结构方程中参数的解释
一、模型结构参数(最核心)
1. 路径结构(Inner Model / Path Matrix)
这是结构方程模型最关键的部分。
需要明确:
-
潜变量之间的因果关系
-
哪些变量是 外生变量(exogenous)
-
哪些变量是 内生变量(endogenous)
(1)外生变量(exogenous variable)=自变量
外生变量是指存在于模型外的变量,模型之外的变量决定其值,因此类似于自变量(independent variable,独立变量)。
(2)内生变量(endogenous variable)=因变量
内生变量是模型中的一个变量,内生变量是因变量(dependent variable,依赖变量),意味着其值取决于模型中的其他变量。
举例来说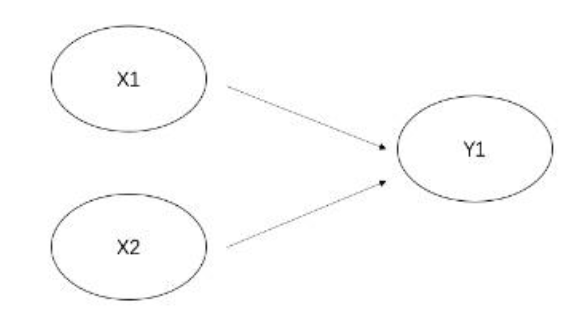
这里X1、X2就是外生变量,Y1是内生变量。如果x1和y1之间有个变量的话,该变量就是中介变量。
二、测量模型参数(Outer Model)
2. 指标类型(Mode A / Mode B)
PLS-PM中有两种测量模式:
| 模式 | 名称 | 适用情况 |
|---|---|---|
| Mode A | Reflective(反射型) | 指标受潜变量影响 |
| Mode B | Formative(形成型) | 指标共同形成潜变量 |
反射型(Mode A)指标之间通常 高度相关。例如生态学中的降水、温度、湿度
形成型(Mode B)指标之间可以 不相关。例如生态学中的人口密度、GDP和夜间灯光。
三、数据预处理参数
3. 数据标准化(Scaling)
PLS-PM一般需要:
scale = TRUE
原因:
不同变量单位不同,例如:
| 变量 | 单位 |
|---|---|
| 温度 | ℃ |
| 降水 | mm |
| NDVI | 无单位 |
标准化可以避免尺度影响。
四、算法参数
4. 权重计算方法(Scheme)
常见三种:
| 方法 | 说明 |
|---|---|
| centroid | 最常用 |
| factorial | 因子型 |
| path | 推荐 |
一般建议:
scheme = “path”
因为它考虑路径方向。
5. 最大迭代次数
例如:
maxiter = 100
注意:
如果模型复杂,建议
maxiter = 500
否则可能 不收敛。
PLS-PM本身没有传统SEM的显著性,需要Bootstrap。
6. Bootstrap次数
一般建议:
| 次数 | 可靠性 |
|---|---|
| 200 | 较低 |
| 500 | 一般 |
| 1000 | 推荐 |
| 5000 | 最好 |
六、模型评价指标(必须检查)
做完模型必须检查:
1 信度
| 指标 | 标准 |
|---|---|
| Cronbach α | >0.7 |
| Composite reliability | >0.7 |
2 收敛效度
| 指标 | 标准 |
|---|---|
| AVE | >0.5 |
| 外部载荷 | >0.7 |
3 判别效度
检查:
Fornell-Larcker
Cross loading
4 结构模型
| 指标 | 标准 |
|---|---|
| R² | >0.25 |
| Path coefficient | 显著 |
5.需要注意的点
1.潜变量至少大于3个指标
2.样本数 ≥ 10 × 最大指标数
3.形成型变量必须检查:VIF < 5

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)