ArXiv 2024 | MambaOut:视觉任务真的需要Mamba吗
·
In memory of Kobe Bryant
“What can I say, Mamba out.” — Kobe Bryant’s NBA farewell speech in 2016
—
文章目录
01 论文信息
- 论文题目:MambaOut: Do We Really Need Mamba for Vision?
- 论文作者:Weihao Yu, Xinchao Wang
- 发表单位:新加坡国立大学(National University of Singapore)
- 发表会议\期刊:ArXiv 2024(已被计算机视觉领域顶会接收)
- 代码链接:https://github.com/yuweihao/MambaOut
- 核心领域:计算机视觉、视觉Mamba、卷积神经网络、状态空间模型(SSM)
02 论文主要贡献
- 核心问题解答:首次从理论与实验层面系统回答“视觉任务是否真的需要Mamba/SSM”这一关键问题,明确指出:
- 在图像分类(短序列、无需因果混合)任务中,SSM完全不必要,甚至会因架构不匹配导致性能下降;
- 在目标检测/语义分割(长序列、无需因果混合)任务中,SSM的线性复杂度优势有潜在价值,但当前视觉Mamba仍未达到卷积-注意力混合模型的最优性能。
- 高效模型提出:提出MambaOut模型,在保留Mamba整体架构的基础上,完全移除核心的SSM模块,仅基于门控卷积(Gated CNN) 构建,在ImageNet分类任务上性能全面超越所有视觉Mamba模型,同时计算效率更高、代码更简洁。
- 任务适配性分析:从序列长度和因果性需求两个维度,量化分析Mamba/SSM与视觉任务的适配性,提出并验证了两个核心假设,为后续跨领域模型设计提供了方法论指导。
- 基准与范式:为视觉Mamba研究提供了一个简洁高效的基准模型,指出视觉Mamba未来应聚焦长序列视觉任务(如视频理解、高分辨率图像分割),而非在图像分类任务中过度优化。
- 架构设计启示:验证了“卷积+门控”结构在视觉任务中的有效性,证明卷积结构在视觉任务中天然具备优势,无需引入复杂的序列建模机制。
03 论文创新点
3.1 任务适配性理论分析

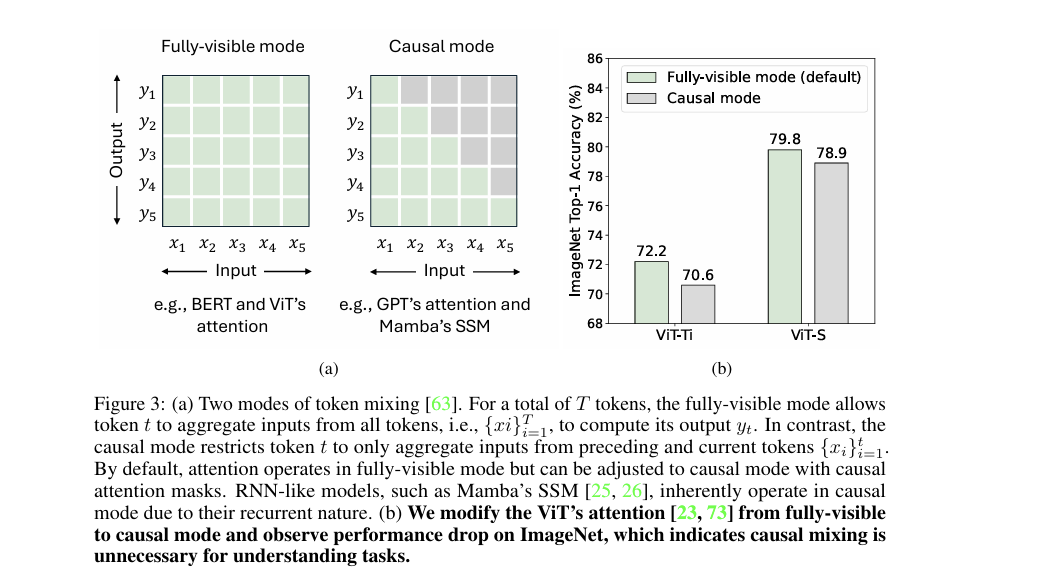
- 序列长度量化:推导长序列判定指标:当令牌长度 (L > 6D)((D) 为通道维度)时,注意力机制的二次复杂度开销超过线性项。
- ImageNet分类:224×224图像经16×16分块后仅产生196个令牌,远小于ViT-S((6×384=2304))阈值,不属于长序列任务;
- 检测/分割任务:COCO检测(800×1280)、ADE20K分割(512×2048)经分块后约产生4K个令牌,超过ViT-S阈值,属于长序列任务。
- 因果性需求分析:视觉识别属于理解类任务,需要全可见模式的令牌混合(每个令牌可访问所有位置信息),而Mamba/SSM的因果模式会人为限制信息获取范围,实验证明将ViT注意力改为因果模式后,ImageNet精度显著下降。
