深度学习分类任务
环境准备与可复现设置
import random
import torch
import torch.nn as nn
import numpy as np
import os
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
from torchvision import transforms
import time
import matplotlib.pyplot as plt
from model_utils.model import initialize_model
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
seed_everything(0)| 导入包 | 作用 | 具体使用 |
|---|---|---|
random |
Python 随机数 | 固定随机种子 |
torch |
PyTorch 核心 | 张量、GPU加速、自动求导、模型定义、向前/反向传播 |
torch.nn |
神经网络模块 | 定义模型、损失函数、网络结构(如nn.Linear) |
numpy |
数值计算 | 存储和预处理图像数据、准确率计算 |
os |
系统操作 | 遍历文件、拼接路径、设置环境变量 |
PIL.Image |
图像读取 | 加载和 resize 图片 |
Dataset, DataLoader |
数据加载 | 自定义数据集 + 批量加载 |
tqdm |
进度条 | 显示数据读取进度 |
transforms |
图像变换 | 数据增强、格式转换(ToTensor()) |
time |
时间处理 | 记录训练耗时 |
matplotlib.pyplot |
绘图 | loss/acc 曲线可视化 |
initialize_model |
自定义模型工厂 | 快速切换 VGG/ResNet/MyModel等模型 |
seed_everything(0) 函数系统性地固定了 PyTorch(CPU/GPU)、cuDNN、NumPy、Python 内置 random 模块以及 Python 哈希种子等随机源,确保模型初始化、数据加载顺序、训练过程和评估结果在多次运行中完全一致,从而实现深度学习实验的可复现性。
数据预处理
train_transform = transforms.Compose( #数据增广,增加训练样本多样性
[
transforms.ToPILImage(), #数据:224,224,3,模型:3,224,224,numpy array → PIL Image
transforms.RandomResizedCrop(224), # 随机裁剪+缩放(增强多样性)
transforms.RandomRotation(50), # 50°内随机旋转
transforms.ToTensor() #转为 [0,1] 的张量 tensor (C,H,W)
]
)
val_transform = transforms.Compose( #用原图进行验证,不进行变换
[
transforms.ToPILImage(), #224, 224, 3模型 :3, 224, 224
transforms.ToTensor()
]
)数据增强/增广(Data Augmentation) 是通过在训练阶段对输入样本施加一系列保持语义不变的随机变换,人工扩充训练集多样性,从而提升模型泛化能力、缓解过拟合的关键技术。
数据增强的前提是:变换后的样本仍属于原类别。例如:旋转小猫 30° 仍是小猫,但旋转文字图像 90° 可能就不可读了。因此,增强策略应符合任务先验(如自然图像不宜垂直翻转,毕竟天上不会长树),避免引入语义错误样本(如:将热狗旋转90°,看起来像一根棍子或不明物体,不再符合“热狗”的典型视觉概念 → 模型可能困惑)。
常见方法:
(1)几何变换:随机裁剪(RandomCrop)、随机缩放(Resize)、随机旋转(Rotation)、水平翻转(HorizontalFlip)等;
(2)颜色扰动:亮度、对比度、饱和度、色调的随机调整(ColorJitter);
(3)区域遮挡:随机擦除(RandomErasing)、CutOut 等;
| 维度 | 鲁棒性(Robustness) | 泛化性(Generalization) |
|---|---|---|
| 定义 | 模型对输入扰动(噪声、对抗攻击、异常值)的抵抗能力 | 模型在未见过的新数据上的表现能力 |
| 关注点 | 输入是否“干净”? (同一分布下的微小变化) |
数据是否“新”? (不同但同源的分布) |
| 测试方式 | 在原测试集上加噪声/扰动,看性能下降多少 | 在独立测试集(如验证集)上评估 |
| 类比 | “抗压能力”: 考试时教室很吵,你还能考好吗? |
“举一反三”: 学了例题,能做新题吗? |
| 典型场景 | - 对抗样本攻击 - 光照/遮挡变化 - 传感器噪声 |
- 训练集 vs 测试集分布差异 - 小样本迁移 - 域泛化(Domain Generalization) |
自定义数据集
class food_Dataset(Dataset):
def __init__(self, path, mode="train"):
self.mode = mode
if mode == "semi":
self.X = self.read_file(path)
else:
self.X, self.Y = self.read_file(path)
self.Y = torch.LongTensor(self.Y) #分类任务中标签为整数,转为长整形
if mode == "train": #对图片进行一次增广
self.transform = train_transform
else:
self.transform = val_transform
def read_file(self, path):
if self.mode == "semi":
file_list = os.listdir(path)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8) #将读出的RGB值改为整数
# 列出文件夹下所有文件名字
for j, img_name in enumerate(file_list):
img_path = os.path.join(path, img_name)
img = Image.open(img_path)
img = img.resize((HW, HW))
xi[j, ...] = img
print("读到了%d个数据" % len(xi))
return xi
else:
for i in tqdm(range(11)):
file_dir = path + "/%02d" % i #适配“00”、“01”的文件名
file_list = os.listdir(file_dir)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8) #以整数形式读取数据
yi = np.zeros(len(file_list), dtype=np.uint8)
# 列出文件夹下所有文件名字
for j, img_name in enumerate(file_list): #enumerate同时读取下标和文件名
img_path = os.path.join(file_dir, img_name)
img = Image.open(img_path)
img = img.resize((HW, HW)) #将图片大小从512*512改为224*224
xi[j, ...] = img
yi[j] = i
if i == 0:
X = xi
Y = yi
else:
