Spring AI Alibaba Skill 注册机制详解与实战指南:小白程序员必备,轻松掌握大模型技能开发,立即收藏学习!
本文深入解析了Spring AI Alibaba的Skill注册机制,详细介绍了如何定义、注册和管理Agent的技能,以及如何将工具与技能绑定实现渐进式披露。通过实际项目案例,展示了技能定义文件的结构、关键字段的含义以及技能注册和使用的具体步骤。文章还提供了最佳实践建议,帮助开发者优化性能、确保安全,并解答了常见问题。对于想要学习大模型技能开发的小白和程序员来说,这是一份极具价值的实战指南。
1、引言
在构建基于大语言模型的智能 Agent 应用时,如何有效地管理和组织 Agent 的能力是一个关键挑战。Spring AI Alibaba 提供了一套完整的 Skill(技能)注册和使用机制,使得我们可以模块化地管理 Agent 的各种能力,并支持渐进式的能力披露。本文将深入解析这套机制的原理和实际使用方法。
你将学到什么
- Spring AI Alibaba 中 Skill 的概念和作用
- 如何定义和注册 Skill
- SkillsAgentHook 的工作原理
- 如何将工具与 Skill 绑定实现渐进式披露
- 实际项目中的最佳实践
2、核心概念解析
2.1 什么是 Skill?
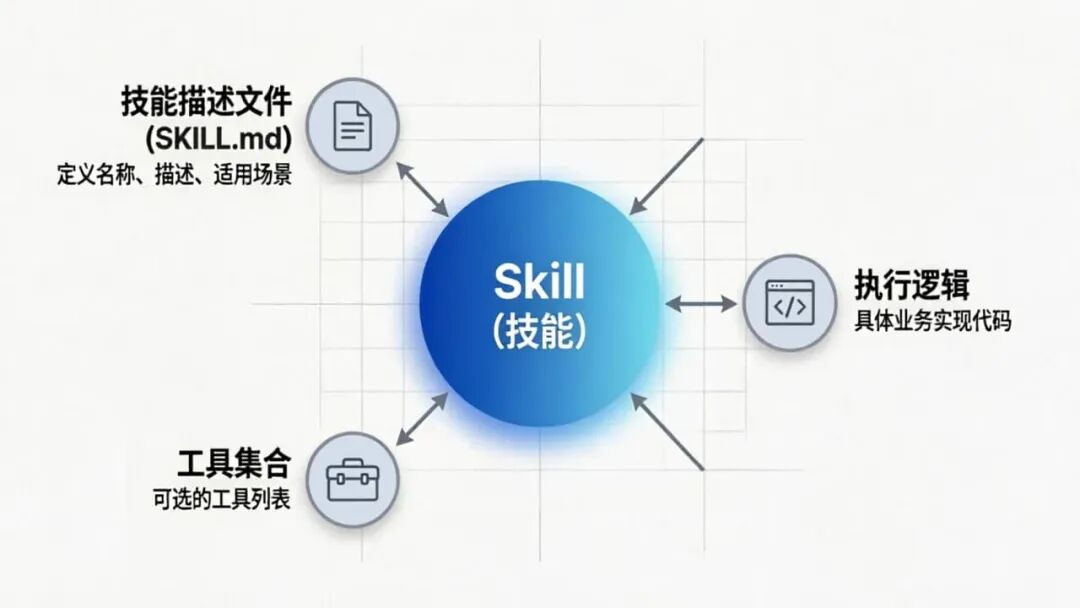
在 Spring AI Alibaba 的语境中,**Skill(技能)**是指 Agent 可以执行的特定任务或能力的封装。一个 Skill 通常包含:
-
技能描述文件(SKILL.md)
:定义技能的名称、描述、适用场景等元信息
-
执行逻辑
:具体的业务实现代码
-
工具集合
:技能执行过程中可能用到的工具(可选)
2.2 为什么需要 Skill 注册机制?
