三、模型架构
1、Transformer 核心组件
Transformer 架构自 2017 年提出以来,已成为几乎所有大模型的基石。其核心设计围绕 自注意力机制 展开,辅以多头注意力、位置编码、前馈网络以及归一化与残差连接。
1.1 自注意力机制(Self-Attention)
自注意力机制让序列中的每个元素都能直接与其他所有元素交互,计算它们之间的关联权重,从而捕捉长距离依赖。
=====================================
整体流程图
输入序列 X
↓ 线性投影(3组不同权重)
┌─────────┬─────────┬─────────┐
│ Q │ K │ V │
│ Query │ Key │ Value │
└─────────┴─────────┴─────────┘
↓
Q · Kᵀ (计算相似度)
↓
÷ √dₖ (缩放,防梯度消失)
↓
softmax (归一化成权重和为1)
↓
× V (按权重对值加权求和)
↓
输出 Attention 结果
=====================================
公式可视化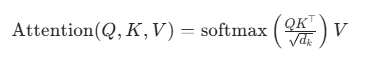
QKᵀ → 每个词和所有词的“关联分数”
÷ √dₖ → 缩放,让数值稳定
softmax → 变成0~1之间的权重,总和=1
× V → 用权重把所有V融合起来
=====================================
QKV 从哪来
输入:
X = [x1, x2, x3…xn]
投影: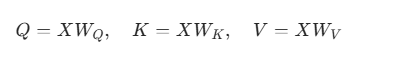
x1 ──┬──→ q1
x2 ──┼──→ q2
… ──┼──→ …
xn ──┴──→ qn Query
x1 ──┬──→ k1
x2 ──┼──→ k2
… ──┼──→ …
xn ──┴──→ kn Key
x1 ──┬──→ v1
x2 ──┼──→ v2
… ──┼──→ …
xn ──┴──→ vn Value
=====================================
注意力权重矩阵
词1 词2 词3 … 词n
┌──────────────────────────┐
词1 │ 0.2 0.1 0.05 … 0.01 │
词2 │ 0.1 0.3 0.2 … 0.02 │
词3 │ 0.05 0.1 0.4 … 0.03 │
… │ … │
词n │ 0.01 0.02 0.03 … 0.5 │
└──────────────────────────┘
每个位置:本行对所有列的注意力权重
=====================================
举例:
The animal didn’t cross the street because it was too tired.
处理 it 时:
it 对 The animal → 权重很高
it 对 street → 权重很低
模型自动知道:it → 指代 animal
图示:
The animal … … … … … it …
↑ ↑
└─────────────────────┘
强注意力连线
记忆口诀
自注意力 = 每个词都看一遍所有词,算出谁更相关
Q = 我要查什么
K = 你有什么信息
V = 你实际的信息内容
用相关性权重把所有信息加权融合。
1.2 多头注意力(Multi-Head Attention)
单头注意力可能只关注一种关联模式。多头注意力通过并行执行多个自注意力(每个头有不同的 WQ,WK,WV),让模型从不同子空间捕捉多样化的关系。
=====================================
核心思想
单头注意力:只学一种关联模式;
多头注意力:并行学h 种不同的关联模式,再融合;
=====================================
整体流程示意图
输入 Q, K, V
│
├───────── 头1 ─────────┐
├───────── 头2 ─────────┤
│ … ├─ 每个头独立做自注意力
└───────── 头h ─────────┘
│
Concat(头1, 头2, …, 头h)
│
线性投影 Wᴏ
│
最终多头输出
=====================================
公式可视化
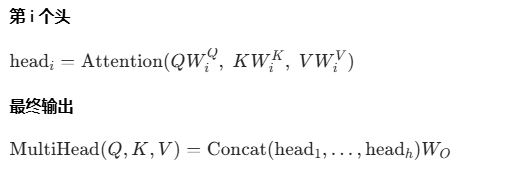
=====================================
结构展开图
输入 Q, K, V