X = np.concatenate((X, xi), axis=0) #axis=0在0维(竖直)方向上合并
Y = np.concatenate((Y, yi), axis=0)
print("读到了%d个数据" % len(Y))
return X, Y
def __getitem__(self, item):
if self.mode == "semi":
return self.transform(self.X[item]), self.X[item] #返回增广后的x和原始x
else:
return self.transform(self.X[item]), self.Y[item] #返回增广后的x和标签y
def __len__(self): #读取长度
return len(self.X)Dataset、Dataloader
| 组件 | 来源 | 作用 |
|---|---|---|
Dataset |
torch.utils.data.Dataset(抽象基类) |
定义“如何读取单个样本” (如:从文件读图 + 标签) |
DataLoader |
torch.utils.data.DataLoader(工具类) |
定义“如何批量加载+并行+打乱” (如:batch_size=16, shuffle=True) |
第一步:创建 food_Dataset 实例(数据源)
train_set = food_Dataset(train_path, "train") # ← 这是一个 Dataset 对象
val_set = food_Dataset(val_path, "val") # ← 这也是一个 Dataset 对象
no_label_set = food_Dataset(no_label_path, "semi") # ← 同样是 Dataset此时它们只是可索引的对象,但不能直接用于训练循环
第二步:用 DataLoader 包装 → 变成生成器
from torch.utils.data import DataLoader # ← 导入官方 DataLoader
train_loader = DataLoader(
train_set, # ← 把 food_Dataset 实例传进去
batch_size=16, # 每次取 16 个样本
shuffle=True # 打乱顺序(仅训练集需要)
)
val_loader = DataLoader(val_set, batch_size=16, shuffle=True)
no_label_loader = DataLoader(no_label_set, batch_size=16, shuffle=False)DataLoader 接收任意 Dataset 子类,自动完成:
- 批量打包:把 16 个
(image, label)合并成(batch_x, batch_y) - 张量化:自动调用
torch.stack()把 list 转为 tensor - 打乱顺序:
shuffle=True时每 epoch 重排
这种解耦设计可以:改 Dataset/ DataLoader 进而更换数据源/调整加载策略(只需改参数)
半监督核心 —— 伪标签机制
class semiDataset(Dataset):
def __init__(self, no_label_loder, model, device, thres=0.99): #置信度0.99
x, y = self.get_label(no_label_loder, model, device, thres)
if x == []:
self.flag = False #表示半监督数据集中根本没有高置信度样本
else:
self.flag = True
self.X = np.array(x)
self.Y = torch.LongTensor(y)
self.transform = train_transform
def get_label(self, no_label_loder, model, device, thres):
model = model.to(device)
pred_prob = []
labels = []
x = []
y = []
soft = nn.Softmax()
with torch.no_grad(): #数据在模型上会积攒梯度,而无标签数据一开始只要预测,不要训练,就用with torch.no_grad()防止积攒梯度
for bat_x, _ in no_label_loder:
bat_x = bat_x.to(device)
pred = model(bat_x)
pred_soft = soft(pred)
pred_max, pred_value = pred_soft.max(1) #获取最大值及其下标
pred_prob.extend(pred_max.cpu().numpy().tolist()) #将预测最大值取下放至cpu后转为数组再转为列表
labels.extend(pred_value.cpu().numpy().tolist())
for index, prob in enumerate(pred_prob):
if prob > thres:
x.append(no_label_loder.dataset[index][1]) #这里取的是原始未增广图像(来自 food_Dataset.__getitem__ 的第二个返回值)
y.append(labels[index])
return x, y
def __getitem__(self, item):
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.X)
def get_semi_loader(no_label_loder, model, device, thres): #在训练过程中才有可能产生semi_dataset,因此要将semi_loader设置为函数
semiset = semiDataset(no_label_loder, model, device, thres)
if semiset.flag == False:
return None
else:
semi_loader = DataLoader(semiset, batch_size=16, shuffle=False)
return semi_loader利用当前模型对无标签数据进行预测,筛选预测概率超过阈值(如 0.99)的样本,并复用其原始未增强图像重新应用训练时的数据增强,确保伪标签数据在加入训练时仍具多样性;同时通过 flag 标志和辅助函数 get_semi_loader 实现空集安全处理,使主训练流程能无缝融合有标签与伪标签数据,有效提升模型在标注稀缺场景下的泛化能力。
模型选择与迁移学习
model, _ = initialize_model("vgg", 11, use_pretrained=True) #选择model.py中的模型
通过 initialize_model 函数提供了一个统一接口,支持从轻量自定义 CNN 到主流 ImageNet 预训练模型(如 VGG、ResNet)的快速切换。
Model.py:
#Model.py:
import torch
import torch.nn as nn
import numpy as np
from timm.models.vision_transformer import PatchEmbed, Block
import torchvision.models as models
def set_parameter_requires_grad(model, linear_probing):
if linear_probing:
for param in model.parameters():