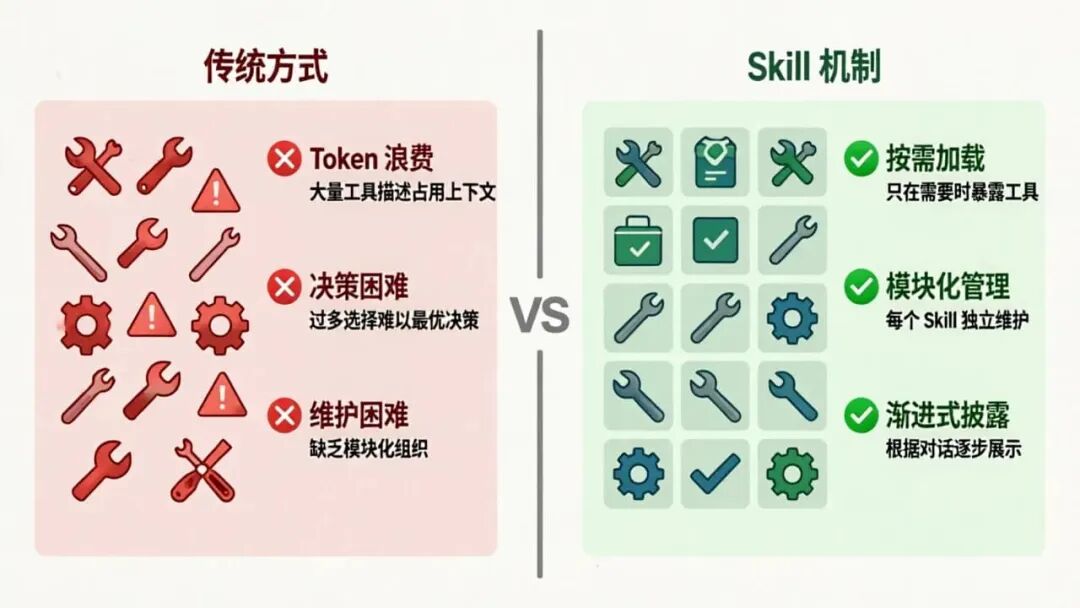
传统的 Agent 实现方式往往将所有工具和能力一次性暴露给大模型,这会导致:
-
Token 浪费
:大量工具描述占用上下文窗口
-
决策困难
:过多的选择可能让模型难以做出最优决策
-
维护困难
:缺乏模块化的组织结构
通过 Skill 注册机制,我们可以实现:
- ✅ 按需加载:只在需要时才暴露具体工具
- ✅ 模块化管理:每个 Skill 独立维护和测试
- ✅ 渐进式披露:根据对话进展逐步展示能力
3、项目结构说明
让我们通过一个实际项目来理解 Skill 的使用:
L03-skill-creator/
├── src/main/
│ ├── java/com/git/hui/springai/ali/
│ │ └── L03Application.java # 主应用程序
│ └── resources/
│ ├── skills/ # 技能定义目录
│ │ ├── blog_creator/
│ │ │ └── SKILL.md # 博客创作技能定义
│ │ └── modern_poetry/
│ │ └── SKILL.md # 现代诗创作技能定义
│ └── application.yml # 应用配置
└── pom.xml # Maven 依赖配置
4、 技能定义文件详解
4.1 SKILL.md 文件结构
每个技能都需要一个 SKILL.md 文件来定义其元数据。以 modern_poetry 为例:
---
name: modern_poetry
description: 创作优美的现代诗歌。使用富有想象力的语言,表达情感、意境和哲思。
allowed-tools: [Read, Write, Shell]
tags: [poetry, creative-writing, literature, art]
platforms: [Claude, ChatGPT, Gemini]
---
# 现代诗创作技能
## 何时使用此技能
- 表达个人情感和内心体验
- 描绘自然景物和生活片段
- 探索哲理和人生思考
...
4.2 关键字段说明
| 字段 | 说明 | 示例 |
|---|---|---|
name |
技能的唯一标识符 | modern_poetry |
description |
技能的详细描述 | “创作优美的现代诗歌…” |
allowed-tools |
允许使用的工具列表 | [Read, Write, Shell] |
tags |
技能标签,便于分类检索 | [poetry, creative-writing] |
5、 技能注册与使用
5.1 基础配置
首先配置必要的依赖:
<dependencies>
<!-- Spring AI OpenAI Starter -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
5.2 应用配置
在 application.yml 中配置模型信息:
spring:
ai:
openai:
api-key: ${silicon-api-key}
chat:
options:
model: Qwen/Qwen2.5-7B-Instruct
base-url: https://api.siliconflow.cn
5.3 技能注册代码实现
步骤一:创建 SkillRegistry
@Bean
CommandLineRunner commandLineRunner(ChatModel chatModel)throws IOException {
