LangChain 框架 | 精简+案例版
目录
实战 2:提示模板复用(ChatPromptTemplate)
实战 3:少样本提示(FewShotChatMessagePromptTemplate)
实战 4:列表输出解析(CommaSeparatedListOutputParser)
实战 5:结构化信息提取(PydanticOutputParser)
一、LangChain 框架基础
1.1 LLM 与 Chat Model 核心区别
LLM(大语言模型):本质是 Transformer 解码器架构的生成式模型,核心逻辑是根据上文 token 预测下一个 token,仅支持单轮文本生成,无原生上下文记忆,直接调用 API 为独立单次交互。
Chat Model(聊天模型):是 LLM 的场景化优化版本,像豆包、通义千问等对话产品均属此类,具备上下文记忆能力,输入为结构化角色消息(系统 / 用户 / AI 消息),适配多轮对话场景。
1.2 LangChain 框架定位
LangChain 并非新的大模型,而是LLM 应用开发的标准化框架,将「模型调用、提示词编写、输出解析、流程串联」等复杂操作拆分为即插即用组件,无需从零开发,直接解决几大开发痛点:
- 大模型输出格式混乱
- 重复编写提示词效率低
- 少样本引导模型输出困难
二、6 大实战案例手把手教学
环境前置
命令行窗口执行:
# 核心依赖安装
pip install langchain-openai
# 配置环境变量(推荐,避免密钥硬编码)
# Windows:set DASHSCOPE_API_KEY=你的阿里云API密钥
# Mac/Linux:export DASHSCOPE_API_KEY=你的阿里云API密钥
实战 1:Chat Model 基础对话调用
目标:掌握 LangChain 调用聊天模型的基础流程,理解角色消息格式
代码:
from langchain_openai import ChatOpenAI
from langchain.schema.messages import HumanMessage, SystemMessage
import os
# 初始化通义千问(OpenAI兼容接口)
model = ChatOpenAI(
model="qwen-plus",
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=1.2,
max_tokens=300
)
# 构造角色化对话消息
messages = [
SystemMessage(content="作为数学课助教,用通俗语言解释数学原理"),
HumanMessage(content="什么是勾股定理?"),
]
# 调用并输出
response = model.invoke(messages)
print(response.content)
结果: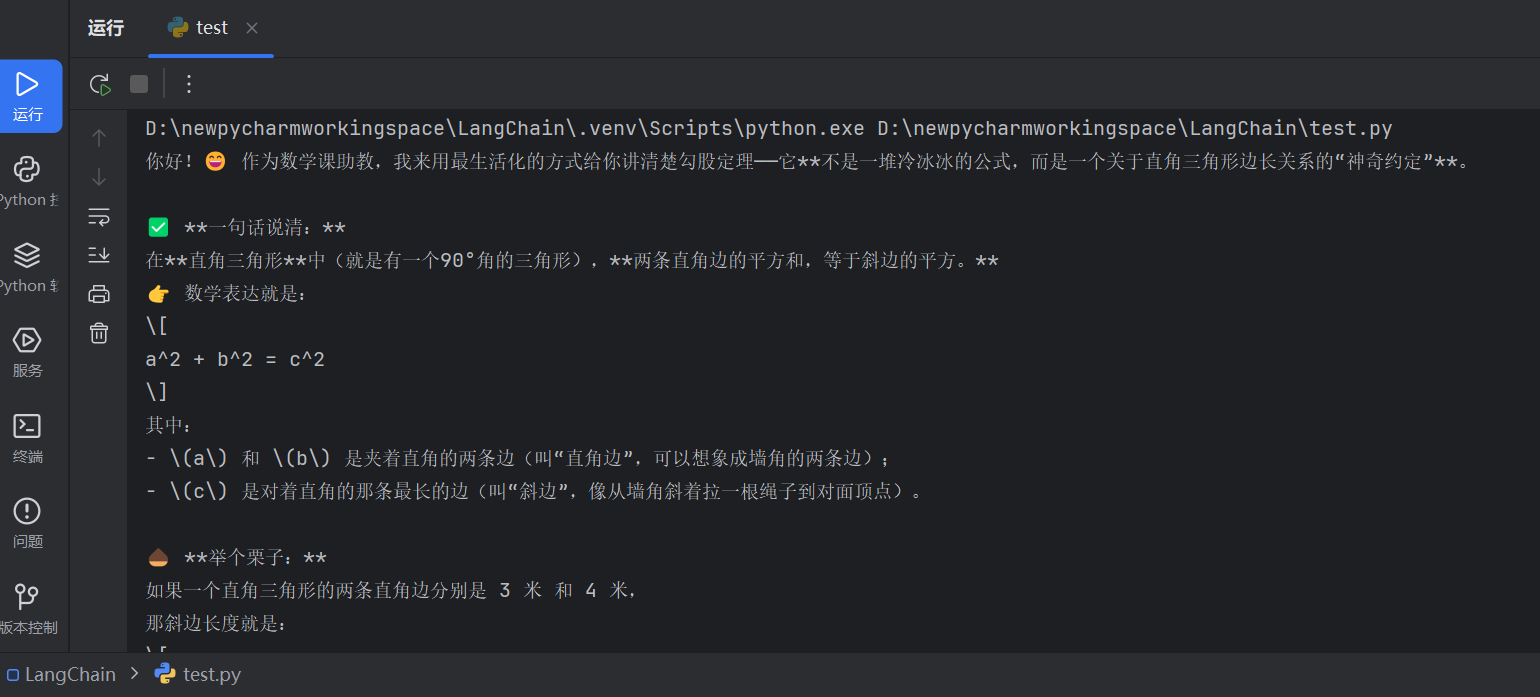
核心知识点:Chat Model 输入为角色化消息列表,SystemMessage定义模型行为,HumanMessage为用户输入。
实战 2:提示模板复用(ChatPromptTemplate)
目标:解决重复写提示词问题,实现动态参数替换与批量调用
代码:
from langchain.prompts import (
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
ChatPromptTemplate
)
from langchain_openai import ChatOpenAI
