TestPilot - 智能测试用例生成工具
一、前言
软件测试活动中,测试用例设计始终是质量保障体系的核心环节之一。然而,在实际项目中,测试用例编写的主要成本往往并不体现在「撰写」动作本身,而体现在需求理解、业务规则提炼、边界条件补全、异常路径覆盖以及历史测试经验复用等前置分析过程。随着系统复杂度持续增长、需求迭代周期不断缩短,传统依赖人工经验驱动的测试用例设计模式,正在面临效率、质量与复用性多重压力。
在大语言模型(LLM)快速发展的背景下,利用生成式 AI 辅助测试用例设计,已成为具有现实意义的技术方向。大语言模型在自然语言理解与结构化内容生成方面具备显著优势,能够在一定程度上缓解测试分析与用例组织的重复性工作负担。然而,若仅依赖简单的 prompt 驱动模式,将需求文本直接输入模型并期望获得高质量测试用例,通常难以满足工程落地要求。其主要原因在于:
- 模型缺乏领域知识上下文约束,难以准确继承团队已有测试规范;
- 生成结果可能存在边界覆盖不充分、业务规则偏离与内容幻觉等问题;
- 模型输出过程通常缺乏配置管理、质量审计与可追溯机制。
基于上述问题,TestPilot 被设计为一个面向测试场景的智能测试用例生成与管理平台,其目标并非构建单纯的「AI 对话式生成工具」,而是建立一条围绕测试用例生成、测试用例维护、测试用例导出、需求分析、知识养成与检索、内容生成、AI测试助手、质量检测与配置管理的完整工程链路。该平台以 LLM 为生成引擎,以知识库增强检索(RAG)为上下文供给手段,以自研幻觉检测机制为质量控制手段,并通过轻量化向量存储架构与配置中心实现工程级部署能力,从而使 AI 生成测试用例的过程从「可尝试」向「可控、可审计、可复用、可成长」演进。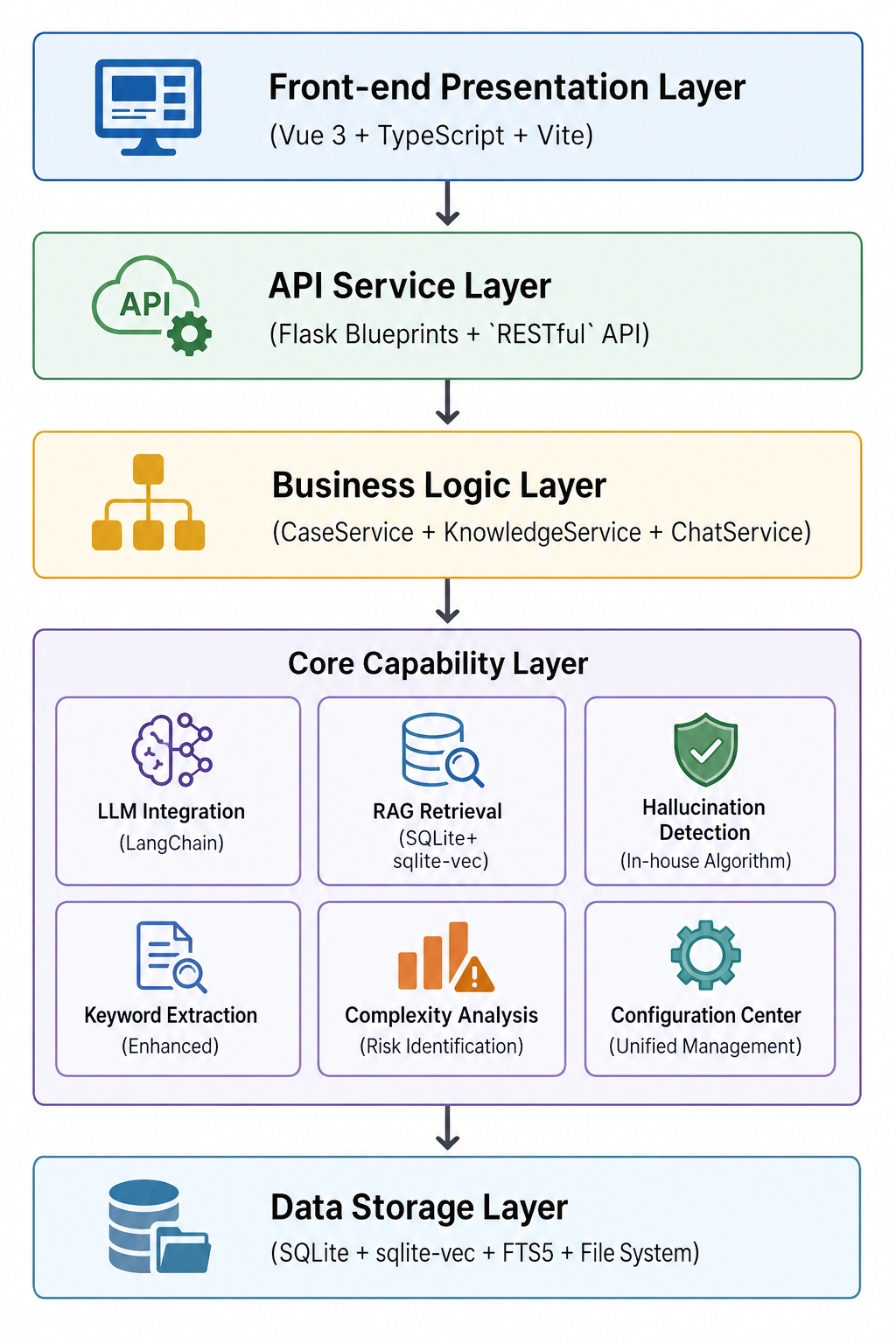
二、引入 LLM 参与测试用例生成的必要性
测试用例生成本质上是一项知识密集型工作,其输入不仅包括自然语言需求描述,还包括业务规则、数据约束、异常处理逻辑、团队历史用例、测试规范以及经验性判断。此类任务同时具备「理解复杂语义」与「输出结构化结果」的双重特征,因此天然适合引入大语言模型进行辅助处理。
从能力边界看,大语言模型在以下两个方面具有显著适配性:
- 对自然语言需求进行语义理解与关键信息提取;
- 在给定上下文约束下输出结构化测试内容。
然而,大语言模型仅解决了「生成能力」问题,并未自动解决「工程可信性」问题。若缺少检索增强、质量控制和运行时配置能力,模型生成内容通常会暴露以下缺陷:
- 无法继承团队既有测试方法论与历史经验;
- 无法准确绑定项目真实业务规则与术语体系;
- 无法避免生成内容中的事实性偏差或逻辑性幻觉;
- 无法提供统一的质量审核、配置管理与变更追踪能力。
因此,LLM 在测试工程中的价值,并不主要体现在「是否能够生成文本」,而体现在其是否能够被嵌入一条可控的工程链路之中。换言之,真正需要回答的问题不是「模型能否写出测试用例」,而是:
- 模型生成之前是否已经获得高质量、可验证的业务上下文;
- 模型生成之后是否存在可执行的质量检测与风险处理策略;
- 模型行为是否能够通过配置进行约束、调整与审计;
- 整套能力是否能够在团队范围内稳定复用,而非停留在一次性演示阶段。
TestPilot 的整体设计,即以此为出发点展开。
三、TestPilot 的系统定位:面向测试工程的智能流水线
