TADA: A Generative Framework for Speech Modeling via Text-Acoustic Dual Alignment
- Hume AI, USA
- 2026.2
- 有开源模型,以及finetune的代码https://github.com/HumeAI/tada
speech encoder
-
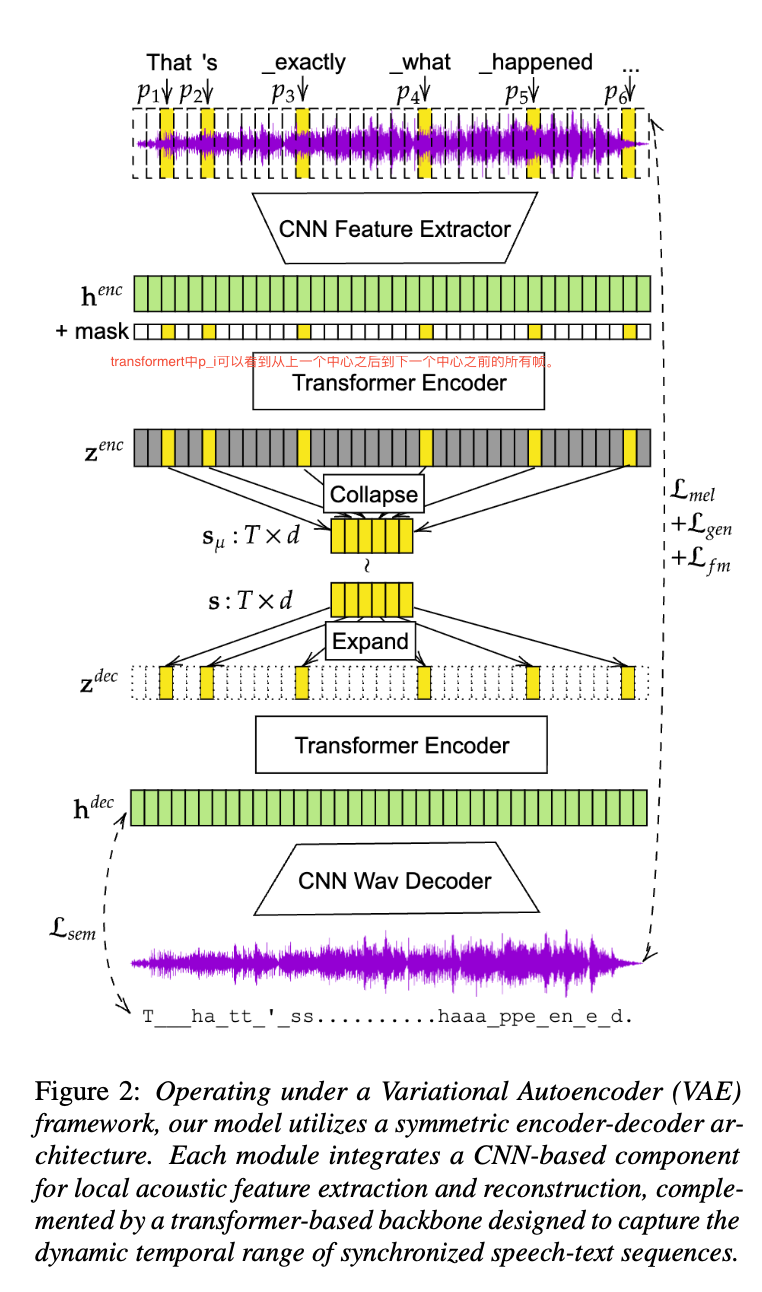
Speech 编码的实现 (Joint Speech-Text Tokenization)
TADA 的核心创新在于建立文本 token 和声学特征之间 1对1 (1-to-1) 的同步关系。其编码过程主要包含三个组件:Aligner(对齐器)、Encoder(编码器) 和 Decoder(解码器),整体在一个变分自编码器(VAE)框架下工作。 -
Aligner (对齐器):
架构: 基于 Wav2Vec2-large。
作用: 建立文本 token 和音频帧之间的映射。它通过 CTC (Connectionist Temporal Classification) 损失进行训练,将音频帧映射到 LLM 的词表(vocabulary)。
流程: 输入语音波形和对应的文本 token ID。通过 Viterbi 算法进行强制对齐(Forced Alignment),确定每个文本 token 在音频中对应的具体帧位置(记为 p i p_i pi -
Encoder (编码器):
- 架构: 包含一个 CNN 特征提取器(基于 DAC 架构,将 24kHz 音频下采样为 50Hz 的帧特征)和一个 Transformer 编码器。
- 对齐感知 (Alignment-Aware): 编码器利用 Aligner 提供的对齐位置 p p p。它引入了一个二进制指示位(binary indicator bit),标记哪些帧是“文本对齐帧”(即 p i p_i pi所在的位置),哪些是“非对齐帧”。
- 注意力机制: 使用了一种受限的注意力掩码(Attention Mask)。文本对齐位置 p i p_i pi只能关注其对应的时间窗口 [ p i − 1 + 1 , p i + 1 − 1 ] [p_{i-1}+1, p_{i+1}-1] [pi−1+1,pi+1−1]内的音频帧—这里是完整片段内的特征,没有删除。这确保了提取的特征严格对应于该文本 token 的发音片段。
- 压缩 (Compression): 编码器最终只提取文本对齐位置 p i p_i pi处的特征向量。因此,如果输入文本有 L 个 token,编码器就输出 L 个声学向量 ,实现了 1-to-1 的同步。
- VAE 采样: 编码器输出的是潜在分布的均值 ,训练时通过重参数化技巧(reparameterization trick)采样得到最终的潜在表示
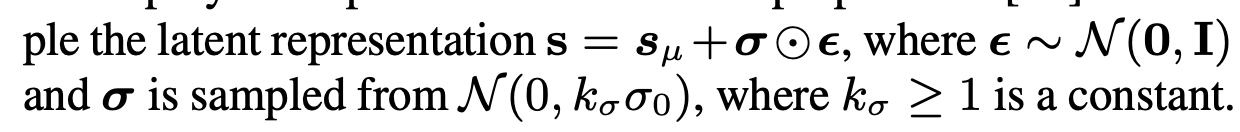
(标准差固定为 0.5)。
qa
整体架构与对应关系
Q: TADA 模型中,文本 Token 和声学特征(Speech Embedding)是 1:1 的关系吗?
