使用适配器将Bedrock转换为OpenAI兼容服务并支持Tool Calling
Bedrock 提供了多个强大的 AI 模型(如 Kimi、DeepSeek、Qwen 等),但其 API 格式与 OpenAI 不兼容。许多工具(如 qwencode)使用 OpenAI 的 API 格式,特别是依赖 Tool Calling(函数调用)功能。
此前在尝试使用litellm将bedrock模型接入opencode,qwencode,claudecode等cli工具过程中发现诸多问题,比如JSON序列化问题,Tool调用不支持问题,但是由于litellm等工具颇为复杂,我个人的需求仅仅是希望使用bedrock上的模型来接入code cli工具,因此参考litellm和bedrock-access-gateway等项目编写一个适配器将 Bedrock 的 Converse API 转换为 OpenAI 兼容格式。在此过程中也对Tool Calling的意义了解更加深入。
在Hiclaw中注册的效果如下
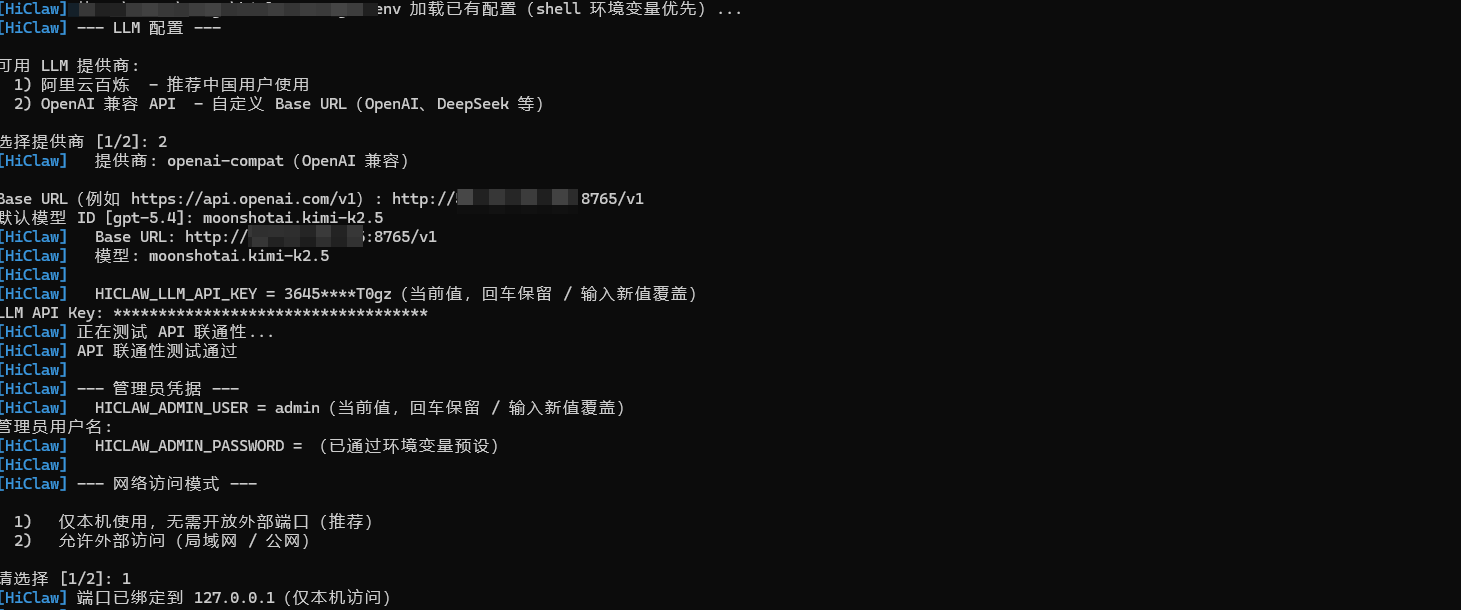
对话效果
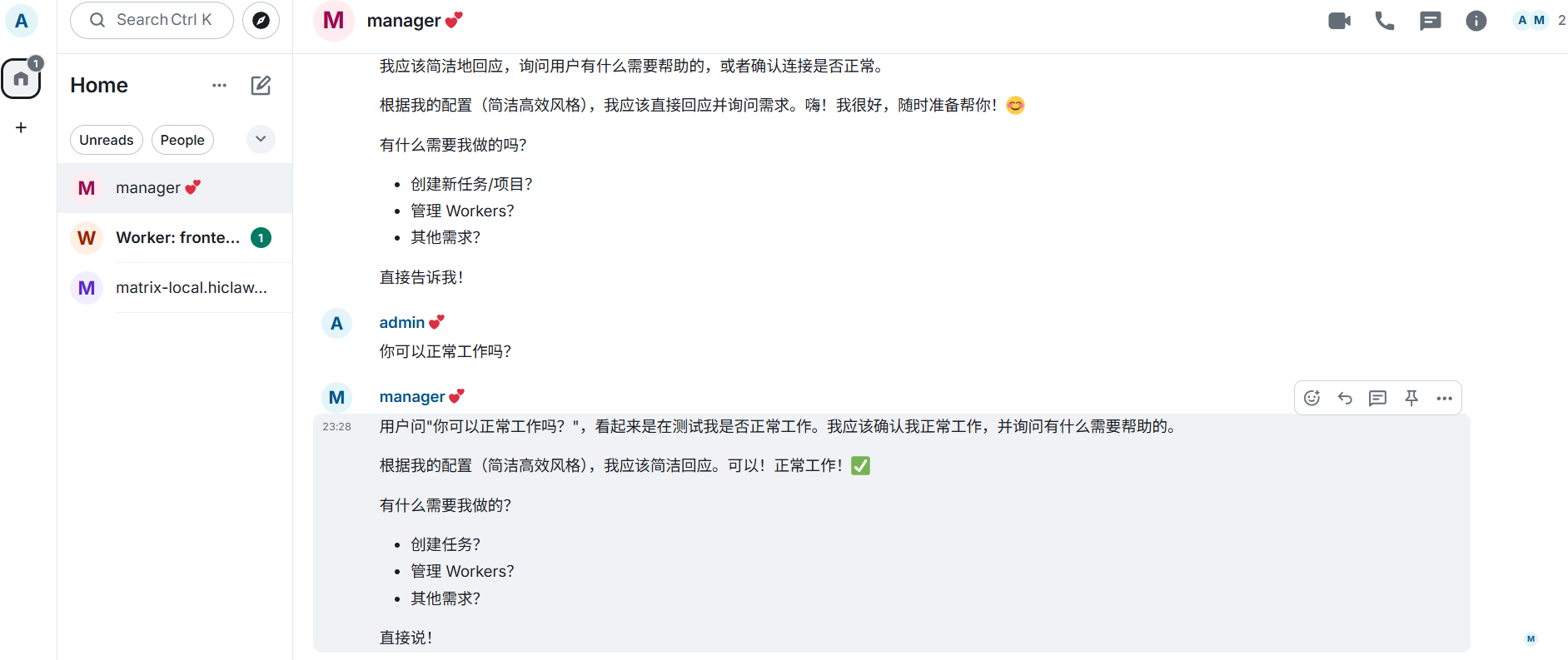
后记,在后续使用中发现bedrock在龙虾类产品中会突然停止输出,因为收到了来自模型的空输入,可能还得再修一修
要解决的问题
市面上已有一些类似的工具,但它们都存在一些问题,例如LiteLLM 在 Bedrock Tool Calling 上存在缺陷
LiteLLM 没有正确处理 Bedrock 的"连续同角色消息必须合并"规则。实际测试中发现:
# qwencode 发送的消息序列
messages = [
{"role": "user", "content": "创建文件"},
{"role": "assistant", "tool_calls": [...]},
{"role": "tool", "content": "成功"},
{"role": "tool", "content": "成功"} # 连续两个 tool 消息
]
LiteLLM 直接转换为:
# 错误:连续两个 user 角色
[
{"role": "user", "content": [...]},
{"role": "assistant", "content": [...]},
{"role": "user", "content": [{"toolResult": ...}]},
{"role": "user", "content": [{"toolResult": ...}]} # ❌ Bedrock 拒绝
]
Bedrock 返回错误:
ValidationException: Messages must alternate between user and assistant roles
此外LiteLLM 在某些版本中将 tool 角色错误地转换为普通文本消息,而不是 toolResult 结构:
# LiteLLM 的错误转换
{"role": "user", "content": [{"text": "工具执行结果"}]} # ❌
# 正确的转换
{"role": "user", "content": [
{"toolResult": {"toolUseId": "...", "content": [{"text": "..."}]}}
]} # ✓
这导致模型无法理解这是工具执行结果,Tool Calling 循环中断。
为了支持 100+ 模型,LiteLLM 的代码高度抽象:
- 核心转换逻辑分散在多个文件中
- 大量的 if-else 判断不同模型的特殊情况
- 调试困难,错误堆栈深达 20+ 层
对于只需要 Bedrock 的场景,这些依赖完全是浪费。
bedrock-access-gateway 的问题是 AWS 社区的一个专门为 Bedrock 设计的网关项目,但也有局限
模型硬编码
# bedrock-access-gateway 的模型配置
SUPPORTED_MODELS = {
"claude-3-sonnet": "anthropic.claude-3-sonnet-20240229-v1:0",
"claude-3-haiku": "anthropic.claude-3-haiku-20240307-v1:0",
}
如果要使用 Kimi、DeepSeek 等新模型,需要修改源码并重新部署。
缺少流式支持
bedrock-access-gateway 只支持非流式响应,对于长文本生成场景体验很差:
# 只支持这种方式
response = bedrock.converse(...) # 等待完整响应
# 不支持流式
response = bedrock.converse_stream(...) # ❌ 未实现
配置复杂
需要配置文件、环境变量、IAM 角色等多个层面:
# config.yaml
models:
- id: claude-3-sonnet
bedrock_id: anthropic.claude-3-sonnet-20240229-v1:0
region: us-east-1
auth:
type: iam_role
role_arn: arn:aws:iam::...
对于简单的本地开发场景,这些配置过于繁琐。
编写适配器的核心挑战有如下几点
(1)消息格式差异
OpenAI 格式:
{