TestPilot 的定位不是「对话式 AI 工具」,而是面向测试工程场景的智能测试用例生成流水线。其核心任务不是简单地产出一段测试文本,而是在需求输入后,经过分析、检索、生成、检测与管理等多个阶段,输出更具可用性与可追溯性的结构化测试用例结果。
系统主要包含以下核心环节
| 模块 | 说明 |
|---|---|
| 需求分析模块 | 支持多种需求文档格式解析,执行关键词提取、业务规则抽取、约束识别与复杂度评估; |
| 知识库增强模块 | 将历史测试用例、需求文档、测试规范等资料向量化存储,用于生成前的上下文补全; |
| 多策略检索模块 | 融合语义检索、关键词检索、混合检索与上下文感知检索,以提升召回质量; |
| LLM 生成模块 | 在增强上下文基础上执行结构化测试用例生成,而非无约束「自由生成」; |
| 幻觉检测模块 | 从模式匹配、逻辑分析与置信度评估等维度,对生成内容执行质量检测与风险处置; |
| 配置中心模块 | 实现模型、阈值、检索策略、敏感参数等配置项的统一管理、动态生效与审计追踪。 |
| 测试用例生成模块 | 基于需求输入与知识库上下文,完成从需求到结构化测试用例的完整流水线,支持单条/批量生成、优先级与测试类型分配、RAG 增强、幻觉检测及导出与统计; |
| AI 测试助手模块 | 面向测试场景的对话式助手,支持流式回复、会话上下文记忆、知识库增强与预置模板引导,可结合幻觉检测对回复内容做质量提示。 |
由此,TestPilot 所解决的问题不再是「让 AI 输出测试文本」,而是建立一套具备以下属性的测试用例生成基础设施:
- 结果具有明确上下文依据;
- 生成过程具备一定可解释性;
- 风险能够在系统内被主动识别与约束;
- 配置能够统一管理与审计;
- 整体架构能够落地部署、扩展与迁移。
四、TestPilot 针对测试场景所解决的关键问题
4.1 测试用例编写效率低
在复杂业务系统中,测试工程师通常需要投入大量时间用于阅读需求、确认流程、分析约束与补全边界条件。许多工作并非「撰写」动作本身,而是前置分析过程的重复劳动。TestPilot 将这一部分流程结构化,通过需求预处理、知识检索与增强生成等方式,将大量基础性工作前移至系统自动处理阶段,从而显著降低测试用例设计的重复成本。
4.2 测试用例质量不稳定
不同测试人员的经验、抽象能力和覆盖意识存在差异,因此测试用例质量在不同个体之间常常波动较大。TestPilot 在生成阶段引入知识库增强,在输出阶段引入幻觉检测与分级处理策略,试图从机制层面对生成内容的规范性、完整性与可信性进行约束,从而降低因个体差异导致的质量不稳定问题。
4.3 历史测试经验难以复用
在多数团队中,历史测试用例、规范文档和经验沉淀通常分散于不同项目和存储载体中,难以在新需求场景下被高效调用。TestPilot 将此类资料纳入知识库体系,通过向量化存储和智能检索,使「经验文档」转化为「可召回的上下文资产」,从而将历史测试经验直接纳入新一轮测试用例生成链路中。
4.4 AI 生成内容存在幻觉风险
在测试场景下,内容幻觉的风险远高于一般文本生成场景,因为错误测试用例不仅会降低文档质量,还可能直接误导测试设计与执行路径。TestPilot 将幻觉检测设计为核心能力之一,而非附属功能。系统从表述模式、逻辑一致性、上下文支撑程度及置信度等维度,对生成内容进行综合评估,并根据阈值采取警告、修正、重生成、人工审核或过滤策略。
