小白从零开始勇闯人工智能:大模型API的调用
引言
人工智能大模型的能力通常通过API(应用程序编程接口)对外提供服务。刚接触大模型的初学者调用这些API时可能不知从何入手。本文将从零开始,带你完成账号注册、环境配置,并通过几个真实的Python代码案例,逐步掌握大模型API的各种玩法。
一、准备工作:账号与密钥
1、注册阿里云账号
访问阿里云官网完成注册。如果已有账号,直接登录即可。
2、开通阿里云百炼
进入阿里云百炼大模型服务平台,阅读并同意协议后自动开通。若提示实名认证,按指引完成认证。
3、获取API Key
在密钥管理页面点击“创建API Key”,复制保存(例如:sk-xxxxxxxx)。注意:API Key是调用模型的凭证,千万要保护好,不要泄露。
4、配置环境变量(推荐)
为避免在代码中硬编码API Key,建议将其设为环境变量。
Windows:在系统属性中添加环境变量DASHSCOPE_API_KEY,值为你的API Key。
macOS/Linux:在终端执行:
export DASHSCOPE_API_KEY="你的API Key"若要永久生效,可追加到~/.bashrc或~/.zshrc。
验证是否成功:
echo $DASHSCOPE_API_KEY # macOS/Linux
echo %DASHSCOPE_API_KEY% # Windows CMD二、搭建Python环境
1、安装Python(3.9或以上)
在终端检查Python版本:
python --version若未安装或版本过低,前往Python官网下载安装。

2、安装OpenAI Python SDK
阿里云百炼提供了兼容OpenAI格式的接口,因此我们安装openai库:
pip install -U openai三、第一个API调用:你好,千问!
新建文件hello_qwen.py,写入以下代码:
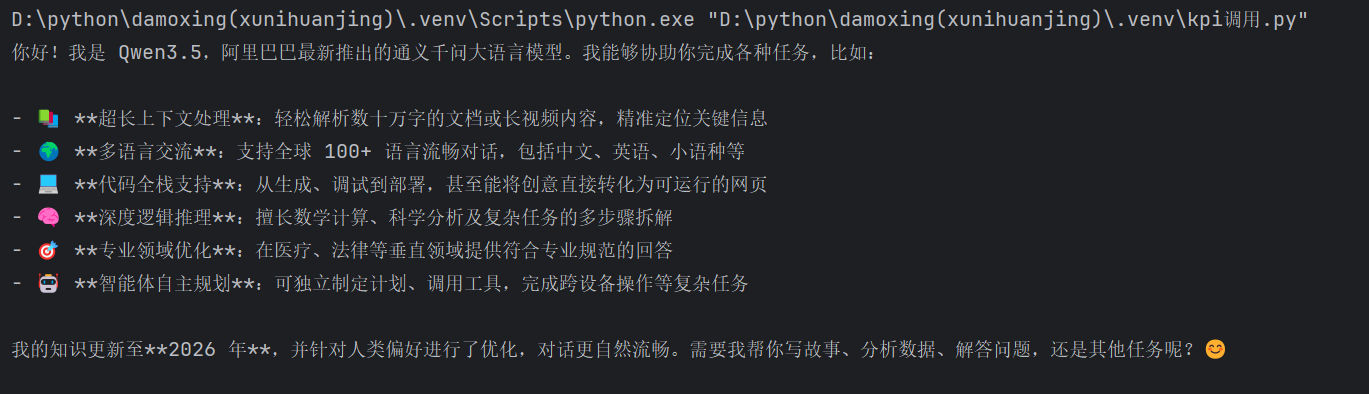
在新建的py文件中,首先导入os和OpenAI库,接着创建OpenAI客户端,其中api_key从环境变量DASHSCOPE_API_KEY读取,base_url指定为阿里云百炼的兼容OpenAI接口接入点,然后使用client.chat.completions.create方法,选择qwen-plus模型,传入包含用户消息“你是谁?”的messages列表,最后打印返回结果中的回复内容。