param.requires_grad = False # 一个参数的requires_grad设为false, 则训练时就会不更新
class MyModel(nn.Module): #自己的模型
def __init__(self,numclass = 2):
super(MyModel, self).__init__()
self.layer0 = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
) #112*112
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
) #56*56
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
) #28*28
self.layer3 = nn.Sequential(
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
) #14*14
self.pool1 = nn.MaxPool2d(2)#7*7
self.fc = nn.Linear(25088, 512)
# self.drop = nn.Dropout(0.5)
self.relu1 = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(512, numclass)
def forward(self,x):
x = self.layer0(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool1(x)
x = x.view(x.size()[0],-1) #view 类似于reshape 这里指定了第一维度为batch大小,第二维度为适应的,即剩多少, 就是多少维。
# 这里就是将特征展平。 展为 B*N ,N为特征维度。
x = self.fc(x)
# x = self.drop(x)
x = self.relu1(x)
x = self.fc2(x)
return x
# def model_Datapara(model, device, pre_path=None):
# model = torch.nn.DataParallel(model).to(device)
#
# model_dict = torch.load(pre_path).module.state_dict()
# model.module.load_state_dict(model_dict)
# return model
#传入模型名字,和分类数, 返回你想要的模型
def initialize_model(model_name, num_classes, linear_prob=False, use_pretrained=True):
# 初始化将在此if语句中设置的这些变量。
# 每个变量都是模型特定的。
model_ft = None
input_size = 0
if model_name =="MyModel":
if use_pretrained == True:
model_ft = torch.load('model_save/MyModel')
else:
model_ft = MyModel(num_classes)
input_size = 224
elif model_name == "resnet18":
""" Resnet18
"""
model_ft = models.resnet18(pretrained=use_pretrained) # 从网络下载模型 pretrain true 使用参数和架构, false 仅使用架构。
set_parameter_requires_grad(model_ft, linear_prob) # 是否为线性探测,线性探测: 固定特征提取器不训练。
num_ftrs = model_ft.fc.in_features #分类头的输入维度
model_ft.fc = nn.Linear(num_ftrs, num_classes) # 删掉原来分类头num_ftrs, 更改最后一层为想要的分类数的分类头num_classes。
input_size = 224
elif model_name == "resnet50":
""" Resnet50
"""
model_ft = models.resnet50(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "googlenet":
""" googlenet
"""
model_ft = models.googlenet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
""" Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg11_bn(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
# 处理辅助网络
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# 处理主要网络
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model_utils name, exiting...")
exit()
return model_ft, input_size
def prilearn_para(model_ft,linear_prob):
# 将模型发送到GPU
device = torch.device("cuda:0")
model_ft = model_ft.to(device)
# 在此运行中收集要优化/更新的参数。
# 如果我们正在进行微调,我们将更新所有参数。
# 但如果我们正在进行特征提取方法,我们只会更新刚刚初始化的参数,即`requires_grad`的参数为True。
params_to_update = model_ft.parameters()
print("Params to learn:")
if linear_prob:
params_to_update = []
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t",name)
else:
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t",name)
#
# # 观察所有参数都在优化
# optimizer_ft = optim.SGD(params_to_update, lr=0.001, momentum=0.9)
def init_para(model):
def weights_init(model):
classname = model.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(model.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(model.weight.data, 1.0, 0.02)
nn.init.constant_(model.bias.data, 0)
model.apply(weights_init)
return model迁移学习:数据量少时的最佳选择 —— “站在巨人的肩膀上”
在深度学习中,“数据即石油”,但高质量标注数据往往稀缺且昂贵。“迁移学习”复用在大规模数据集(如 ImageNet)上学到的知识,迁移到目标任务上,大幅降低对标注数据的依赖。
其核心思想是:预训练模型 = 通用特征提取器 + 特定分类头。
-
特征提取器(Feature Extractor):