return args -> {
// 使用 ClasspathSkillRegistry 从 classpath 的 skills 目录加载技能
SkillRegistryregistry= ClasspathSkillRegistry.builder()
.classpathPath("skills")
.build();
// 也可以使用 FileSystemSkillRegistry 从文件系统加载
// SkillRegistry registry = FileSystemSkillRegistry.builder()
// .projectSkillsDirectory("/path/to/skills")
// .build();
};
}
说明:
-
ClasspathSkillRegistry:适合打包在 JAR 中的技能
-
FileSystemSkillRegistry:适合动态添加/修改的技能场景
步骤二:创建 SkillsAgentHook
// 创建 SkillsAgentHook,注册 read_skill 工具
SkillsAgentHook hook = SkillsAgentHook.builder()
.skillRegistry(registry)
.build();
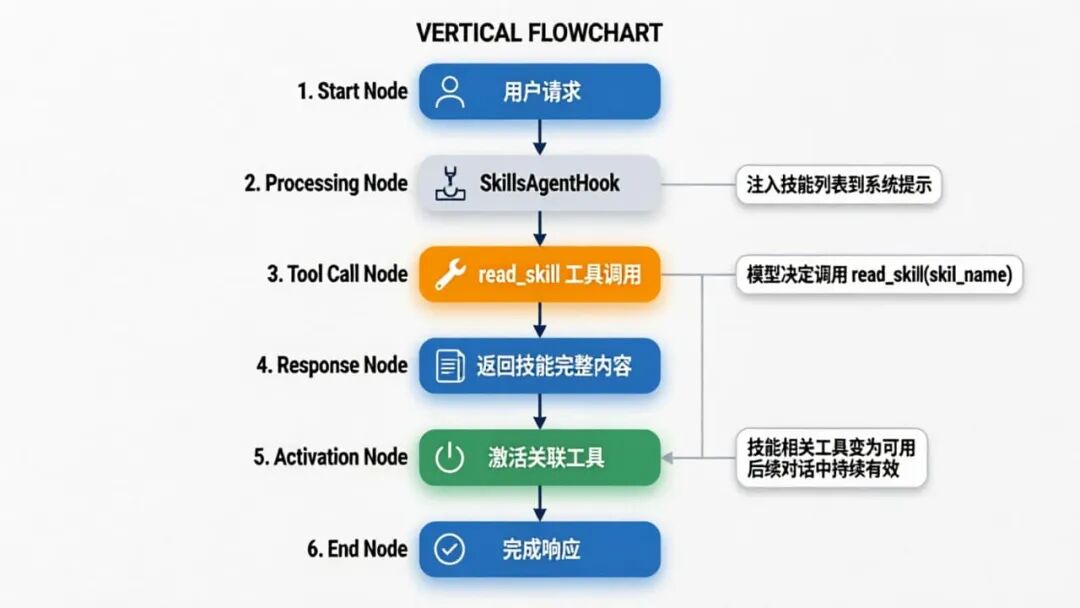
工作原理:
-
SkillsAgentHook会自动向 Agent 注册一个
read_skill工具 -
该工具会将所有可用技能的元数据(名称、描述)注入到系统提示中
-
当模型调用
read_skill(skill_name)时,会返回对应技能的完整内容 -
技能被激活后,其关联的工具也会在后续对话中可用
步骤三:添加其他工具 Hook
如果技能需要执行 shell 命令或其他操作,需要注册相应的工具:
// Shell Hook:提供 Shell 命令执行能力
ShellToolAgentHook shellHook = ShellToolAgentHook.builder()
.shellTool2(ShellTool2.builder(System.getProperty("user.dir")).build())
.build();
// 如果需要 Python 脚本支持
// ToolCallback pythonTool = PythonTool.createPythonToolCallback(PythonTool.DESCRIPTION);
步骤四:构建 ReactAgent
// 创建网络获取工具(可选,用于从网络搜索素材)
varwebFetchTool= WebFetchTool.builder(ChatClient.builder(chatModel).build())
.withName("web-fetcher")
.withDescription("这是一个网络查询的工具,当你需要从网络上进行搜索相关信息时,使用这个工具")
.build();
// 构建 Agent
ReactAgentagent= ReactAgent.builder()
.name("skills-agent")
.model(chatModel)
.systemPrompt("""
你是一个专业的协作助手,当需要进行创作、写文章、写诗歌,
你可以通过 read_skill 工具来获取技能
""")
.enableLogging(true)
.saver(newMemorySaver()) // 启用记忆保存
