机器学习优化:梯度下降法与牛顿法手推公式详解
本文为机器学习优化算法入门笔记,核心为梯度下降法与牛顿法的个人手推公式,对比两种算法的核心思想与适用场景。文字为个人学习记录,适合深度学习 / 机器学习初学者一起阅读交流。
一、前言
在机器学习中,我们的中心目标是找到一组参数,使得损失函数L(
)最小化。而梯度下降法与牛顿法正是解决这个优化问题的两类核心算法:
- 梯度下降法:一阶优化的代表,仅利用一阶导数(梯度),是深度学习的基础优化器。
- 牛顿法:二阶优化的代表,额外引入二阶导数(海森矩阵),收敛速度更快,但计算代价更高。
理解它们的推导逻辑,可以帮助我们在实际训练中更合理地选择优化器。
二、算法背景
1. 梯度下降法(Gradient Descent)
梯度下降法的核心思想是:沿着损失函数梯度的反方向更新参数,逐步逼近极小值点。网上很多文章喜欢用爬山来类比梯度,下山时有很多条路(方向),这里我们希望找到最快下山的路,即坡度最陡(梯度的反方向)。
- 核心优势:计算简单、内存占用小、易于实现,完美适配高维参数空间(如百万级参数的神经网络)。
- 典型应用:
- 线性回归、逻辑回归的参数求解
- 深度神经网络训练(SGD、Adam 等优化器的底层逻辑)
- 大规模数据集下的在线学习(随机梯度下降 SGD)