通常指卷积主干网络(如 VGG 的前10层、ResNet 的除最后一层外的所有层)。它在 ImageNet 上学会了丰富的通用视觉特征(边缘、纹理、部件等),这些特征对大多数图像任务都有价值。 -
分类头(Classifier Head):
通常是最后的全连接层(或 1×1 卷积),专为原始任务(如 ImageNet 的 1000 类)设计。在迁移时,这一层必须替换为目标任务的类别数。
基于此,有两种主流迁移策略:
(1)线性探测(Linear Probing)—— “相信大佬”
线性探测是迁移学习中最保守也最稳定的策略。其核心思想是:完全信任在大规模数据集(如 ImageNet)上预训练好的特征提取器,认为它已经学到了足够通用且有效的视觉表示,因此在目标任务上只需学习一个新的“解读器”——即分类头。具体操作时,将预训练模型的主干网络(如 ResNet 的卷积层或 VGG 的特征部分)的所有参数冻结(设置 requires_grad=False),仅替换最后的分类层为目标任务的类别数,并只训练这一新层。由于大部分参数不更新,线性探测训练速度快、显存占用低,且几乎不会过拟合,特别适用于标注数据极少(如几百到一两千张图像)、计算资源有限,或目标任务与源任务(如自然图像分类)相似度较高的场景。它的局限在于无法根据新任务的特点调整特征表示,若目标域与 ImageNet 差异较大(如医学影像、遥感图像),性能可能受限。
(2)微调(Fine-tuning)—— “因地制宜”
微调则是一种更灵活、更具适应性的迁移学习策略。它不再将预训练特征视为固定不变的“真理”,而是允许模型根据目标任务的数据分布对已有特征进行适度调整。具体做法是:加载预训练模型后,替换分类头为目标类别数,然后解冻部分或全部网络层,以较小的学习率对整个模型(或主干网络的后几层)进行端到端训练。微调能够使特征提取器更好地捕捉目标域特有的语义信息(例如,Food-11 中食物的纹理、摆盘风格等),从而获得比线性探测更高的准确率。它适用于拥有中等规模标注数据(如几千至上万张)的场景,常见策略包括“全微调”(所有层更新)和“分层微调”(冻结浅层通用特征,仅微调深层语义特征)。需要注意的是,微调必须使用比从零训练小得多的学习率(通常为 1e-4 到 1e-5),以避免破坏预训练权重中已学到的有用知识,同时需配合良好的正则化手段以防过拟合。
训练循环、半监督集成与训练启动
def train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path):
model = model.to(device)
semi_loader = None
plt_train_loss = []
plt_val_loss = []
plt_train_acc = []
plt_val_acc = []
max_acc = 0.0
for epoch in range(epochs):
train_loss = 0.0
val_loss = 0.0
train_acc = 0.0
val_acc = 0.0
semi_loss = 0.0
semi_acc = 0.0
start_time = time.time()
model.train()
for batch_x, batch_y in train_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
train_bat_loss = loss(pred, target)
train_bat_loss.backward()
optimizer.step() # 更新参数 之后要梯度清零否则会累积梯度
optimizer.zero_grad()
train_loss += train_bat_loss.cpu().item()
train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
# pred.detach().cpu().numpy()将张量从神经网络上取下来放到cpu上转为矩阵以便计算
# argmax(), axis=1在横轴上指出最大值的下标与标签(target.cpu().numpy())对比以计算准确预测的数量
plt_train_loss.append(train_loss / train_loader.__len__()) #除以batch长度
plt_train_acc.append(train_acc/train_loader.dataset.__len__()) #除以数据集长度,记录准确率,
if semi_loader!= None:
for batch_x, batch_y in semi_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
semi_bat_loss = loss(pred, target)
semi_bat_loss.backward()
optimizer.step() # 更新参数 之后要梯度清零否则会累积梯度
optimizer.zero_grad()
semi_loss += semi_bat_loss.cpu().item()
semi_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
print("半监督数据集的训练准确率为", semi_acc/train_loader.dataset.__len__())
model.eval()
with torch.no_grad():
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss(pred, target)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
plt_val_loss.append(val_loss / val_loader.dataset.__len__())
plt_val_acc.append(val_acc / val_loader.dataset.__len__())
#在上面准确率达到指定值之后才生成semi_loader
if epoch%3 == 0 and plt_val_acc[-1] > 0.6:
semi_loader = get_semi_loader(no_label_loader, model, device, thres)
if val_acc > max_acc:
torch.save(model, save_path)
max_acc = val_acc
print('[%03d/%03d] %2.2f sec(s) TrainLoss : %.6f | valLoss: %.6f Trainacc : %.6f | valacc: %.6f' % \
(epoch, epochs, time.time() - start_time, plt_train_loss[-1], plt_val_loss[-1], plt_train_acc[-1], plt_val_acc[-1])
) # 打印训练结果。 注意python语法, %2.2f 表示小数位为2的浮点数, 后面可以对应。
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend(["train", "val"])
plt.show()
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title("acc")
plt.legend(["train", "val"])
plt.show()
train_path = r"......"
val_path = r"......"
no_label_path = r"......"
