二、基础概念
基础概念详解
1 深度学习回顾
深度学习是构建大模型的基石。理解它的核心组件——神经网络、前向传播、损失函数、梯度下降和反向传播——是掌握大模型训练的第一步。
1.1 神经网络(Neural Network)
神经网络由多个神经元(节点)和连接它们的权重组成,通常组织成层(输入层、隐藏层、输出层)。每个神经元接收输入信号,进行加权求和后通过一个激活函数(如ReLU、Sigmoid)引入非线性,从而让网络能够学习复杂模式。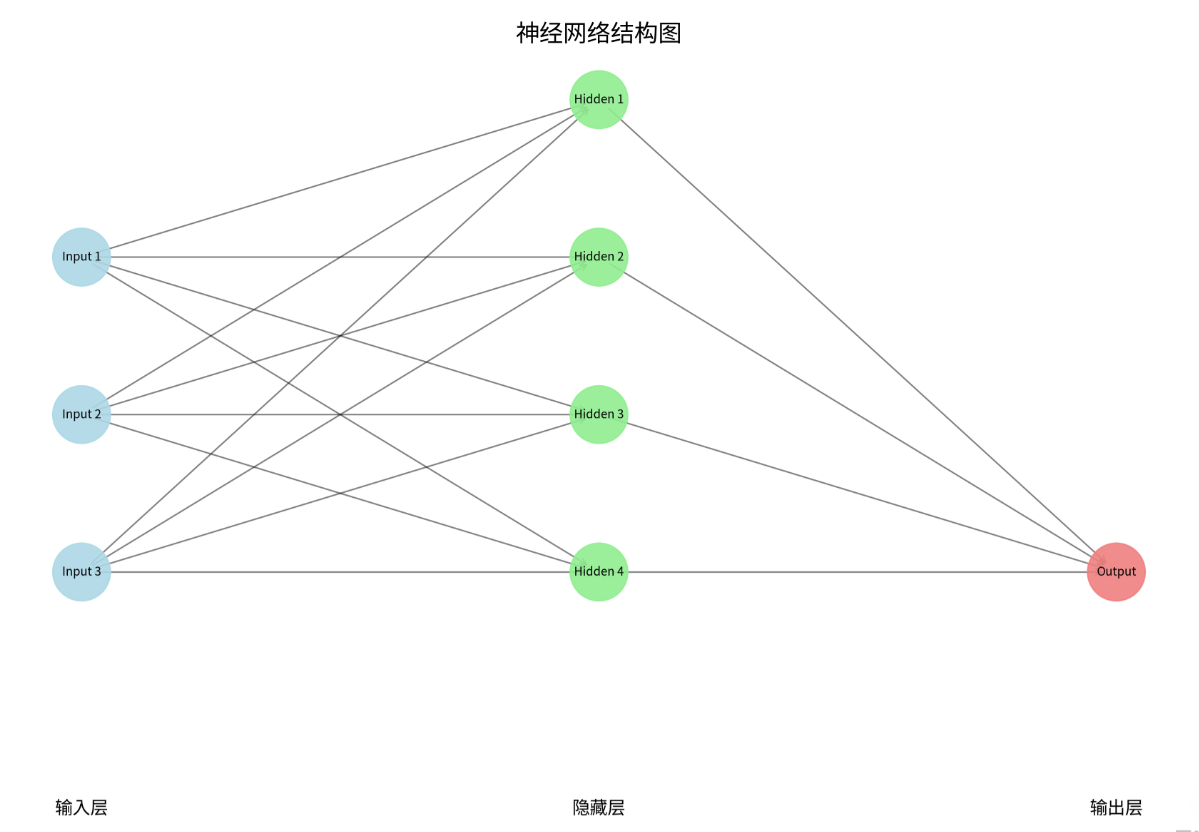
1.2 前向传播(Forward Propagation)
前向传播是指输入数据从输入层开始,逐层向前计算,最终得到预测输出的过程。每一步都是简单的矩阵乘法和激活函数计算。
1.3损失函数(Loss Function)
损失函数衡量模型预测值与真实值之间的差距。训练的目标就是最小化这个损失。对于回归任务常用均方误差(MSE),对于分类任务常用交叉熵。
1.4 梯度下降(Gradient Descent)
梯度下降是一种优化算法,通过计算损失函数对每个参数的梯度(偏导数),并沿着梯度的负方向更新参数,从而逐步减小损失。
1.5 反向传播(Backpropagation)
反向传播利用链式法则,从输出层开始向后逐层计算损失对每个参数的梯度。它高效地计算出所有参数的梯度,供梯度下降使用。
2 语言模型
语言模型(Language Model) 的核心任务是计算一个词序列出现的概率,或者更常见地,根据上文预测下一个词的概率。
句子 S = [ w₁, w₂, w₃, …, wₙ ]
整个句子出现的概率:
P(S) = P(w₁) · P(w₂|w₁) · P(w₃|w₁,w₂) · … · P(wₙ|w₁,…,wₙ₋₁)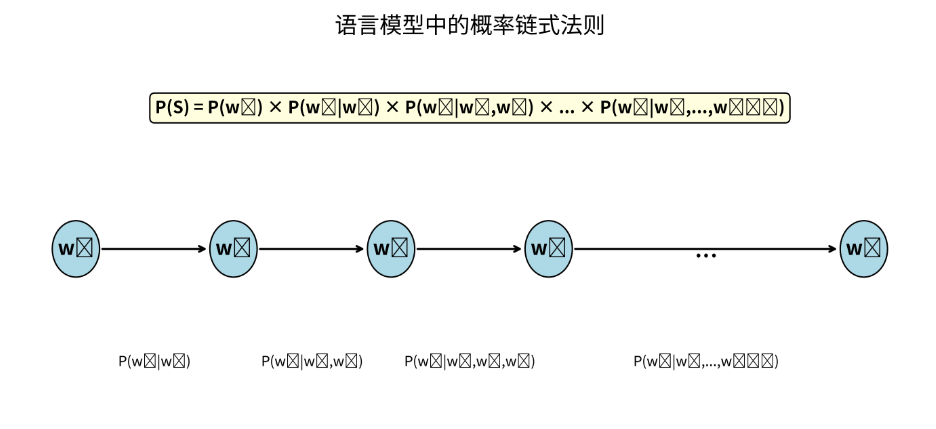
根据建模方式的不同,语言模型主要分为两类:自回归和自编码。
2.1 自回归语言模型(Autoregressive LM)
自回归模型按照从左到右的顺序,每次根据已知的前文预测下一个词。这类模型是单向的(只能利用上文信息)。典型代表是 GPT 系列(Generative Pre-trained Transformer)。
训练目标:最大化给定上文条件下,下一个词出现的概率(即最大似然估计)。对于句子 S,损失函数为: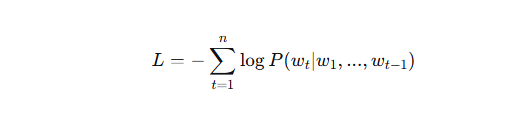
特点:
天然适合文本生成任务(续写、对话、故事生成)。
在训练时使用因果掩码(Causal Mask),确保注意力只能看到当前位置之前的 token。
例子:
输入:“今天天气”
【自回归语言模型(以 GPT 为代表)】
↓
【单向:只能看左边,不能看右边】
输入句子序列: w₁ → w₂ → w₃ → … → wₜ₋₁ → ?
↑ ↑ ↑ ↑
└──────┴──────┴────────────┘
上文
↓ 模型预测
P(wₜ | w₁, w₂, ..., wₜ₋₁) 【下一个词概率】
【因果掩码 Causal Mask】
(注意力只能看到当前及之前的 token)
位置: 1 2 3 4 … t