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量读取
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 北京地域接入点
)
completion = client.chat.completions.create(
model="qwen-plus",
messages=[{'role': 'user', 'content': '你是谁?'}]
)
print(completion.choices[0].message.content)其中OpenAI客户端需指定api_key和base_url(阿里云百炼兼容OpenAI接口),model选择qwen-plus(也可换其他模型,如qwen-max),messages是对话历史,这里只有一条用户消息,返回的completion.choices[0].message.content即模型回复。
四、进阶技巧:让模型按你的要求输出
1、少样本学习(Few-shot)——教会模型格式
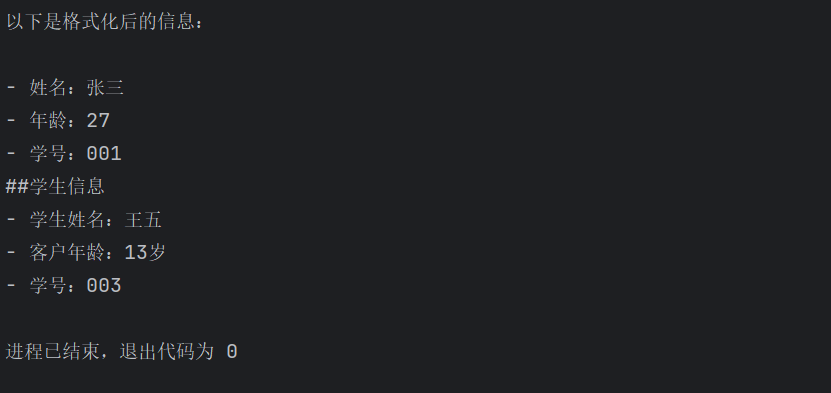
通过少样本学习让模型掌握固定格式输出。无示例时,模型对信息自由格式输出,结果不统一,提供几个示例(如将姓名、年龄、学号格式化为带标题的列表)后,模型学会模仿示例格式,为新信息生成结构化回复。其原理是在阿里云千问模型的messages列表中交替传入用户请求和助手示例,构建输入输出对,使模型从上下文中理解期望的格式,适用于需要规范输出的任务,如信息抽取和模板化生成。
from openai import OpenAI
client = OpenAI(api_key="sk-xxx", base_url="...")
# 无示例(自由发挥)
response = client.chat.completions.create(
model="qwen-plus",
messages=[{"role": "user", "content": "格式化以下信息:\n姓名 -> 张三\n年龄 -> 27\n学号 -> 001"}]