4.5 需求文档解析工作量大
需求文档通常来源多样、格式不一、表达方式复杂,人工抽取测试要点与规则约束成本较高。TestPilot 在文档处理阶段支持多格式解析与预处理,并通过关键词提取、业务规则识别和复杂度分析,将需求内容转化为更适合后续检索与生成的结构化输入。
4.6 知识库检索效果不稳定
单纯依赖关键词匹配,难以准确表达语义相关性;单纯依赖向量检索,又可能丢失关键术语对召回效果的约束作用。TestPilot 因而采用多策略检索机制,并在当前主架构下使用 FTS5 与 sqlite-vec 组成两阶段混合检索流程,以在相关性、性能与部署复杂度之间取得平衡。
五、TestPilot 的工作机制与数据流转过程
从系统视角出发,TestPilot 的核心数据链路可以抽象为如下过程:

在该链路中,有两个设计原则尤为关键。
第一,检索质量决定生成质量。
LLM 生成并非凭空完成,而是显著依赖上下文质量。因此,TestPilot 将多策略智能检索设计为质量基础设施,而不是单纯的增强选项。
第二,生成结果必须接受后处理质量控制。
在测试场景中,生成完成并不意味着流程结束。能够进入实际使用阶段的内容,必须经过可靠性检测与风险筛选,从而降低错误结果直接进入测试管理体系的概率。
5.1 一个示例场景
假设输入需求为:
用户登录功能:支持账号密码登录,连续输错密码 5 次后锁定 30 分钟。
系统首先会抽取「登录」「账号密码」「连续失败」「锁定」「30 分钟」等核心信息,并以此为基础执行知识库检索,召回与登录、鉴权、锁定策略相关的历史测试用例和规范文档。随后,系统将需求原文与检索结果共同输入生成模块,输出结构化测试点,例如:
- 正确账号密码登录成功;
- 错误密码登录失败;
- 连续输错 5 次后账号被锁定;
- 锁定期间再次尝试登录的处理逻辑;
- 30 分钟后锁定是否自动解除;
- 锁定前后提示信息是否符合预期;
- 边界条件下失败次数统计是否准确。
生成完成后,系统继续对上述结果执行质量检测,以识别潜在逻辑冲突、表述异常或幻觉风险,并根据置信度进行后续处置。
{
"cases": [
{
"case_id": "TC-LOGIN-01",
"module": "登录",
"title": "正确账号密码登录成功",
"preconditions": "用户已注册且账号未被锁定;登录页面可正常访问。",
"steps": [
"1. 打开登录页面",
"2. 输入正确的账号和密码",
"3. 点击登录按钮"
],
"expected": [
"1. 登录成功",
"2. 跳转至系统首页或指定页面",
"3. 显示用户身份信息"
],
"priority": "P0",
"test_type": "功能测试",
"test_method": "正向验证",
"tags": ["登录", "账号密码", "正常流程"]
}
]
}
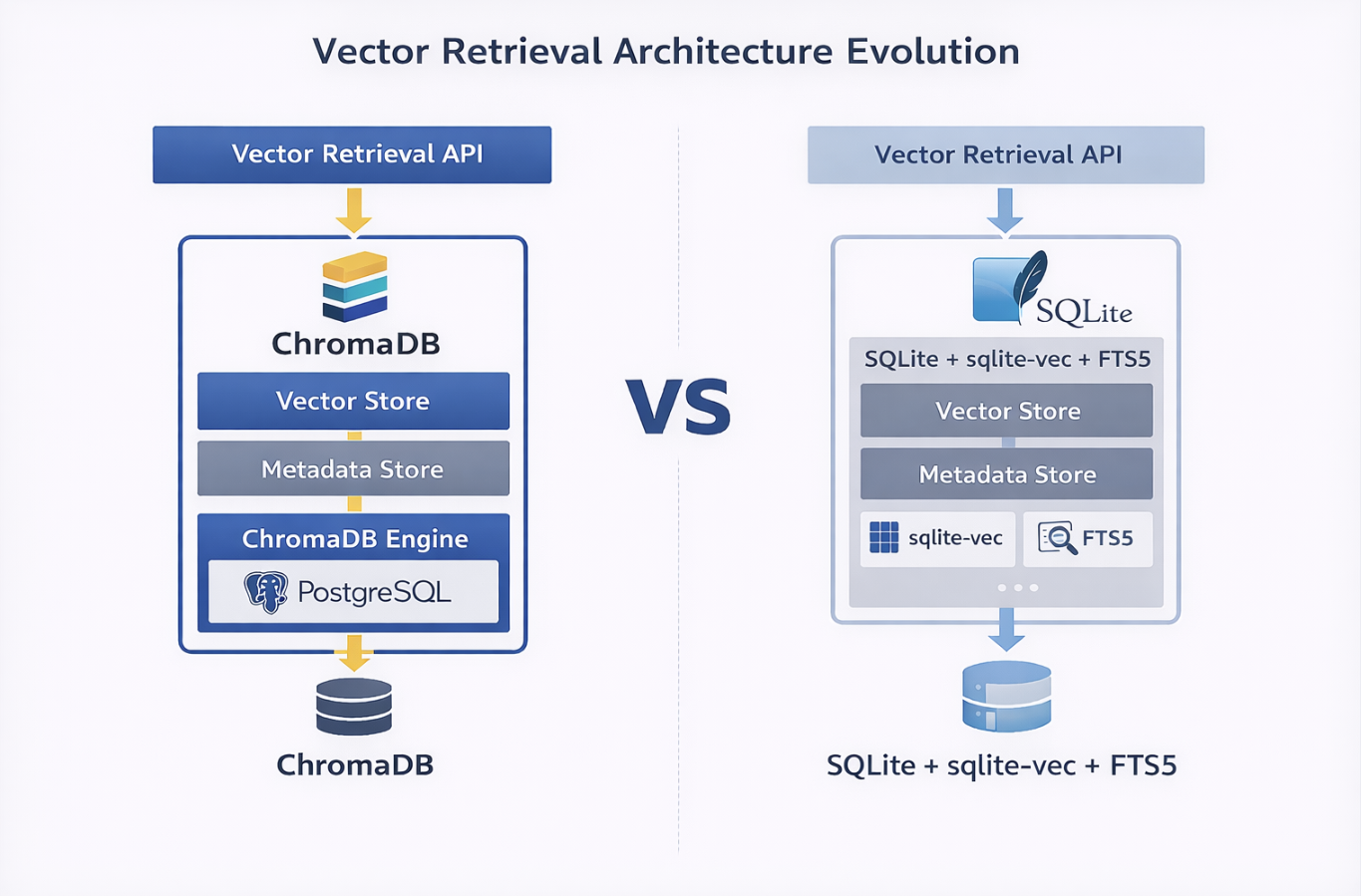
六、向量检索架构演进:从 ChromaDB 到 SQLite + sqlite-vec + FTS5
TestPilot 在早期曾采用 ChromaDB 作为向量存储与检索方案。然而,随着项目目标逐渐转向「可部署、可迁移、可内网落地」的工程场景,原有架构开始暴露出若干问题:
- 需要额外维护独立组件;
- 部署链路与运行依赖相对更重;
- 备份、恢复与迁移过程复杂度较高;