.tools(webFetchTool) // 注册全局工具
.hooks(List.of(hook, shellHook)) // 注册 Hook
.build();
步骤五:调用 Agent 执行任务
// 场景 1:创作诗歌
AssistantMessage msg = agent.call("帮我写一首关于爱情的诗");
System.out.println(msg.getText());
// 场景 2:结合网络搜索创作博文
AssistantMessage msg = agent.call("""
帮我写一篇关于 ReAct 原理的介绍文章
在开始之前,请先使用 web-fetcher 从
https://www.ppai.top/ai-guides/tutorial/hello-agent/03.Agent%E6%80%9D%E8%80%83%E6%A1%86%E6%9E%B6-ReAct.html
中搜索相关的素材作为博文的准备材料
""");
System.out.println(msg.getText());
6、 进阶用法:工具与技能绑定
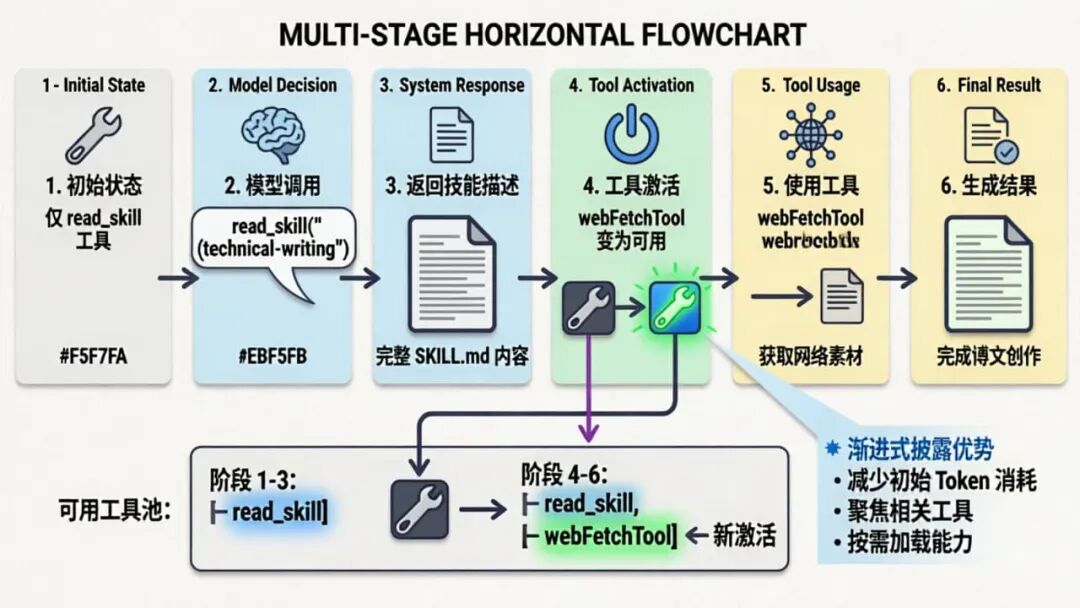
6.1 渐进式工具披露
通过将工具与特定 Skill 绑定,可以实现更精细的控制:
Map<String, List<ToolCallback>> groupedTools = Map.of(
"technical-writing", // 与 SKILL.md 的 name 一致
List.of(webFetchTool)
);
SkillsAgentHook hook = SkillsAgentHook.builder()
.skillRegistry(registry)
.groupedTools(groupedTools) // 绑定工具到技能
.build();
工作流程:
- 初始状态:只暴露
read_skill工具和技能列表 - 模型调用:
read_skill("technical-writing") - 系统响应:返回
technical-writing技能的完整描述 - 工具激活:同时暴露与该技能绑定的
webFetchTool - 后续对话:模型可以使用已激活的工具完成写作任务
6.2 优势分析
| 特性 | 传统方式 | Skill 绑定方式 |
|---|---|---|
| Token 消耗 | 所有工具描述 | 仅激活技能的工具 |
| 决策效率 | 选择过多 | 聚焦相关工具 |
| 可维护性 | 分散 | 模块化组织 |
| 扩展性 | 困难 | 容易 |
7、 执行流程图解
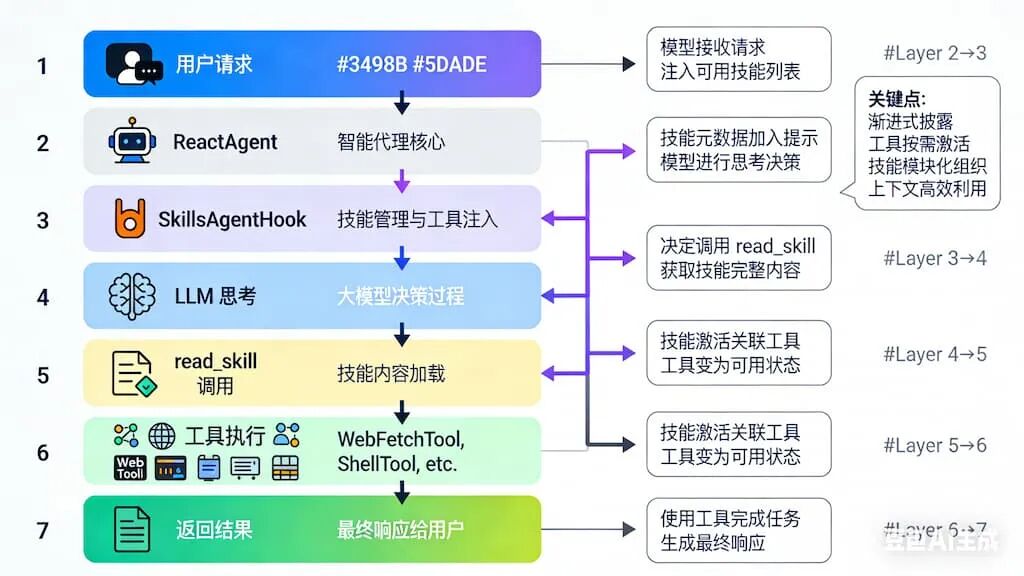
用户请求
↓
[ReactAgent]
↓
[SkillsAgentHook] ← 注入技能列表到系统提示
↓
[LLM 思考]
↓
决定调用 read_skill("blog_creator")
↓
[SkillsAgentHook] ← 返回技能完整内容
激活关联工具
↓
[LLM 再次思考] ← 使用技能知识和工具
↓
执行工具调用 → [WebFetchTool] 获取素材
↓
生成最终结果
↓
返回给用户
8、最佳实践建议
8.1 技能设计原则
- 单一职责:每个 Skill 专注于一个特定领域
- ✅ 好:
blog_creator(博客创作) - ❌ 差:
everything_helper(什么都做)
- 清晰描述:在 SKILL.md 中明确说明使用场景
## 何时使用此技能
- 撰写技术教程和指南