"role": "assistant",
"content": "我来帮你",
"tool_calls": [{
"id": "call_123",
"type": "function",
"function": {"name": "write_file", "arguments": "{...}"}
}]
}
Bedrock 格式:
{
"role": "assistant",
"content": [
{"text": "我来帮你"},
{"toolUse": {"toolUseId": "call_123", "name": "write_file", "input": {...}}}
]
}
(2)Tool Result 格式差异
OpenAI使用 tool 角色
{"role": "tool", "tool_call_id": "call_123", "content": "成功"}
Bedrock使用 user 角色 + toolResult
{
"role": "user",
"content": [{"toolResult": {"toolUseId": "call_123", "content": [{"text": "成功"}]}}]
}
此外Bedrock 不允许连续的同角色消息,必须合并。
核心转换函数
def convert_to_bedrock(messages):
"""OpenAI -> Bedrock"""
system = ""
bedrock_messages = []
for msg in messages:
role = msg["role"]
content = msg.get("content", "")
# 提取 system
if role == "system":
system = content
continue
# 处理 assistant 消息
if role == "assistant":
bedrock_content = []
# 添加文本内容
if content:
bedrock_content.append({"text": content})
# 转换 tool_calls
if "tool_calls" in msg:
for tc in msg["tool_calls"]:
bedrock_content.append({
"toolUse": {
"toolUseId": tc["id"],
"name": tc["function"]["name"],
"input": json.loads(tc["function"]["arguments"])
}
})
bedrock_messages.append({"role": "assistant", "content": bedrock_content})
# 处理 tool 角色 -> user + toolResult
elif role == "tool":
bedrock_messages.append({
"role": "user",
"content": [{
"toolResult": {
"toolUseId": msg["tool_call_id"],
"content": [{"text": content}]
}
}]
})
# 处理 user 消息
else:
bedrock_messages.append({
"role": "user",
"content": [{"text": content}]
})
return system, bedrock_messages
消息合并
def merge_messages(messages):
"""合并连续同角色消息"""
if not messages:
return []
merged = []
current = messages[0]
for msg in messages[1:]:
if msg["role"] == current["role"]:
# 合并 content
current["content"].extend(msg["content"])
else:
merged.append(current)
current = msg
merged.append(current)
return merged
反向转换
def convert_from_bedrock(response, model):
"""Bedrock -> OpenAI"""
message = response["output"]["message"]
content_blocks = message.get("content", [])
# 提取文本和 toolUse
text_parts = []
tool_calls = []
for block in content_blocks:
if "text" in block:
text_parts.append(block["text"])
elif "toolUse" in block:
tool_use = block["toolUse"]
tool_calls.append({
"id": tool_use["toolUseId"],
"type": "function",
"function": {
"name": tool_use["name"],
"arguments": json.dumps(tool_use["input"])
}
