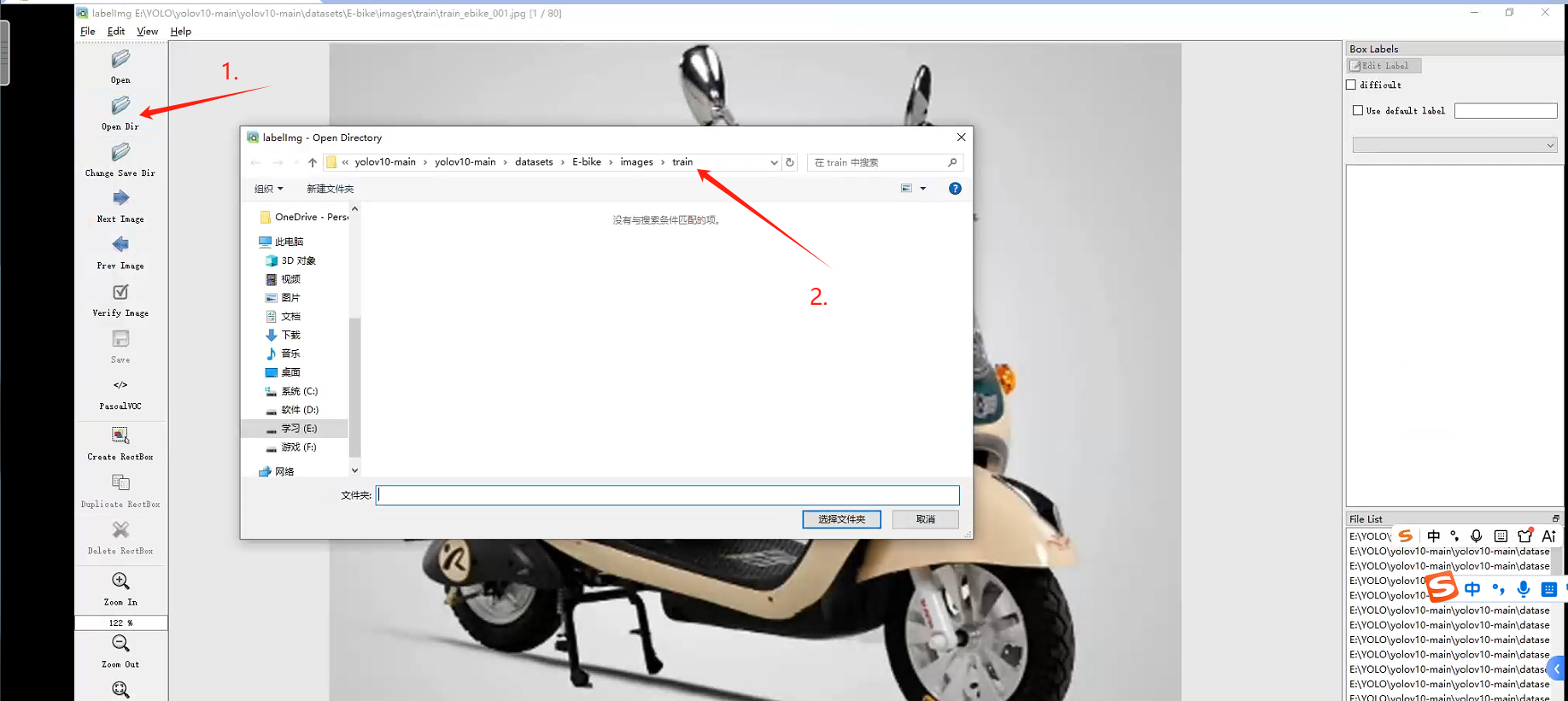
首先点击open dir选择打开上面创建的images/train文件
然后点击Change save dir为其选择对应存放标签的文件,用于存放打的标签信息
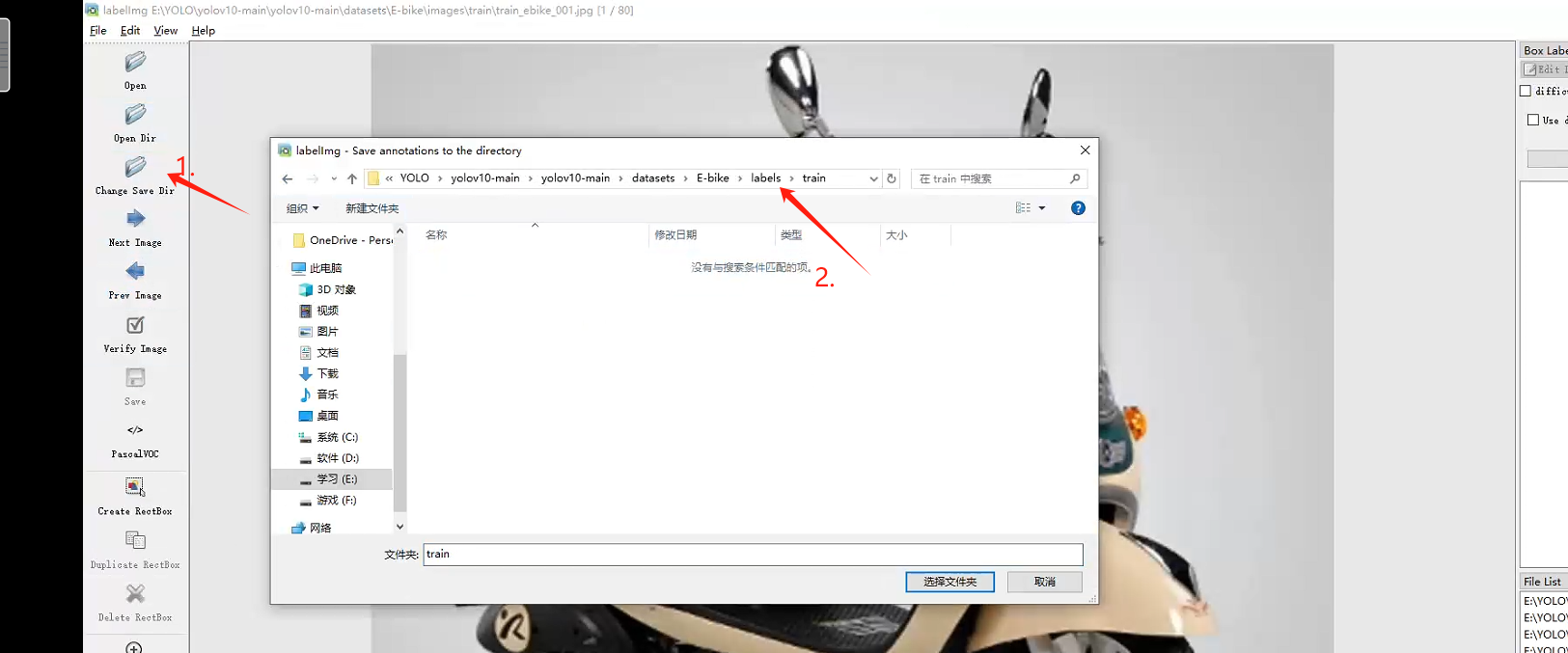
设置标注完文件自动保存:工具栏 view-auto save mode
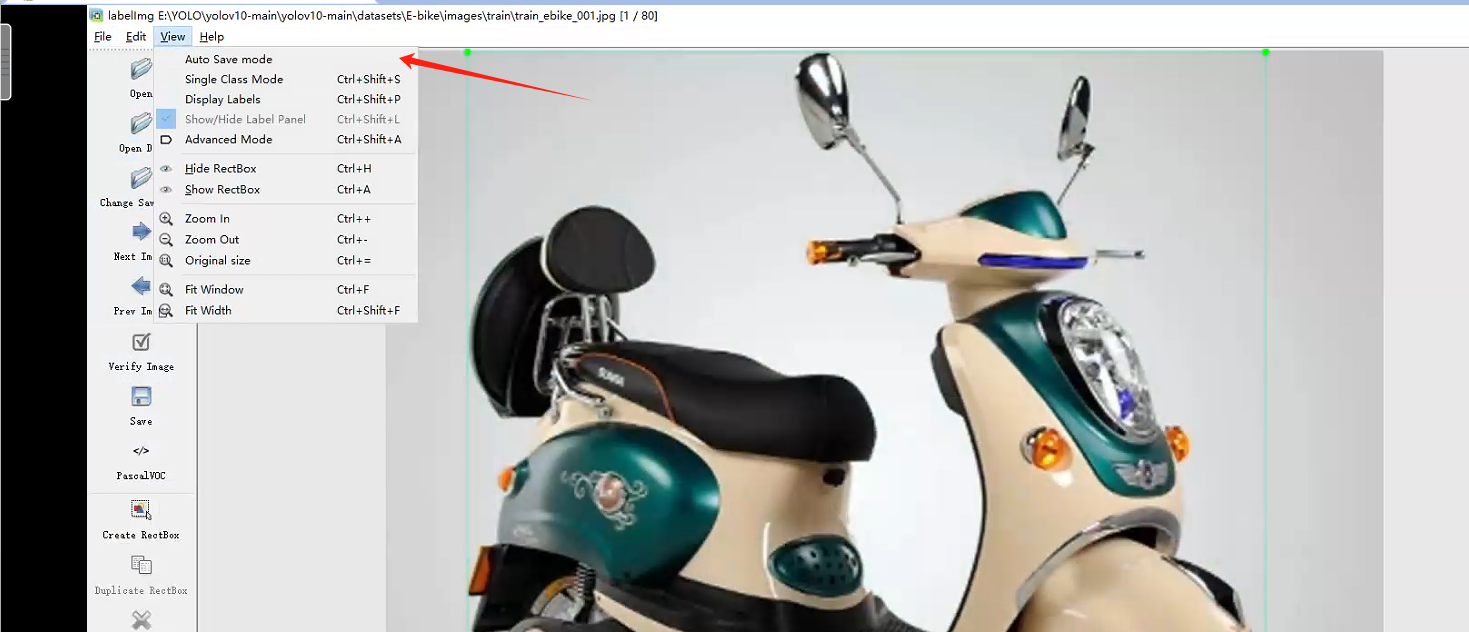
然后点击PasoalVOC使其转换为YOLO模式,最后点击SAVE保存修改
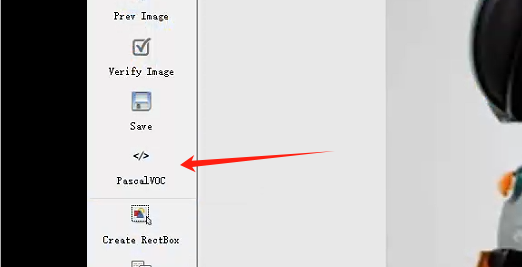

开始标注图片,点击Create Rectbox(快捷方式为键盘的 W),框选要训练识别的部分,在弹出的对话框中输入标签名字,点击OK,完成之后点击Nextra Image,开始标注下一张图片(快捷方式为键盘的 D),依次标注完成,然后会在此前设置好的保存目录中得到标注信息.

