Transformer模型、整体结构,编码器与解码器内部组成,自注意力机制,位置编码,mask机制,API使用,附中英翻译案例
目录
一、Transformer
此前的Seq2Seq模型通过Attention机制取得了一定提升,但由于整体结构仍依赖RNN,依然存在
计算效率低、难以建模长距离依赖等结构性限制。Transformer完全摒弃了RNN结构,转而使用注
意力机制直接建模序列中各位置之间的关系。
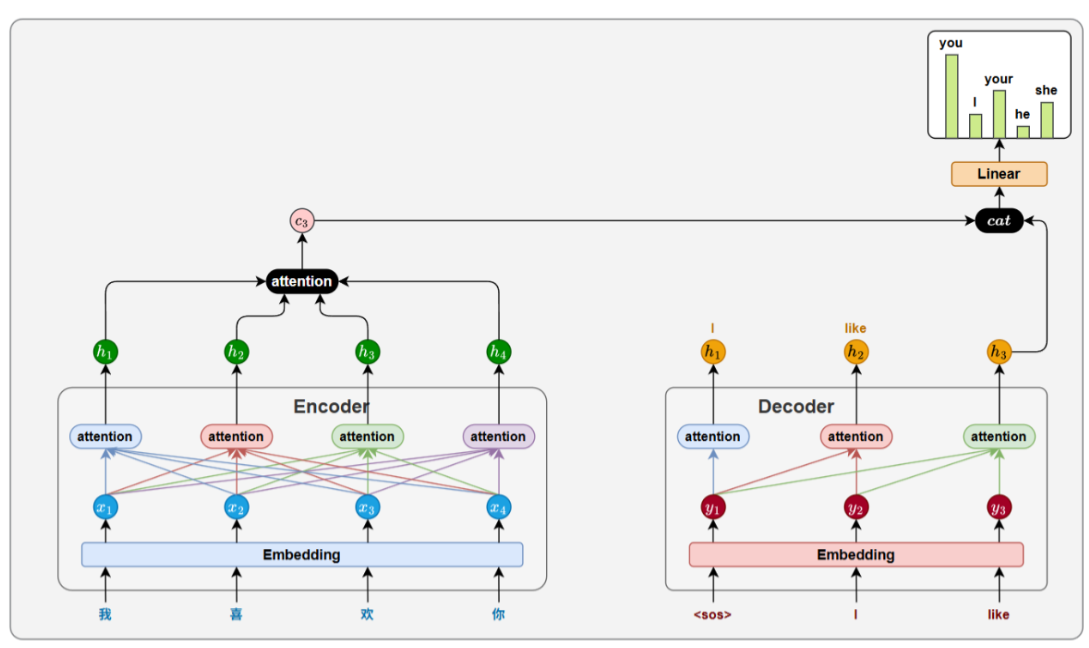
1、整体结构
与基于RNN的Seq2Seq模型一样,Transformer的解码器采用自回归方式生成目标序列。不同之处
在于,每一步的输入是此前已生成的全部词,模型会输出一个与输入长度相同的序列,但我们只取
最后一个位置的结果作为当前预测。这个过程不断重复,直到生成结束标记<eos>。
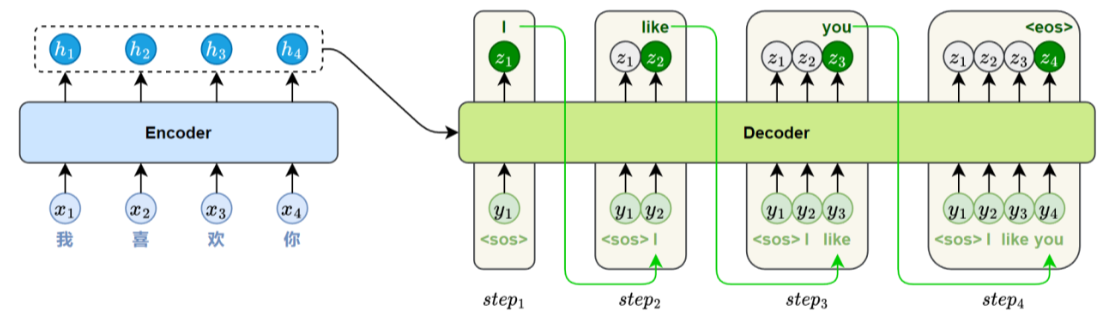
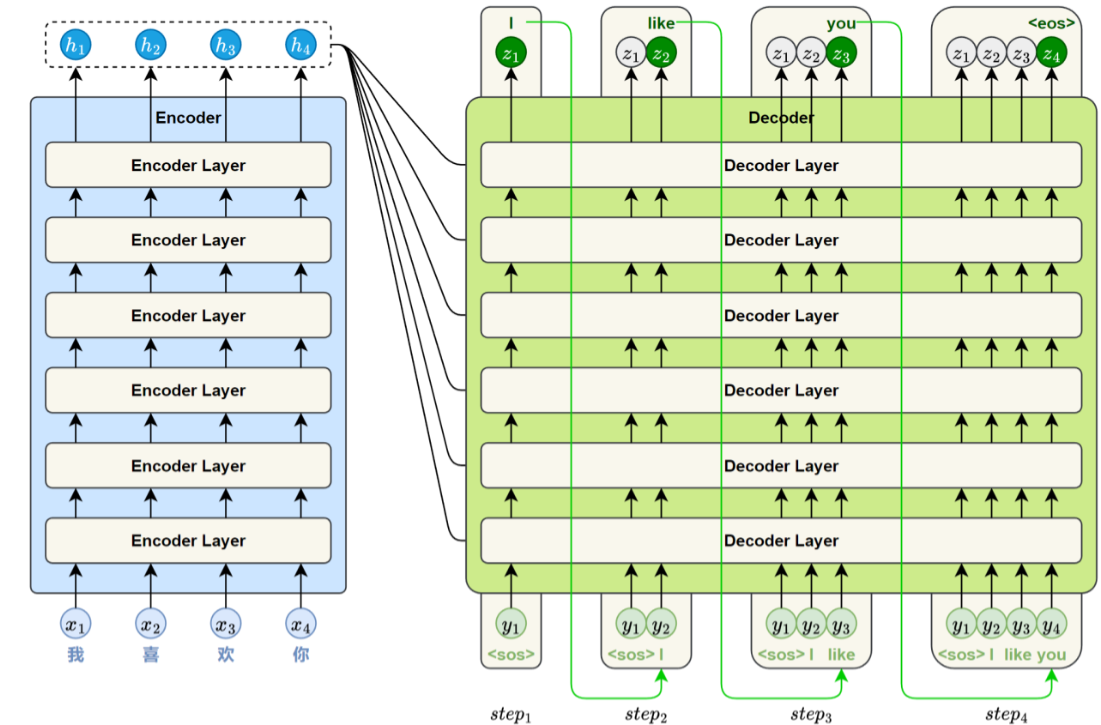
此外,Transformer的编码器和解码器模块分别由多个结构相同的层堆叠而成。通过层层堆叠,模
型能够逐步提取更深层次的语义特征,从而增强对复杂语言现象的建模能力。标准的Transformer
模型通常包含6个编码器层和6个解码器层。
2、编码器
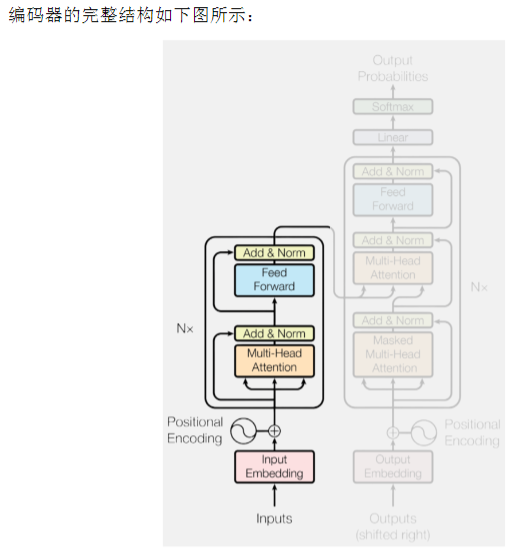
每个Encoder Layer都包含两个子层(sublayer)自注意力子层(Self-Attention Sublayer)和前馈
神经网络子层(Feed-Forward Sublayer)。
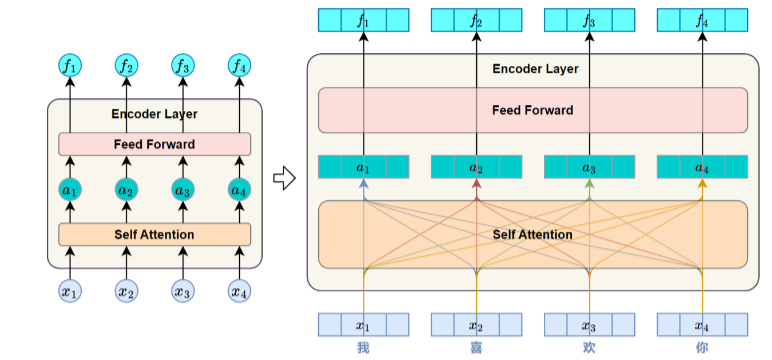
2.1、自注意力子层
在序列内部建立各位置之间的依赖关系,使模型能够为每个位置生成融合全局信息的表示。
(1)生成Q,K,V向量
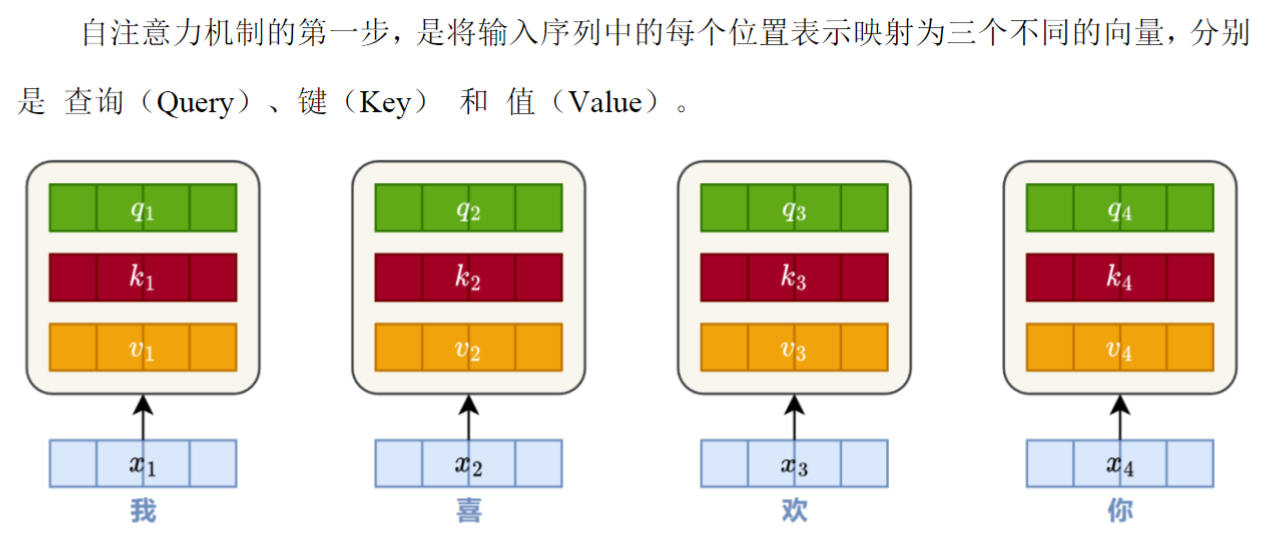

总结:Q发起匹配,K与Q匹配,V加权求和
(2)计算位置相关性
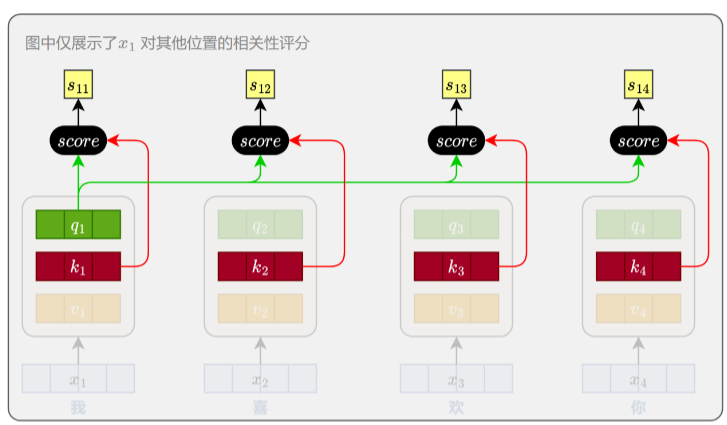
评分函数采用向量点积形式。由于在高维空间中,点积的数值可能过大,会影响softmax的稳定
性,因此在实际计算中对结果进行了缩放。最终的评分函数为:
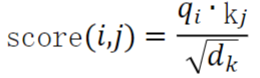
其中𝑑𝑘是key向量的维度,用于缩放点积的幅度。这个分数越大,表示第i个位置越应该关注第j个
位置的信息。
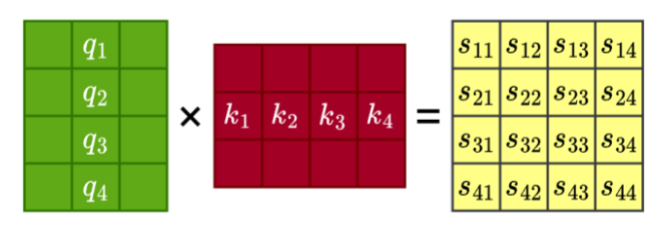
(3)计算注意力权重
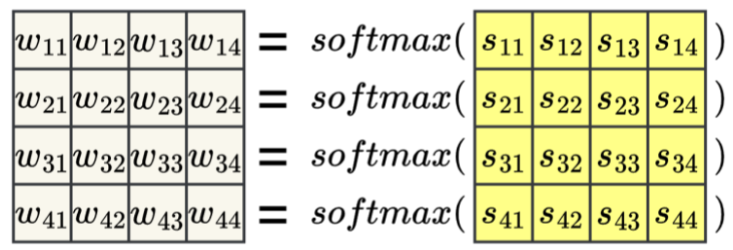
(4)加权汇总生成输出
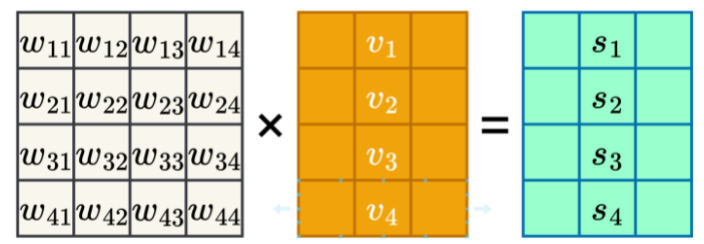
(5)总结
整个自注意力机制的完整计算公式如下:
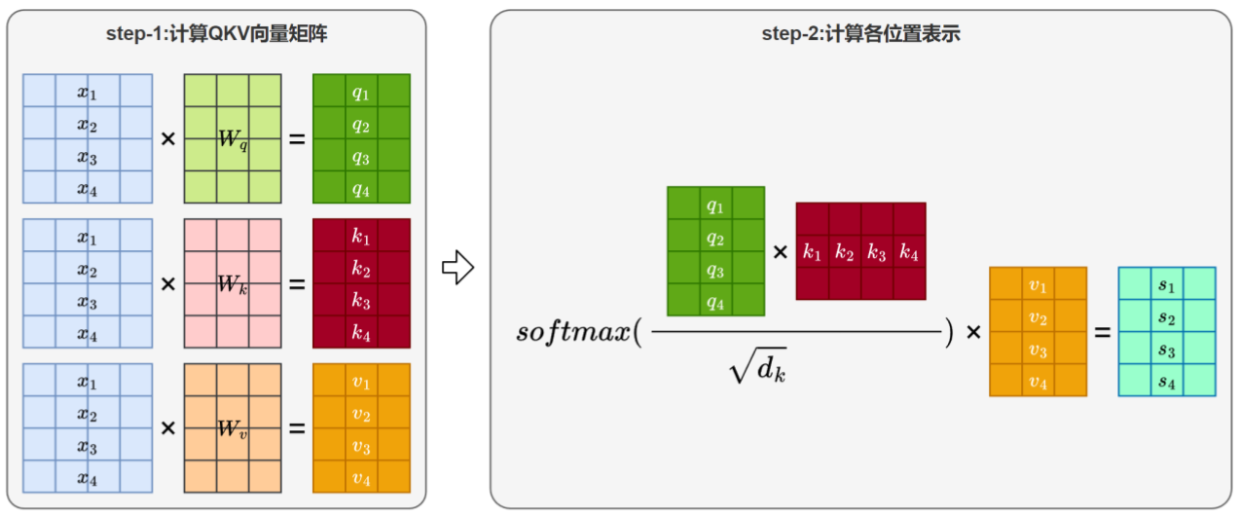
![]()
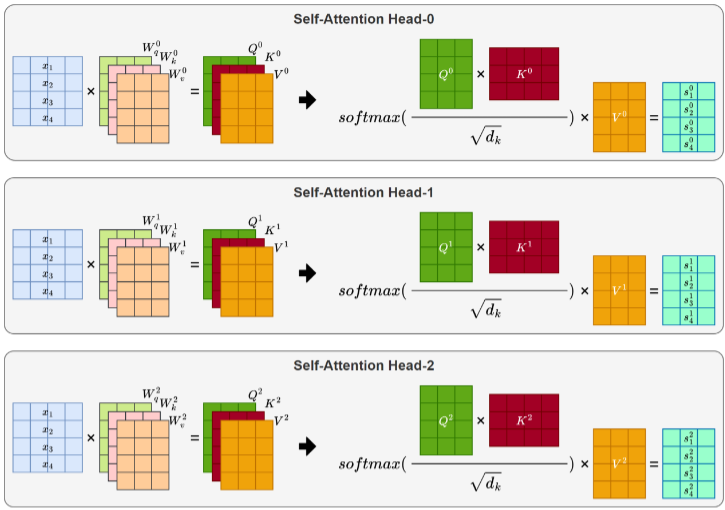
(6)多头注意力计算过程
要准确理解语义复杂的句子,Transformer引入了多头注意力机制(Multi-Head Attention)。其核
