推理引擎系列(三)《从大模型推理到 AI 对话》
目录
基于Transformer的开源大语言模型——DeepSeek
本文将深入解析大模型推理的核心流程,从 token 概率分布到文本生成,从 KV Cache 优化到采样策略。前置课程为《大模型原理与结构》,感兴趣可以先行预习。
大模型推理的基本流程
1. 输入到输出的完整路径
大模型推理的核心任务是文本生成,其基本流程如下:
-
• Tokenizer:将输入文本转换为 token 序列
-
• Embedding:将 token 转换为向量表示
-
• Transformer 计算:通过多层注意力机制和前馈网络进行计算
-
• 概率分布输出:模型输出下一个 token 的概率分布
-
• 采样选择:根据概率分布选择下一个 token
-
• 循环生成:将新 token 加入输入,重复上述过程直至结束

2. 关键洞察:概率分布的本质
大模型并不会直接输出确定的文本,而是输出下一个 token 的概率分布。这种概率化的输出方式使得模型能够保持一定的创造性和多样性。
推理优化:KV Cache技术
1. 重复计算的问题
在基础的自回归生成过程中,每生成一个新 token 都需要重新计算所有历史 token 的注意力权重,这导致了大量的重复计算。
2. KV Cache 解决方案
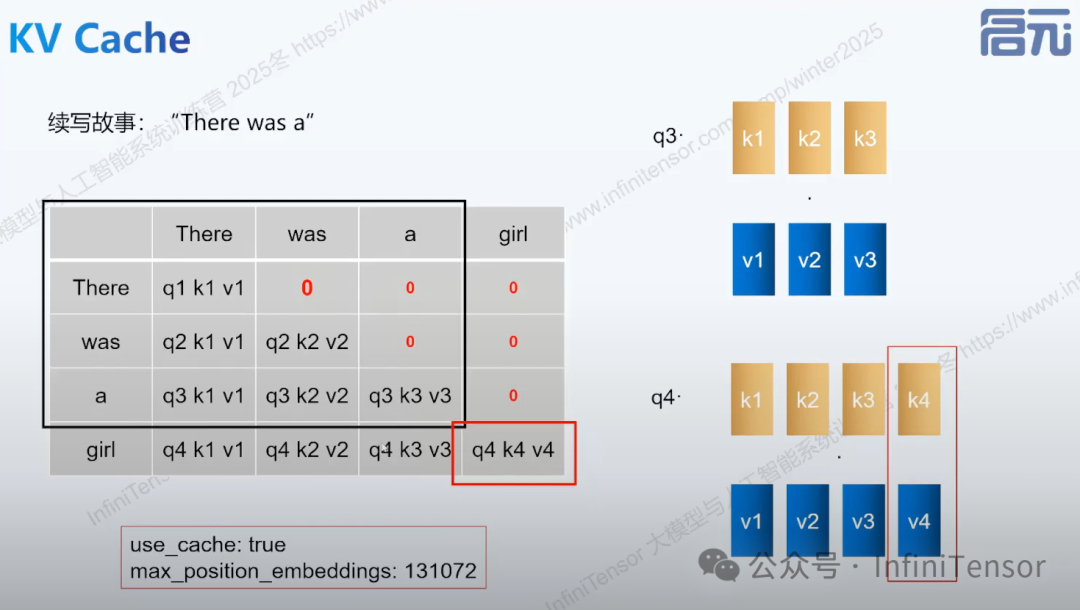
KV Cache(键值缓存)是大模型推理中的关键技术:
-
• 核心思想:缓存历史 token 的 Key 和 Value 向量
-