train图片标注完成之后,同理打开val验证集文件进行标注,同理标签文件保存在labels/val中……
注:yolov10标注完成后的.txt数据文件中,每一行的数据格式为: 类型 x中心坐标 y中心坐标 宽度 高度
4.整理数据集datasets文件
打完标签之后检查自己的数据严格按照以下格式存放文件
--datasets
--E-bike(文件的命名根据自己情况写项目名称,我训练对象只有电动车所以写E-bike)
--images:存放图片
--train:训练集图片
--val: 验证集图片
--labels:存放标签
--train:训练集标签文件,要与训练集图片名称一一对应
--val:验证集标签文件,要与验证集图片名称一一对应
--classes.txt(可以没有):这个文件是标注的类型文件
(四)开启训练
1.配置文件
在yolov10-main根目录下创建一个.yaml配置文件
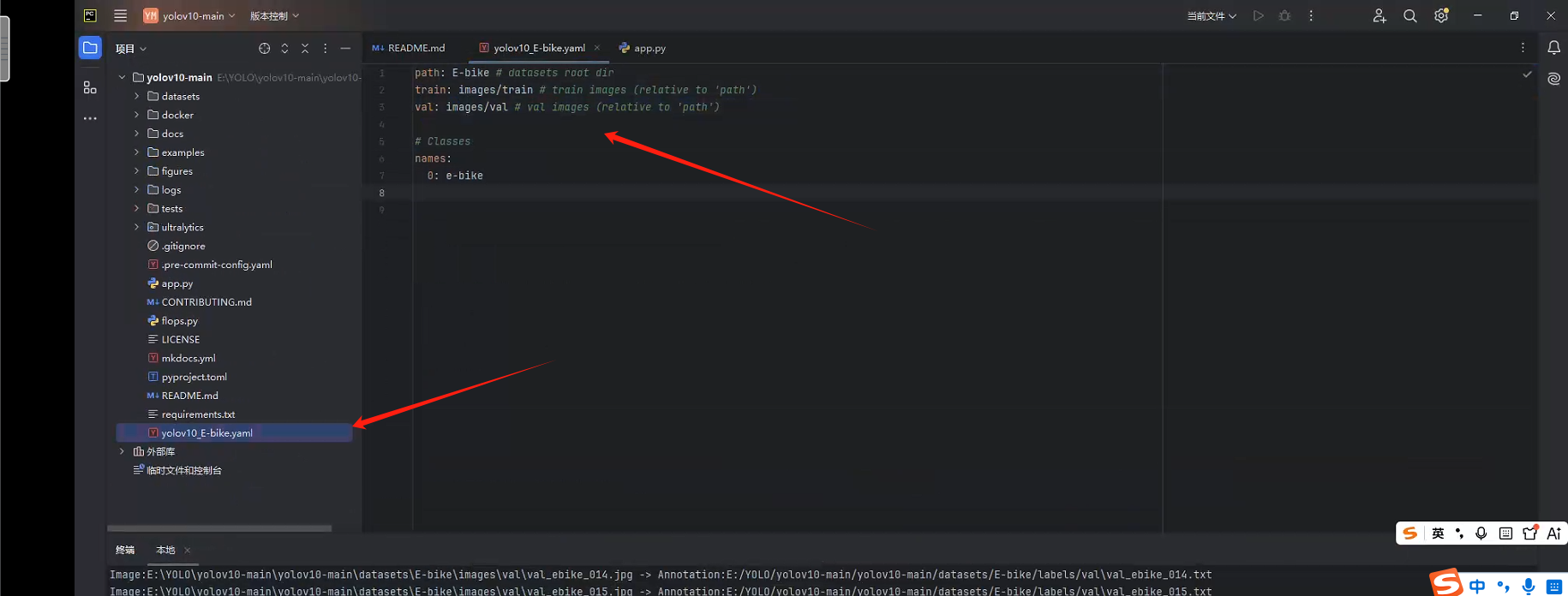
yolov10_E-bike.yaml
path: E-bike # datasets root dir train: images/train # train images (relative to 'path') val: images/val # val images (relative to 'path') # Classes names: 0: e-bike
注:path为从datasets目录开始算的根文件夹名称
train与val为训练集与验证集的位置
names这里就是分类标签,可以按照标注后生成的calsses.txt文件填
2.启动训练
(1)方式一:使用cpu训练
这是当电脑没有独立显卡时,只能使用cpu训练,但训练的效果不佳,不太推荐
运行命令
yolo detect train data=yolov10-E-bike.yaml model=yolov10n.pt epochs=100 batch=1 imgsz=640 device=cpu cache=False