2. 牛顿法(Newton's Method)
牛顿法在梯度信息的基础上,额外引入了海森矩阵(二阶导数),可以更精准地拟合损失函数的局部曲率,因此收敛速度远快于梯度下降法。
- 核心优势:收敛速度快(二次收敛),接近极小值点时步长自动调整,无需手动调学习率。
- 典型应用:
- 逻辑回归、SVM 等小规模模型训练
- 数值优化领域的方程根求解
- 对收敛速度要求高、参数维度较低的场景
总结:
两种方法主要应用场景有区别:
1)梯度下降法仅需要求一阶导,计算快,用简单计算换来了高维场景的可行性,是深度学习的核心动力。
2)牛顿法是 “精准派” 代表,引入二阶信息实现更快收敛,但高维场景下计算与内存开销过大,因此衍生出拟牛顿法(如 BFGS、L-BFGS)来近似海森矩阵,平衡效率与性能。
三、梯度下降法(一阶泰勒展开推导)
梯度下降法的推导基于一阶泰勒展开,通过近似损失函数的局部变化,找到让损失下降的参数更新方向。
1. 一阶泰勒展开
我们知道一阶泰勒展开公式为:
将损失函数带入,当
时泰勒展开,可以得到:
其中损失函数一阶导
就是梯度
(损失函数二阶导是n维海森矩阵
,后面牛顿法会提到),因为权重等参数
默认为n*1的列向量,因此梯度也是一个n*1的列向量。为了实现矩阵乘法(行*列),这里对梯度进行转置