lr = 0.001
loss = nn.CrossEntropyLoss() #交叉熵损失
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-4) #优化器
device = "cuda" if torch.cuda.is_available() else "cpu"
save_path = "model_save/best_model.pth"
epochs = 15
thres = 0.99
train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path)在每轮训练中先用有标签数据更新模型,再定期(如每3个epoch)且仅当验证准确率超过阈值(如60%)时,触发伪标签生成流程,利用当前模型筛选高置信度无标签样本并构建半监督数据集;随后在同一次epoch内,将这些伪标签样本与原始有标签数据一并用于参数更新。
监督/无监督/半监督学习:
监督学习:
标签:所有训练数据都带有真实标签 y
核心思想:让模型从人工标注的“输入-标签”配对中直接学习映射关系。
具体流程:准备一个所有样本都带有真实标签的数据集,将输入数据送入模型得到预测结果,通过损失函数(如交叉熵)计算预测与真实标签之间的误差,再利用优化器根据梯度反向传播更新模型参数以不断缩小这一误差,如此迭代训练,直到模型在验证集上的性能达到最优或收敛,最终获得一个能对新输入做出准确预测的判别模型。
无监督学习:
标签:所有数据都没有标签
核心思想:让模型从人工标注的“输入-标签”配对中直接学习映射关系。
具体流程:准备一个所有样本都带有真实标签的数据集,将输入数据送入模型得到预测结果,通过损失函数(如交叉熵)计算预测与真实标签之间的误差,再利用优化器根据梯度反向传播更新模型参数以不断缩小这一误差,如此迭代训练,直到模型在验证集上的性能达到最优或收敛,最终获得一个能对新输入做出准确预测的判别模型。
半监督学习:
标签:同时使用少量有标签数据 + 大量无标签数据
准确率acc:在已训练模型准确率超过指定值后,无标签数据的预测值才会被作为标签
置信度:无标签数据的预测值超过置信度之后才会被采纳
准确率和置信度就像是采纳预测值之前的二把手
核心思想:在少量有标签数据的基础上,利用大量无标签数据提升模型泛化能力,通过模型自身生成高置信度伪标签来扩充训练集。
具体流程:首先对无标签数据集(no_labled_dataset)中的无标签数据(比如取其中一个为x)放入模型(只有高于指定准确率的模型才会被用于该预测)进行预测,得到预测值pred,其中包含置信度和预测值y共2个数据,当置信度高于指定值(比如0.99)时,就将无标签数据x以及预测的标签y放入一个新的数据集(如semi_dataset),该数据集中的数据便认为是预测准确的,与有标签数据集地位相同,可用于之后的模型训练。(对x进行数据增广(transforms)后预测,但加入新数据集的是原始x)
| 维度 | 监督学习 | 半监督学习 | 无监督学习 |
|---|---|---|---|
| 数据需求 | 全部有标签 | 少量有标签 + 大量无标签 | 全部无标签 |
| 学习目标 | 拟合 x → y 映射 | 利用无标签数据提升监督性能 | 发现数据内在结构 |
| 标签来源 | 人工标注 | 人工标注 + 模型生成(伪标签) | 无标签 |
| 适用场景 | 标注充足、任务明确 | 标注昂贵但有大量未标注数据 | 探索性分析、预训练 |
| 性能潜力 | 高(若有足够标注) | 常优于纯监督(在标注稀缺时) | 不直接用于分类等判别任务 |
优化器:根据损失函数的梯度,决定如何更新模型参数,从而让模型逐步逼近最优解。
SGD:只看当前点的梯度
Adam:以一定权重综合看当前和之前的梯度,自动更改学习率,梯度增大/减小→lr减小/增大
AdamW:在Adam基础上增加权重衰减
训练结果以及代码/模型调整:
模型MyModel:
编写的CNN模型准确率为35%,没有达到触发半监督学习的阈值。
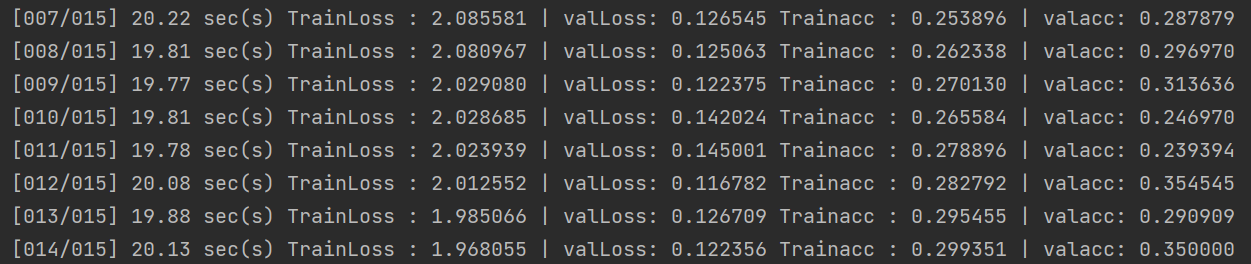
MyModel→VGG11:
将模型替换为vgg,准确率提升至50%,但仍没有触发半监督学习。
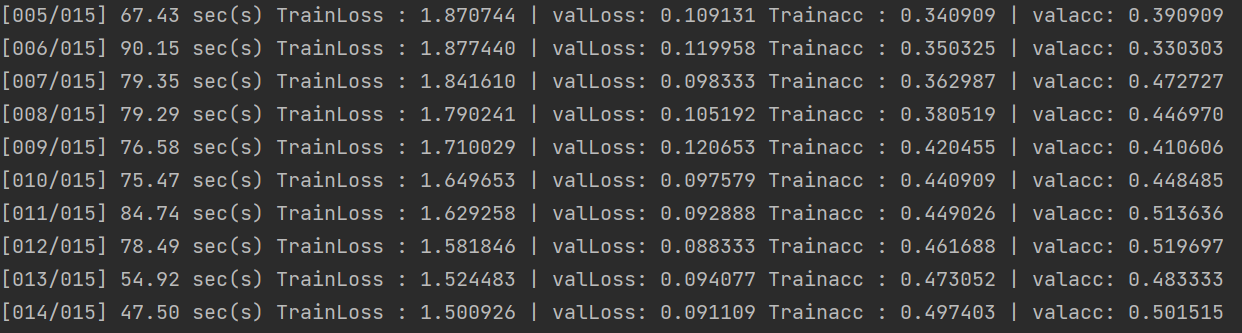
VGG11→ResNet18:
代码上更改:
①增加归一化:ResNet 对输入分布敏感,必须对齐 ImageNet 预处理
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
②数据增强部分:旋转角度从 50° 降至 15°(避免食物图像过度失真);新增 ColorJitter(亮度/对比度扰动),提升色彩鲁棒性;
transforms.RandomRotation(15),
transforms.ColorJitter(brightness=0.2, contrast=0.2),③food_Dataset.read_file() 中强制图像转为RGB:部分图像可能为灰度(单通道)或 RGBA(四通道),而 ResNet 要求 3 通道输入,保证数据一致性。
img = Image.open(img_path).convert('RGB')④train_val() 函数中新增:
早停机制:当验证准确率连续多轮未提升时提前终止训练,避免过拟合,节省计算资源,并自动保留最佳模型。
patience = 3; no_improve_count += 1; if no_improve_count >= patience: break伪标签损失加权:由于伪标签存在噪声风险,将其损失乘以小于 1 的权重(如 0.5),可降低其在总梯度中的影响,使模型更侧重有标签数据,提升训练稳定性。
semi_bat_loss = loss(pred, target) * pseudo_weight # pseudo_weight=0.5⑤semiDataset.get_label() 中新增
伪标签引入数量上限与排序机制:防止模型在早期阶段因置信度整体偏高而一次性引入大量低质量伪标签;通过限制数量并优先选择高置信样本,提升伪标签可靠性,避免噪声污染训练。
candidates.sort(key=lambda x: x[0], reverse=True)
selected = candidates[:max_samples] # max_samples=50⑥修改延迟伪标签触发条件:ResNet 收敛更快,但初期仍不稳定,延迟到至少第 5 轮后再启动。
if epoch >= 5 and epoch % 3 == 0 and current_val_acc > 0.6:模型准确率显著提升,为66%,触发半监督学习,准确率为46%,并且连续3轮训练准确率未得到提升,触发早停机制。