import os
# 1. 单独定义提示模板
system_template = SystemMessagePromptTemplate.from_template(
"你是专业翻译,将{input_language}译为{output_language},按{style}输出,仅返回译文"
)
human_template = HumanMessagePromptTemplate.from_template(
"文本:{text}"
)
# 2. 可以直接把1的单独定义整合为统一提示模板
prompt_template = ChatPromptTemplate.from_messages([
("system", "你是专业翻译,将{input_language}译为{output_language},按{style}输出,仅返回译文"),
("human", "文本:{text}")
])
# 3. 初始化模型
model = ChatOpenAI(
model="qwen-plus",
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 4. 批量调用
batch_inputs = [
{"input_language":"汉语","output_language":"汉语","text":"勿以善小而不为","style":"白话文"},
{"input_language":"法语","output_language":"英语","text":"Je suis désolé","style":"古英语"}
]
for item in batch_inputs:
res = model.invoke(prompt_template.invoke(item))
print(res.content)
结果: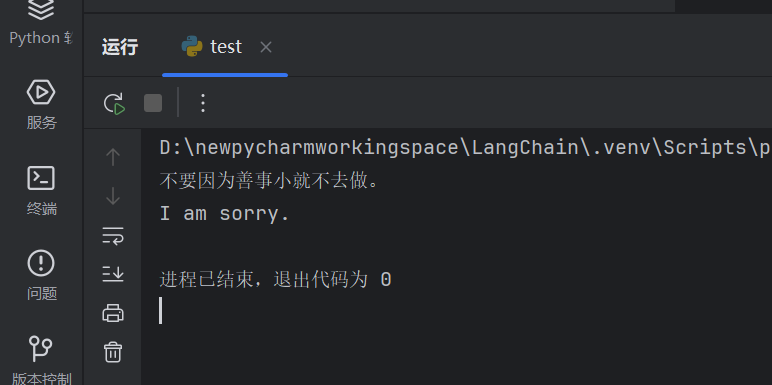
核心知识点:ChatPromptTemplate支持参数化提示词,整合多角色消息,大幅提升提示复用率。
实战 3:少样本提示(FewShotChatMessagePromptTemplate)
目标:通过少量示例引导模型固定输出格式,无需冗长提示词
代码:
from langchain_openai import ChatOpenAI
from langchain.prompts import FewShotChatMessagePromptTemplate, ChatPromptTemplate
import os
# 1. 定义示例格式
example_prompt = ChatPromptTemplate.from_messages([
("human", "格式化客户信息:\n姓名->{name}\n年龄->{age}\n城市->{city}"),
("ai", "##客户信息\n-姓名:{f_name}\n-年龄:{f_age}\n-地址:{f_addr}")
])
# 2. 少样本示例数据
examples = [
{"name":"张三","age":"27","city":"长沙","f_name":"张三","f_age":"27岁","f_addr":"湖南省长沙市"},
{"name":"李四","age":"42","city":"广州","f_name":"李四","f_age":"42岁","f_addr":"广东省广州市"}
]
# 3. 构建少样本提示
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples
)
# 4. 最终提示
final_prompt = ChatPromptTemplate.from_messages([
few_shot_prompt,
("human", "{input}")
])
# 5. 调用模型
model = ChatOpenAI(
model="qwen-plus",
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0.1
)
res = model.invoke(final_prompt.invoke({"input":"格式化:姓名->王五,年龄->31,城市->郑州"}))
print(res.content)
结果: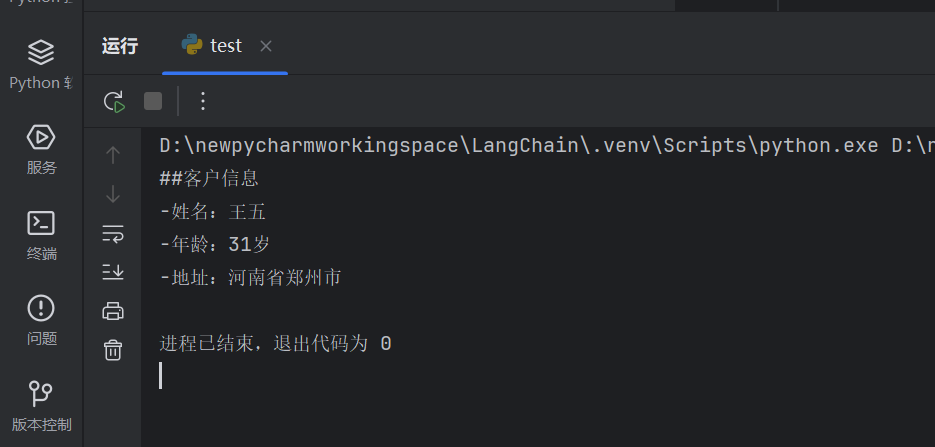
核心知识点:少样本提示用少量示例替代长提示,temperature=0.1保证输出格式稳定。
实战 4:列表输出解析(CommaSeparatedListOutputParser)
目标:将模型文本输出转为 Python 列表,解决格式混乱问题
第三方库:
ChatOpenAI:LangChain 封装的 OpenAI 风格聊天模型类(这里兼容阿里云通义千问的 API 格式),用于调用大模型。CommaSeparatedListOutputParser:逗号分隔列表解析器,能把模型返回的「A,B,C」格式文本转换成 Python 列表[A,B,C]。ChatPromptTemplate:LangChain 的聊天型提示模板,用于构建结构化的对话提示(区分系统 / 人类角色)。os:用于读取环境变量中的 API 密钥(避免硬编码密钥,更安全)。
代码:
from langchain_openai import ChatOpenAI
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import ChatPromptTemplate
import os
# 1. 初始化解析器
parser = CommaSeparatedListOutputParser()
parser_instr = parser.get_format_instructions()
# 2. 提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "{parser_instr}"),
("human", "列出5个{subject}汽车品牌")
])
# 3. 模型调用
model = ChatOpenAI(
model="qwen-plus",
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 4. 解析输出
raw_res = model.invoke(prompt.invoke({"subject":"中国","parser_instr":parser_instr}))
print(raw_res)
parsed_res = parser.invoke(raw_res)
print("解析后列表:", parsed_res)
注释:
parser = CommaSeparatedListOutputParser():创建解析器实例,核心作用是标准化模型输出格式,确保后续能把文本转成列表。parser_instr = parser.get_format_instructions():获取解析器的「格式说明指令」(比如:"请将输出格式化为逗号分隔的列表,例如:苹果,香蕉,橙子"),这行指令会传给模型,强制模型按逗号分隔的格式输出,方便后续解析。