})
# 构造 OpenAI 格式响应
choice = {
"index": 0,
"message": {
"role": "assistant",
"content": "".join(text_parts) or None
},
"finish_reason": response.get("stopReason", "stop")
}
if tool_calls:
choice["message"]["tool_calls"] = tool_calls
return {
"id": f"chatcmpl-{uuid.uuid4().hex[:8]}",
"object": "chat.completion",
"created": int(time.time()),
"model": model,
"choices": [choice],
"usage": {
"prompt_tokens": response["usage"]["inputTokens"],
"completion_tokens": response["usage"]["outputTokens"],
"total_tokens": response["usage"]["totalTokens"]
}
}
Tools 配置转换
# OpenAI tools -> Bedrock toolConfig
if tools:
kwargs["toolConfig"] = {
"tools": [{
"toolSpec": {
"name": tool["function"]["name"],
"description": tool["function"].get("description", ""),
"inputSchema": {"json": tool["function"].get("parameters", {})}
}
} for tool in tools if tool.get("type") == "function"]
}
模型兼容性
测试了 80+ Bedrock 模型的 Tool Calling 支持,发现如下模型完全支持转换
moonshotai.kimi-k2.5- Kimi K2.5deepseek.v3.2- DeepSeek V3.2qwen.qwen3-coder-next- Qwen3 Coderamazon.nova-pro-v1:0- Amazon Nova Promistral.mistral-large-3-675b-instruct- Mistral Large
比较特殊的是zai.glm-4.7 - 只能发起工具调用,但不支持接收 toolResult
完整内容
完整adapter内容如下
from fastapi import FastAPI, Request, HTTPException, Header
from fastapi.responses import StreamingResponse, JSONResponse
import boto3
import json
import time
import uuid
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
app = FastAPI()
session = boto3.Session(profile_name='global', region_name='us-east-1')
bedrock = session.client('bedrock-runtime')
API_KEY = "sk-7f9a2xxxxxb9c2d4a6f8e1b"
def convert_to_bedrock(messages):
"""Convert OpenAI to Bedrock - based on bedrock-access-gateway"""
system = ""
bedrock_messages = []
for msg in messages:
role = msg["role"]
content = msg.get("content", "")
if role == "system":
system = content if isinstance(content, str) else ""
elif role == "tool":
tool_call_id = msg.get("tool_call_id", "")
if isinstance(content, list):
content = "\n".join([item.get("text", str(item)) if isinstance(item, dict) else str(item) for item in content])
bedrock_messages.append({
"role": "user",
"content": [{"toolResult": {"toolUseId": tool_call_id, "content": [{"text": str(content)}]}}]
})
elif role == "assistant":
has_content = content and (isinstance(content, str) and content.strip() or isinstance(content, list) and len(content) > 0)