• 工作原理:生成新 token 时,只需计算当前 token 的 Q、K、V,然后与缓存的历史 K、V 进行注意力计算
-
• 性能优势:显著减少重复计算,提升推理速度
推理阶段划分:Prefill vs Decode
1. Prefill 阶段(预填充)
-
• 触发时机:接收到用户输入时
-
• 计算特点:一次性处理所有输入 token
-
• 资源消耗:计算密集型 (Compute-bound)
-
• 类比:老师阅读学生提出的问题
2. Decode 阶段(解码)
-
• 触发时机:开始生成回复后
-
• 计算特点:逐个生成 token,利用 KV Cache
-
• 资源消耗:访存密集型 (Memory-bound)
-
• 类比:老师基于问题逐步组织回答
3. PD 分离优化
由于 Prefill 和 Decode 阶段的计算特性不同,现代推理引擎常采用 PD分离(Prefill-Decode Separation)策略:
-
• 使用不同的硬件资源处理两个阶段
-
• 针对各自特点进行专门优化
-
• 提升整体推理效率
AI 对话的实现机制
1. 角色标记(Role Tagging)
AI 对话系统的核心是带身份信息的文本生成:
<|user|>请给我讲一个故事
<|assistant|>从前有一个小女孩...通过角色标记符合训练时的 Prompt Template(提示词模板),引导模型激活对应的生成模式

2. 模板引擎的应用
为了正确处理对话格式,现代 AI 系统广泛使用 Jinja2 模板引擎:
-
• 定义对话模板格式
-
• 自动插入角色标记