)
print(response.choices[0].message.content)
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{"role": "user", "content": "格式化以下信息:\n姓名 -> 张三\n年龄 -> 17\n学号 -> 001"},
{"role": "assistant", "content": "##学生信息\n- 学生姓名:张三\n- 客户年龄:17岁\n- 学号:001"},
{"role": "user", "content": "格式化以下信息:\n姓名 -> 李四\n年龄 -> 12\n学号 -> 002"},
{"role": "assistant", "content": "##学生信息\n- 学生姓名:李四\n- 客户年龄:12岁\n- 学号:002"},
{"role": "user", "content": "格式化以下信息:\n姓名 -> 王五\n年龄 -> 13\n学号 -> 003"}
]
)
print(response.choices[0].message.content)
2、调整参数控制多样性
frequency_penalty参数对生成文本词汇重复度的会产生一定的影响。该参数取值范围为[-2,2],正值可减少重复,使输出更多样化,负值则鼓励重复,可能导致内容单调。例如设置-2时,生成的电影清单句式可能大量重复,设为2时,词汇和表达则更加丰富。通过调节此参数,并结合temperature等,可以有效控制模型输出的风格和多样性。
# frequency_penalty = -2(鼓励重复,生成内容可能更单调)
response = client.chat.completions.create(
model="qwen-plus",
messages=[{"role": "user", "content": "生成一个豆瓣高分电影清单,至少20部..."}],
max_tokens=300,
frequency_penalty=-2
)