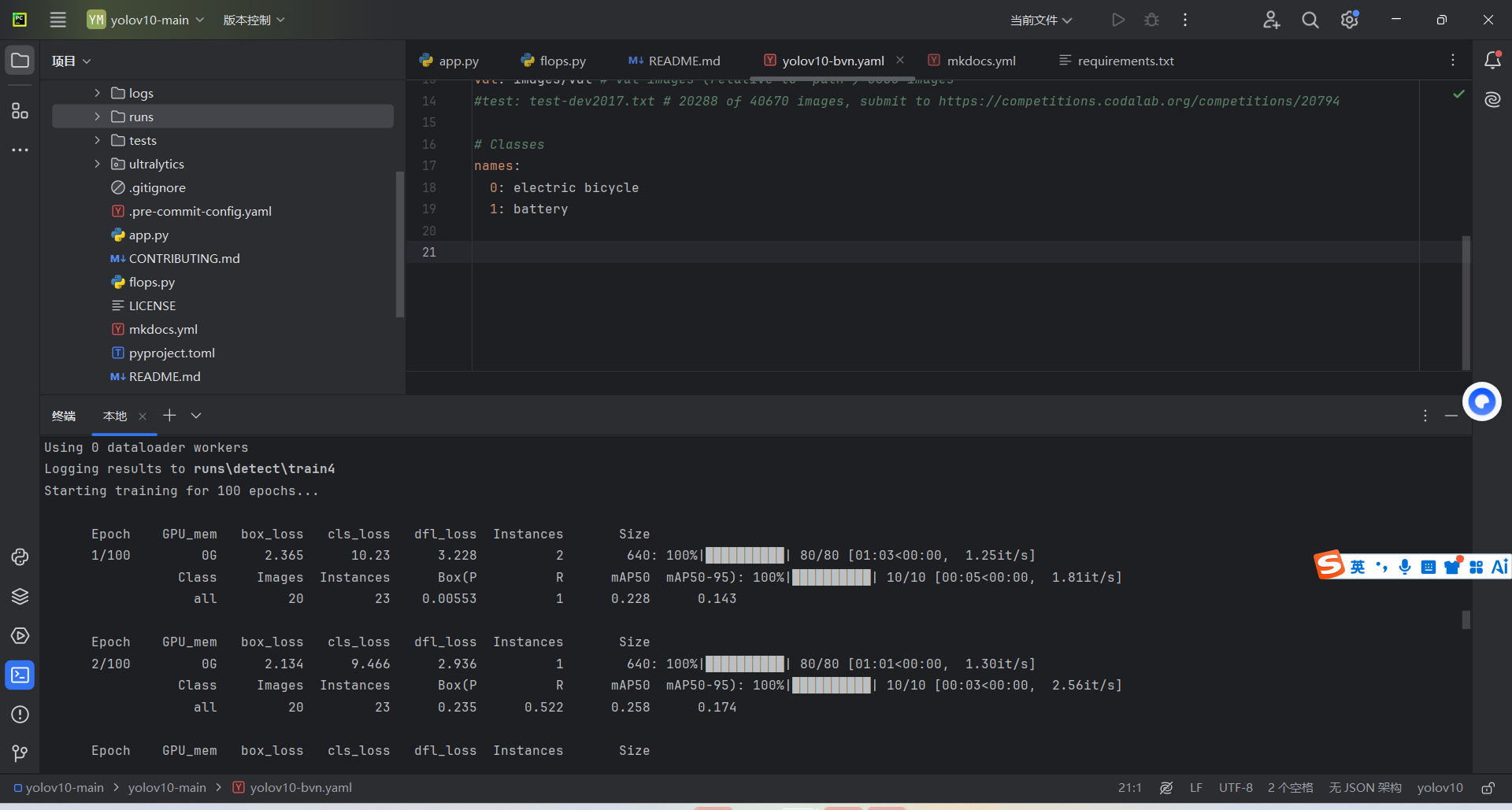
(2)方式二:使用显卡CUDA加速(推荐)
首先检查是否装有CUDA版本的PyTorch
运行以下.py文件,输出打印显示 False 表示未安装,则卸载pytorch重新安装CUDA版本的pytorch(当打印为Ture表示已安装此版本的pytorch可以跳过安装步骤直接开始训练)
import
torch print(torch.cuda.is_available()) # 输出True=正常,False=需重装PyTorch
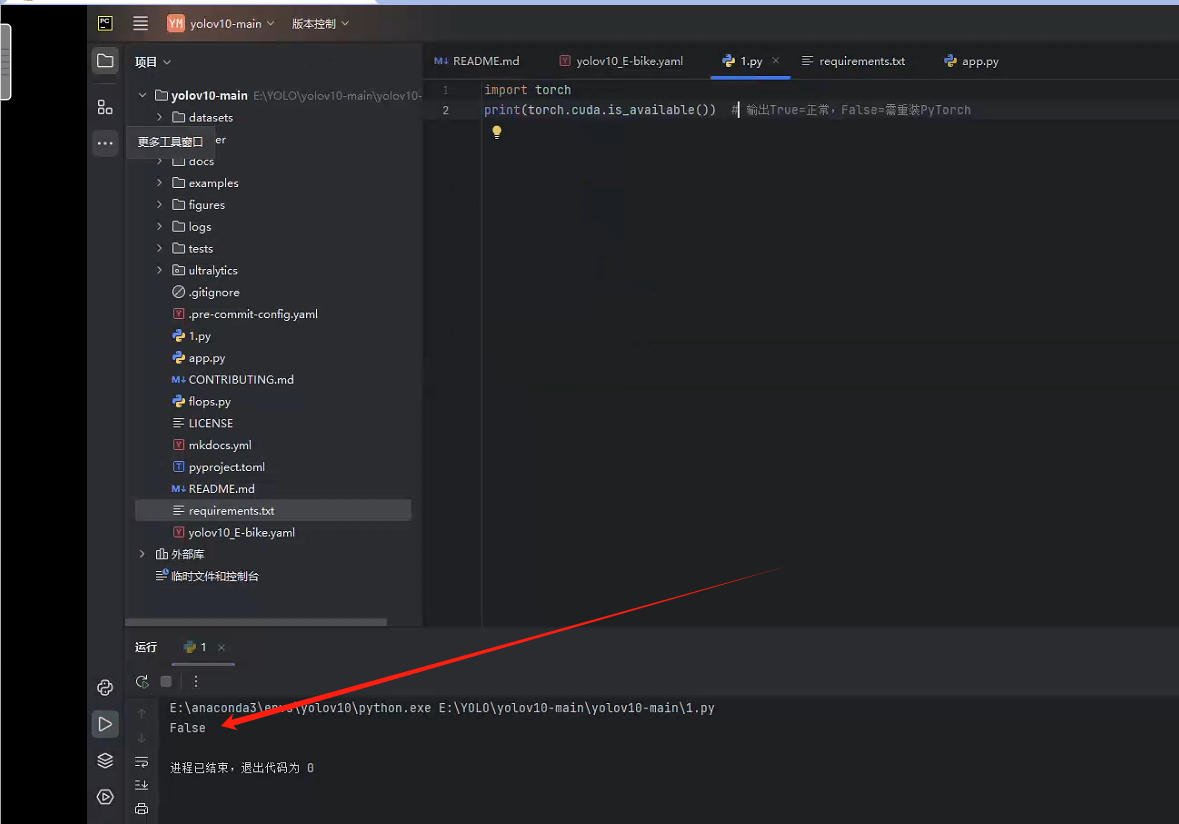
我这里显示未安装,则需要卸载重新安装一下
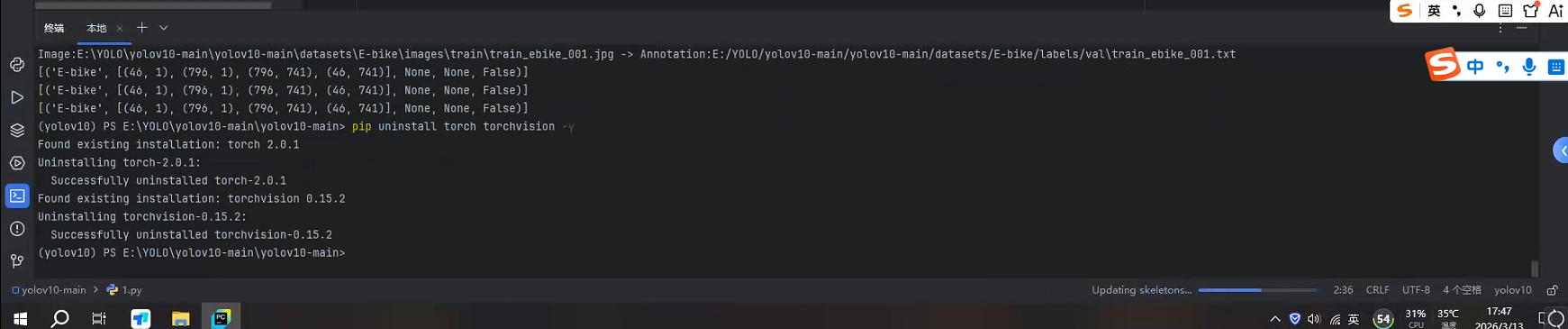
运行以下命令卸载
pip uninstall torch torchvision -y
运行以下命令安装CUDA版本的pytorch
pip install torch==2.0.1 torchvision==0.15.2 --index-url https://download.pytorch.org/whl/cu118

运行以下命令开始训练!!!
yolo detect train data=yolov10-E-bike.yaml model=yolov10s.pt epochs=100 batch=8 imgsz=640 device=0 amp=True cache=True
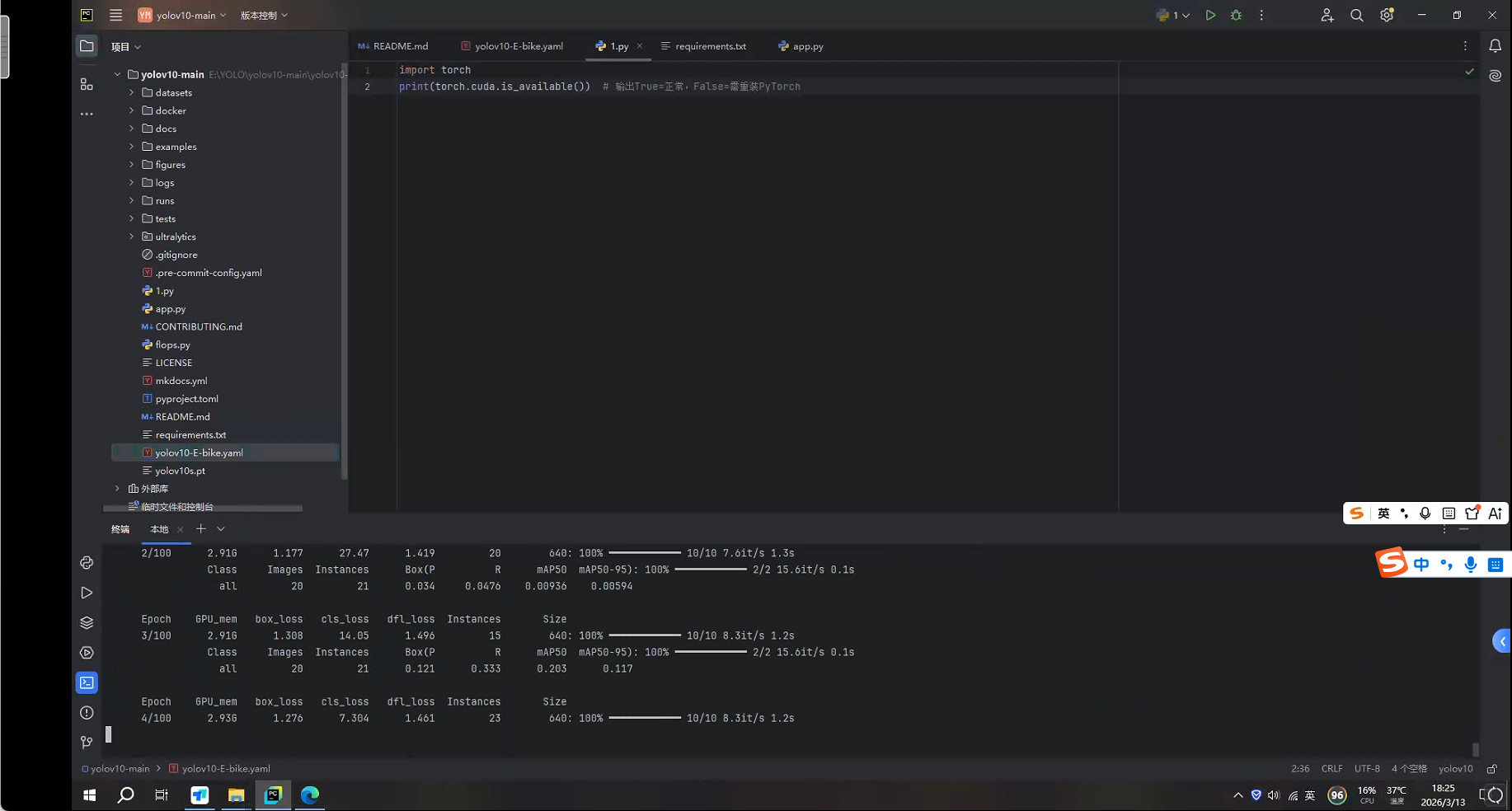
训练完成后,得到best.pt
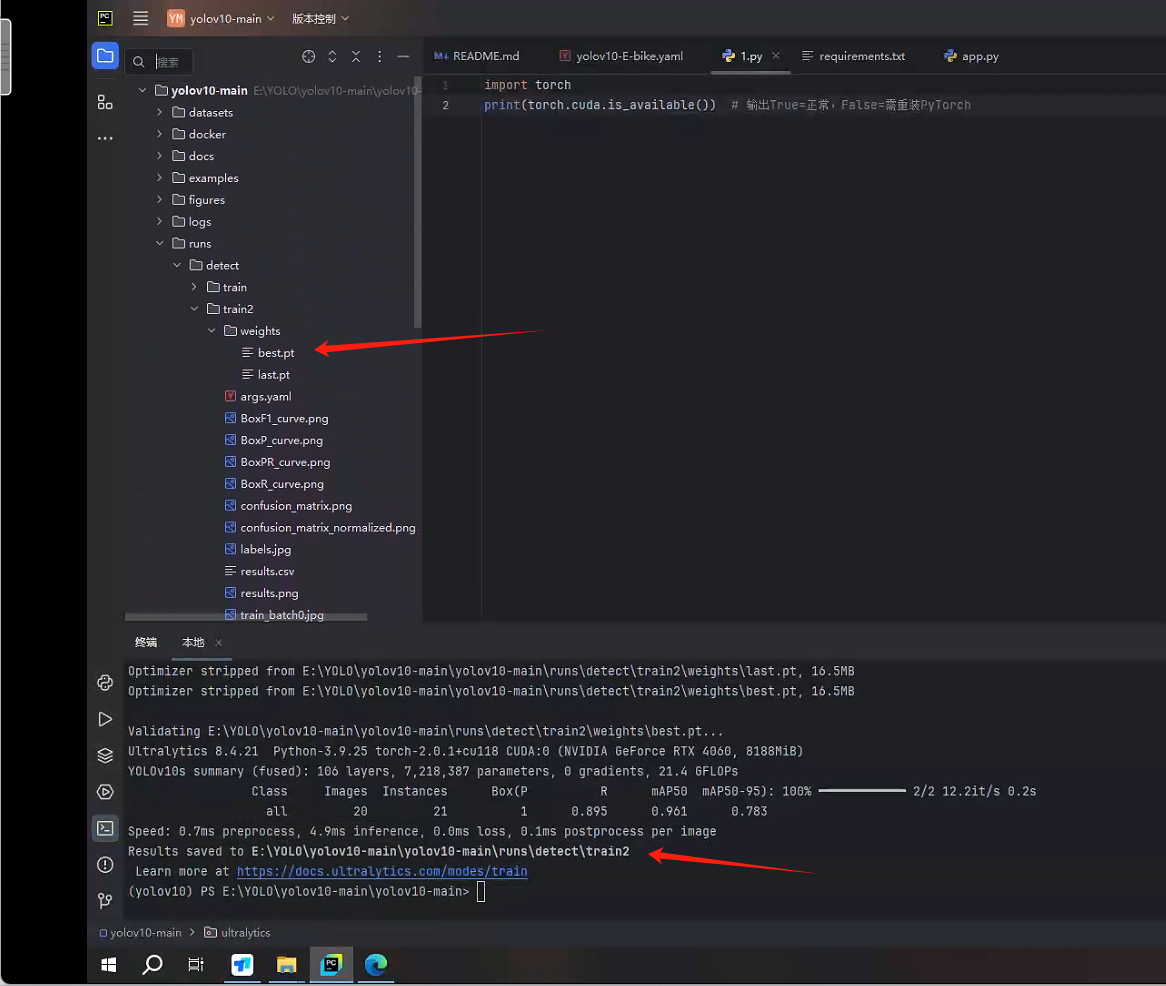
(五)推理测试
创建一个测试集文件夹,运行以下代码来测试训练的情况,我这里找了10张图片来验证
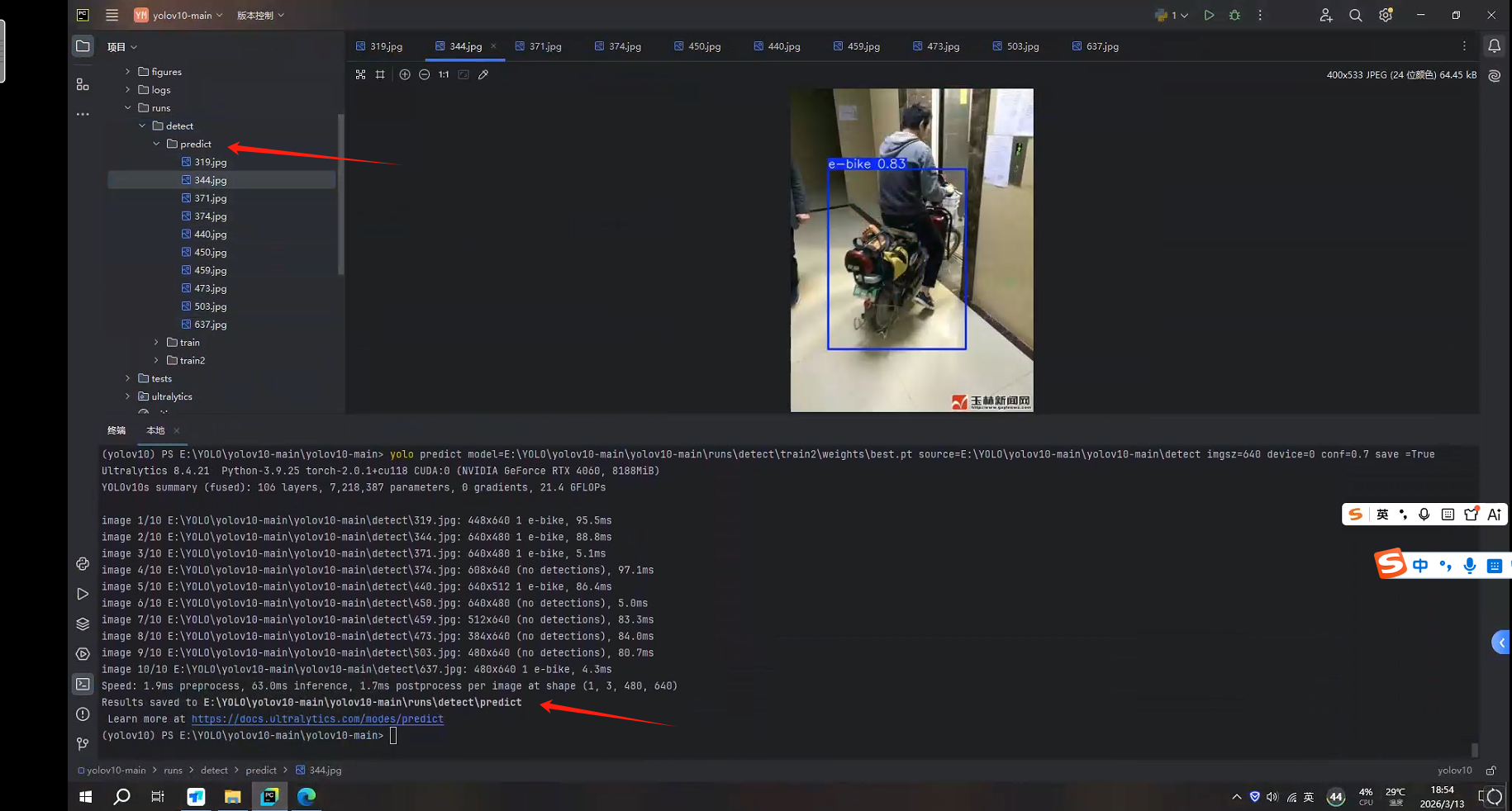