-
• 构造符合模型预期的输入文本格式
这种设计使得前端能够清晰区分用户输入和 AI 回复,提供更好的用户体验。
文本生成的采样策略
1. Argmax 采样
-
• 策略:始终选择概率最高的 token
-
• 特点:结果确定但缺乏多样性
-
• 问题:生成内容过于死板,缺乏创意

2. 随机采样
-
• 策略:根据概率分布随机选择 token
-
• 特点:保持多样性但可能产生不合理内容
-
• 风险:小概率事件累积可能导致语义错误
-
• 改进策略:
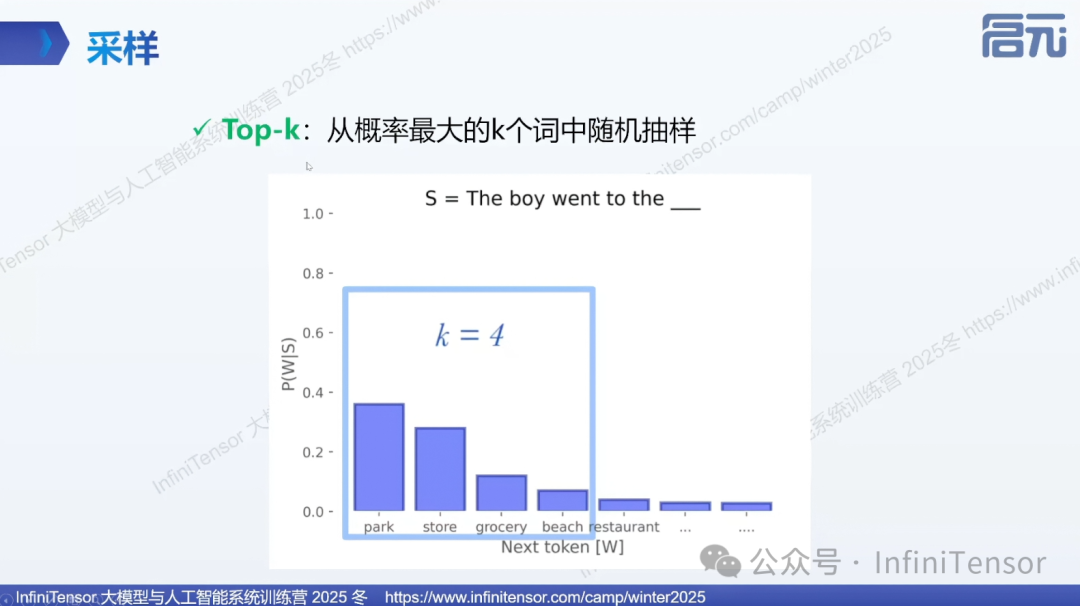
①Top-K 采样: 从概率最高的 K 个 token 中随机选择,平衡多样性和合理性
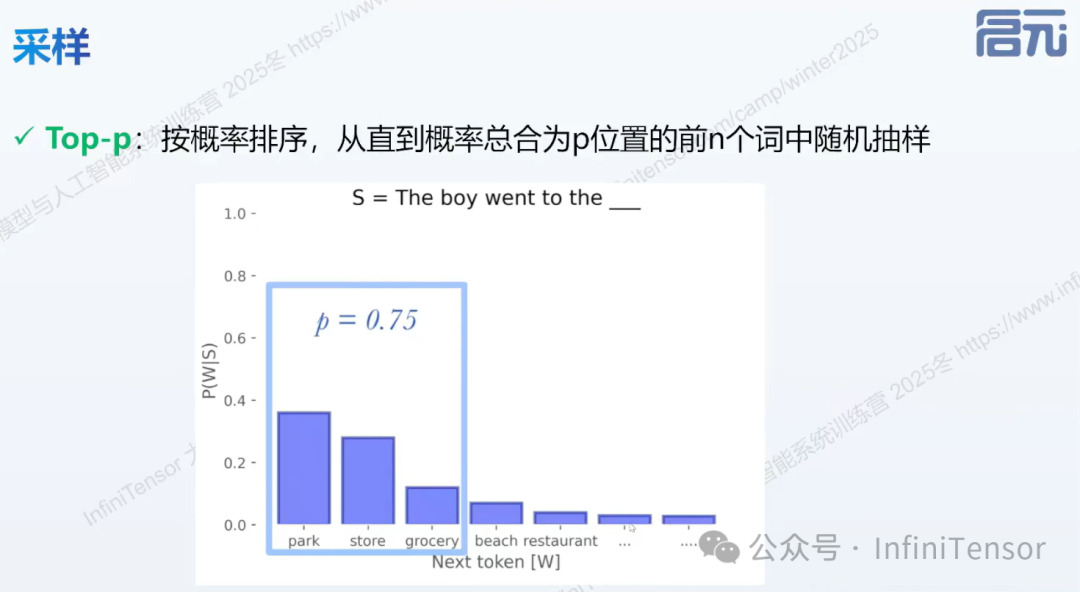
②Top-P采样: 从累积概率达到 P 的最小 token 集合中随机选择,动态调整候选集大小,适应不同上下文
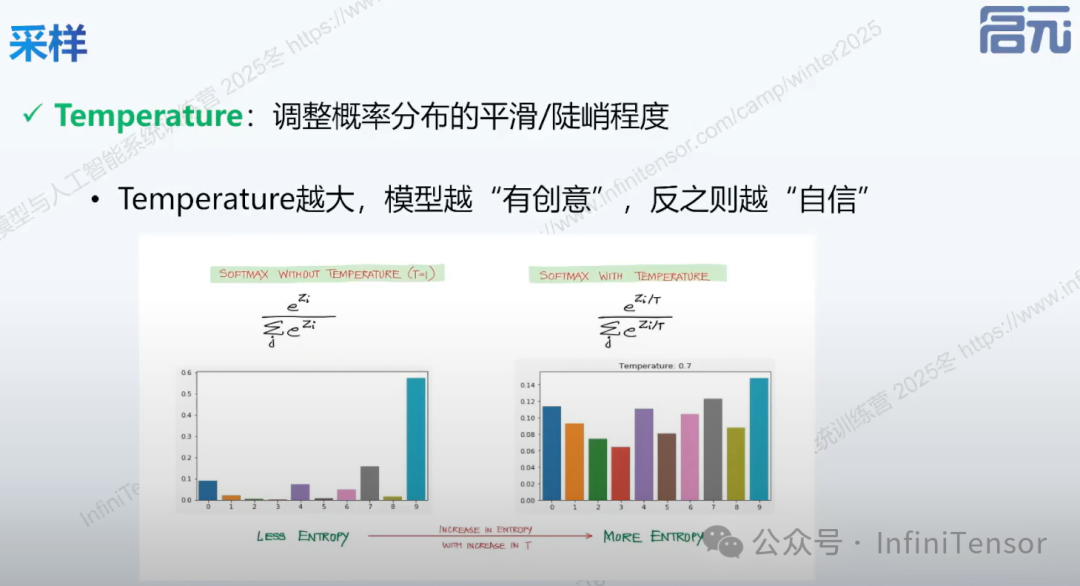
3. Temperature 调节
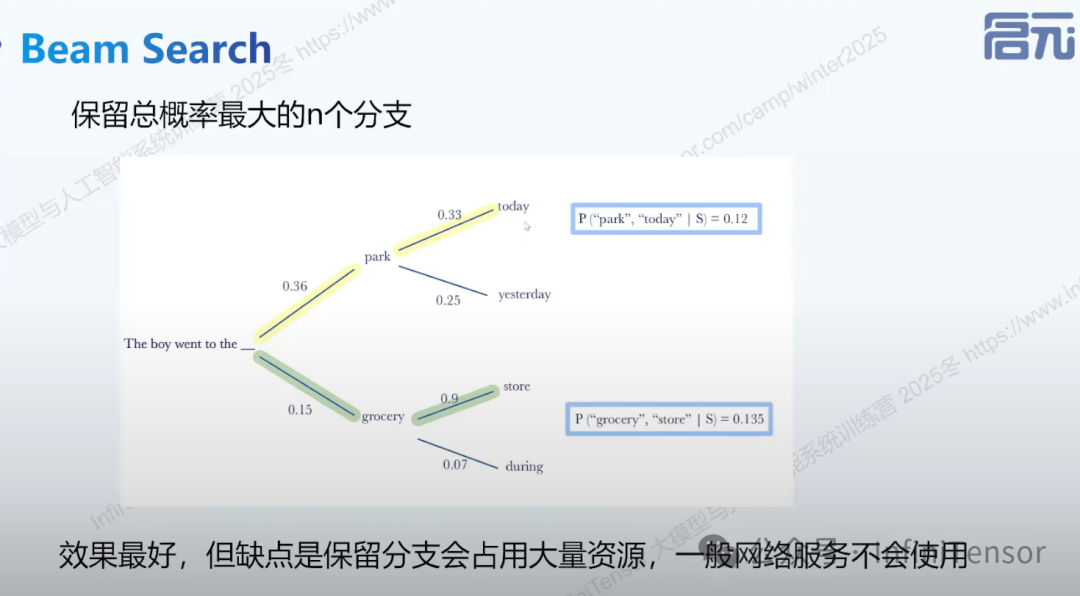
4. Beam Search
-
• 更适用于翻译、摘要等确定性较强的任务
基于Transformer的开源大语言模型——DeepSeek
-
• DeepSeek-V3
-
• DeepSeek-R1
-
• DeepSeek-VL2

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)