│
┌───────────────┼───────────────┐
│ │ │
投影得到 投影得到 投影得到
Q₁,K₁,V₁ Q₂,K₂,V₂ Qₕ,Kₕ,Vₕ
│ │ │
┌───┴────┐ ┌──────┴──────┐ ┌────┴──────┐
│ 自注意力头1│ │ 自注意力头2 │ │ 自注意力头h │
└───┬────┘ └──────┬──────┘ └────┬──────┘
│ │ │
└────────────┼─────────────┘
拼接 Concat
│
线性层 Wᴼ
│
多头注意力输出
=====================================
每个head做什么
头1:关注【主谓语法关系】
头2:关注【指代关系(it → animal)】
头3:关注【语义相似】
头4:关注【长距离依赖】
…
所有头一起 → 表示更丰富、更强大
1.3 位置编码(Positional Encoding)
自注意力本身是 置换不变 的,即打乱输入顺序会得到相同输出(只是对应位置重新排列)。但语言是顺序敏感的,因此必须注入位置信息。
绝对位置编码:最早 Transformer 使用正弦/余弦函数生成固定向量,与词向量相加: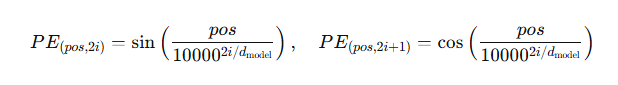
这样不同位置的编码具有唯一性,且能外推到更长序列。
相对位置编码:后续研究发现,相对位置(词与词之间的距离)比绝对位置更重要。如 Transformer-XL 和 RoPE(Rotary Position Embedding) 通过旋转矩阵在注意力计算中融入相对位置,使模型更容易泛化到长序列。LLaMA、GPT-NeoX 等现代模型普遍采用 RoPE。
1.4 前馈网络(Feed-Forward Network,FFN)
每个 Transformer 层在多头注意力之后,会对每个位置的输出独立地应用一个前馈网络(即逐位置的全连接层)。它通常包含两个线性变换和一个非线性激活函数: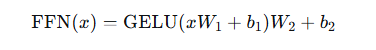 第一个线性变换将维度放大(通常为 4 倍模型维度),引入更多参数以学习复杂特征。
第一个线性变换将维度放大(通常为 4 倍模型维度),引入更多参数以学习复杂特征。
激活函数常用 GELU(高斯误差线性单元)或 SwiGLU(LLaMA 等采用),比 ReLU 更平滑。
第二个线性变换恢复原维度。
作用:FFN 为模型引入非线性,并对每个位置的特征进行再变换,相当于在注意力聚合信息后进行局部处理。
1.5 层归一化与残差连接
为了使深层网络训练稳定,Transformer 在每个子层(注意力层和 FFN)后都使用残差连接和层归一化。
残差连接:将子层输入与子层输出相加,形成跳跃连接。这有助于梯度直接流向底层,缓解梯度消失。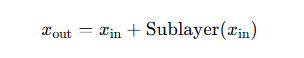 层归一化(Layer Normalization):对每个样本的所有特征维度进行归一化(均值为 0,方差为 1),然后施加可学习的缩放和平移。它稳定了训练过程,降低对初始化的敏感度。
层归一化(Layer Normalization):对每个样本的所有特征维度进行归一化(均值为 0,方差为 1),然后施加可学习的缩放和平移。它稳定了训练过程,降低对初始化的敏感度。
原始 Transformer 采用 Post-Norm(先残差后归一化),但后来发现 Pre-Norm(先归一化后子层)更易训练,被 GPT、BERT 等广泛采用。
2 主流架构变体
根据注意力掩码方式和任务需求,Transformer 衍生出三种主流架构:仅编码器、仅解码器、编码器-解码器。
2.1 仅编码器架构(Encoder-only)
代表模型:BERT、RoBERTa、ALBERT、DeBERTa
结构特点:只使用 Transformer 的编码器部分。编码器采用 双向自注意力(无掩码),每个位置可以看到整个输入序列的所有 token。训练任务通常是掩码语言建模(MLM)和下一句预测(NSP)。
输入序列 → 【双向自注意力】 → 【前馈网络】 → 输出
适用任务:自然语言理解(NLU)任务,需要从输入中提取丰富语义信息进行分类或标记。
文本分类(情感分析、新闻分类)
序列标注(命名实体识别、词性标注)
抽取式问答(从段落中定位答案)
例子
BERT-base 有 12 层编码器,隐藏维度 768,12 个注意力头。在微调时,通常将 [CLS] 位置的输出作为整个句子的表示,输入分类器。
任务:情感分类(正面 / 负面)
输入句子:这家店的蛋糕超级好吃!