心思想是通过多组独立的Query、Key、Value投影,让不同注意力头分别专注于不同的语义关系,
最后将各头的输出拼接融合。
分别计算多头注意力输出
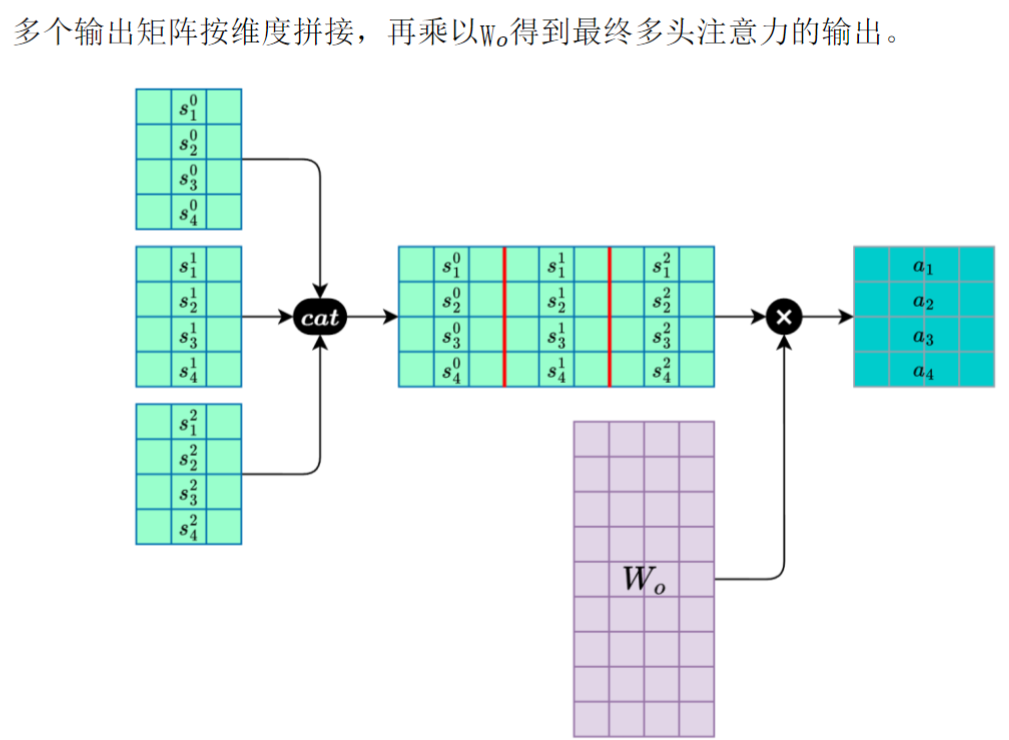
合并多头注意力
2.2、前馈神经网络子层
前馈神经网络(Feed-Forward Network,简称FFN),一个标准的FFN子层包含两个线性变换和一
个非线性激活函数,中间通常使用ReLU激活。
![]()
2.3、残差连接与层归一化
在Transformer的每个编码器层中,每个子层,包括自注意力子层和前馈神经网络子层,其输出都
要经过残差连接(Residual Connection)和层归一化(Layer Normalization)处理。这两者是深层
神经网络中常用的结构,用于缓解模型训练中的梯度消失、收敛困难等问题。
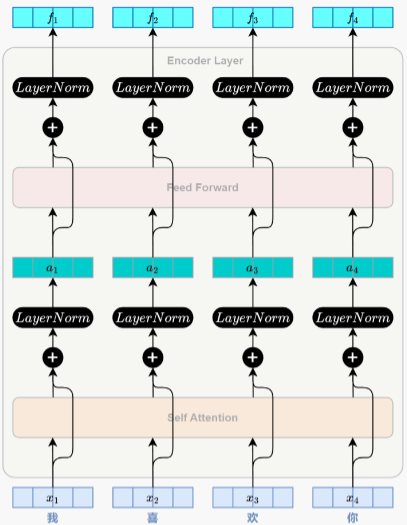
(1)残差连接(Residual Connection)
将子层的输入直接与其输出相加,形成一条跨越子层的“捷径”,其数学形式为:
![]()
(2)层归一化(Layer Normalization)
主要作用是规范输入序列中每个token的特征分布(某个token的表示可能在不同维度上有较大数值
差异),提升模型训练的稳定性。该操作会将每个token的向量调整为均值为0、方差为1的规范分
布。
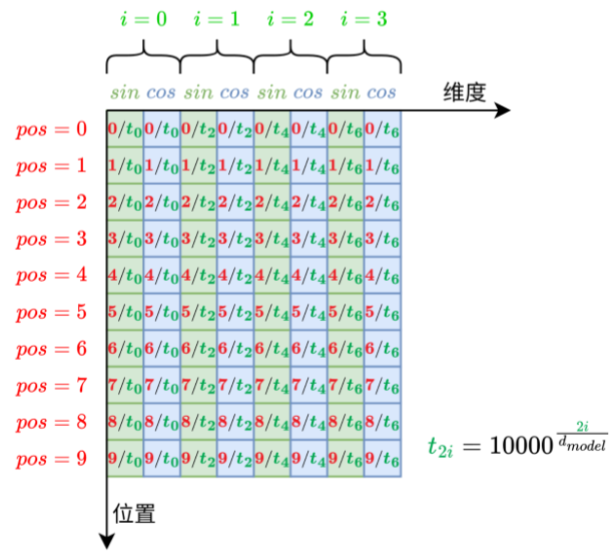
2.4、位置编码
为了解决 Transformer 无法捕捉语序的问题,该模型引入了位置编码(Positional Encoding)机
制,通过为每个词添加位置向量,使其在获取词义的同时也能感知位置信息,从而理解语序。
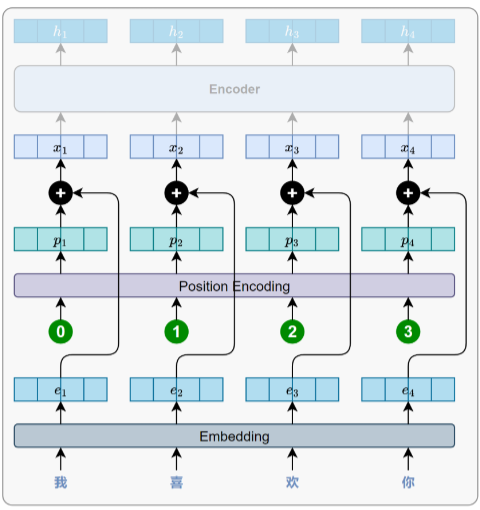
为解决绝对位置编码数值倾斜及归一化导致的位置不一致问题,Transformer采用基于正弦和余弦
函数的固定位置编码,为每个位置生成唯一且与句子长度无关的向量,从而保证模型能稳定捕捉语
序信息。

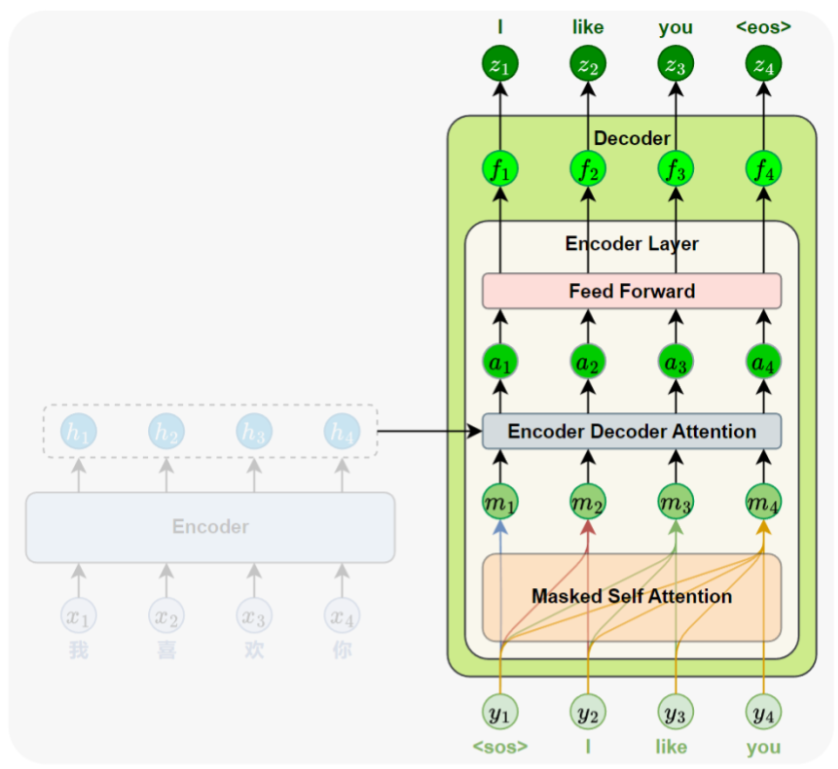
3、解码器
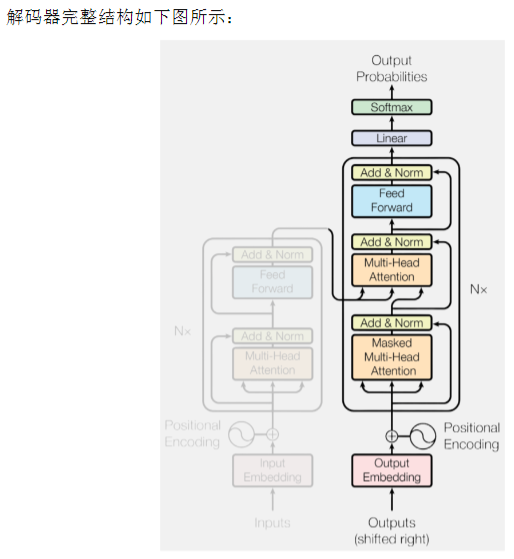
每个Decoder Layer都包含三个子层,分别是Masked自注意力子层、编码器-解码器注意力子
层(Encoder-Decoder Attention)和前馈神经网络子层(Feed-Forward Network),每个子层后
也都配有残差连接与层归一化(Layer Normalization),结构设计与编码器保持一致,确保训练的
稳定性和效率。
此外,解码器在输入端同样需要加入位置编码(Positional Encoding),用于提供序列中的位
置信息,其计算方式与编码器中相同。
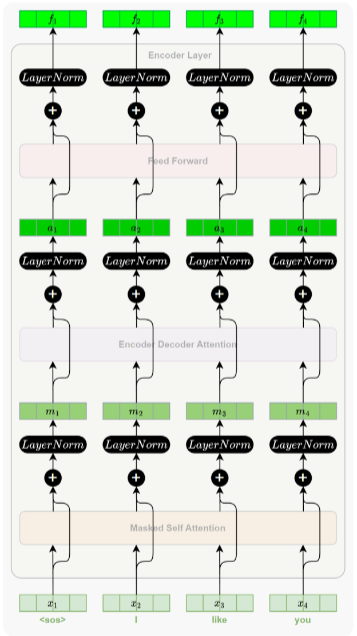
3.1、Masked自注意力子层
用于建模当前位置与前文词之间的依赖关系。为了在训练时模拟逐词生成的过程,引入遮盖机制
(Mask),限制每个位置只能关注它前面的词。
Mask是一个下三角矩阵,上三角设置为负无穷的原因是让上三角部分经过softmax之后,权重几乎
为0。
3.2、编码器--解码器注意力子层