yolo predict model=E:\YOLO\yolov10-main\yolov10-main\runs\detect\train2\weights\best.pt source=E:\YOLO\yolov10-main\yolov10-main\detect imgsz=640 device=0 conf=0.7 save =True
在predict文件夹中即可看到推理的置信度及画框情况
(六)部署到RK3588边缘设备
1.pt转onnx
转换需要在ubuntu系统上进行转换,没有的可以去下载个虚拟机,安装ubuntu系统,运行以下命令,pt→onnx
yolo export model=./best.pt format=rknn opset=13 simplify=True
model:修改为自己的best.pt路径

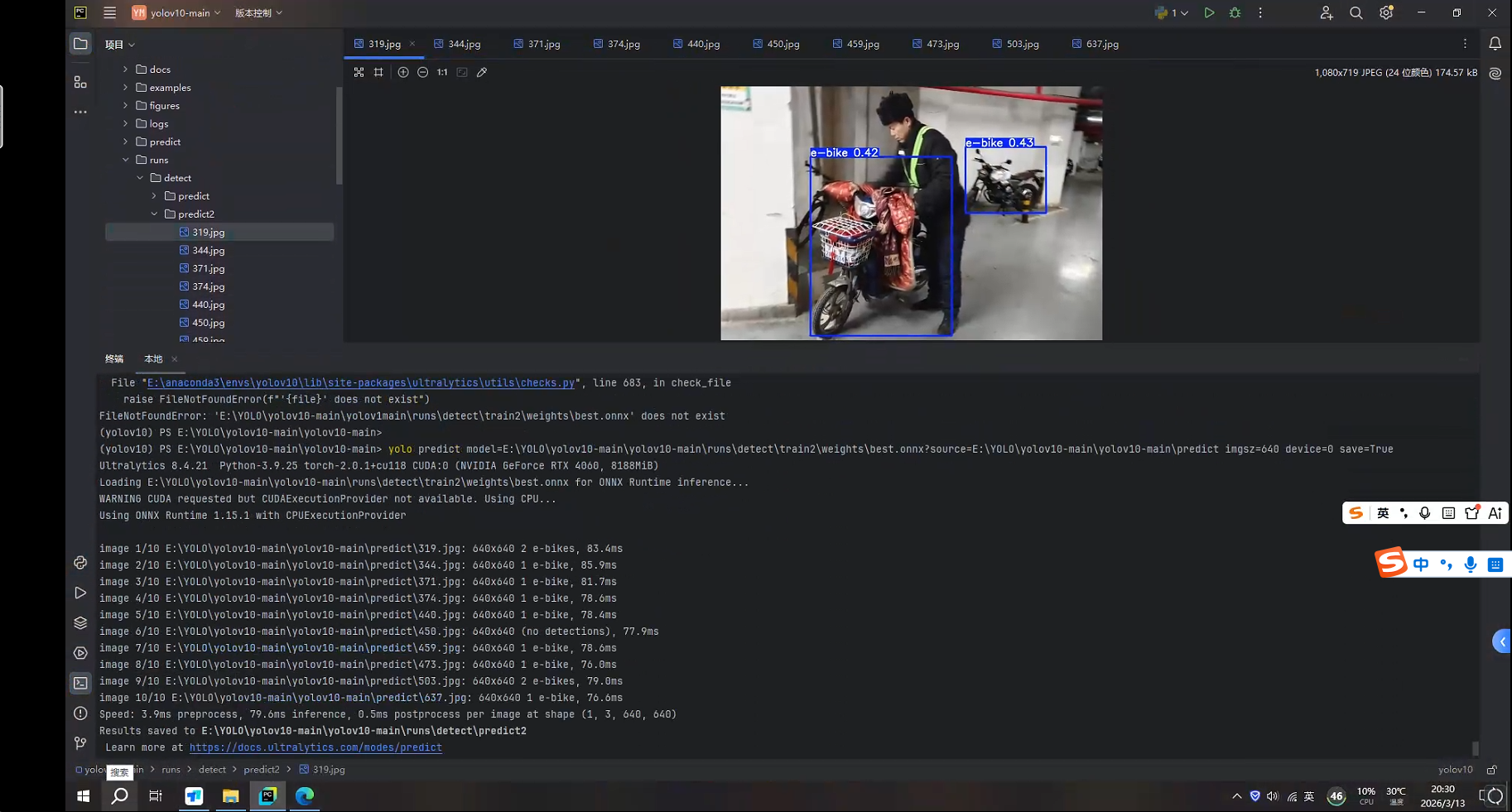
验证best.onnx是否可用,运行以下命令
yolo predict model=E:\YOLO\yolov10-main\yolov10-main\runs\detect\train2\weights\best.onnx source=E:\YOLO\yolov10-main\yolov10-main\predict imgsz=640 device=0 save=True
2.onnx转rknn
rknn的转换也需要在Ubuntu系统,并且需要安装rknn-toolkit2环境,可以在这https://github.com/airockchip/rknn-toolkit2下载最新版,安装完使用以下开源的程序转换https://github.com/airockchip/rknn_model_zoo/examples/yolov10/python/convert.py![]() https://github.com/airockchip/rknn_model_zoo/examples/yolov10/python/convert.py