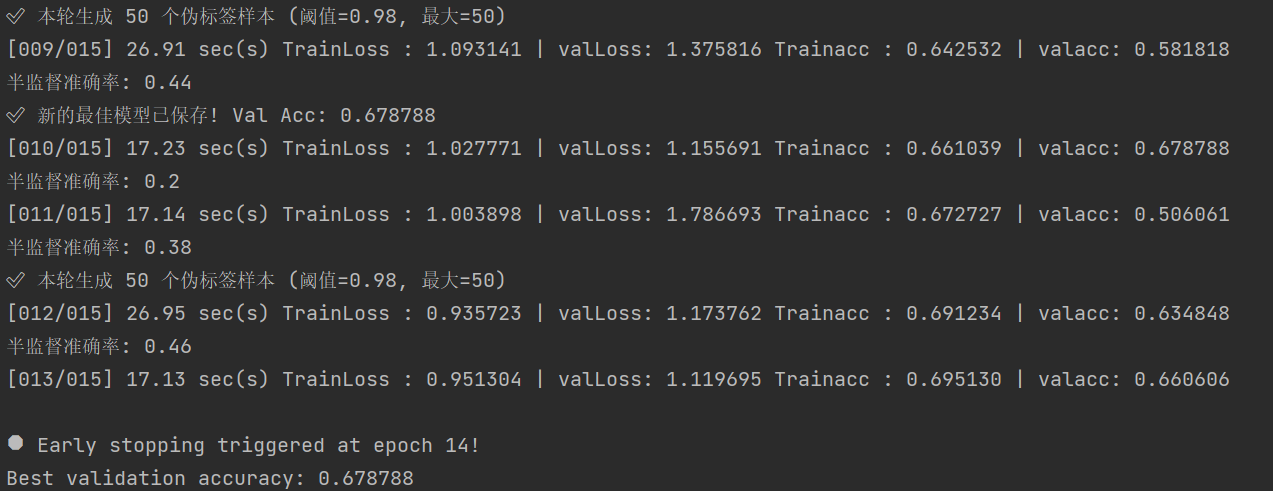
ResNet18→ResNet50
降低学习率:
lr = 1e-4 # 原为 0.001
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-4)ResNet50 参数量更大、梯度更敏感,若沿用较大初始学习率(如 1e-3),会导致训练初期剧烈震荡甚至发散;降低学习率可使优化过程更稳定,尤其在迁移学习微调阶段,小学习率能更好地保留预训练知识并精细调整高层分类器。
以全监督学习作为baseline,准确率为71%
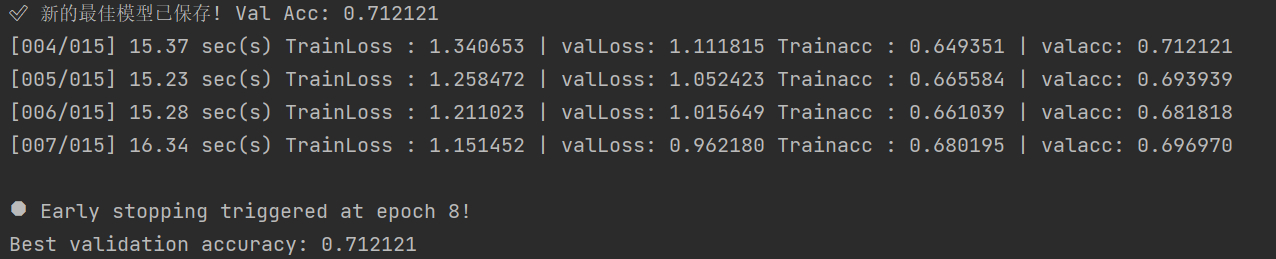
将迁移学习模式由全量微调转为冻结主干,只训练分类头,准确率为75%

最终代码:
import random
import torch
import torch.nn as nn
import numpy as np
import os
from PIL import Image #读取图片数据
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
from torchvision import transforms
import time
import matplotlib.pyplot as plt
from model_utils.model import initialize_model
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
seed_everything(0)
HW = 224
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
train_transform = transforms.Compose( #数据增广,增加训练样本多样性
[
transforms.ToPILImage(), #224, 224, 3模型 :3, 224, 224
transforms.RandomResizedCrop(224),
transforms.RandomRotation(15),
transforms.ColorJitter(brightness=0.2, contrast=0.2),
transforms.ToTensor(),
normalize
]
)
val_transform = transforms.Compose( #用原图进行验证,不进行变换
[
transforms.ToPILImage(), #224, 224, 3模型 :3, 224, 224
transforms.ToTensor(),
normalize
]
)
class food_Dataset(Dataset):
def __init__(self, path, mode="train"):
self.mode = mode
if mode == "semi":
self.X = self.read_file(path)
else:
self.X, self.Y = self.read_file(path)
self.Y = torch.LongTensor(self.Y) #标签转为长整形\
if mode == "train":
self.transform = train_transform
else:
self.transform = val_transform
def read_file(self, path):
if self.mode == "semi":
file_list = os.listdir(path)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)
# 列出文件夹下所有文件名字
for j, img_name in enumerate(file_list):
img_path = os.path.join(path, img_name)
img = Image.open(img_path).convert('RGB')
img = img.resize((HW, HW))
xi[j, ...] = img
print("读到了%d个数据" % len(xi))
return xi
else:
for i in tqdm(range(11)):
file_dir = path + "/%02d" % i #适配“00”、“01”的文件名
file_list = os.listdir(file_dir)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8) #以整数形式读取数据
yi = np.zeros(len(file_list), dtype=np.uint8)
# 列出文件夹下所有文件名字
for j, img_name in enumerate(file_list):
img_path = os.path.join(file_dir, img_name)
img = Image.open(img_path).convert('RGB')
img = img.resize((HW, HW)) #将图片大小从512*512改为224*224
xi[j, ...] = img
yi[j] = i
if i == 0:
X = xi
Y = yi
else:
X = np.concatenate((X, xi), axis=0)
Y = np.concatenate((Y, yi), axis=0)
print("读到了%d个数据" % len(Y))
return X, Y
def __getitem__(self, item):
if self.mode == "semi":
return self.transform(self.X[item]), self.X[item]
else:
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.X)
class semiDataset(Dataset):
def __init__(self, no_label_loader, model, device, thres=0.95, max_samples=200):
x, y = self.get_label(no_label_loader, model, device, thres, max_samples)
if len(x) == 0:
self.flag = False
else:
self.flag = True
# self.X = np.array(x)
self.X = np.stack(x, axis=0)
self.Y = torch.LongTensor(y)
self.transform = train_transform