- 在单机、内网与离线场景下不够轻量。
基于上述考虑,当前 TestPilot 的主架构已经切换为:
- SQLite
- sqlite-vec
- FTS5
- FastEmbed(ONNX/CPU)
需要强调的是,ChromaDB 在当前项目中仅保留为历史方案或兼容回滚路径,不再作为主架构推荐方案。
6.1 当前架构的技术组成
当前向量检索架构可概括为:
| 层级 | 技术选型 | 说明 |
|---|---|---|
| Embedding 层 | FastEmbed(ONNX/CPU) | 无需 PyTorch; |
| 向量存储层 | SQLite 单文件数据库 + sqlite-vec 扩展 | 向量与元数据同库; |
| 全文索引层 | FTS5 虚拟表 | 用于关键词召回; |
| 混合检索机制 | FTS5 候选召回 → sqlite-vec 向量精排 | 两阶段检索。 |
这种设计具备以下工程优势:
- 单文件数据库,易于部署与备份:向量数据、元数据与全文索引均可整合于同一数据库体系中,便于迁移、备份和恢复。
- 轻量化运行依赖:FastEmbed 基于 ONNX/CPU,降低了模型部署对 GPU 与重型推理依赖的要求。
- 适合单机、内网与离线环境:无需额外维护独立向量服务,更符合中小团队内部平台的部署需求。
- 兼顾关键词与语义相关性:混合检索机制使关键术语约束与语义相似性能够共同参与结果排序。
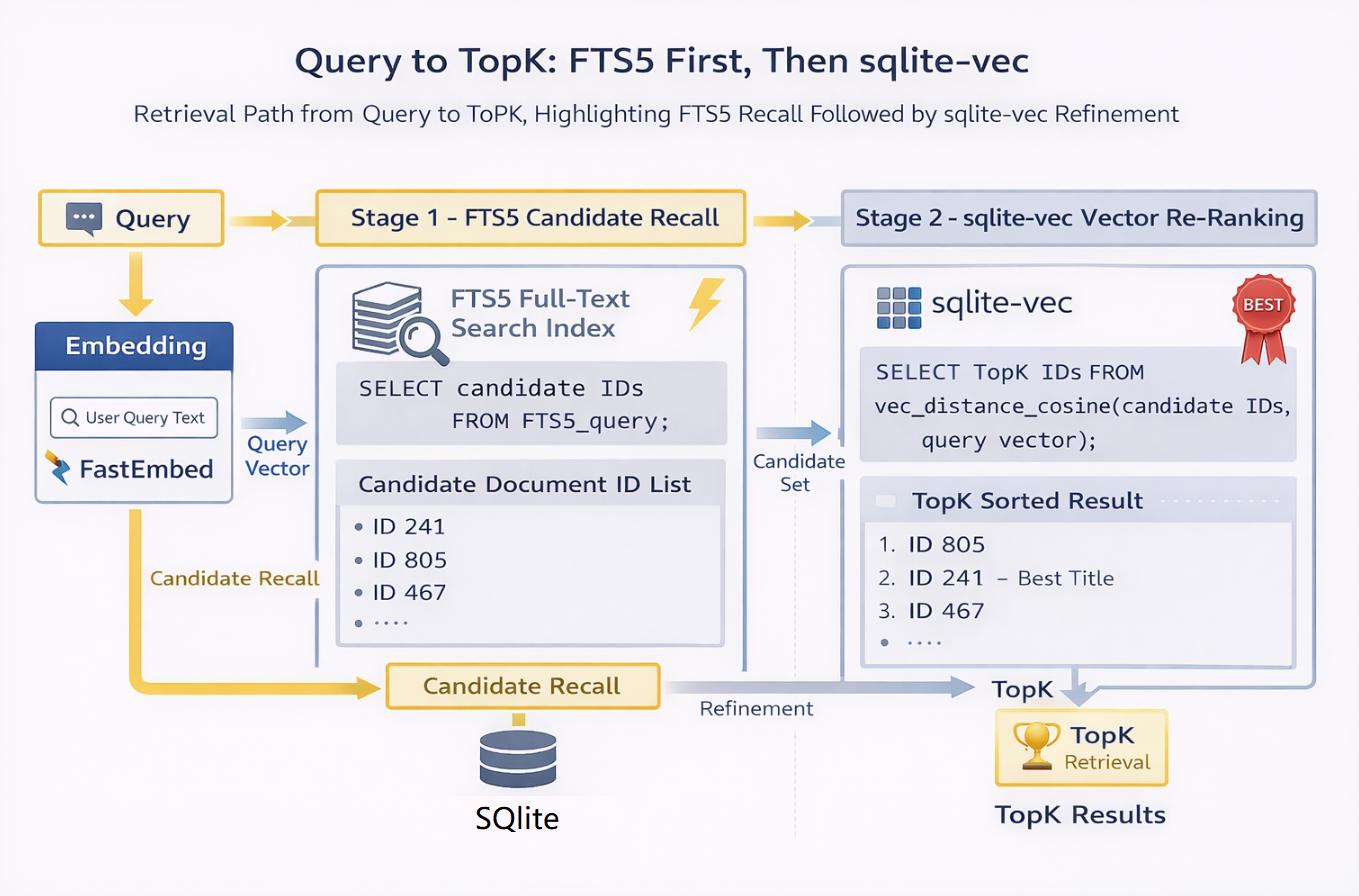
6.2 两阶段混合检索机制
当前检索流程采用两阶段设计:
第一阶段:FTS5 关键词召回
系统首先基于 FTS5 全文索引进行快速候选召回。为避免固定候选规模带来的召回不足或计算浪费,系统使用自适应候选策略:
- 简单查询可适当扩大召回范围;
- 复杂查询可适当缩小候选集;
- 候选规模受
MAX_FTS_CANDIDATE_K约束。
第二阶段:sqlite-vec 向量精排
在候选集合基础上,系统使用 vec_distance_cosine 计算向量距离,并将其映射为相似度分数,再按相关性返回 topK 结果。相较于直接对全量文档进行向量扫描,两阶段检索在数据规模提升后更具工程可控性。
6.3 工程级约束与容错策略
「限制与回退机制」的显式管理:
-
EMBEDDING_DIM 不可随意变更
向量数据库结构与 Embedding 维度存在绑定关系,因此一旦确定EMBEDDING_DIM,不可直接变更。若维度改变,必须先重建向量数据库。 -
SQLite IN 参数上限已做分批处理
SQLite 默认 IN 参数存在上限。为避免在大候选集合下触发异常,系统已经对高候选规模执行自动分批查询与结果合并。 -
sqlite-vec 扩展失败时允许自动退化
若 sqlite-vec 扩展不可用,系统自动降级为全表扫描模式,虽然性能下降,但功能仍可维持可用状态。 -
FTS5 返回为空时自动回退
若 FTS5 不可用或召回为空,系统自动切换为纯向量检索路径。 -
所有退化路径均有 warning 日志
相关 fallback 行为不会静默发生,而是显式记录 warning 日志,便于排查与运维。
# 向量存储后端(默认 sqlite,历史上支持 sqlite/chroma,当前推荐仅使用 sqlite)
VECTOR_BACKEND=sqlite