if has_content:
if isinstance(content, list):
content = "\n".join([item.get("text", str(item)) if isinstance(item, dict) else str(item) for item in content])
bedrock_messages.append({"role": "assistant", "content": [{"text": str(content)}]})
for tc in msg.get("tool_calls", []):
bedrock_messages.append({
"role": "assistant",
"content": [{"toolUse": {
"toolUseId": tc["id"],
"name": tc["function"]["name"],
"input": json.loads(tc["function"]["arguments"]) if tc["function"]["arguments"] else {}
}}]
})
else: # user
if isinstance(content, list):
content = "\n".join([item.get("text", str(item)) if isinstance(item, dict) else str(item) for item in content])
if content:
bedrock_messages.append({"role": role, "content": [{"text": str(content)}]})
return system, bedrock_messages
def merge_messages(messages):
"""Merge consecutive same-role messages"""
if not messages:
return messages
result = []
for msg in messages:
if result and result[-1]["role"] == msg["role"]:
result[-1]["content"].extend(msg["content"])
else:
result.append({"role": msg["role"], "content": list(msg["content"])})
return result
def convert_from_bedrock(response, model):
content = ""
tool_calls = []
if "output" in response and "message" in response["output"]:
for block in response["output"]["message"].get("content", []):
if "text" in block:
content = block["text"]
elif "toolUse" in block:
tool_use = block["toolUse"]
tool_calls.append({
"id": tool_use["toolUseId"],
"type": "function",
"function": {"name": tool_use["name"], "arguments": json.dumps(tool_use.get("input", {}))}
})
finish_reason = "tool_calls" if response.get("stopReason") == "tool_use" else "stop"
choice = {
"index": 0,
"message": {"role": "assistant", "content": content if content else None},
"finish_reason": finish_reason
}
if tool_calls:
choice["message"]["tool_calls"] = tool_calls
return {
"id": f"chatcmpl-{uuid.uuid4().hex[:8]}",
"object": "chat.completion",
"created": int(time.time()),
"model": model,
"choices": [choice],
"usage": {
"prompt_tokens": response.get("usage", {}).get("inputTokens", 0),
"completion_tokens": response.get("usage", {}).get("outputTokens", 0),
"total_tokens": response.get("usage", {}).get("totalTokens", 0)
}
}
async def stream_generator(stream, model):
tool_use_buffer = {}
for event in stream:
if "contentBlockStart" in event:
start = event["contentBlockStart"]["start"]
if "toolUse" in start:
idx = event["contentBlockStart"]["contentBlockIndex"]
tool_use = start["toolUse"]
tool_use_buffer[idx] = {"id": tool_use["toolUseId"], "name": tool_use["name"], "input": ""}
chunk = {
"id": f"chatcmpl-{uuid.uuid4().hex[:8]}",
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": model,
"choices": [{
"index": 0,
"delta": {"tool_calls": [{
"index": idx,
"id": tool_use["toolUseId"],
"type": "function",
"function": {"name": tool_use["name"], "arguments": ""}
}]},
"finish_reason": None
}]
}
yield f"data: {json.dumps(chunk)}\n\n"
elif "contentBlockDelta" in event:
delta = event["contentBlockDelta"]["delta"]
idx = event["contentBlockDelta"]["contentBlockIndex"]
if "toolUse" in delta:
tool_input = delta["toolUse"].get("input", "")
if idx in tool_use_buffer:
tool_use_buffer[idx]["input"] += tool_input
chunk = {
"id": f"chatcmpl-{uuid.uuid4().hex[:8]}",
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": model,
"choices": [{
"index": 0,
"delta": {"tool_calls": [{"index": idx, "function": {"arguments": tool_input}}]},
"finish_reason": None
}]
}
yield f"data: {json.dumps(chunk)}\n\n"
elif "text" in delta:
chunk = {
"id": f"chatcmpl-{uuid.uuid4().hex[:8]}",
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": model,
"choices": [{"index": 0, "delta": {"content": delta["text"]}, "finish_reason": None}]
}
yield f"data: {json.dumps(chunk)}\n\n"
elif "messageStop" in event:
finish_reason = "tool_calls" if event["messageStop"].get("stopReason") == "tool_use" else "stop"
chunk = {
"id": f"chatcmpl-{uuid.uuid4().hex[:8]}",
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": model,
"choices": [{"index": 0, "delta": {}, "finish_reason": finish_reason}]
}
yield f"data: {json.dumps(chunk)}\n\n"
yield "data: [DONE]\n\n"
def verify_api_key(authorization: str = Header(None)):
if not authorization or not authorization.startswith("Bearer "):
raise HTTPException(status_code=401, detail="Missing API key")
if authorization.replace("Bearer ", "") != API_KEY:
raise HTTPException(status_code=401, detail="Invalid API key")
@app.post("/v1/chat/completions")
async def chat_completions(request: Request, authorization: str = Header(None)):
try:
verify_api_key(authorization)
body = await request.json()
logger.info(f"=== Incoming request ===")
logger.info(f"Body: {json.dumps(body, ensure_ascii=False)[:500]}")