在解码器的交叉注意力中,Query来自解码器当前输入,Key和Value来自编码器输出。通过计算
Query与所有Key的相似度,得到源序列各位置的权重,再对Value加权求和,从而为当前生成词提
取相关的上下文信息。
3.3、前馈神经网络子层
与编码器中结构完全一致,对每个位置的表示进行非线性变换,增强模型的表达能力。
4、模型训练和推理机制
4.1、模型训练
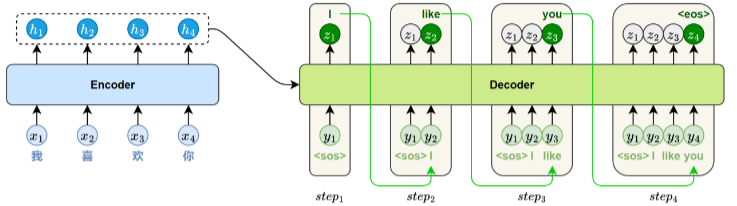
训练时,Transformer将目标序列整体输入解码器,并在每个位置同时进行预测。为防止模型“看到”
后面的词,破坏因果顺序,解码器在自注意力机子层中引入了遮盖机制(Mask),限制每个位置
只能关注它前面的词。
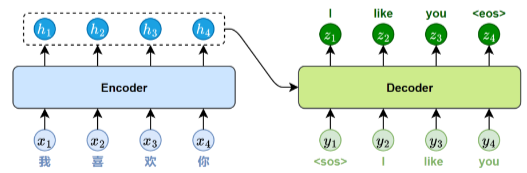
4.2、模型推理
推理时,每一步都要重新输入整个已生成序列,模型需要基于全量前文重新计算注意力分布,决定
下一个词的输出。整个过程必须顺序执行,无法并行。推理阶段,模型每一步都要重新输入当前已
生成的全部词,通过自注意力机制建模上下文关系,预测下一个词。
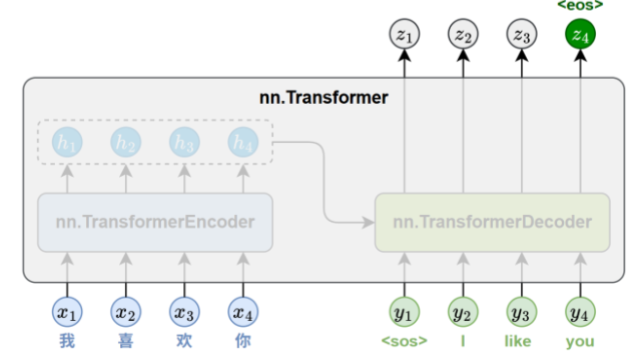
5、API使用
PyTorch提供了完整的Transformer官方实现,封装了编码器-解码器结构,适用于机器翻译、文本生成等序列建模任务。核心模块包括:
-
nn.Transformer:顶层接口,封装完整编码器-解码器架构,支持自定义层数、注意力头数、隐藏维度等参数。
-
nn.TransformerEncoder / Decoder:分别由多个编码器/解码器层堆叠而成,用于序列编码和目标序列生成。
-
nn.TransformerEncoderLayer / DecoderLayer:实现单层结构,编码器层包含多头自注意力和前馈子层;解码器层额外增加编码器-解码器注意力。各子层均配有残差连接和层归一化。
1、Transformer构造参数

2、Transformer.forward
nn.Transformer封装了完整的前向传播逻辑,其forward()方法接收源语言序列(编码器输入)和目
标语言序列(解码器输入),返回解码器的预测结果。

3、Transformer.encoder
nn.Transformer通过encoder属性(nn.TransformerEncoder实例)对源序列进行编码,提取上下文
相关的语义表示。

4、Test
import torch.nn as nn
import torch
model = nn.Transformer(d_model = 64,nhead = 8,num_encoder_layers = 3,num_decoder_layers = 3,
dim_feedforward = 256,batch_first=True)
print(model)
src = torch.randn(32,10,64)
tgt = torch.randn(32,24,64)
output1 = model(src,tgt)
print(output1.shape )
memory = model.encoder(src)
print(memory.shape)
output2 = model.decoder(tgt,memory)
print(output2.shape)
Transformer(