# Embedding 模型配置(必须与实际模型一致)
EMBEDDING_MODEL_NAME=BAAI/bge-small-en-v1.5
EMBEDDING_DIM=384 # 重要:维度一旦确定,不允许再变更(sqlite-vec 要求)
# SQLite 向量存储配置(可选)
SQLITE_VECTOR_DB_PATH= # 如果为空,使用 vector_store/vector_store.db
SQLITE_VEC_EXTENSION_PATH= # sqlite-vec 扩展路径(可选,未设置时自动尝试加载)
# 混合检索配置
ENABLE_HYBRID_RETRIEVAL=true # 是否启用混合检索(FTS5 + sqlite-vec)
FTS_CANDIDATE_K=200 # FTS5 召回候选数量(默认 200,适用于 topK=5~10)
七、幻觉检测机制的设计意义
在生成式测试平台中,幻觉检测并非附属模块,而是质量保障体系的一部分。TestPilot 当前采用多维度检测机制,其主要维度包括:
- 模式匹配:识别常见幻觉表述模式;
- 逻辑分析:检测输出内部是否存在逻辑矛盾或自相矛盾;
- 置信度评估:综合上下文支撑程度与规则特征,形成量化分值。
在处理策略上,系统根据置信度阈值选择不同动作:
- 警告模式(置信度 < 0.3):仅提示用户注意
- 自动修正(0.3 ≤ 置信度 < 0.5):尝试自动修正
- 重新生成(0.5 ≤ 置信度 < 0.7):使用LLM重新生成
- 人工审核(0.7 ≤ 置信度 < 0.9):标记为需要人工审核
- 过滤处理(置信度 ≥ 0.9):直接过滤掉
这使得 TestPilot 的输出不再是「一次生成即直接交付」,而是先进入风险检测与分级处理链路,从而提升整体可用性。
# 幻觉检测配置
ENABLE_HALLUCINATION_DETECTION=true
HALLUCINATION_SIMILARITY_THRESHOLD=0.8
HALLUCINATION_CONFIDENCE_THRESHOLD=0.7
HALLUCINATION_WARN_THRESHOLD=0.3
HALLUCINATION_AUTO_CORRECT_THRESHOLD=0.5
HALLUCINATION_REGENERATE_THRESHOLD=0.7
HALLUCINATION_FILTER_THRESHOLD=0.9
#幻觉检测相关接口
- `POST /api/hallucination/detect` - 检测内容中的幻觉问题
- `GET /api/hallucination/report/{id}` - 获取检测报告
- `POST /api/hallucination/handle` - 处理检测到的幻觉问题
- `GET /api/hallucination/config` - 获取幻觉检测配置
#幻觉检测相关代码块
│ │ ├── utils_ai_quality/ # AI内容质量检测
│ │ │ ├── hallucination_detector.py # 幻觉检测器
│ │ │ ├── hallucination_handler.py # 幻觉处理器
│ │ │ └── hallucination_reporter.py # 幻觉报告器
八、配置中心与工程可管理性