# 输出可能有很多重复句式
# frequency_penalty = 2(惩罚重复,生成内容更多样)
response = client.chat.completions.create(
model="qwen-plus",
messages=[{"role": "user", "content": "生成一个豆瓣高分电影清单,至少20部..."}],
max_tokens=300,
frequency_penalty=2
)

3、结构化输出:获取JSON格式
通过结构化输出提示词让模型生成纯JSON格式数据。用户构造提示词,要求生成包含三个学生信息的JSON列表,每个元素包含student_number、student_name、student_marks、phone字段,且均为字符串,并明确禁止输出任何额外文本。调用qwen-plus模型后,获取返回的content字符串,使用json.loads直接解析为Python列表,进而可以访问具体数据如第一个学生的姓名。关键是在提示词中强调仅输出JSON,可以避免混入解释性文字。
import json
prompt = """
生成一个由三个学生考试分数信息所组成的列表,以JSON格式进行返回。
JSON列表里的每个元素包含以下信息:student_number、student_name、student_marks、phone。
所有信息都是字符串。除了JSON之外,不要输出任何额外的文本。
"""
response = client.chat.completions.create(
model="qwen-plus",
messages=[{"role": "user", "content": prompt}]
)
content = response.choices[0].message.content
print(content) # 可能是一个JSON字符串
data = json.loads(content) # 解析为Python列表
print(data[0]["student_name"]) # 访问第一个学生的姓名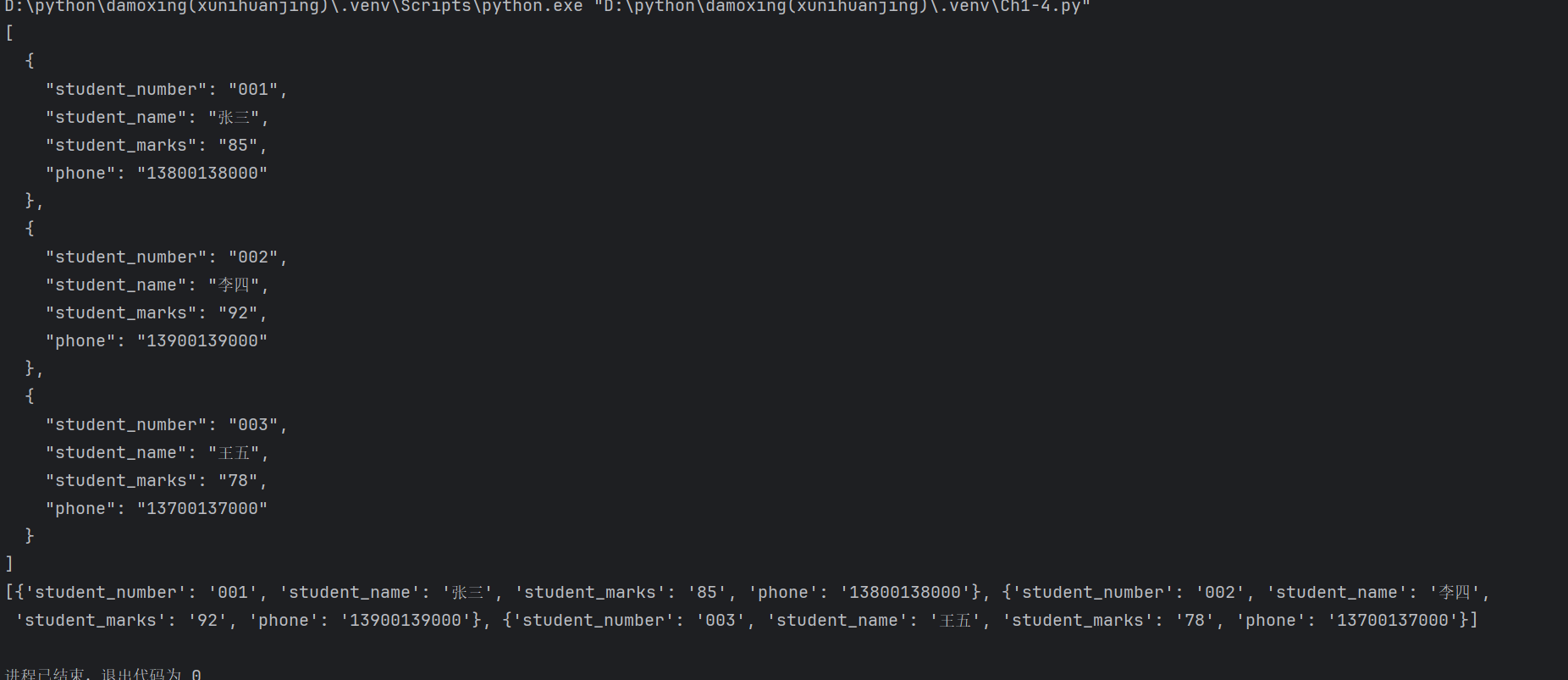
4、思维链(Chain of Thought)——让模型学会推理
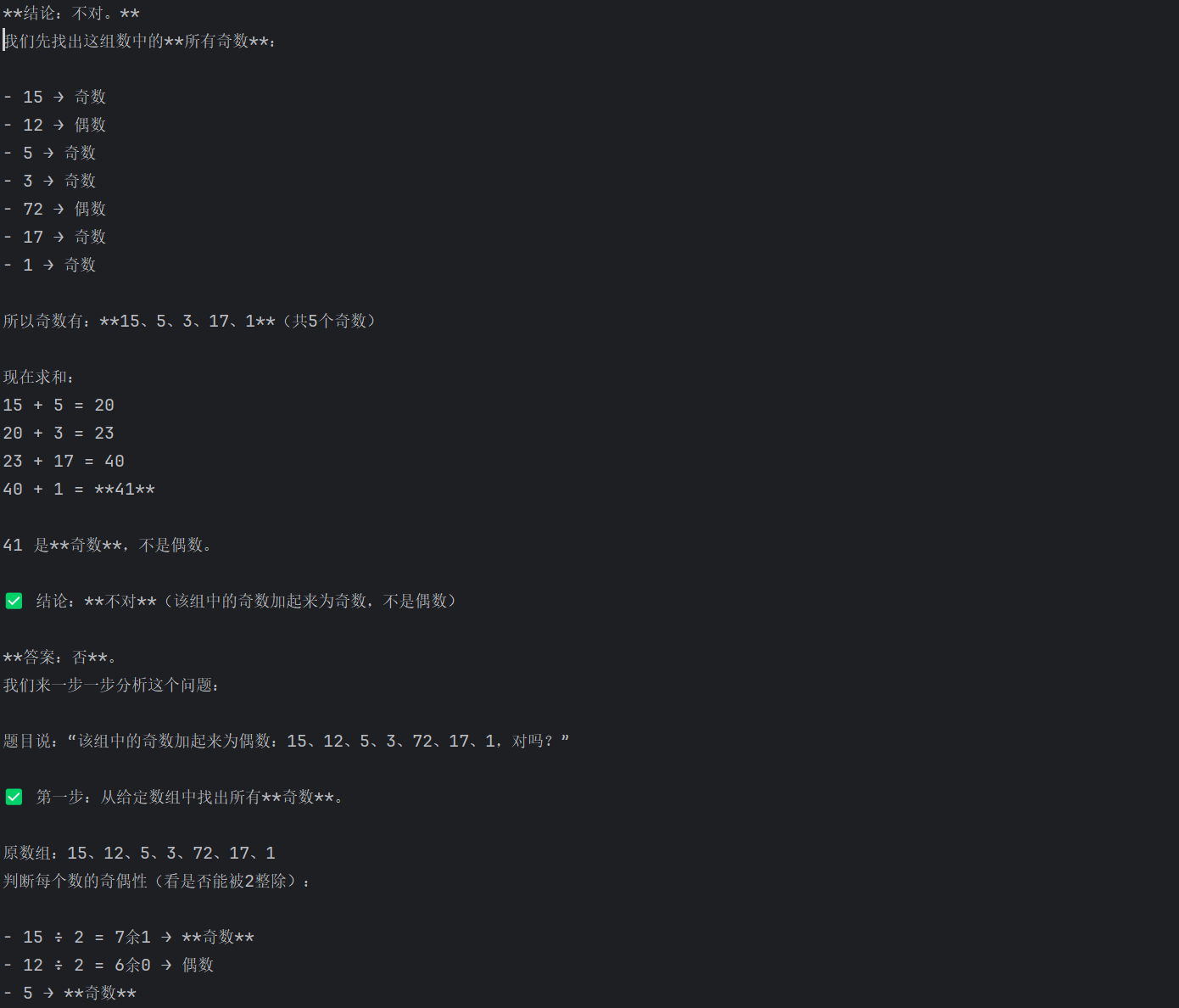