ChatPromptTemplate.from_messages():按「角色 - 内容」的格式构建提示模板,模拟真实的对话场景:
("system", "{parser_instr}"):系统角色,传入解析器的格式说明,告诉模型「必须按逗号分隔列表输出」。("human", "列出5个{subject}汽车品牌"):人类用户的提问,{subject}是占位符(后续会传入「中国」「德国」等具体值)。
结果: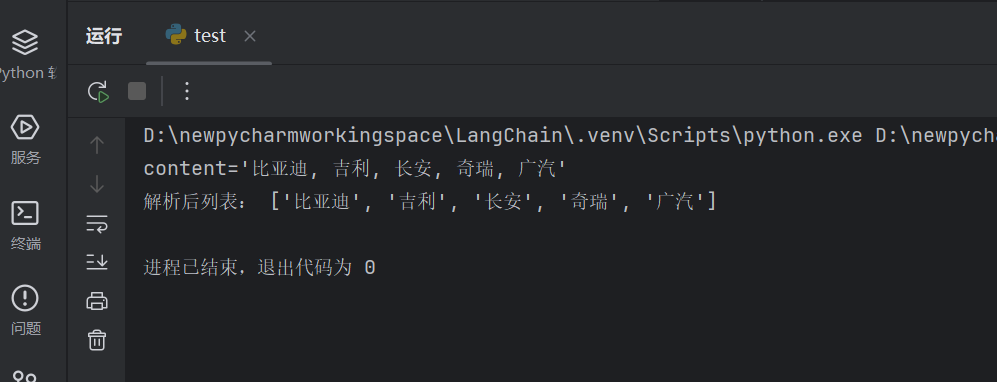
核心知识点:解析器自动将文本转为 Python 数据结构,无需手动字符串处理。
实战 5:结构化信息提取(PydanticOutputParser)
目标:自定义数据结构,精准提取多字段、多类型结构化信息,可以理解成Python的字典类型
第三方库:
from typing import List:导入列表类型注解,用于定义「题材」字段的类型(支持多个题材,如["喜剧", "悬疑"])。PydanticOutputParser:LangChain 专为 Pydantic 模型设计的输出解析器,能把模型返回的文本转换成 Pydantic 对象(强类型,可直接通过属性调用)。ChatPromptTemplate:构建结构化的聊天提示模板,区分系统 / 人类角色。BaseModel, Field:Pydantic 的核心类 ——BaseModel是自定义数据模型的基类,Field用于给字段添加描述、示例,帮助大模型理解要输出的内容。ChatOpenAI:兼容 OpenAI API 格式的模型调用类(这里用于调用阿里云通义千问)。
代码:
from typing import List
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
import os
# 1. 定义结构化数据模型
class FilmInfo(BaseModel):
film_name: str = Field(description="电影名", example="唐人街探案")
director: str = Field(description="导演", example="陈思诚")
genres: List[str] = Field(description="题材", example=["喜剧"])
# 2. 初始化解析器
parser = PydanticOutputParser(pydantic_object=FilmInfo)
# 3. 提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "{parser_instr} 输出使用中文"),
("human", "从概述提取电影名、导演、题材:###{text}###")
])
# 4. 调用&解析
model = ChatOpenAI(
model="qwen-plus",
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
text = """《唐人街探案》由陈思诚执导,是喜剧题材电影"""
res = model.invoke(prompt.invoke({
"text":text,
"parser_instr":parser.get_format_instructions()
}))
result = parser.invoke(res)
print(result)
print("电影名:", result.film_name)
print("题材:", result.genres)