再与
相乘。
2. 参数更新公式推导
为了实现梯度下降,所以令,所以
,
即梯度和参数的变化量
符号要相反,所以参数每次迭代的变化方向是梯度的反方向。
这里再引入一个大于0的常数 来表示每次迭代的步长,即学习率。实际项目中学习率一般都是在不停变化,但其为标量不影响公式的推导:
令 ,
至此,梯度下降公式就可以表示为:
梯度下降法和牛顿法本质上都是找到令损失函数L(w)最小的参数w*,但是由于函数本身是高维,非凸,无解析解,因此我们无法一步解出w*,只能通过逐步逼近的迭代法来表示。迭代法的基本表达形式就是W(k+1)=F(W(k)),用当前值通过一个固定规则,算出下一个值。
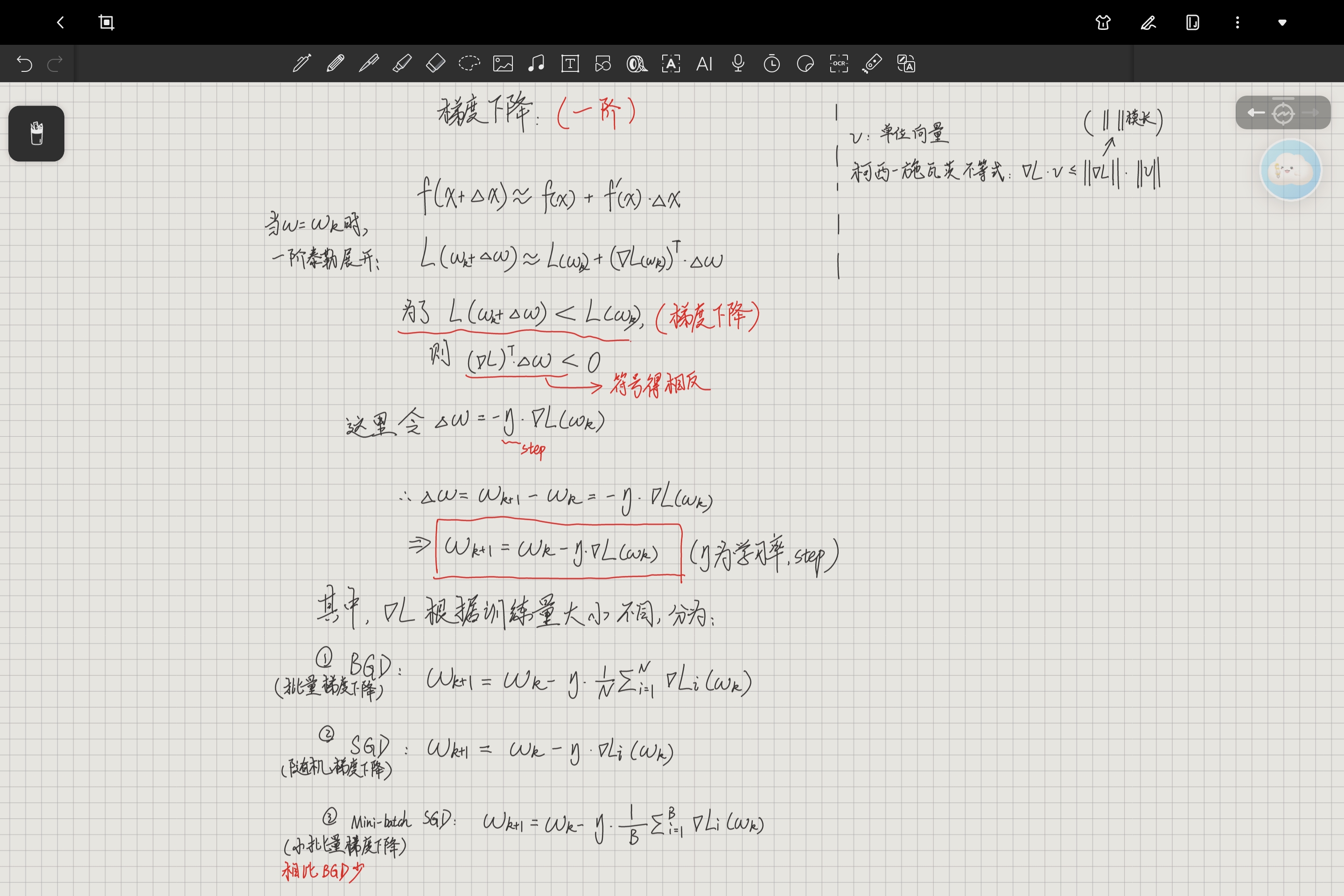
3. 梯度下降的三种常用变体
根据训练数据量的不同,梯度下降法衍生出三种高效实现:
1. BGD(批量梯度下降): 利用全部训练数据计算梯度,更新稳定但计算量大,适合小数据集。
2. SGD(随机梯度下降): 仅用单个样本计算梯度,速度快但噪声大,适合大规模在线学习。
3. Mini-batch SGD(小批量梯度下降): 平衡了稳定性与计算效率,是深度学习中最常用的形式,这里的B为训练样本数,1<B<N。(一般B=32/64/128)