对于模型驱动系统而言,配置管理能力决定了平台是否具备团队级可用性。TestPilot 当前支持配置中心统一管理,其设计重点包括:
- 配置按功能分类组织;
- 敏感项加密存储;
- 配置格式与必填项校验;
- 审计日志记录变更历史;
- 配置动态生效。
其配置优先级为:
配置中心 > .env > 默认值
这意味着系统既支持环境变量方式快速启动,也支持在 Web 界面中对关键配置进行统一调整,而无需频繁修改代码或重启服务。
从工程角度看,配置中心之所以必要,是因为一旦系统引入以下能力:多模型接入、检索策略切换、阈值与评分控制、API Key 管理、性能调优参数、幻觉检测规则,就无法长期依赖手工编辑 .env 文件来满足团队协作需求。配置中心将这些原本分散的变更操作纳入统一管理体系,从而使平台具备更高的可维护性与可审计性。
# 配置中心相关接口
- `GET /api/config` - 获取所有配置项
- `GET /api/config/<category>` - 获取指定分类的配置
- `POST /api/config/<category>` - 批量更新指定分类的配置
- `GET /api/config/item/<key>` - 获取单个配置项
- `PUT /api/config/item/<key>` - 更新单个配置项
- `DELETE /api/config/item/<key>` - 删除配置项
- `GET /api/config/audit` - 获取配置审计日志
九、技术架构与项目结构设计
从系统架构上看,TestPilot 采用典型的分层设计:
| 层级 | 技术组成 |
|---|---|
| 前端展示层 | Bootstrap 5 + ES6 Modules + Chart.js |
| API 服务层 | Flask Blueprints + RESTful API |
| 业务逻辑层 | CaseService、KnowledgeService、ChatService 等 |
| 核心能力层 | LLM 集成、RAG 检索、幻觉检测、关键词提取、复杂度分析、配置中心 |
| 数据存储层 | SQLite + sqlite-vec + FTS5 + 文件系统 |
这一设计的目标并非形式上的「架构完整」,而是通过职责分离降低后续扩展与维护成本。
9.1 后端选型:Flask
Flask 的优势在于轻量、直观与可扩展性强。对于内部工具型平台和快速迭代型项目而言,Flask 能够在保持较低心智负担的前提下,通过 Blueprint 与服务层封装实现清晰的模块拆分。
9.2 前端选型:Bootstrap + ES6 Modules
TestPilot 并未采用重型前端框架,而是以 Bootstrap 5 与原生 ES6 Modules 构建页面交互。原因在于,该平台的核心竞争力不在复杂前端生态,而在测试工程链路本身。轻量前端方案更有利于快速验证、维护与部署。
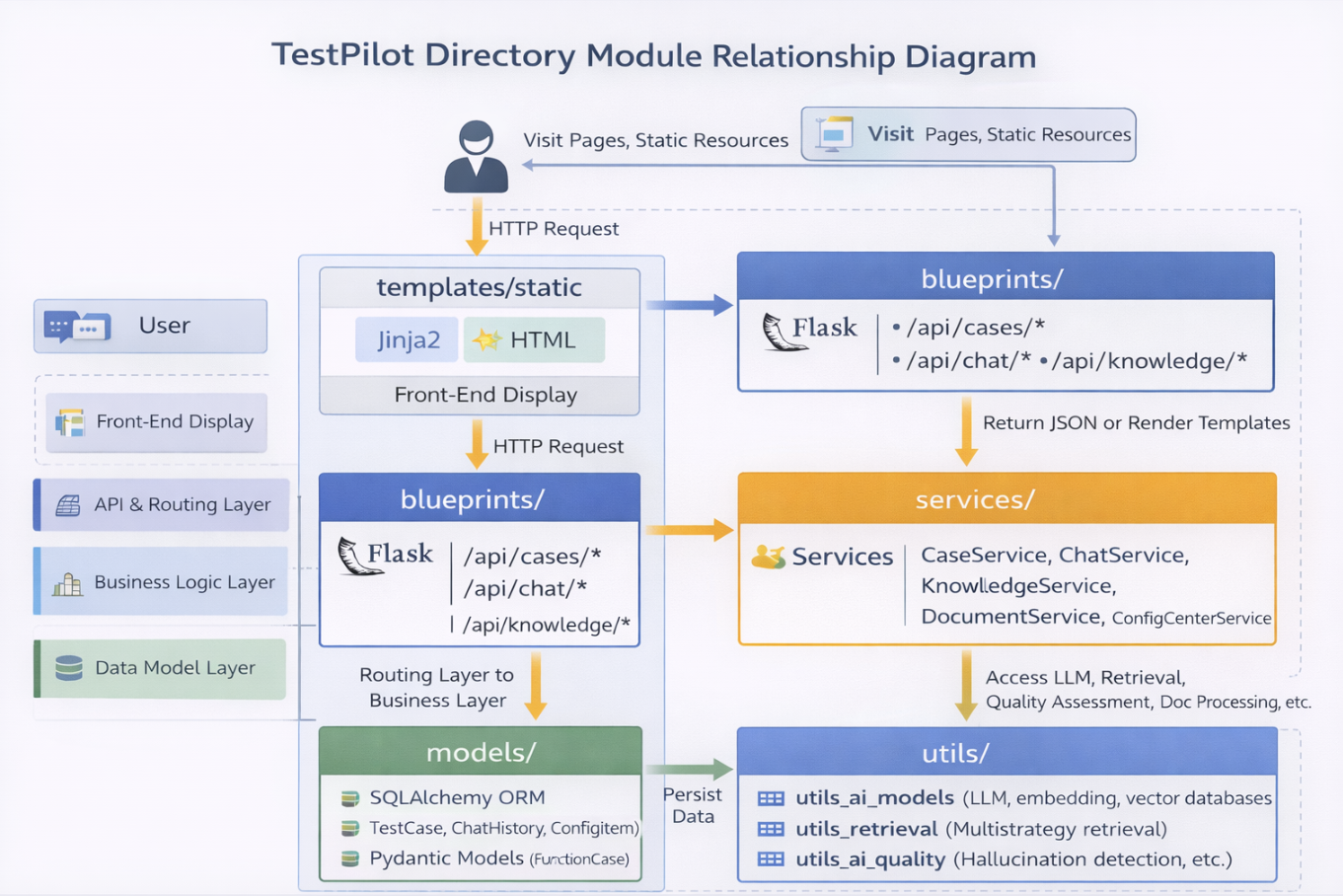
9.3 项目目录组织
为避免项目演化为脚本堆叠结构,TestPilot 在目录设计上进行了明确分层,核心结构如下:
TestPilot/
├── app.py / run.py # 应用入口
├── config/ # 核心配置
├── blueprints/ # API 路由层
├── services/ # 业务服务层