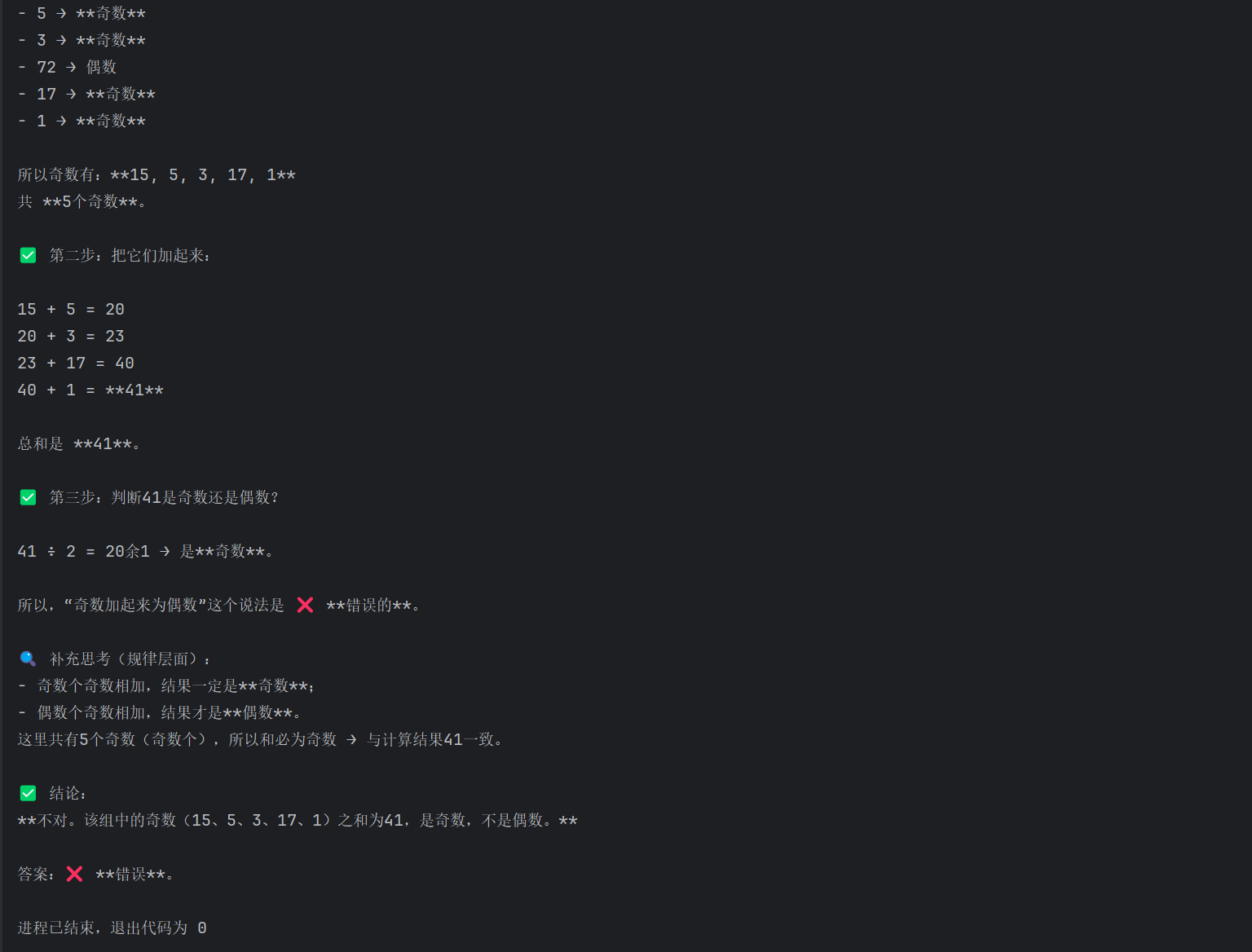
我们可以通过两种方式引导模型进行逻辑推理:第一种是使用包含推理步骤的少样本示例,在messages中交替用户问题和助手答案,让模型学会先识别奇数、再计算和、最后得出结论,第二种是直接在提示词末尾添加“让我们来分步骤思考”,触发模型内置的推理能力。两种方法都能使模型输出结构化的分步推理过程,而不是直接猜测结果,从而提升回答的准确性和可解释性。
from openai import OpenAI
client = OpenAI(api_key="******",
base_url="******")
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{
"role": "user",
"content": "该组中的奇数加起来为偶数:1、2、3、4、5、6、7,对吗?"
},
{
"role": "assistant",
"content": "所有奇数相加等于16。答案为是。"
},
{
"role": "user",
"content": "该组中的奇数加起来为偶数:17、10、19、4、8、12、24、3,对吗?"
},
{
"role": "assistant",
"content": "所有奇数相加等于39。答案为否。"
},
{
"role": "user",
"content": "该组中的奇数加起来为偶数:15、12、5、3、72、17、1,对吗?"
},
]
)
print(response.choices[0].message.content)
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{
"role": "user",
"content": "该组中的奇数加起来为偶数:4、8、9、15、12、2、1,对吗?"
},
{
"role": "assistant",
"content": "所有奇数(9、15、1)相加,9 + 15 + 1 = 25。答案为否。"
},
{
"role": "user",
"content": "该组中的奇数加起来为偶数:17、10、19、4、8、12、24,对吗?"
