YOLO数据集制作及使用
在基于 YOLOv10 做目标检测训练时,规范统一的数据集目录结构是保证训练正常运行的第一步。YOLOv10 延续了 YOLO 系列经典的数据集组织方式,图片与标签分文件夹存放、文件名一一对应,清晰的层级能有效避免路径错误、标签匹配失败等问题。本文给出一种简洁的数据集目录结构,方便大家快速对照搭建自己的数据集。
YOLO(含 v10)目标检测数据集的训练集(train)、验证集(val/valid)、测试集(test)图片数量通用经典划分比例为 7:2:1(训练集 70% 用于模型参数学习、验证集 20% 用于调参评估、测试集 10% 用于最终泛化能力评估),该比例可根据数据集规模灵活调整,但需保证三类数据集无重叠且类别分布一致。
YOLOv10 数据集目录结构
data/
├── train/ # 训练集目录
│ ├── images/ # 训练集图片文件夹
│ │ ├── train_001.jpg # 训练图片1(格式支持jpg/png/bmp等)
│ │ ├── train_002.png
│ │ └── ... # 其余训练集图片
│ └── labels/ # 训练集标签文件夹(与图片一一对应)
│ ├── train_001.txt # 训练图片1对应的标签文件
│ ├── train_002.txt
│ └── ... # 其余训练集标签文件
├── valid/ # 验证集目录(结构与train完全一致)
│ ├── images/
│ │ ├── val_001.jpg
│ │ ├── val_002.png
│ │ └── ...
│ └── labels/
│ ├── val_001.txt
│ ├── val_002.txt
│ └── ...
├── test/ # 测试集目录(结构与train完全一致)
│ ├── images/
│ │ ├── test_001.jpg
│ │ ├── test_002.png
│ │ └── ...
│ └── labels/
│ ├── test_001.txt
│ ├── test_002.txt
│ └── ...
└── data.yaml # YOLOv10 核心配置文件(必须)注意事项
文件命名规则:
图片文件和对应的标签文件必须同名不同后缀(如 train_001.jpg ↔ train_001.txt)(可采用专门的标注工具标注,如LabelImg),YOLOv10 会通过文件名自动匹配图片和标签,命名不一致会导致训练 / 推理报错。
标签文件(.txt)格式(YOLO 标准格式):
每个 txt 文件每行对应一个目标,格式为:类别ID 中心点x 中心点y 宽度w 高度h(所有数值均为归一化后的值,范围 0~1)
对于OBC306数据集:整个图片都是待检测的目标,YOLO 格式的标签需要体现 “目标覆盖整张图片” 的特征,核心是将宽度和高度设为 1.0(归一化后占满整图),中心点坐标设为 (0.5, 0.5)(图片正中心),面对这样特殊场景,我们可以直接采用python脚本来实现快速制作label文件内容
实例:
0 0.45 0.52 0.18 0.25 # 类别0,目标中心点(0.45,0.52),宽0.18,高0.25
1 0.78 0.36 0.12 0.19 # 类别1,第二个目标
2 0.5 0.5 1.0 1.0 # 类别2,目标覆盖整张图片(中心点x=0.5, y=0.5,宽1.0,高1.0),如甲骨文数据集OBC306数据集中的图片以OBC306为例,数据集及其对应的label如图
data:
test:

images:

labels:

data.yaml 核心配置示例:
这是 YOLOv10 识别数据集的关键文件,需指定类别、数据集路径等,示例:
# 数据集根目录
path: D:/yolov10/data
# 训练/验证/测试集路径(相对于path的相对路径,无需重复写根目录)
train: train/images
val: val/images
test: test/images
# 类别数量(必须与names列表长度一致,此处24个类别)
nc: 24
# 类别名称列表(顺序对应类别ID 0-23,支持字符串/数字字符串格式)
names: ['001000', '001004', '001008', '001014', '001018', '001027', '001032',
'001054', '001072', '001086', '001096', '001106', '001109', '001114',
'001125', '001135', '001136', '001148', '001157', '001166', '001173',
'001176', '001184', '001206']
names两种写法:
# 写法1:字典式(清晰标注ID,适合类别少的场景)
names:
0: 001000
1: 001004
2: 001008
# ... 依次补全24个类别
# 写法2:列表式(简洁,适合类别多的场景,默认索引为ID)
names: ['001000', '001004', '001008', ...] # 索引0→ID0,索引1→ID1,以此类推使用数据集
在README中查找训练指令
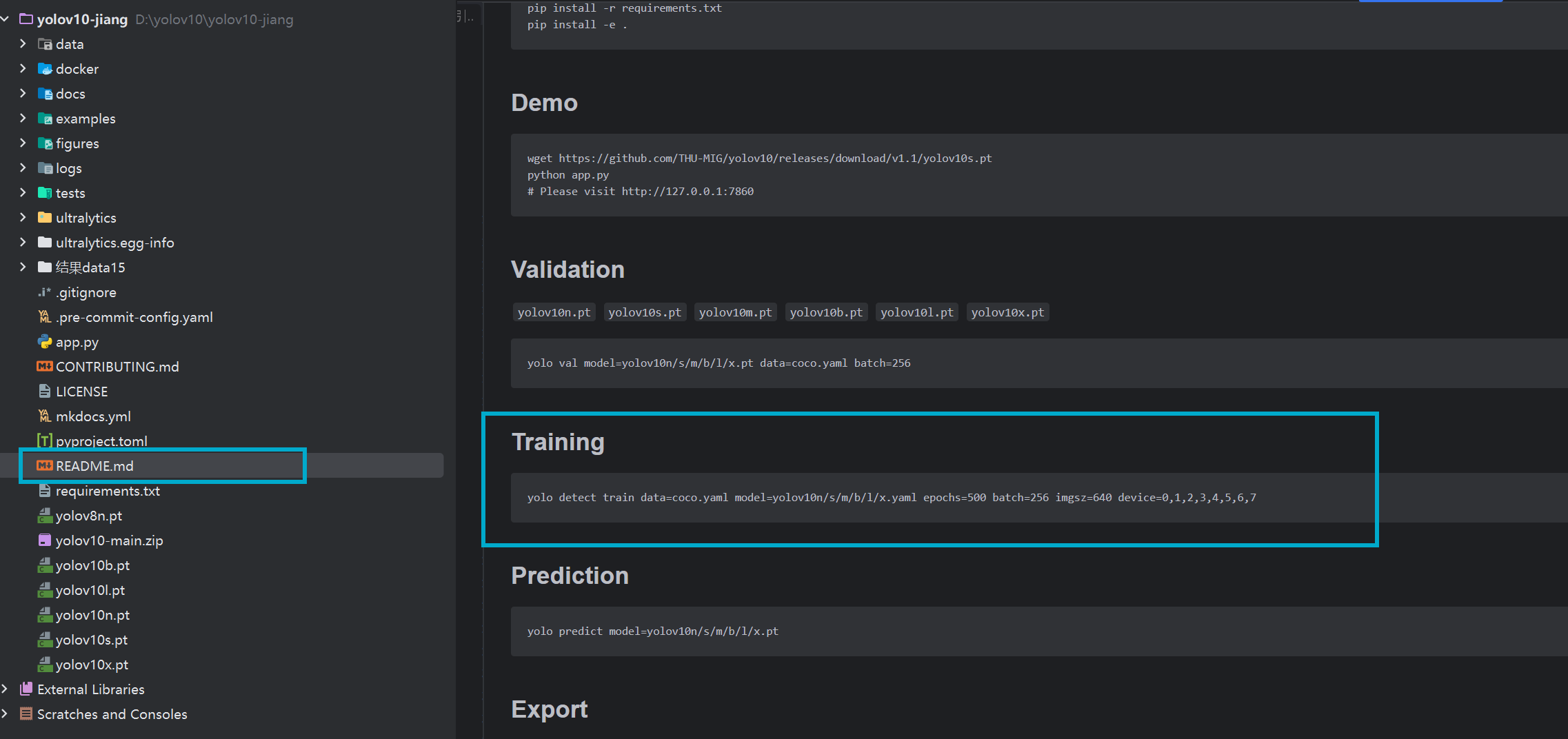
核心参数说明