┌───────────────────────────┐
1 │ ✔️ ❌ ❌ ❌ … ❌ │
2 │ ✔️ ✔️ ❌ ❌ … ❌ │
3 │ ✔️ ✔️ ✔️ ❌ … ❌ │
4 │ ✔️ ✔️ ✔️ ✔️ … ❌ │
…│ … │
t │ ✔️ ✔️ ✔️ ✔️ … ✔️ │
└───────────────────────────┘
只能看左边 & 当前,不能看右边
=====================================================================
【训练目标:最大似然 → 最小化损失】
L = - Σₜ=1ⁿ log P(wₜ | w₁,…,wₜ₋₁)
含义:
让模型“更有把握”猜对每一个真实出现的下一个词。
=====================================================================
【文本生成示例】
输入: 今天天气
↓
模型输出概率:
P(不错 | 今天天气) = 0.6
P(很好 | 今天天气) = 0.3
P(下雨 | 今天天气) = 0.1
↓
贪心输出: 今天天气 不错
采样生成: top-k / nucleus 采样 → 增加多样性
=====================================================================
2.2 自编码语言模型(Autoencoding LM)
自编码模型不按顺序预测,而是通过掩码语言建模(Masked Language Modeling,MLM) 任务来学习。它会随机掩盖输入中的一部分词,然后要求模型根据上下文预测被掩盖的词。因为可以看到被掩盖词两侧的信息,这类模型是双向的。典型代表是 BERT(Bidirectional Encoder Representations from Transformers)。
训练目标:对于被掩盖的 token,最小化预测分布与真实 token 的交叉熵。
特点:
能更好地捕捉上下文的双向信息,在自然语言理解任务(如分类、情感分析、问答)上表现优异。
不适合直接用于文本生成(因为不是顺序预测),但可以通过改造(如结合自回归头)用于生成。
例子:
输入句子:“我今天[MASK]去公园玩。”
【自编码语言模型(以 BERT 为代表)】
↓
【双向:同时看左边 + 右边上下文】
=====================================================================
核心思想:掩码语言模型 MLM(Masked Language Modeling)
原始句子:
我 今天 要 去 公园 玩。
随机掩码后输入:
我 今天 [MASK] 去 公园 玩。
↑
被遮住
模型任务:
根据【左边 + 右边】所有词,预测 [MASK] 位置原来的词
=====================================================================
双向结构(和自回归最大区别)
【自回归 GPT:单向】
只能看左边 → 预测下一个词
w1 w2 w3 … wt-1 → ?
