告别付费 PDF 工具!这款 AI 加持的免费神器搞定所有处理需求
·

日常处理 PDF 时,不少人都有过这样的经历:想修改文档里的文字和图片,却发现普通阅读器没有编辑权限;把 PDF 转成 Word 后格式全乱,还要重新排版;扫描版的 PDF 无法复制文字,只能手动录入;多个 PDF 文件需要整合,却找不到简单的合并方法。而市面上多数能解决这些问题的软件,要么有功能限制,要么需要付费开通会员,耗费时间又增加成本。而这款融合 AI 技术的免费 PDF 处理软件,能一站式解决上述所有问题,且支持 Windows、Mac、安卓、iOS 多端使用,无需付费无附加条件,AI 相关功能也可免费使用,完全适配日常办公学习的各类 PDF 处理需求。
一、软件核心功能实操教程
(一)基础文档编辑操作
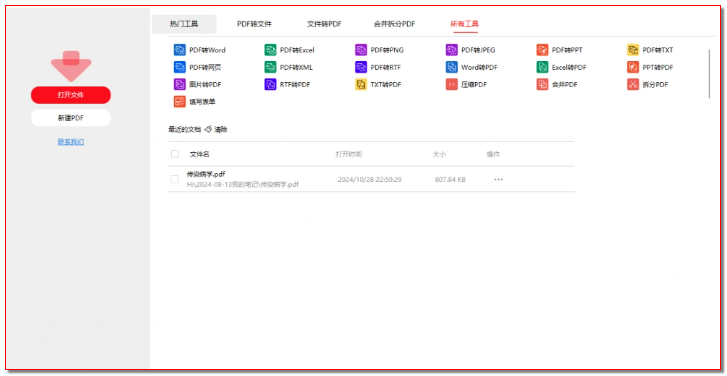
- 打开软件后,直接拖拽 PDF 文件至界面,或通过「文件 - 打开」选择目标文档,软件会自动识别文档内的文本、图像、形状等所有元素。
- 编辑文本时,直接双击需要修改的文字区域,即可进入编辑模式,支持字体、字号、颜色的调整,修改后保存即可同步至文档。
- 处理图像时,选中图片可进行裁剪、旋转、缩放,若需要替换图片,直接将新图片拖拽至目标位置,软件会自动适配原有排版。
- 若需要给文档添加签名、链接或表单字段,在软件顶部工具栏找到对应的功能按钮,签名支持手写绘制或导入图片形式,链接可直接关联网址或文档内页面,表单字段可根据需求添加输入框、选择框等。
(二)PDF 格式转换与批量处理
- 单文件转换:打开需要转换的 PDF,点击工具栏「转换」按钮,选择目标格式(Word、Excel、PPT、图片等),勾选「保留原格式」,点击「开始转换」,几秒内即可完成,转换后的文档排版与原 PDF 高度一致。
- 批量转换:点击软件首页「批量处理」,选择「批量转换」,添加需要转换的所有 PDF 文件,统一选择目标格式,设置输出路径后,可一次性完成多文件转换,大幅提升处理效率。
- 格式互转:该软件也支持其他格式转 PDF,将 Word、图片等文件导入软件,点击「转 PDF」,可快速生成标准 PDF 文档,支持调整文档分辨率和压缩程度。

(三)OCR 图文识别(支持扫描版 PDF)
- 打开扫描版 PDF 或包含图片的 PDF 文档,点击工具栏「OCR 识别」,软件会弹出语言选择框,选择文档对应的语言(支持多语种)。
- 勾选需要识别的页面,点击「开始识别」,软件会自动将图片或扫描内容转换为可编辑的文本,识别完成后,即可对文本进行修改、复制等操作。
- 识别后的文档可直接保存为 PDF,也可转换为其他格式,识别准确率较高,能满足日常办公学习的文字提取需求。
(四)PDF 文档管理(合并、拆分、组织页面)
- 合并 PDF:点击「批量处理 - 合并 PDF」,添加需要合并的所有 PDF 文件,可通过拖拽调整文件的排列顺序,设置好输出路径后,点击「开始合并」,即可生成一个完整的 PDF 文档。
- 拆分 PDF:打开需要拆分的 PDF,点击「拆分」,可选择按页面数量拆分(如每 5 页拆分为一个文件)或按指定页面拆分(如提取第 3-8 页为新文档),确认后即可完成拆分。
- 组织页面:打开 PDF 后,软件左侧会显示页面缩略图,选中页面可进行删除、旋转、拖拽排序,调整完成后保存,即可更新文档的页面布局。
(五)AI 特色功能(总结、提问 PDF)
- AI 总结 PDF:打开需要总结的 PDF 文档,点击工具栏「AI 总结」,软件会自动扫描文档内容,根据文档篇幅生成精简的总结内容,涵盖核心观点、关键数据和主要结论,支持调整总结的详细程度。
- AI 提问 PDF:在「AI 总结」旁边的输入框中,输入想要了解的问题(如「本文的研究方法有哪些?」「这份报告的核心数据是什么?」),软件会基于文档内容给出精准的回答,无需手动翻阅查找。
(六)其他实用功能
- PDF 注释:工具栏提供高亮、下划线、注释框、箭头等多种注释工具,选中需要标记的内容,点击对应的工具即可添加注释,注释支持修改和删除,方便文档批注和交流。
- 表格填写:打开包含表单的 PDF,直接点击表格输入框即可填写内容,支持单选、多选、文本输入等各类表单类型,填写完成后可保存或打印。
- PDF 压缩:打开需要压缩的 PDF,点击「压缩」,可选择轻度、中度、重度压缩,软件会在保证清晰度的前提下,减小文档体积,方便传输和存储。
- 跨设备签字:点击「签字」功能,完成签名制作后,可将签名应用至 PDF 的指定位置,签名支持跨设备同步,在手机、电脑上均可快速调用,且签字过程加密,保障文档安全。
二、软件适用场景分析
- 职场办公场景:日常撰写报告、整理合同、处理会议资料时,可快速编辑 PDF 内容、合并拆分多份文档,将 PDF 转成 Word 进行二次编辑,扫描版的发票、合同也能通过 OCR 识别提取文字,AI 总结功能可快速梳理长文档的核心内容,提升办公效率。
- 学生学习场景:整理课件、复习资料时,可将多个 PDF 讲义合并为一个文档,方便翻阅;扫描版的教材、习题集通过 OCR 识别后,可复制文字整理笔记;遇到长篇的文献资料,利用 AI 总结和提问功能,能快速掌握核心知识点,节省阅读时间。
- 移动办公场景:软件支持安卓、iOS 移动端使用,外出时可通过手机处理 PDF,比如在手机上填写表单、给文档添加注释、完成电子签字,无需携带电脑,满足随时随地的文档处理需求。
- 团队协作场景:团队成员之间分享 PDF 文档时,可通过注释工具进行批注交流,无需额外发送文字说明;整理团队的多份工作成果时,可快速合并为一个 PDF,方便统一提交和归档,提升团队协作的效率。