(encoder): TransformerEncoder(
(layers): ModuleList(
(0-2): 3 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=64, out_features=64, bias=True)
)
(linear1): Linear(in_features=64, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=256, out_features=64, bias=True)
(norm1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
)
(norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(decoder): TransformerDecoder(
(layers): ModuleList(
(0-2): 3 x TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=64, out_features=64, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=64, out_features=64, bias=True)
)
(linear1): Linear(in_features=64, out_features=256, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=256, out_features=64, bias=True)
(norm1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
)
(norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
)
torch.Size([32, 24, 64])
torch.Size([32, 10, 64])
torch.Size([32, 24, 64])6、Transformer中英翻译案例
PyTorch无内置位置编码,而Transformer不具备位置感知能力,故需手动实现位置编码,与嵌入层输出相加后输入模型。还需实现以下模块:
-
源语言和目标语言的词嵌入层(nn.Embedding)
-
输出层(nn.Linear),将模型输出映射至目标词表大小
model
import torch
import torch.nn as nn
from config import *
import math
# # 自定义位置编码层
# class PositionEncoding(nn.Module):
# def __init__(self,max_len,d_model):
# super().__init__()
# # 定义编码矩阵
# pe = torch.zeros(size = (max_len,d_model),dtype=torch.float)
# # 遍历每一行
# for pos in range(max_len):
# # 遍历当前位置向量的每个特征,步长为2
# for _2i in range(0,d_model,2):
# # 按公式计算向量里的这两个特征
# pe[pos,_2i] = math.sin(pos/(10000 ** (_2i/d_model)))
# pe[pos,_2i+1] = math.cos(pos/(10000 ** (_2i/d_model)))
# # 注册缓冲
# self.register_buffer('pe', pe)
#
# def forward(self, x):
# seq_len = x.size(1) # 提取当前序列长度
# # 在位置编码矩阵中截取L个向量
# part_pe = self.pe[0:seq_len]
# return x + part_pe
# 自定义位置编码层
class PositionEncoding_Pro(nn.Module):
def __init__(self, max_len, d_model):
super().__init__()
# 定义编码矩阵
pe = torch.zeros(size=(max_len, d_model))
pos = torch.arange(0,max_len).unsqueeze(1)
_2i = torch.arange(0,d_model,2)
div_term = torch.pow(10000,(_2i/d_model))
pe[:,0::2] = torch.sin(pos/div_term)
pe[:,1::2] = torch.cos(pos/div_term)
self.register_buffer('pe', pe)
def forward(self, x):
seq_len = x.size(1) # 提取当前序列长度
# 在位置编码矩阵中截取L个向量
part_pe = self.pe[0:seq_len]
return x + part_pe
class TranslationModel(nn.Module):
def __init__(self,cn_vocab_size,en_vocab_size,cn_padding_idx,en_padding_idx):
super().__init__()
self.cn_embedding = nn.Embedding(cn_vocab_size, embedding_dim=DIM_MODEL, padding_idx=cn_padding_idx)
self.en_embedding = nn.Embedding(en_vocab_size, embedding_dim=DIM_MODEL, padding_idx=en_padding_idx)
# 位置编码
self.position_encoding = PositionEncoding_Pro(SEQ_LEN, DIM_MODEL)
self.transformer = nn.Transformer(d_model=DIM_MODEL,nhead = NUM_HEADS,
num_encoder_layers=NUM_ENCODER_LAYERS,num_decoder_layers=NUM_DECODER_LAYERS,
batch_first=True)
self.linear = nn.Linear(in_features=DIM_MODEL,out_features=en_vocab_size)