def get_label(self, no_label_loader, model, device, thres, max_samples):
model.eval()
pred_prob = []
labels = []
all_images = []
soft = nn.Softmax(dim=1) # ← 显式指定 dim=1
with torch.no_grad():
for bat_x, orig_img in no_label_loader:
bat_x = bat_x.to(device)
pred = model(bat_x)
pred_soft = soft(pred)
pred_max, pred_value = pred_soft.max(1)
pred_prob.extend(pred_max.cpu().numpy())
labels.extend(pred_value.cpu().numpy())
all_images.extend(orig_img)
# 收集候选样本
candidates = []
for i, prob in enumerate(pred_prob):
if prob > thres:
candidates.append((prob, labels[i], all_images[i]))
if not candidates:
print("⚠️ 本轮无满足置信度的样本")
return [], []
# 按置信度降序排序(优先选高置信样本)
candidates.sort(key=lambda x: x[0], reverse=True)
# 严格限制数量
selected = candidates[:max_samples]
x = [item[2] for item in selected] # 原始图像
y = [item[1] for item in selected] # 伪标签
print(f"✅ 本轮生成 {len(x)} 个伪标签样本 (阈值={thres}, 最大={max_samples})")
return x, y
def __getitem__(self, item):
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.X)
def get_semi_loader(no_label_loader, model, device, thres, max_samples=200):
semiset = semiDataset(no_label_loader, model, device, thres, max_samples)
if not semiset.flag:
return None
else:
return DataLoader(semiset, batch_size=16, shuffle=True)
class myModel(nn.Module):
def __init__(self, num_class):
super(myModel, self).__init__()
#3 *224 *224 -> 512*7*7 -> 拉直 -》全连接分类
self.conv1 = nn.Conv2d(3, 64, 3, 1, 1) # 64*224*224
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU()
self.pool1 = nn.MaxPool2d(2) #64*112*112
self.layer1 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1), # 128*112*112
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2) #128*56*56
)
self.layer2 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2) #256*28*28
)
self.layer3 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2) #512*14*14
)
self.pool2 = nn.MaxPool2d(2) #512*7*7
self.fc1 = nn.Linear(25088, 1000) #25088->1000
self.relu2 = nn.ReLU()
self.fc2 = nn.Linear(1000, num_class) #1000->11
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pool1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool2(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.relu2(x)
x = self.fc2(x)
return x
def train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path):
model = model.to(device)
semi_loader = None
plt_train_loss = []
plt_val_loss = []
plt_train_acc = []
plt_val_acc = []
#早停相关变量
best_val_acc = 0.0 # 记录历史最高验证准确率
patience = 3 # 允许多少轮不提升
no_improve_count = 0 # 连续未提升的轮数
for epoch in range(epochs):
train_loss = 0.0
val_loss = 0.0
train_acc = 0.0
val_acc = 0.0
semi_loss = 0.0
semi_acc = 0.0
start_time = time.time()
#训练有标签数据
model.train()
for batch_x, batch_y in train_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
train_bat_loss = loss(pred, target)
train_bat_loss.backward()
optimizer.step()
optimizer.zero_grad()
train_loss += train_bat_loss.cpu().item()
train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