这款 PDF 处理软件将基础的文档处理功能与 AI 技术深度融合,打破了传统 PDF 工具的功能限制和付费壁垒,无论是简单的文本编辑、格式转换,还是复杂的 OCR 识别、AI 内容分析,都能一站式完成,且多端同步的特性让文档处理不再受设备限制。
相关的软件教程都已经打包好了放在网盘,私信我备注文章标题获取完整软件教程。
import os
import PyPDF2
import pdfplumber
from pdf2docx import Converter
import pytesseract
from PIL import Image
import fitz # PyMuPDF
from typing import List, Optional
# 配置OCR环境(需提前安装Tesseract-OCR,并配置路径)
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe' # Windows路径示例
# Mac/Linux可注释此行,确保tesseract已加入系统环境变量
class PDFProcessor:
"""PDF多功能处理类,集成编辑、转换、OCR、合并拆分等功能"""
def __init__(self, pdf_path: str):
self.pdf_path = pdf_path
self.output_dir = "pdf_output"
if not os.path.exists(self.output_dir):
os.makedirs(self.output_dir)
def extract_text(self, page_numbers: Optional[List[int]] = None) -> str:
"""
提取PDF文本内容
:param page_numbers: 指定提取的页码列表(从0开始),None则提取全部
:return: 提取的文本内容
"""
text = ""
with pdfplumber.open(self.pdf_path) as pdf:
pages = pdf.pages
if page_numbers:
pages = [pages[i] for i in page_numbers if i < len(pages)]
for page in pages:
page_text = page.extract_text() or ""
text += page_text + "\n"
return text
def convert_pdf_to_word(self, output_filename: str = "converted_doc") -> str:
"""
PDF转Word文档
:param output_filename: 输出文件名(无需后缀)
:return: 生成的Word文件路径
"""
output_path = os.path.join(self.output_dir, f"{output_filename}.docx")
cv = Converter(self.pdf_path)
cv.convert(output_path, start=0, end=None)
cv.close()
return output_path
def merge_pdfs(self, pdf_list: List[str], output_filename: str = "merged_pdf") -> str:
"""
合并多个PDF文件
:param pdf_list: 待合并的PDF文件路径列表
:param output_filename: 输出文件名(无需后缀)
:return: 合并后的PDF文件路径
"""
merger = PyPDF2.PdfMerger()
for pdf in pdf_list:
if os.path.exists(pdf):
merger.append(pdf)
output_path = os.path.join(self.output_dir, f"{output_filename}.pdf")
merger.write(output_path)
merger.close()
return output_path
def split_pdf(self, split_pages: List[int], output_prefix: str = "split_pdf") -> List[str]:
"""
拆分PDF文件(按指定页码拆分)
:param split_pages: 拆分页码列表,如[2,5]表示拆分为0-2页、3-5页、6-末尾
:param output_prefix: 输出文件前缀
:return: 拆分后的PDF文件路径列表
"""
output_paths = []
with open(self.pdf_path, 'rb') as f:
reader = PyPDF2.PdfReader(f)
total_pages = len(reader.pages)
# 处理拆分页码(补充首尾)
split_points = [0] + split_pages + [total_pages]
for i in range(len(split_points)-1):
start = split_points[i]
end = split_points[i+1]
writer = PyPDF2.PdfWriter()