def forward(self,src,tgt,src_pad_mask,tgt_mask):
# 编码
memory = self.encode(src,src_pad_mask)
# 解码
output = self.decode(tgt,memory,tgt_mask = tgt_mask,memory_pad_mask = src_pad_mask)
return output
def encode(self,src,src_pad_mask):
embed = self.cn_embedding(src)
input = self.position_encoding(embed)
memory = self.transformer.encoder(src = input,src_key_padding_mask = src_pad_mask)
return memory
def decode(self,tgt,memory,tgt_mask=None,memory_pad_mask=None):
embed = self.en_embedding(tgt)
input = self.position_encoding(embed)
output = self.transformer.decoder(tgt=input, memory = memory,tgt_mask=tgt_mask,memory_key_padding_mask=memory_pad_mask)
output = self.linear(output)
return output
if __name__ == "__main__":
model = TranslationModel(1000,1024,0,0)
print(model)
train
import torch
from torch import nn, optim
from config import *
from dataset import get_dataloader
from model import TranslationModel
from tqdm import tqdm
from torch.utils.tensorboard import SummaryWriter # 日志写入器
import time # 时间库
from tokenizer import ChineseTokenizer,EnglishTokenizer
# 定义训练引擎函数,训练一个epoch,返回平均损失
def train_one_epoch(model, train_loader, loss,optimizer,device):
model.train()
total_loss = 0
for inputs, targets in tqdm(train_loader,desc='训练:'):
inputs, targets = inputs.to(device), targets.to(device) # 形状(N,L)
# 准备参数
decoder_inputs = targets[:,:-1]
decoder_targets = targets[:,1:]
src_pad_mask = (inputs == model.cn_embedding.padding_idx)