},
{
"role": "assistant",
"content": "所有奇数(17、19)相加,17 + 19 = 36。答案为是。"
},
{
"role": "user",
"content": "该组中的奇数加起来为偶数:15、12、5、3、72、17、1,对吗?"
},
]
)
print(response.choices[0].message.content)
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{
"role": "user",
"content": "该组中的奇数加起来为偶数:15、12、5、3、72、17、1,对吗?让我们来分步骤思考。" #只需要加上分步骤思考的提示,就可分步骤进行推理。推理模型已经实现。
},
]
)
print(response.choices[0].message.content)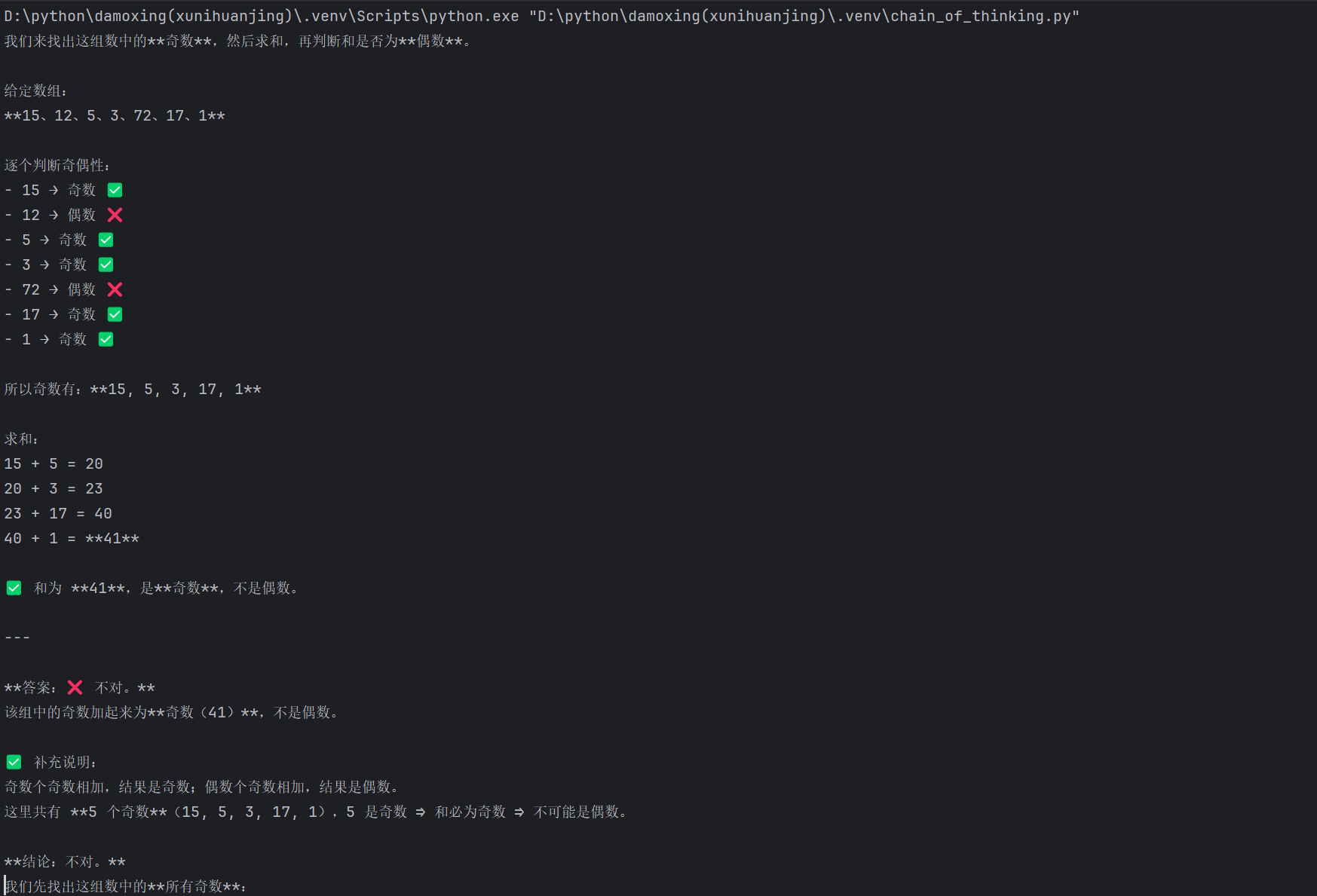

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)