├── models/ # 数据模型层
├── templates/ + static/ # 前端页面与静态资源
├── utils/ # 模型、检索、文档处理、质量控制等工具层
├── scripts/ # 初始化、导入、检查与运维脚本
├── tests/ # 测试代码
├── docs/ # 详细文档
└── vector_store / uploads / logs # 数据与运行产物
进一步细分后,可看到:
utils_ai_models/负责模型接入;utils_ai_quality/负责幻觉检测;utils_intelligent_retrieval/负责多策略检索;utils_document_processing/负责文档处理;utils_config_management/负责配置管理;scripts/目录则负责数据库初始化、向量库初始化、配置中心初始化、知识库导入与系统检查等。
这种分层方式有助于将「模型能力」「检索能力」「质量能力」「配置能力」进行解耦,使平台在后续扩展中具有更好的工程弹性。
十、可运行性与部署能力
TestPilot 并非仅停留在概念层面,而是已经具备清晰的运行路径。最基础的启动过程包括:
- 克隆项目;
- 创建虚拟环境;
- 安装依赖;
- 预下载 FastEmbed 模型;
- 配置 .env;
- 初始化数据库;
- 初始化向量数据库;
- 基于run.py启动应用。
#!/usr/bin/env python3
"""
TestPilot 应用启动文件
支持开发和生产环境的启动配置
支持跨平台运行(Windows、Linux、Mac)
"""
import os
import sys
import threading
from pathlib import Path
from utils.utils_core.logger import init_logging, get_logger
# 添加项目根目录到Python路径
project_root = Path(__file__).parent
sys.path.insert(0, str(project_root))
from app import create_app
from utils.utils_core.common_utils import get_local_ip, open_browser
from utils.utils_core.platform_utils import get_platform, get_wsgi_server
def main():
"""主启动函数"""
# 初始化日志系统
init_logging()
logger = get_logger(__name__)
# 获取环境变量
debug = os.getenv('DEBUG', 'False').lower() == 'true'
port = int(os.getenv('PORT', 5001))
# 获取本地IP地址
host = get_local_ip()
if not host:
logger.warning("无法获取本地IP,使用0.0.0.0")
host = '0.0.0.0'
try:
# 创建Flask应用
app = create_app()
logger.info(f"启动TestPilot应用...")