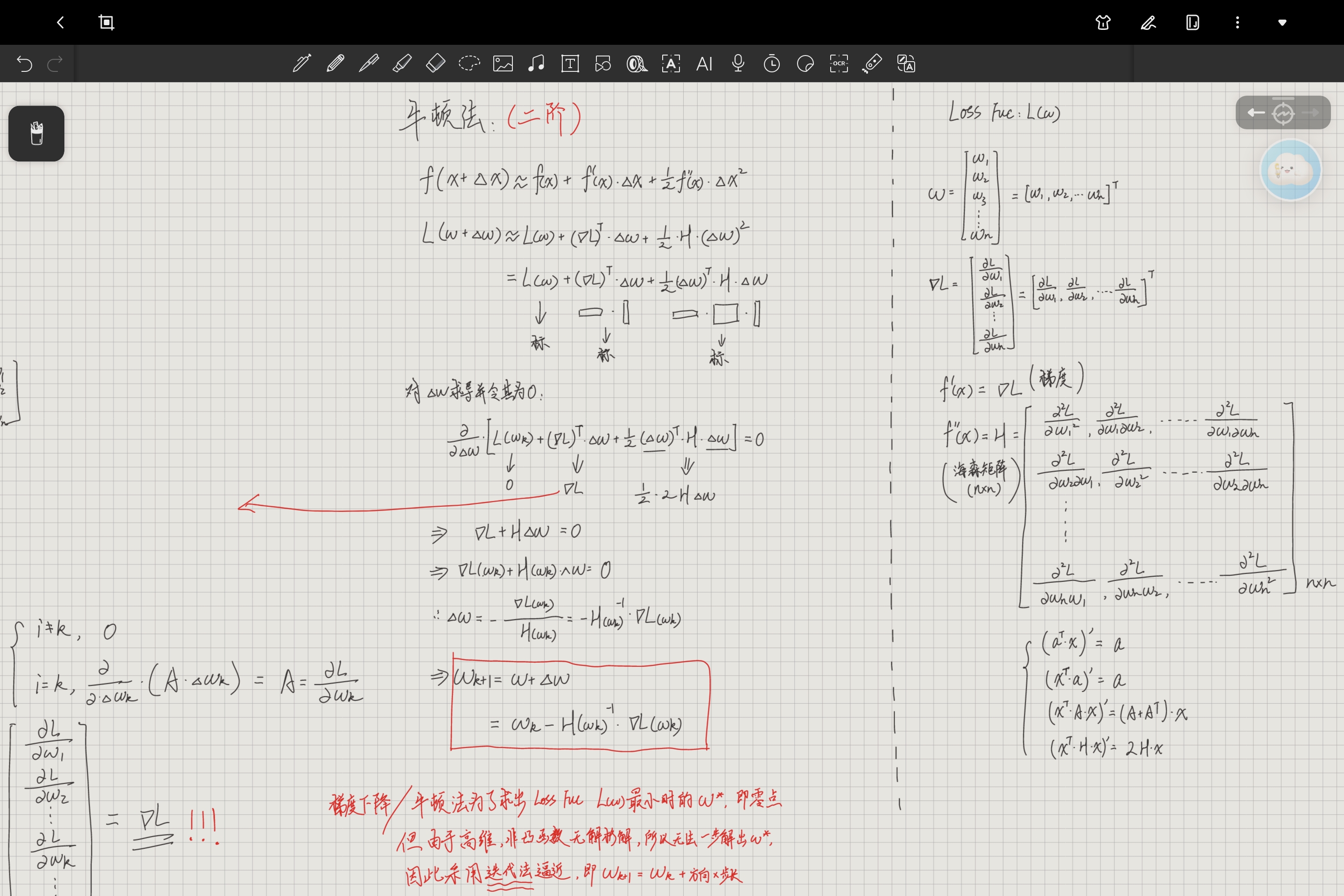
四、牛顿法(二阶泰勒展开推导)
牛顿法是在一阶泰勒展开的基础上,加入二阶项(海森矩阵 H),更精准地拟合损失函数的局部形状,从而得到更优的更新方向。
1. 二阶泰勒展开
与刚刚梯度下降法类似,对损失函数在处做二阶泰勒展开:
其中 是海森矩阵,代表损失函数的二阶偏导数:
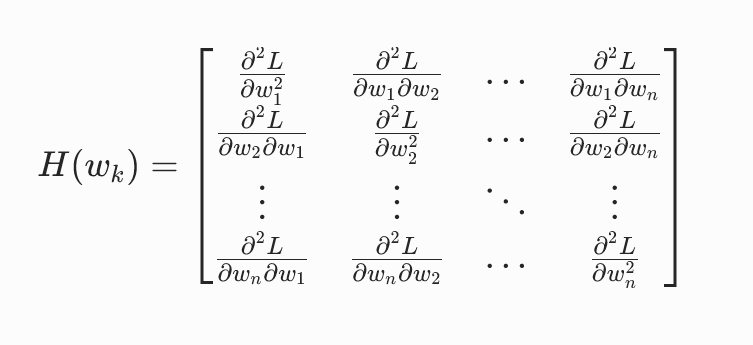
这里二阶项中是行向量,无法直接平方,因此对
进行转置:
为了找到损失函数在处损失最小的
,对
求导并令导数为 0。
展开求导后得到关键方程:
这里应用矩阵的求导公式可知:
;
;
以一阶项为例,也可以推出其导数就是
。
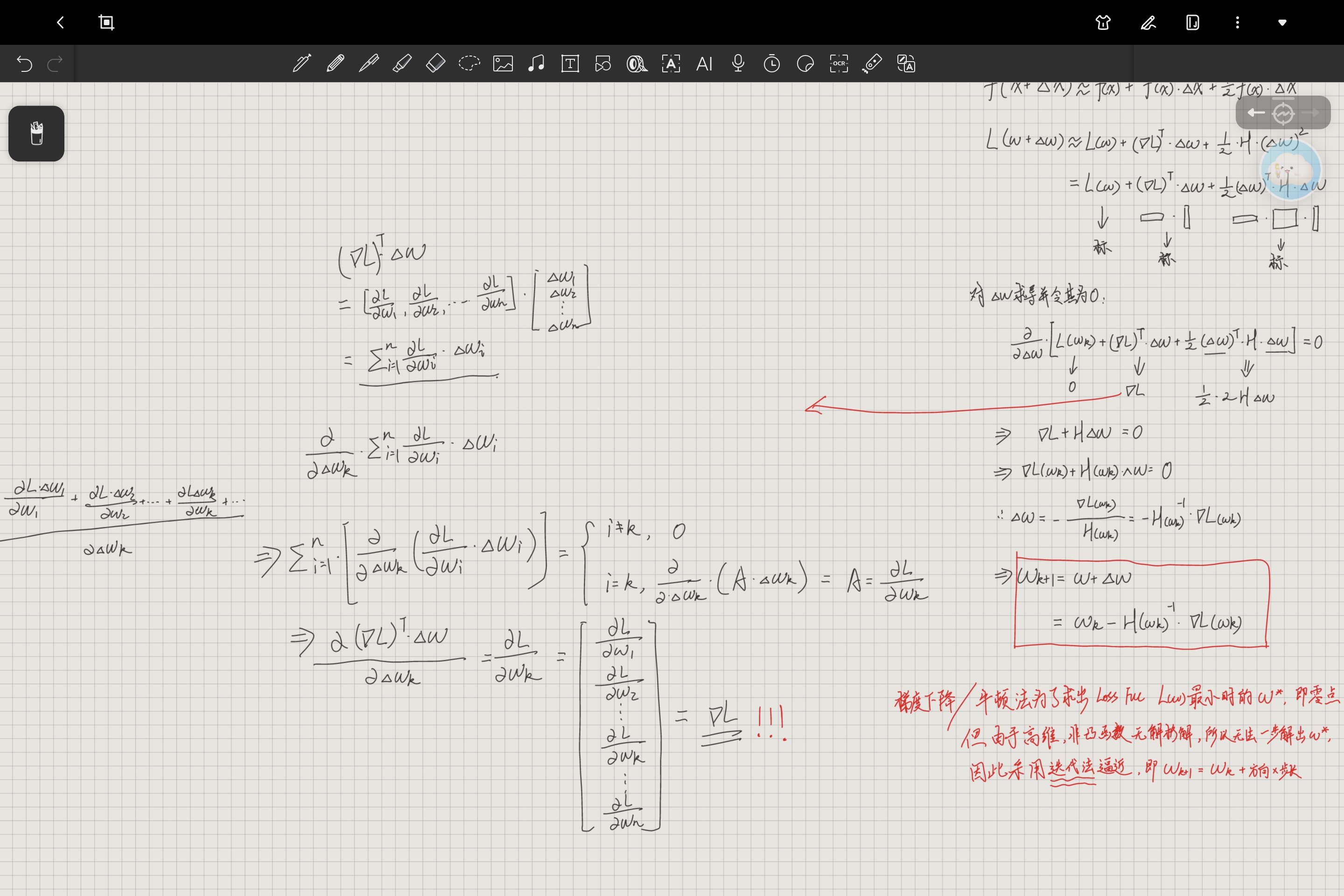
2. 参数更新公式推导
接着来看刚刚求偏导后的公式:
整理可得:
至此,我们得到了牛顿法参数更新公式:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 24
24 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)