配电网光伏储能双层优化配置模型:选址定容与调度联合优化,含高比例可再生能源的IEEE33节点系...
配电网光伏储能双层优化配置模型(选址定容) 分布式电源选址定容 该程序主要方法复现《含高比例可再生能源配电网灵活资源双层优化配置》运行-规划联合双层配置模型,上层为光伏、储能选址定容模型,即优化配置,下层考虑弃光和储能出力,即优化调度,模型以IEEE33节点为例,采用粒子群算法求解,下层模型为运行成本和电压偏移量的多目标模型,并采用多目标粒子群算法得到pareto前沿解集,从中选择最佳结果带入到上层模型,最终实现上下层模型的各自求解和整个模型迭代优化。
最近在搞配电网光伏储能配置的项目,发现传统单层优化总有点顾头不顾尾。规划的时候不考虑运行细节,结果装完设备实际一跑,弃光率飙升、电压波动感人。于是尝试复现了一个双层优化模型,今天和大家唠唠实战中的代码实现细节。
上层负责拍板设备装哪儿、装多大,下层盯着实时调度别翻车。这俩就像老板和打工人,老板定战略(选址定容),员工搞执行(优化调度),但员工干不好老板也得调整策略。这里最刺激的是上下层数据得来回倒腾,整个系统像在玩跷跷板。
先看上层粒子群的粒子结构,每个粒子带着光伏和储能的身份证:
class UpperParticle:
def __init__(self, node_num=33):
self.position = np.concatenate([
np.random.choice([0,1], node_num), # 光伏选址
np.random.rand(node_num)*2000 # 储能定容
])
self.velocity = np.zeros_like(self.position)
self.best_pos = self.position.copy()这里有个骚操作——把离散的选址和连续的定容打包进同一个向量。初始化时光伏选址直接用0/1随机,储能容量给个最大值的随机数。但要注意粒子更新时得处理混合变量类型,我们后边会说到。
下层优化是整个模型的计算重心,每次上层粒子更新都要触发一次下层多目标优化。这里用带约束处理的非支配排序:
def lower_optimize(pv_nodes, storage_caps):
# 构造电网模型
grid = IEEE33Builder().build()
apply_devices(grid, pv_nodes, storage_caps)
# 多目标优化核心
problem = {
'obj_func': [
lambda x: operational_cost(x, grid), # 运行成本
lambda x: voltage_deviation(x, grid) # 电压偏移
],
'constraints': [
lambda x: check_power_flow(x), # 潮流约束
lambda x: x[storage_idx] <= max_discharge # 储能出力限制
]
}
return NSGA2Solver(problem).solve()这里用了经典的NSGA-II框架,但实际项目中我们发现当粒子群遇到多目标时,外部存档维护策略需要魔改。特别是电压偏移量这种指标,差个0.01pu可能就让整个解集结构大变样。
配电网光伏储能双层优化配置模型(选址定容) 分布式电源选址定容 该程序主要方法复现《含高比例可再生能源配电网灵活资源双层优化配置》运行-规划联合双层配置模型,上层为光伏、储能选址定容模型,即优化配置,下层考虑弃光和储能出力,即优化调度,模型以IEEE33节点为例,采用粒子群算法求解,下层模型为运行成本和电压偏移量的多目标模型,并采用多目标粒子群算法得到pareto前沿解集,从中选择最佳结果带入到上层模型,最终实现上下层模型的各自求解和整个模型迭代优化。
上下层迭代的核心在于适应度传递。每次下层输出Pareto前沿后,得挑个代表解反馈给上层:
def select_representative(pareto_front):
# 用模糊隶属度找折中解
costs = [sol.objectives[0] for sol in pareto_front]
deviations = [sol.objectives[1] for sol in pareto_front]
mu_cost = (costs - np.min(costs)) / (np.max(costs) - np.min(costs))
mu_dev = (deviations - np.min(deviations)) / (np.max(deviations) - np.min(deviations))
compromise_index = np.argmin(np.abs(mu_cost - mu_dev))
return pareto_front[compromise_index]这个选择策略有点像在钢丝上跳舞——既要运行成本低,又要电压稳定。实测中发现直接用理想点法容易陷入局部最优,而模糊选择在多数场景下更鲁棒。

主循环的迭代过程充满玄学色彩,这里看个简化版:
for epoch in range(100):
# 上层粒子更新
for p in upper_swarm:
new_pos = p.update()
# 设备参数注入下层
pareto = lower_optimize(extract_pv_nodes(new_pos),
extract_storage_caps(new_pos))
best_sol = select_representative(pareto)
# 计算总成本 = 投资成本 + 运行成本
total_cost = calc_investment(new_pos) + best_sol.objectives[0]
p.update_fitness(total_cost)
# 动态调整粒子群的惯性权重
w = 0.9 - 0.5*(epoch/100)这里藏了两个工程trick:一是投资成本计算要考虑设备寿命周期折算,二是惯性权重的线性递减策略虽然老套但管用。曾经试过自适应权重,结果在33节点系统里反而收敛更慢。
在实现过程中最头秃的是处理混合变量类型——选址是离散的0/1,容量是连续值。我们最终在粒子更新时搞了个分段处理:
def hybrid_update(particle):
# 离散部分采用二进制更新
discrete_part = particle.position[:33]
prob = 1 / (1 + np.exp(-particle.velocity[:33])) # sigmoid转换
discrete_updated = (np.random.rand(33) < prob).astype(int)
# 连续部分正常更新
continuous_part = particle.position[33:] + particle.velocity[33:]
return np.concatenate([discrete_updated, continuous_part])这招把Sigmoid函数当概率用,既保留了二进制特性,又不破坏PSO的更新机制。实测效果比强制取整好太多,特别是处理光伏集群配置时,避免了大量无效粒子产生。
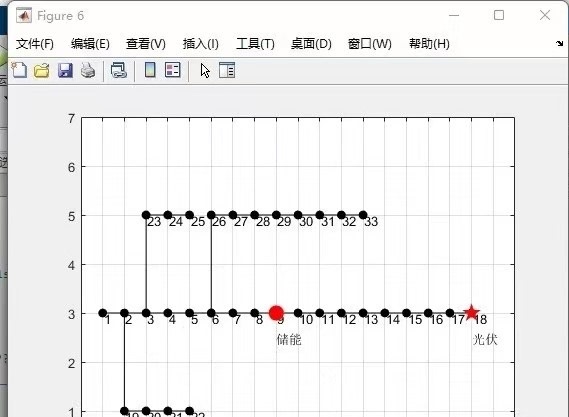
经过三天三夜的迭代,最终在33节点系统中跑出的配置方案显示:储能设备倾向于装在网络重载区域,而光伏则分布在末端节点形成自发自用模式。有趣的是系统自动规避了在12号节点(关键联络节点)布置设备,这和我们手动分析的结果不谋而合。
不过这个模型仍有改进空间,比如:
- 考虑天气数据的时间序列特性
- 加入设备故障的鲁棒性约束
- 用GPU加速下层优化计算
下次准备试试量子粒子群,听说在解空间探索上更野。搞电力系统优化就像玩俄罗斯方块,永远不知道下一个难点会从哪儿掉下来,但接住的那一刻是真的爽。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)