A 步骤图解
[CLS] 这 家 店 的 蛋 糕 超 级 好 吃 [SEP]
B 进 Encoder 层(双向注意力)
每个词都能看到整句话 → 理解“超级好吃”是正面
C 取 [CLS] 输出
[CLS] 的输出 = 整句话的语义向量
D 进分类器
语义向量 → 线性层 → Softmax
→ 输出:正面 99% / 负面 1%
记忆口诀
Encoder-only = 只理解、不生成
双向注意力 = 左右都能看
MLM 掩码预测 = 填空游戏
[CLS] = 整句代表
擅长:分类、标注、抽取式问答
2.2 仅解码器架构(Decoder-only)
代表模型:GPT 系列、LLaMA、PaLM、Bloom
结构特点:只使用 Transformer 的解码器部分,但移除了编码器-解码器注意力层(即标准的解码器原本有两个注意力子层:掩码自注意力 + 交叉注意力,在仅解码器架构中只保留掩码自注意力)。它采用 因果掩码(Causal Mask),即在计算自注意力时,当前位置只能看到它之前的 token,不能看到未来信息。这使得模型天生适合自回归生成。
标准Transformer 解码器 本来有两层注意力
输入
├─ 掩码自注意力(只能看前面)
├─ 编码器-解码器交叉注意力(看编码器输出)
└─ 前馈网络
Decoder-only 模型:砍掉交叉注意力,只留掩码自注意力
输入
├─ 【掩码自注意力(Causal Mask)】
└─ 前馈网络
Decoder-only 完整流程
输入提示词 → 词嵌入 → 叠加位置编码
↓
【掩码自注意力】(只能看前面)
↓
前馈网络
↓
预测下一个词
↓
把预测词拼回输入 → 继续生成下一个
适用任务:自然语言生成(NLG)任务,以及其他可统一为生成形式的下游任务。
文本生成(故事续写、对话、代码生成)、零样本/少样本推理(通过提示词完成分类、翻译等)
例子:GPT-3 拥有 1750 亿参数,96 层解码器。给定提示“Translate English to French: ‘Hello, how are you?’”,模型自回归地生成“Bonjour, comment allez-vous?”。
2.3 编码器-解码器架构(Encoder-Decoder)
代表模型:T5、BART、MASS、原始 Transformer
结构特点:包含一个编码器和一个解码器。编码器使用双向注意力对输入序列进行编码,输出上下文表示;解码器使用因果掩码和交叉注意力(关注编码器输出)逐步生成目标序列。
整体结构
【编码器 Encoder】 【解码器 Decoder】
输入序列 ──────────────────────────▶ 上下文记忆 ◀────────────────── 解码器自注意力
(理解用) 双向注意力 │ 因果掩码
└────────────────────▶ 交叉注意力
↓
生成输出序列
编码器 Encoder(理解端)
只用 双向自注意力
能看到整个输入
输出:上下文向量 / 记忆(memory)
输入:我爱北京天安门
↓
编码器(双向注意力)
↓
得到:整段话的语义记忆
解码器 Decoder(生成端)
解码器里有 两个注意力:
掩码自注意力(因果掩码)→ 只能看前面已生成的词,不能看未来
交叉注意力(Cross-Attention)→ 回头看编码器的上下文记忆
已生成的部分 → 掩码自注意力(只能看左边)
↓
交叉注意力 ←── 编码器的记忆
↓
前馈网络
↓
预测下一个词
适用任务:序列到序列(Seq2Seq)任务,输入和输出都是序列,且长度或结构可能不同。
机器翻译、文本摘要、问答生成(输入问题+上下文,输出答案)
例子:T5 将所有任务统一为“文本到文本”格式。对于翻译任务,输入为“translate English to German: That is good.”,输出为“Das ist gut.”。T5 在预训练时使用类似 MLM 的降噪目标(随机掩盖一段连续 token 并让模型重建),同时结合编码器-解码器结构,表现出强大的迁移能力。
3 混合专家(MoE)在架构中的融入
在讨论大模型架构时,MoE 已成为扩展参数规模的主流方式。MoE 并非颠覆 Transformer 核心组件,而是将 前馈网络(FFN)层替换为多个并行的专家网络,并引入一个门控网络(Router)动态选择激活哪些专家。
结构:在 Transformer 层中,原本的 FFN 被替换为 MoE 层。例如,Switch Transformer 在每个 token 上只激活一个专家(Top-1),而 GShard 等通常激活 Top-2。
Token
↓
自注意力
↓
┌---------------------------┐
│ 门控 Router │ ← 给每个token选专家
└---------------------------┘
↓(只激活少数专家)
┌-------┐ ┌-------┐ ┌-------┐ ┌-------┐
│专家1 │ │专家2 │ │专家3 │ │专家4 │...(很多专家)
└-------┘ └-------┘ └-------┘ └-------┘
↓
合并输出
优势:模型总参数量可以极大增加(如 1.6 万亿),但计算量仅相当于一个稍大的稠密模型,因为每个 token 只经过少数专家。
挑战:需要处理负载均衡(避免某些专家过载)、通信开销(专家并行中需分发 token)和训练稳定性。
MoE 架构已在多个大规模模型中应用,如 GPT-4(传闻采用 MoE)、Mixtral 8x7B、DeepSeek-V2 等。它是对 Transformer 层内组件的增强,属于架构层面的重要变体。
记忆口诀
FFN 变 多专家
加个 Router 门控
每个 token 只走少数专家
参数大、计算省、 scaling 强

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)