基于一维卷积神经网络(1D-CNN)的多变量回归预测模型MATLAB完整代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。
🍎 往期回顾关注个人主页:Matlab科研工作室
👇 关注我领取海量matlab电子书和数学建模资料
🍊个人信条:格物致知,完整Matlab代码获取及仿真咨询内容私信。
🔥 内容介绍
一、背景
(一)多变量回归预测的需求
在众多领域,如气象学、经济学、工程学等,常常需要对多个变量进行回归预测。例如,在气象预测中,不仅要预测温度,还需考虑湿度、气压、风速等多个变量,以更全面准确地预报天气状况;在金融领域,预测股票价格时,除了历史价格数据,还需综合考虑宏观经济指标、公司财务数据等多种变量。多变量回归预测旨在建立一个模型,通过对多个相关变量的分析,预测目标变量的数值,为决策制定提供重要依据。
(二)传统方法的局限性
传统的多变量回归预测方法,如线性回归、岭回归、Lasso 回归等,基于线性假设构建模型。然而,实际中的许多问题具有高度的非线性特征,变量之间的关系复杂且难以用简单的线性方程描述。例如,在生态环境研究中,物种多样性与多种环境因素(如温度、降水、土壤成分等)之间的关系可能是非线性的,传统线性回归方法难以准确捕捉这些复杂关系,导致预测精度受限。此外,传统方法在处理高维数据时,容易出现过拟合、计算复杂度高等问题。
(三)1D - CNN 的优势
一维卷积神经网络(1D - CNN)作为深度学习的一种重要模型,在处理序列数据和多变量回归预测方面具有显著优势。1D - CNN 能够自动学习数据中的特征模式,无需手动提取特征,尤其擅长捕捉序列数据中的局部相关性。对于多变量回归预测问题,它可以有效地处理多个变量的时间序列数据,通过卷积操作挖掘变量之间复杂的非线性关系。同时,1D-CNN 具有较强的泛化能力,能够在一定程度上避免过拟合,适用于各种复杂的多变量回归预测任务。
二、原理

(二)基于 1D - CNN 的多变量回归预测模型构建
-
数据准备:收集与多变量回归预测相关的数据集,确保数据包含多个自变量和对应的目标变量。对数据进行预处理,包括数据清洗(去除异常值、填补缺失值)、归一化(将数据映射到相同的尺度范围,如 [0,1] 或 [−1,1])等操作,以提高模型的训练效果。将数据集划分为训练集、验证集和测试集,其中训练集用于模型的训练,验证集用于调整模型参数和防止过拟合,测试集用于评估模型的最终性能。
-
模型搭建:根据具体问题的特点和需求,设计 1D - CNN 模型的结构。确定卷积层的数量、卷积核大小、步长,池化层的类型和窗口大小,以及全连接层的神经元数量等参数。例如,对于具有复杂时间序列特征的多变量数据,可以增加卷积层的数量和深度,以更好地提取特征;对于数据维度较高的情况,可以适当调整池化窗口大小,有效降低维度。在搭建模型时,还可以考虑添加一些正则化方法,如 Dropout,以防止过拟合。
-

⛳️ 运行结果
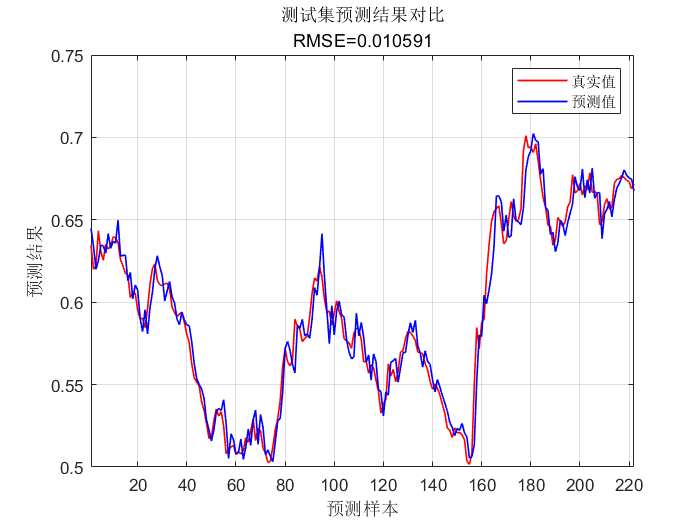
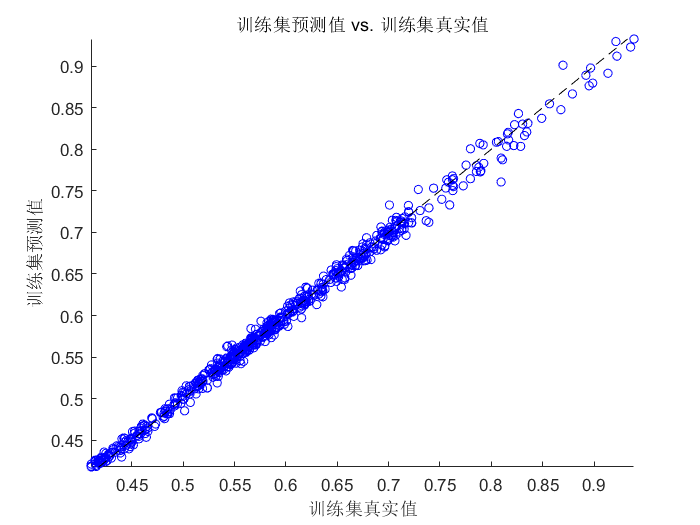
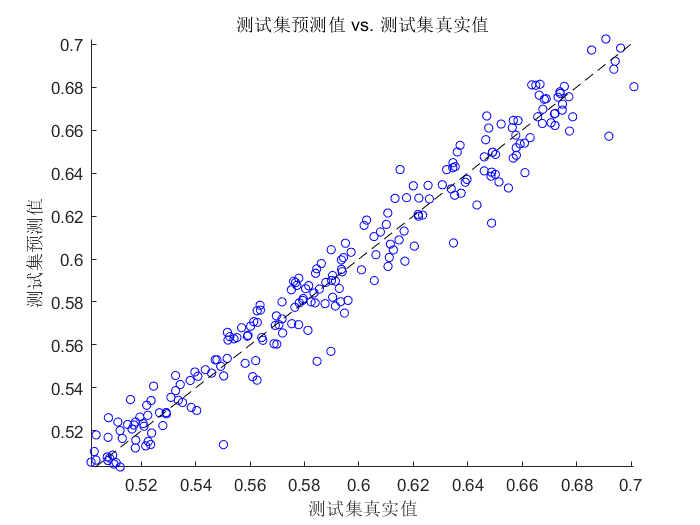
📣 部分代码
%% 导入数据(时间序列的单列数据)
result = xlsread('数据集.xlsx');
%% 数据分析
num_samples = length(result); % 样本个数
kim = 15; % 延时步长(kim个历史数据作为自变量)
zim = 1; % 跨zim个时间点进行预测
%% 划分数据集
for i = 1: num_samples - kim - zim + 1
res(i, :) = [reshape(result(i: i + kim - 1), 1, kim), result(i + kim + zim - 1)];
end
%% 划分训练集和测试集
temp = 1: 1: 922;
P_train = res(temp(1: 700), 1: 15)';
T_train = res(temp(1: 700), 16)';
M = size(P_train, 2);
🔗 参考文献
🍅往期回顾扫扫下方二维码

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)