- 核心假设提出:
- 假设1:ImageNet图像分类既非长序列任务,也无需因果混合,因此SSM并非必需;
- 假设2:检测/分割等长序列视觉任务中,SSM的线性复杂度有潜在价值,值得进一步探索。
3.2 极简架构设计
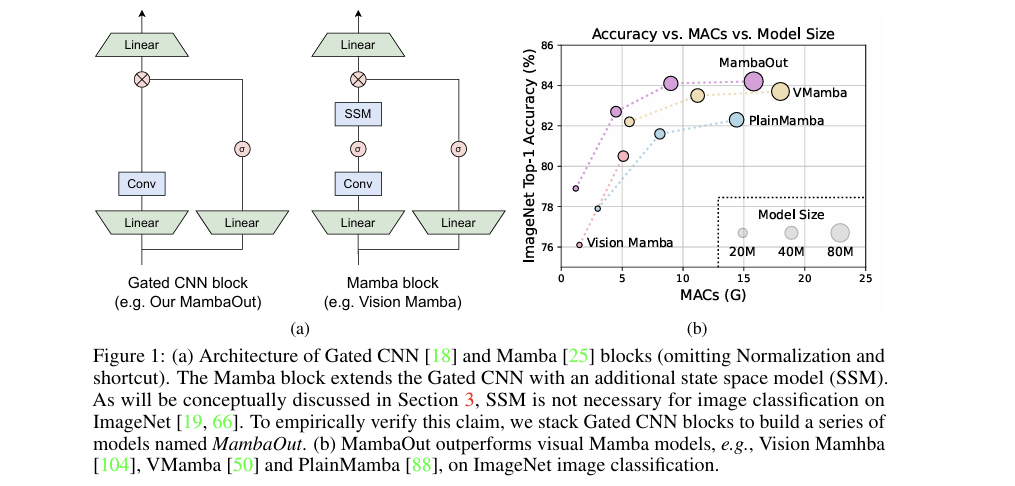
- SSM完全移除:保留Mamba的“门控+残差”整体架构,彻底移除核心的SSM模块,仅用7×7深度可分离卷积作为令牌混合器,实现全可见的空间特征混合,适配视觉任务。
- Gated CNN Block优化:
- 借鉴InceptionNeXt思路,将升维后的特征拆分为门控分支(g)、全连接分支(i)、卷积分支(c),实现全局特征与局部空间特征的融合;
- 引入卷积分支比例(conv_ratio) 超参数,可灵活控制卷积分支的通道数,在精度与计算效率间实现权衡;
- 采用通道扩展比例(expension_ratio=8/3),在提升特征表达能力的同时控制计算量。
- 代码极简性:基于PyTorch和timm实现,无复杂依赖,核心代码仅数百行,便于后续研究与扩展。
3.3 大规模实验验证
- 多任务基准测试:在ImageNet分类、COCO目标检测/实例分割、ADE20K语义分割三大主流视觉基准上,全面对比MambaOut与各类视觉Mamba、卷积、注意力模型;
- 消融实验:系统验证卷积核大小、通道扩展比例、卷积分支比例、归一化方式等关键设计的有效性,为模型调参提供指导;
- 效率对比:证明MambaOut在精度相当的情况下,计算量(MACs)和参数量显著低于视觉Mamba模型,推理速度更快。
04 方法
4.1 整体架构
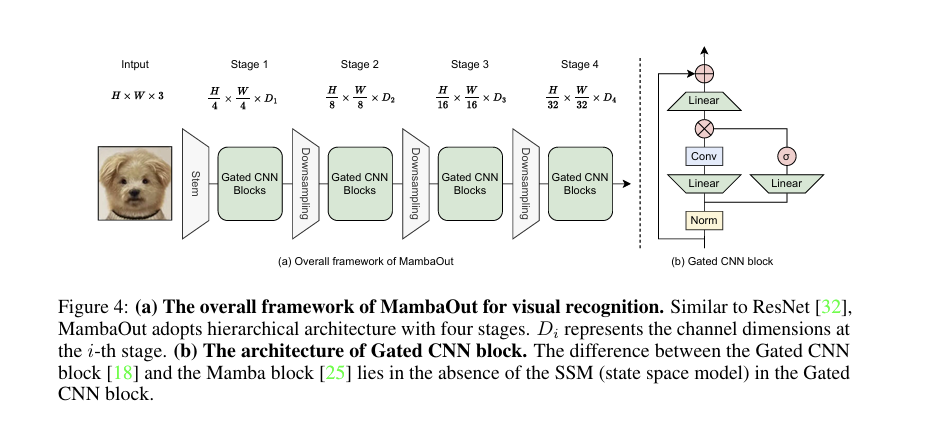
MambaOut采用经典的分层卷积架构,与ResNet/ConvNeXt保持一致,共分为4个Stage,逐步压缩特征图尺寸、提升通道数:
- Stem层:由3×3卷积(步长2)+3×3卷积(步长2)组成,将输入图像 (H×W×3) 下采样为 (\frac{H}{4}×\frac{W}{4}×D_1),完成初步特征提取;
- Stage 1~4:每个Stage由多个Gated CNN Block堆叠而成,Stage间通过下采样层(步长2的3×3卷积)压缩特征图尺寸,通道数依次变为 (D_2, D_3, D_4);
- 输出层:最终特征图尺寸为 (\frac{H}{32}×\frac{W}{32}×D_4),经全局平均池化+全连接层后输出分类结果,或接入检测/分割头完成下游任务。
模型规模分为四个版本:Femto、Tiny、Small、Base,对应不同的通道数和Block堆叠数量。
4.2 Gated CNN Block(核心模块)
该模块是MambaOut的核心,完全替代Mamba的SSM模块,数学表达为:
X′ =Norm(X),
Y =(TokenMixer(X′W1)⊙σ(X′W2))W3 +X,