plt_train_loss.append(train_loss / len(train_loader))
plt_train_acc.append(train_acc / len(train_loader.dataset))
#训练伪标签数据(如果有)
if semi_loader is not None:
pseudo_weight = 0.5 # ← 伪标签损失权重(0.3~0.7 之间可调)
for batch_x, batch_y in semi_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
semi_bat_loss = loss(pred, target) * pseudo_weight # ← 乘以权重
semi_bat_loss.backward()
optimizer.step()
optimizer.zero_grad()
semi_loss += semi_bat_loss.cpu().item()
semi_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
semi_total = len(semi_loader.dataset)
print("半监督准确率:", semi_acc / semi_total)
#验证阶段
model.eval()
with torch.no_grad():
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss(pred, target)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
plt_val_loss.append(val_loss / len(val_loader))
current_val_acc = val_acc / len(val_loader.dataset)
plt_val_acc.append(current_val_acc)
if epoch >= 5 and epoch % 3 == 0 and current_val_acc > 0.55:
semi_loader = get_semi_loader(
no_label_loader,
model,
device,
thres=0.98,
max_samples=50
)
#早停逻辑
if current_val_acc > best_val_acc:
best_val_acc = current_val_acc
no_improve_count = 0
# 保存当前最佳模型
torch.save(model.state_dict(), save_path) # 推荐保存 state_dict
print(f"✅ 新的最佳模型已保存! Val Acc: {best_val_acc:.6f}")
else:
no_improve_count += 1
print('[%03d/%03d] %2.2f sec(s) TrainLoss : %.6f | valLoss: %.6f Trainacc : %.6f | valacc: %.6f' % \
(epoch, epochs, time.time() - start_time, plt_train_loss[-1], plt_val_loss[-1],
plt_train_acc[-1], current_val_acc))
if no_improve_count >= patience:
print(f"\n🛑 Early stopping triggered at epoch {epoch + 1}!")
print(f"Best validation accuracy: {best_val_acc:.6f}")
break
plt.figure()
plt.plot(plt_train_loss, label="train")
plt.plot(plt_val_loss, label="val")
plt.title("Loss")
plt.legend()
plt.show()
plt.figure()
plt.plot(plt_train_acc, label="train")
plt.plot(plt_val_acc, label="val")
plt.title("Accuracy")
plt.legend()
plt.show()
train_path = r""
val_path = r""
no_label_path = r""
train_set = food_Dataset(train_path, "train")
val_set = food_Dataset(val_path, "val")
no_label_set = food_Dataset(no_label_path, "semi")
train_loader = DataLoader(train_set, batch_size=16, shuffle=True)
val_loader = DataLoader(val_set, batch_size=16, shuffle=True)
no_label_loader = DataLoader(no_label_set, batch_size=16, shuffle=False)
model, _ = initialize_model("resnet50", 11, use_pretrained=True)
model, _ = initialize_model("resnet50", 11, use_pretrained=True)
for param in model.parameters():
param.requires_grad = False
for param in model.fc.parameters():
param.requires_grad = True
lr = 1e-4
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(
filter(lambda p: p.requires_grad, model.parameters()),
lr=lr,
weight_decay=1e-4
)
device = "cuda" if torch.cuda.is_available() else "cpu"
save_path = "model_save/best_model_resnet50.pth"
epochs = 15
thres = 0.98
train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path)
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)