tgt_mask = model.transformer.generate_square_subsequent_mask(decoder_inputs.shape[1])
# 解码器前向传播得到解码输出
decoder_outputs = model(src = inputs,tgt = decoder_inputs,src_pad_mask = src_pad_mask,tgt_mask = tgt_mask)
loss_value = loss(decoder_outputs.transpose(1,2), decoder_targets)
loss_value.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += loss_value.item()
return total_loss / len(train_loader)
def train():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader = get_dataloader(train = True)
cn_tokenizer = ChineseTokenizer.from_vocab(MODEL_DIR/CN_VOCAB_FILE)
en_tokenizer = EnglishTokenizer.from_vocab(MODEL_DIR/EN_VOCAB_FILE)
model = TranslationModel(cn_tokenizer.vocab_size,en_tokenizer.vocab_size,cn_tokenizer.pad_id,en_tokenizer.pad_id).to(device)
# with open(MODEL_DIR/VOCAB_FILE,'r',encoding='utf-8') as f:
# vocab_list = [token.strip() for token in f.readlines()]
#
# model = InputMethodModel(vocab_size = len(vocab_list)).to(device)
loss = nn.CrossEntropyLoss(ignore_index=en_tokenizer.pad_id)
optimizer = optim.Adam(model.parameters(),lr = LEARNING_RATE)
writer = SummaryWriter(log_dir=LOG_DIR / time.strftime("%Y-%m-%d_%H-%M-%S"))
min_loss = float('inf')
for epoch in range(EPOCHS):
print('='*10,f'EPOCH:{epoch+1}','='*10)
this_loss = train_one_epoch(model, train_loader, loss,optimizer,device)
print("本轮训练损失:",this_loss)
writer.add_scalar('loss',this_loss,epoch+1)
if this_loss < min_loss:
min_loss = this_loss
torch.save(model.state_dict(),MODEL_DIR/BEST_MODEL)
print('模型保存成功!')