4.2.1 详细流程

- 输入归一化:对输入特征 (X) 执行LayerNorm,得到 (X’),稳定训练过程;
- 通道升维与分支拆分:
- 通过全连接层 (fc1) 将通道数从 (dim) 升维至 (hidden×2)((hidden = int(8/3×dim)));
- 按
split_indices=(hidden, hidden-conv_channels, conv_channels)拆分为三个分支:- (G):门控分支,维度为 (hidden),用于生成动态权重;
- (I):全连接分支,维度为 (hidden-conv_channels),捕捉全局特征;
- (C):卷积分支,维度为 (conv_channels),捕捉局部空间特征;
- 卷积分支处理:
- 将 (C) 从通道最后格式 ([B,H,W,C]) 转置为通道优先格式 ([B,C,H,W]),适配PyTorch卷积层;
- 执行7×7深度可分离卷积(
groups=conv_channels),提取局部空间特征,保持特征图尺寸不变; - 转回通道最后格式 ([B,H,W,C]);
- 门控融合:
- 对 (G) 执行GELU激活,生成非线性门控权重;
- 将 (I) 与 (C) 在通道维度拼接,得到融合特征(维度为 (hidden));
- 门控权重与融合特征逐元素相乘,实现动态特征选择;
- 降维与残差连接:
- 通过全连接层 (fc2) 将融合特征降维回原始通道数 (dim);
- 与原始输入 (X) 执行残差连接,得到最终输出 (Y),缓解梯度消失问题。
4.2.2 关键设计细节
- TokenMixer:采用7×7深度可分离卷积,替代Mamba的SSM,实现全可见的空间特征混合,避免因果模式的限制;
- 门控机制:通过GELU激活生成门控权重,动态筛选重要特征,弥补传统卷积缺乏选择性的短板;
- 通道扩展:默认扩展比例为 (8/3),在提升特征表达能力的同时控制计算量,避免过度升维导致的效率下降;
- 卷积分支比例:通过
conv_ratio控制卷积分支的通道数,可在精度与效率间灵活权衡(如conv_ratio=0.5可显著减少计算量)。
05 实验分析
5.1 ImageNet图像分类(核心验证)
- 实验设置:输入分辨率224×224,训练300 epochs,优化器AdamW,权重衰减0.05,学习率余弦退火;
- 性能对比:
模型 参数量 MACs Top-1精度 MambaOut-Small ~27M ~4.6G 84.1% LocalVMamba-S ~30M ~5.8G 83.7% VMamba-S ~29M ~5.2G 83.5% ConvNeXt-S ~35M ~4.5G 83.9% - MambaOut-Small在参数量更少的情况下,Top-1精度达到84.1%,比LocalVMamba-S高0.4%,计算量仅为后者的79%;
- 小规模模型MambaOut-Femto精度78.9%,优于同量级Vim-Ti(78.2%)、EfficientVMamba-T(78.5%);