bedrock_model = body.get("model")
if not bedrock_model:
return JSONResponse({"error": "model is required"}, status_code=400)
messages = body.get("messages", [])
stream = body.get("stream", False)
temperature = body.get("temperature", 0.7)
max_tokens = body.get("max_tokens", 2048)
tools = body.get("tools", [])
logger.info(f"Model: {bedrock_model}, Messages: {len(messages)}, Stream: {stream}, Tools: {len(tools)}, MaxTokens: {max_tokens}")
system, bedrock_messages = convert_to_bedrock(messages)
bedrock_messages = merge_messages(bedrock_messages)
logger.info(f"Converted: {len(messages)} messages -> {len(bedrock_messages)} bedrock messages")
logger.info(f"Bedrock messages: {json.dumps(bedrock_messages, ensure_ascii=False)[:1000]}")
kwargs = {
"modelId": bedrock_model,
"messages": bedrock_messages,
"inferenceConfig": {"temperature": temperature, "maxTokens": max_tokens}
}
if system:
kwargs["system"] = [{"text": system}]
logger.info(f"System: {system[:200]}")
if tools:
kwargs["toolConfig"] = {
"tools": [{
"toolSpec": {
"name": tool["function"]["name"],
"description": tool["function"].get("description", ""),
"inputSchema": {"json": tool["function"].get("parameters", {})}
}
} for tool in tools if tool.get("type") == "function"]
}
logger.info(f"Tools: {len(kwargs['toolConfig']['tools'])} tools")
logger.info(f"Calling Bedrock with modelId={bedrock_model}")
if stream:
response = bedrock.converse_stream(**kwargs)
logger.info("Streaming response started")
return StreamingResponse(stream_generator(response["stream"], bedrock_model), media_type="text/event-stream")
else:
response = bedrock.converse(**kwargs)
logger.info(f"Response: {json.dumps(response.get('output', {}), ensure_ascii=False)[:500]}")
result = convert_from_bedrock(response, bedrock_model)
logger.info(f"Converted response: {json.dumps(result, ensure_ascii=False)[:500]}")
return JSONResponse(result)
except Exception as e:
logger.error(f"=== ERROR ===")
logger.error(f"Exception: {type(e).__name__}: {str(e)}")
import traceback
logger.error(f"Traceback: {traceback.format_exc()}")
raise HTTPException(status_code=500, detail=str(e))
@app.get("/v1/models")
async def list_models():
return {"object": "list", "data": []}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8765)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)