writer.close()
if __name__ == '__main__':
train()
predict
import torch
from config import *
from model import TranslationModel
from tokenizer import ChineseTokenizer,EnglishTokenizer
def predict_batch(model,inputs,tokenizer,device):
model.eval()
with torch.no_grad():
# 定义当前batchsize
batch_size = inputs.shape[0]
src_pad_mask = (inputs == model.cn_embedding.padding_idx)
memory = model.encode(inputs,src_pad_mask)
# 构建第一个时间步的输入,长度为N的向量,内容全部为<sos>id
decoder_input = torch.full(size = (batch_size,1),fill_value = tokenizer.start_id).to(device)
# 生成id列表
generated_ids = []
# 定义一个长度为N的tensor,保存每个数据样本是否已生成结束标志<eos>
is_finished = torch.full(size = [batch_size],fill_value = False).to(device)
# 循环迭代自回归生成
for i in range(SEQ_LEN):
tgt_mask = model.transformer.generate_square_subsequent_mask(decoder_input.shape[1])
decoder_output = model.decode(decoder_input, memory,tgt_mask = tgt_mask, memory_pad_mask = src_pad_mask)
# 词选择策略,贪心解码
next_token_ids = torch.argmax(decoder_output[:,-1,:], dim = -1,keepdim = True)
# 保存预测id到生成列表中
generated_ids.append(next_token_ids)
# 更新输入
decoder_input = torch.cat((decoder_input,next_token_ids),dim = -1)
# 判断是否生成结束标志<eos>,如果一批全部生成<eos>则退出循环
is_finished |= (next_token_ids.squeeze(1) == tokenizer.end_id)
if is_finished.all():
break
# 处理生成结果
# 基于生成列表 generated_ids:[tensor(N,1),tensor(N,1),...]
# 将列表转成(N,L)张量
generated_tensor = torch.cat(generated_ids,dim= 1)
# 转换为二维列表
generated_list = generated_tensor.tolist()
# 去掉每个元素(句子的id列表)中eos之后的所有内容
for i,sentence_ids in enumerate(generated_list):
if tokenizer.end_id in sentence_ids:
eos_pos = sentence_ids.index(tokenizer.end_id)
generated_list[i] = sentence_ids[:eos_pos]
return generated_list # 转换成列表返回
# def predict(text,model,id2word,word2id,k,device):
# tokens = jieba.cut(text)
# ids = [word2id.get(token, word2id.get(UNK_TOKEN)) for token in tokens]
def predict(text, model, cn_tokenizer, en_tokenizer,device):
ids = cn_tokenizer.encode(text)
input = torch.tensor([ids], dtype=torch.long).to(device)
result = predict_batch(model,input,en_tokenizer,device)
return en_tokenizer.decode(result[0])
def run_predict():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
cn_tokenizer = ChineseTokenizer.from_vocab(MODEL_DIR / CN_VOCAB_FILE)
en_tokenizer = EnglishTokenizer.from_vocab(MODEL_DIR / EN_VOCAB_FILE)
# with open(MODEL_DIR/VOCAB_FILE,'r',encoding='utf-8') as f:
# vocab_list = [token.strip() for token in f.readlines()]
# id2word = {id:word for id,word in enumerate(vocab_list)}
# word2id = {word:id for id,word in enumerate(vocab_list)}
print("词表加载成功!")
model = TranslationModel(cn_tokenizer.vocab_size,en_tokenizer.vocab_size,cn_tokenizer.pad_id,en_tokenizer.pad_id).to(device)
# model = InputMethodModel(vocab_size = len(id2word)).to(device)
model.load_state_dict(torch.load(MODEL_DIR/BEST_MODEL))
print("模型加载成功!")
print('欢迎使用中英翻译模型!输入q或者quit退出...')
while True: # 核心,一个死循环
user_input = input('中文 > ')
# 判断如果是q或quit直接退出
if user_input.strip() in['q','quit']:
print('欢迎下次再来!')
break
# 判断如果是空白,提示信息后继续循环
if user_input.strip() == '':
print('请输入有效内容!')
continue
# 预测译文
result = predict(user_input, model, cn_tokenizer,en_tokenizer, device)
print('英文:',result)
if __name__ == '__main__':
# text = "我们公司"
# top5_tokens = predict(text)
# print(top5_tokens)
run_predict()
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)