- 结论:图像分类任务中,SSM不仅无增益,反而因因果性限制性能,完全不需要Mamba,卷积+门控结构更适配视觉任务。
5.2 COCO目标检测/实例分割
- 实验设置:以Mask R-CNN为检测框架,输入分辨率800×1280,在COCO train2017上训练,在val2017上测试;
- 性能对比:
模型 骨干网络 检测AP 分割AP MambaOut-Tiny MambaOut-Tiny 47.5 42.3 VMamba-T VMamba-T 48.9 43.4 LocalVMamba-T LocalVMamba-T 48.7 43.2 - MambaOut-Tiny的检测AP比VMamba-T低1.4,分割AP低1.1;
- 结论:长序列视觉任务中,SSM的线性复杂度优势得以体现,具有潜在研究价值,但当前视觉Mamba仍未达到卷积-注意力混合模型的最优性能。
5.3 ADE20K语义分割
- 实验设置:以UperNet为分割框架,输入分辨率512×2048,在ADE20K训练集上训练,在验证集上测试;
- 性能对比:
模型 骨干网络 单尺度mIoU 多尺度mIoU MambaOut-Tiny MambaOut-Tiny 45.2 46.1 LocalVMamba-T LocalVMamba-T 45.7 46.6 - LocalVMamba-T的单尺度/多尺度mIoU均比MambaOut-Tiny高0.5;
- 结论:与检测任务趋势一致,长序列视觉任务中SSM有潜在价值,但视觉Mamba仍需优化架构以适配视觉任务的全可见需求。
5.4 消融实验
- 卷积核大小:
- 3×3:精度83.2%,MACs~4.2G;
- 7×7:精度84.1%,MACs~4.6G;
- 9×9:精度84.2%,MACs~5.1G;
- 结论:7×7卷积核在精度与效率间最优,9×9卷积核精度提升有限但计算量显著增加。
- 通道扩展比例:
- 扩展比例2:精度83.7%,MACs~4.1G;
- 扩展比例8/3:精度84.1%,MACs~4.6G;
- 扩展比例3:精度84.3%,MACs~5.2G;
- 结论:
expension_ratio=8/3为最优值,兼顾精度与效率。
- 卷积分支比例:
conv_ratio=0.5:精度83.8%,MACs~3.8G;conv_ratio=0.75:精度84.0%,MACs~4.2G;conv_ratio=1.0:精度84.1%,MACs~4.6G;- 结论:
conv_ratio=1.0时精度最高,降低至0.5可显著减少计算量,精度损失可控(仅0.3%)。
06 个人声明
本文为作者对原论文《MambaOut: Do We Really Need Mamba for Vision?》的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表任何平台或机构立场。
如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)