注释:
class FilmInfo(BaseModel):自定义一个 Pydantic 数据模型,继承BaseModel,定义要提取的三个核心字段:film_name: str:字符串类型,存储电影名;Field(description="电影名", example="唐人街探案")给大模型提供「字段含义 + 示例」,让模型更精准输出。director: str:字符串类型,存储导演名。genres: List[str]:列表类型(支持多个题材),存储电影题材;示例["喜剧"]告诉模型要输出列表格式。
- Pydantic 对象本质是 基于 Pydantic 库的
BaseModel自定义类创建的实例,可以把它理解成:带 “严格说明书” 的结构化数据容器 —— 它不仅能存储数据,还会自动校验数据的类型和格式是否符合你定义的规则,且支持通过「对象。属性」的方式便捷访问数据。
结果: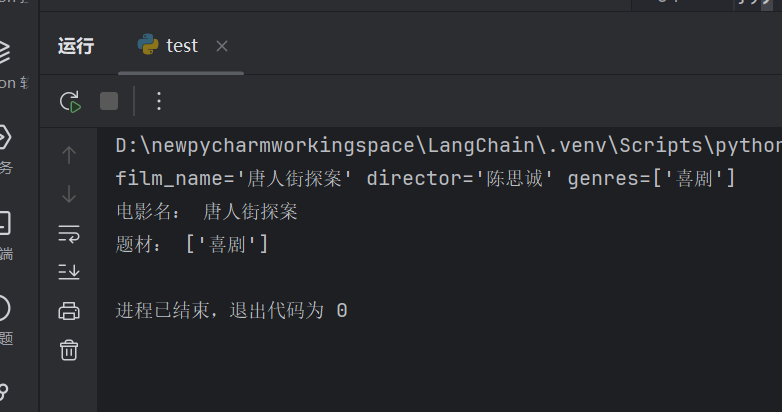
核心知识点:BaseModel定义输出规范,解析器自动校验数据类型,支持复杂结构化提取。
实战 6:LCEL 链式调用(核心最佳实践)
目标:用管道符|串联组件,极简代码实现全流程调用
代码:
from langchain_openai import ChatOpenAI
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import ChatPromptTemplate
import os
# 1. 定义组件
prompt = ChatPromptTemplate.from_messages([
("system", "{parser_instr}"),
("human", "列出5个{subject}汽车品牌")
])
parser = CommaSeparatedListOutputParser()
model = ChatOpenAI(
model="qwen-plus",
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 2. LCEL链式串联(核心)
chain = prompt | model | parser
# 3. 一键调用
res = chain.invoke({
"subject":"中国",
"parser_instr":parser.get_format_instructions()
})
print(res)
结果: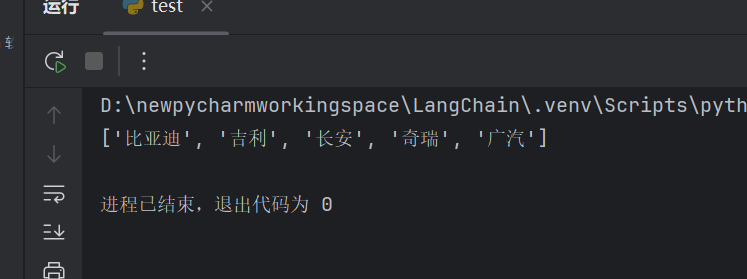
核心知识点:LCEL 用|定义数据流向,提示→模型→解析一步到位,代码极简、可复用性拉满。
三、实战总结
- Chat Model:角色化消息是对话基础,
SystemMessage控制模型行为; - 提示模板:参数化 + 复用,解决提示词冗余问题;
- 少样本提示:少量示例引导格式,比长提示更稳定;
- 输出解析:文本转结构化数据,适配工程化开发;
- Pydantic 解析:自定义结构,精准提取复杂信息;
- LCEL 链式:LangChain 标准开发范式,极简高效。
本文所有代码可直接运行,适配国内通义千问模型,替换model与 API 配置即可兼容 ChatGPT、Ollama 等模型,快速落地各类 LLM 应用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 27
27 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)