logger.info(f"平台: {get_platform()}")
logger.info(f"环境: {'开发' if debug else '生产'}")
logger.info(f"地址: http://{host}:{port}")
# 在开发环境下自动打开浏览器
if debug and host != '0.0.0.0':
browser_thread = threading.Thread(
target=open_browser,
args=(host, port)
)
browser_thread.daemon = True
browser_thread.start()
# 启动应用
if debug:
# 开发环境
app.run(
host=host,
port=port,
debug=True,
threaded=True,
use_reloader=False
)
else:
# 生产环境使用平台特定的WSGI服务器
wsgi_server = get_wsgi_server()
logger.info(f"生产环境WSGI服务器: {wsgi_server}")
if wsgi_server == "waitress":
# Windows平台使用Waitress
waitress_available = False
try:
from waitress import serve
waitress_available = True
except ImportError:
serve = None # 定义为None以满足linter要求
if waitress_available:
logger.info("使用Waitress服务器 (Windows)")
serve(
app,
host=host,
port=port,
threads=int(os.getenv('WORKERS', 4)),
channel_timeout=30,
cleanup_interval=30,
asyncore_use_poll=True
)
else:
logger.warning("Waitress未安装,使用Flask内置服务器")
logger.info("提示: 运行 'pip install waitress' 安装Waitress")
app.run(
host=host,
port=port,
debug=False,
threaded=True
)
else:
# Linux/Mac平台使用Gunicorn
gunicorn_available = False
try:
import gunicorn.app.wsgiapp as gunicorn_app
gunicorn_available = True
except ImportError:
gunicorn_app = None # 定义为None以满足linter要求
if gunicorn_available:
logger.info("使用Gunicorn服务器 (Linux/Mac)")
# Gunicorn配置
# noinspection SpellCheckingInspection
gunicorn_config = {
'bind': f'{host}:{port}',
'workers': os.getenv('WORKERS', 4),
'worker_class': 'eventlet',
'worker_connections': 1000,
'timeout': 30,
'keepalive': 2,
'max_requests': 1000,
'max_requests_jitter': 100,
'preload_app': True,
'accesslog': 'logs/access.log',
'errorlog': 'logs/error.log', # Gunicorn官方配置项名称
'loglevel': 'info'
}
# 设置环境变量给Gunicorn
for key, value in gunicorn_config.items():
os.environ[f'GUNICORN_{key.upper()}'] = str(value)
# 启动Gunicorn
sys.argv = ['gunicorn', 'app:create_app()']
gunicorn_app.run()
else:
logger.warning("Gunicorn未安装,使用Flask内置服务器")
logger.info("提示: 运行 'pip install gunicorn' 安装Gunicorn")
app.run(
host=host,
port=port,
debug=False,
threaded=True
)
except Exception as e:
logger.error(f"启动应用失败: {str(e)}")
sys.exit(1)
if __name__ == '__main__':
main()
在离线部署场景下,基于Pyinstaller打包将已下载的FastEmbed 模型缓存支持提前下载并迁移至目标环境,从而满足内网或无外网环境的运行要求。
@echo off
chcp 65001 >nul
REM TestPilot PyInstaller Build Script
REM Windows Platform
echo ========================================
echo TestPilot PyInstaller Build Script
echo ========================================
echo.
REM Check if running in virtual environment
python -c "import sys; sys.exit(0 if hasattr(sys, 'real_prefix') or (hasattr(sys, 'base_prefix') and sys.base_prefix != sys.prefix) else 1)"
if %errorlevel% neq 0 (
echo [WARNING] Virtual environment not detected, recommend running in venv
echo.
)
REM Check if PyInstaller is installed
python -c "import PyInstaller" 2>nul
if %errorlevel% neq 0 (
echo [ERROR] PyInstaller not installed, installing...
pip install pyinstaller
if %errorlevel% neq 0 (
echo [ERROR] PyInstaller installation failed
pause
exit /b 1
)
)
echo [INFO] Cleaning old build files...
if exist build rmdir /s /q build
if exist dist rmdir /s /q dist
if exist TestPilot.spec del /q TestPilot.spec
echo [INFO] Starting build...
echo.
REM Build using spec file
pyinstaller build.spec
if %errorlevel% neq 0 (
echo [ERROR] Build failed
pause
exit /b 1
)
echo.
echo ========================================
echo Build completed!
echo ========================================
echo.
echo Executable location: dist\TestPilot.exe
echo.
echo Notes:
echo 1. Make sure .env file is configured before first run
echo 2. Ensure target machine has necessary runtime libraries
echo 3. Recommend packaging the entire dist directory for distribution
echo.
pause
十一、适用对象与应用价值
从应用场景判断,TestPilot 适合以下几类对象:
测试工程师与测试开发人员
适用于希望降低重复测试设计成本、提升历史经验复用率,同时又不愿完全放弃人工质量把控的使用者。
QA 负责人或测试经理
适用于关注测试规范沉淀、团队用例质量一致性、模型切换能力与配置审计能力的管理角色。
LLM + RAG 工程实践研究者
适用于关注如何将需求分析、知识检索、生成与质量控制整合成可落地工程系统的开发者或研究人员。
十二、结论
TestPilot 的设计目标并非将「AI 测试」概念化包装,而是围绕一个实际问题展开:测试用例生成能否从「辅助尝试」演进为「进入工程流程的基础能力」。
从目前的实现路径看,这一目标并不能单纯依赖更强的模型,也不能依赖更复杂的 prompt,而需要将以下能力统一纳入系统设计:
- 需求分析;
- 知识库建设;
- 多策略检索;
- 结构化生成;
- 幻觉检测;
- 配置管理;
- 部署与运维能力。
正因如此,TestPilot 最终并未被设计为一个「对话式生成工具」,而被设计为一套面向测试工程场景、具备可配置、可审计、可迁移与可部署能力的智能平台。
如果关注的是测试用例自动生成、测试知识库复用、RAG 在测试场景中的落地,或希望参考一套相对轻量的 Flask + SQLite + sqlite-vec + FTS5 工程实现路径,那么 TestPilot 具有一定的实践参考价值。
十三、开源地址
如果该项目对相关研究或工程实践有所启发,欢迎进一步交流、提出问题。
项目开源地址:https://github.com/zhoujun94511/TestPilot-vue

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)