https://github.com/airockchip/rknn_model_zoo/examples/yolov10/python/convert.py
文件夹格式--convert.py
--best.onnx
--dataset.txt(里面需要指引到量化图片的路径)
import sys
from rknn.api import RKNNDATASET_PATH = './dataset.txt
DEFAULT_RKNN_PATH = './best.rknn'
DEFAULT_QUANT = Truedef parse_arg():
if len(sys.argv) < 3:
print("Usage: python3 {} onnx_model_path [platform] [dtype(optional)] [output_rknn_path(optional)]".format(sys.argv[0]))
print(" platform choose from [rk3562, rk3566, rk3568, rk3576, rk3588, rv1126b, rv1109, rv1126, rk1808]")
print(" dtype choose from [i8, fp] for [rk3562, rk3566, rk3568, rk3576, rk3588, rv1126b]")
print(" dtype choose from [u8, fp] for [rv1109, rv1126, rk1808]")
exit(1)model_path = sys.argv[1]
platform = sys.argv[2]do_quant = DEFAULT_QUANT
if len(sys.argv) > 3:
model_type = sys.argv[3]
if model_type not in ['i8', 'u8', 'fp']:
print("ERROR: Invalid model type: {}".format(model_type))
exit(1)
elif model_type in ['i8', 'u8']:
do_quant = True
else:
do_quant = Falseif len(sys.argv) > 4:
output_path = sys.argv[4]
else:
output_path = DEFAULT_RKNN_PATHreturn model_path, platform, do_quant, output_path
if __name__ == '__main__':
model_path, platform, do_quant, output_path = parse_arg()# Create RKNN object
rknn = RKNN(verbose=False)# Pre-process config
print('--> Config model')
rknn.config(mean_values=[[0, 0, 0]], std_values=[
[255, 255, 255]], target_platform=platform)
print('done')# Load model
print('--> Loading model')
ret = rknn.load_onnx(model=model_path)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')# Build model
print('--> Building model')
ret = rknn.build(do_quantization=do_quant, dataset=DATASET_PATH)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')# Export rknn model
print('--> Export rknn model')
ret = rknn.export_rknn(output_path)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')# Release
rknn.release()
python convert.py best.onnx rk3588 i8
运行以上.py程序即可完成转换,得到best.rknn模型!
3.在rk3588计算板卡运行推理
需要把转换的best.rknn导入到rk3588中,并下载rknn_model_zoo中的推理程序,https://github.com/airockchip/rknn_model_zoo/examples/yolov10/python/yolov10.py运行以下程序即可推理
python yolov10. py - - model_path best.rknn - - target rk3588 --img_show img_folder data
-
--model_path MODEL_PATH: 指定 RKNN 模型文件路径(必须) -
-t target TARGET: 目标平台,例如rk3588 -
--device_id DEVICE_ID: 设备 ID(如果有多个 RKNN 设备) -
-img_show: 显示推理结果图片 -
-img_save: 保存推理结果图片 -
--anno_json ANNO_JSON: 标注文件的 JSON 路径(用于精度评估) -
-img_folder IMG_FOLDER: 待推理的图片文件夹 -
--coco_map_test: 执行 COCO mAP 测试(需要提供标注文件)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 37
37 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)