yolo detect train:指定执行 YOLOv10 目标检测模型训练;data=coco.yaml:数据集配置文件路径,需替换为自定义data.yaml(含路径 / 类别);model=yolov10n/s/m/b/l/x.yaml:模型规格(n = 最小 / 快,x = 最大 / 准,按需选);yolov10n.yaml:nano 版(最小模型,速度最快,精度最低,适合边缘设备);yolov10s.yaml:small 版(小模型,速度与精度平衡,新手首选);yolov10m.yaml:medium 版(中等模型);yolov10b.yaml:big 版(大模型);yolov10l.yaml:large 版(更大模型);yolov10x.yaml:xlarge 版(最大模型,精度最高,速度最慢,适合算力充足的场景);epochs=500:训练轮数,小数据集 50-200、大数据集 300-1000 即可;batch=256:批次大小,8 卡均分单卡 32,显存不足可降为 64/128 ,笔记本电脑建议4-8;imgsz=640:输入图尺寸(32 的倍数),越大精度越高、速度越慢;device=0-7:指定 8 张 GPU 训练,单卡写device=0,CPU 写device=cpu。
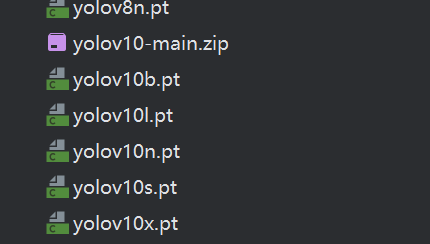
选择model要有对应权重的文件如图:
yolov10n/s/m/b/l/x.pt 是 PyTorch 格式的预训练模型权重文件,里面存储的是模型在 COCO 等大规模数据集上已经训练好的参数(包括卷积核、BN 层、全连接层等全部可学习参数)
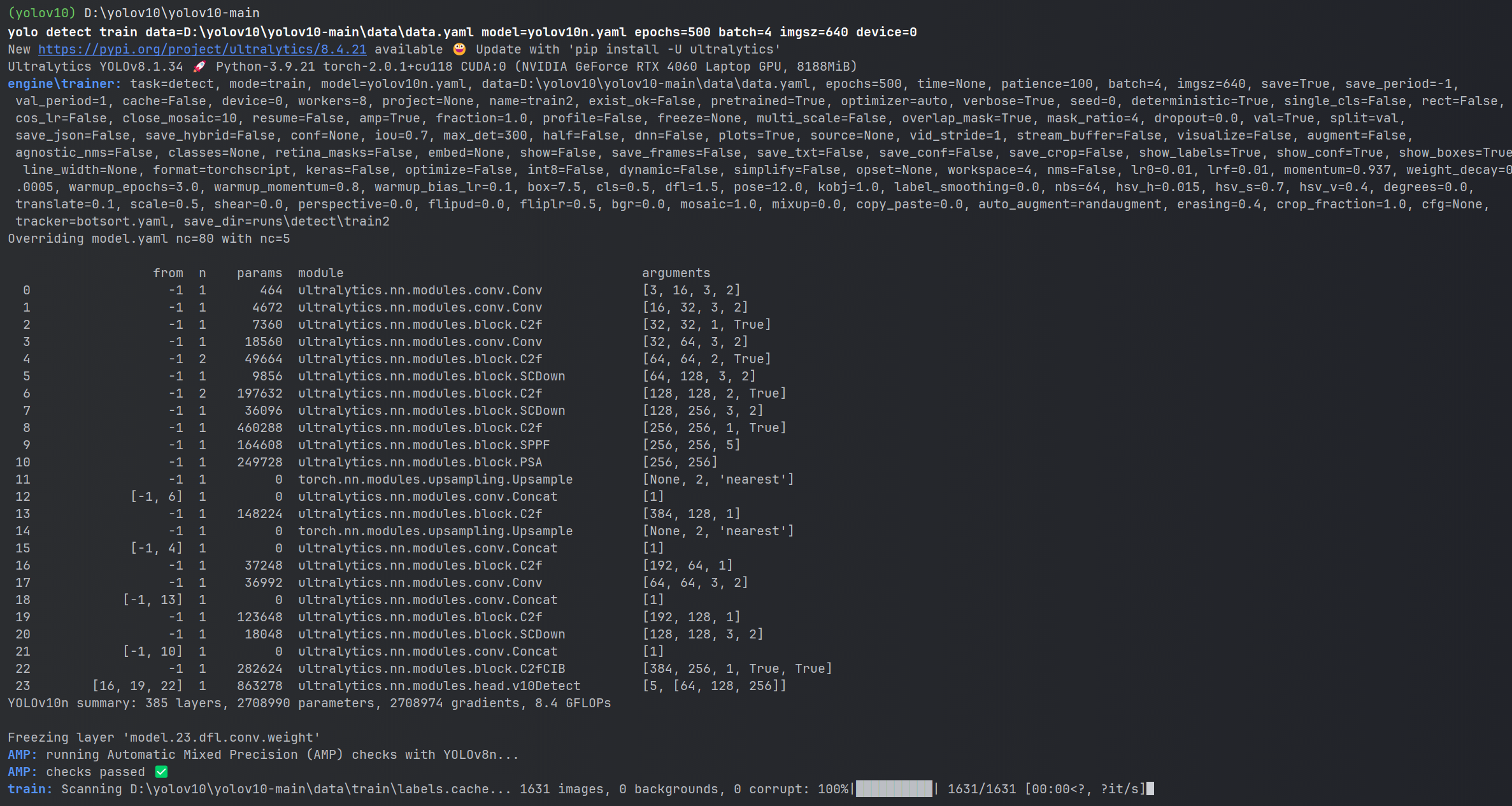
终端指令输入:
如图:

启动成功如下

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)