A: 是的,严格保持 1:1 对应。与 VALL-E 等模型(1个文本对应多个 Codec Codes)不同,TADA 的 Encoder 将每个单词/字压缩为一个单一的声学向量。如果输入文本有 N 个 Token,模型生成的声学特征序列长度也是 N。这极大地提高了推理效率。
Q: LLM Backbone 是如何融合文本和声学信息的?输入长度?
A:融合方式: 加法融合 (Additive Fusion)。输入向量 = Text_Embedding + Speech_Embedding。
Shift 机制: 为了让模型能利用未来的文本信息,声学特征会向后平移 K 步。即输入为:
T e x t i + s p e e c h i − k Text_i + speech_{i-k} Texti+speechi−k, 输入长度保持为 2N-K。这使得 LLM 的上下文窗口利用率极高。
2. 预测头 (Flow Matching Head) 与时长编码
Q: Flow Matching (FM) Head 具体预测什么?
A: FM Head 进行联合预测 (Joint Prediction),输出一个拼接向量:
y = [ S p e e c h E m b e d d i n g , D u r a t i o n B i t s ] y=[Speech Embedding,Duration Bits] y=[SpeechEmbedding,DurationBits],它同时预测声学特征(频谱信息)和时长信息(元数据)。
Q: 为什么要使用格雷码 (Gray Code) 来编码时长?它和频谱类型的特征预测冲突吗?
A:Gray Code 仅代表该 Token 对应的音频时长(帧数)。
为什么用 Gray Code:
平滑性: 相比普通二进制,格雷码保证相邻整数之间只有 1 个比特 发生翻转。
易于拟合: FM 是连续模型,格雷码的平滑特性使得模型更容易学习离散整数的变化规律。
Q: FM 是连续模型,如何预测离散的 0/1 比特?(Analog Bits)
A: 使用 Analog Bits(模拟比特) 技术。将离散的 0 映射为 -1.0,1 映射为 +1.0。FM 将其视为连续实数进行预测。推理时,通过阈值(>0 或 <0)将其还原为离散比特,再解码为整数时长。
解码器 (Decoder) 设计
Q: TADA 的 Decoder 是如何设计的?
A: 采用了 “稀疏扩展 + 双解码器” 策略:
- 稀疏扩展 (Sparse Expansion): 输入是大部分为 0 的序列,仅在对齐点填入预测的 Speech Embedding。
- 双解码器 (Two Decoders):
- Global Decoder: 训练时使用,看全局信息,保证重建质量上限。
- Streamable Decoder: 推理时使用,仅看局部上下文(Local Attention),支持流式生成。
Q: 流式解码器 (Streamable Decoder) 如何实现流式推理?
A: 通过特殊的 Attention Mask。解码器在生成当前片段时,视野被限制在 [ p i − 2 , p i ] [p _{i−2},p_i] [pi−2,pi]
(即当前 Token 和上一个 Token 的范围内)。
这意味着只要 LLM 吐出一个 Token,Decoder 就能立即生成对应的音频,无需等待整句结束。
Q: 推理时,如何将预测出的 Embedding 和 Gray Code 还原为最终音频?
A: 流程如下:
解析时长: 将 FM 输出的 Analog Bits 解码为整数时长(例如 5 帧)。
稀疏排版: 在时间轴上创建一个长度为 5 的全 0 片段,将预测的 Speech Embedding 填入该片段的对齐位置(Alignment Point)。
填补细节: Decoder 的 Transformer 层接收这个稀疏序列,根据 Embedding 的信息“填补”周围 0 的位置,生成稠密的声学特征。
波形生成: CNN 层(DAC Decoder)将稠密特征上采样,还原为最终的波形。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)