for page_num in range(start, end):
if page_num < total_pages:
writer.add_page(reader.pages[page_num])
output_path = os.path.join(self.output_dir, f"{output_prefix}_{i+1}.pdf")
with open(output_path, 'wb') as out_f:
writer.write(out_f)
output_paths.append(output_path)
return output_paths
def ocr_pdf_page(self, page_num: int = 0) -> str:
"""
OCR识别PDF指定页面(提取图片中的文字)
:param page_num: 待识别的页码(从0开始)
:return: 识别后的文本内容
"""
# 提取PDF页面为图片
doc = fitz.open(self.pdf_path)
page = doc[page_num]
pix = page.get_pixmap()
img_path = os.path.join(self.output_dir, f"ocr_temp_{page_num}.png")
pix.save(img_path)
# OCR识别图片文字
img = Image.open(img_path)
text = pytesseract.image_to_string(img, lang='chi_sim') # chi_sim为简体中文,可改为eng等
# 删除临时图片
os.remove(img_path)
doc.close()
return text
def compress_pdf(self, output_filename: str = "compressed_pdf", zoom: float = 0.7) -> str:
"""
压缩PDF文件(降低分辨率)
:param output_filename: 输出文件名(无需后缀)
:param zoom: 缩放比例(0.1-1.0,越小压缩越明显)
:return: 压缩后的PDF文件路径
"""
doc = fitz.open(self.pdf_path)
output_path = os.path.join(self.output_dir, f"{output_filename}.pdf")
# 创建新PDF文档
new_doc = fitz.open()
for page in doc:
# 缩放页面内容
mat = fitz.Matrix(zoom, zoom)
pix = page.get_pixmap(matrix=mat)
# 将图片转回PDF页面
new_page = new_doc.new_page(width=page.rect.width, height=page.rect.height)
new_page.insert_image(new_page.rect, pixmap=pix)
new_doc.save(output_path)
new_doc.close()
doc.close()
return output_path
# ---------------------- 示例:调用PDF处理工具 ----------------------
if __name__ == "__main__":
# 1. 初始化处理器(替换为你的PDF文件路径)
pdf_processor = PDFProcessor("test.pdf")
# 2. 提取文本
print("=== 提取PDF文本 ===")
text = pdf_processor.extract_text(page_numbers=[0,1]) # 提取前2页文本
print(text[:500]) # 打印前500个字符
# 3. PDF转Word
print("\n=== PDF转Word ===")
word_path = pdf_processor.convert_pdf_to_word("我的文档")
print(f"Word文件已生成:{word_path}")
# 4. 合并PDF(需准备多个PDF文件路径)
# pdf_list = ["file1.pdf", "file2.pdf"]
# merged_path = pdf_processor.merge_pdfs(pdf_list, "合并后的文档")
# print(f"合并后的PDF:{merged_path}")
# 5. 拆分PDF(按页码2和5拆分)
# split_paths = pdf_processor.split_pdf([2,5], "拆分后的文档")
# print(f"拆分后的PDF路径:{split_paths}")
# 6. OCR识别第0页(扫描版PDF)
# ocr_text = pdf_processor.ocr_pdf_page(0)
# print("=== OCR识别结果 ===")
# print(ocr_text)
# 7. 压缩PDF
# compressed_path = pdf_processor.compress_pdf("压缩后的文档", 0.6)
# print(f"压缩后的PDF:{compressed_path}")
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)