【自编码 BERT:双向】
左边 + 右边 一起看 → 预测中间被遮住的词
… 左上下文 … [MASK] … 右上下文 …
=====================================================================
因果掩码 vs 双向注意力(一眼对比)
【GPT 因果掩码】 【BERT 双向注意力】
只能看左/当前 所有位置互相可见
┌─────────────┐ ┌─────────────┐
│✔️❌❌❌…│ │✔️✔️✔️✔️…│
│✔️✔️❌❌…│ │✔️✔️✔️✔️…│
│✔️✔️✔️❌…│ │✔️✔️✔️✔️…│
│…│ │…│
└─────────────┘ └─────────────┘
=====================================================================
训练目标:
对所有被 [MASK] 的位置,
最小化 模型预测token 与 真实token 的交叉熵。
直观理解:
尽量猜对被遮住的每个词。
=====================================================================
输入:
我 今天 [MASK] 去 公园 玩。
模型看到:
左边:我 今天
右边:去 公园 玩
模型预测概率:
P(想 | …) = 0.7
P(要 | …) = 0.2
P(打算 | …) = 0.1
输出:
我 今天 想 去 公园 玩。
=====================================================================
3、预训练与微调
在大模型时代,“预训练+微调”是一种主流范式,它解决了标注数据稀缺且昂贵的问题。
3.1 预训练(Pre-training)
预训练阶段在海量无标注文本数据上进行自监督学习,让模型学习通用的语言知识(语法、语义、事实等)。模型通过上述语言模型任务(如自回归或自编码)进行训练,无需人工标注。这一阶段通常耗费巨大算力,但得到的基座模型(Foundation Model)具备强大的语言理解和生成能力。
例子:GPT-3 在 45TB 的文本数据(包括网页、书籍、维基百科等)上进行了预训练,学习到如何续写文本、回答问题、翻译等能力,但此时模型还没有针对特定任务进行优化。
3.2 微调(Fine-tuning)
微调阶段在预训练模型的基础上,使用少量有标注的下游任务数据,对模型参数进行进一步更新(或添加一个小的任务头),使模型适应特定任务。由于预训练模型已经具备良好的初始化,微调只需很少的轮次和标注数据即可达到优异效果。
例子(以BERT为例):
预训练:BERT 在 BookCorpus 和英文维基百科(约 33 亿词)上进行 MLM 和下一句预测(NSP)任务预训练。
微调:现在我们想做一个情感分类任务(判断电影评论是正面还是负面)。我们使用标注好的电影评论数据集(比如 1 万条评论,每条有“正面”或“负面”标签)。在 BERT 的基础上,我们在 [CLS] 位置的输出上添加一个简单的线性分类层,然后用标注数据微调整个模型。微调后,BERT 就能准确地对新评论进行情感分类。
另一种微调方式(GPT):对于自回归模型,微调时通常将下游任务也构造成文本生成的形式。例如,在机器翻译任务中,可以构造输入:“Translate English to French: {英语句子}”,然后让模型生成对应的法语翻译。这种方式被称为提示微调(Prompt Tuning) 或指令微调(Instruction Tuning)。
3.3 概念延伸
全量微调(Full Fine-tuning):更新所有预训练参数,适用于下游数据量充足时。
参数高效微调(Parameter-Efficient Fine-tuning,PEFT):如 LoRA(Low-Rank Adaptation)、Adapter 等,只更新少量额外参数,大大降低存储和计算开销。
指令微调(Instruction Tuning):在大量任务上以指令形式微调模型,使模型能遵循人类指令,如 ChatGPT 的训练第一步。
总结
为什么预训练+微调有效?
知识迁移:预训练模型学习到的通用语言表示可以迁移到各种下游任务,避免了从零开始训练。
数据效率:微调只需要少量标注数据,因为模型已经具备了语言理解能力。
收敛快:预训练提供了良好的初始化,微调阶段收敛迅速,计算成本低。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)