- 分享项目实战经验
...
- 合理分组工具:将相关工具绑定到同一技能
Map.of(
"data-analysis",
List.of(pythonTool, chartTool, fileTool)
)
8.2 性能优化
-
使用 MemorySaver:保持对话上下文
.saver(new MemorySaver()) -
启用日志:便于调试和监控
.enableLogging(true) -
合理设置模型:根据任务复杂度选择
# 简单任务:使用较小模型
model: Qwen/Qwen2.5-7B-Instruct
# 复杂任务:使用更大模型
model: Qwen/Qwen3.5-4B
8.3 安全考虑
- 限制 Shell 命令范围:
ShellTool2.builder(System.getProperty("user.dir")) // 限制在项目目录
.build()
-
审查技能内容:确保 SKILL.md 不包含恶意指令
-
API Key 管理:使用环境变量
api-key: ${silicon-api-key} # 从环境变量读取
9、常见问题解答
Q1: 技能文件放在哪里?
A: 有两种方式:
-
Classpath
:
src/main/resources/skills/(打包在 JAR 中) -
文件系统
:任意目录(支持热更新)
Q2: 如何调试技能调用过程?
A: 启用日志记录:
.enableLogging(true)
查看控制台输出,了解模型的思考过程和工具调用详情。
Q3: 多个技能之间如何协作?
A: 模型可以依次调用多个技能:
- 先调用
read_skill("data-analysis")分析数据 - 再调用
read_skill("blog_creator")生成报告
Q4: 如何自定义技能的加载逻辑?
A: 实现自己的 SkillRegistry:
public class CustomSkillRegistry implements SkillRegistry { // 自定义加载逻辑}
10、 总结
Spring AI Alibaba 的 Skill 注册机制提供了一套优雅的方式来管理和使用 Agent 的能力。通过本文的学习,你应该掌握了:
- ✅ Skill 的概念和价值
- ✅ 如何定义和注册 Skill
- ✅ SkillsAgentHook 的工作原理
- ✅ 工具与技能绑定的渐进式披露
- ✅ 实际应用中的最佳实践
下一步学习建议
- 尝试创建自己的 Skill
- 实验不同的工具组合
- 探索更复杂的 Agent 编排模式
- 参考官方文档了解更多高级特性
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。
对于想入局大模型、抢占未来10年行业红利的程序员和小白来说,现在正是最好的学习时机:行业缺口大、大厂需求旺、薪资天花板高,只要找准学习方向,稳步提升技能,就能轻松摆脱“低薪困境”,抓住AI时代的职业机遇。
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
下面是我整理的大模型学习资源,希望能帮到你。

👇👇扫码免费领取全部内容👇👇

最后
1、大模型学习路线

2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、面试试题/经验

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献301条内容
已为社区贡献301条内容

所有评论(0)