GB300集群互联

-
一、背景
NVIDIA 开放 GB300 SuperPod 集群参考架构,本文中将介绍GB300 参考架构。此外,这里主要以计算网络互联(后端网络)为主,存储网络,In-Band 网络,Out-of-Band 网络等.
二、GPU
B300
B300基于台积电5nm工艺,采用GB110 Blackwell架构GPU,专为AI计算与高性能计算设计,不支持DirectX图形接口,无法运行消费级游戏。
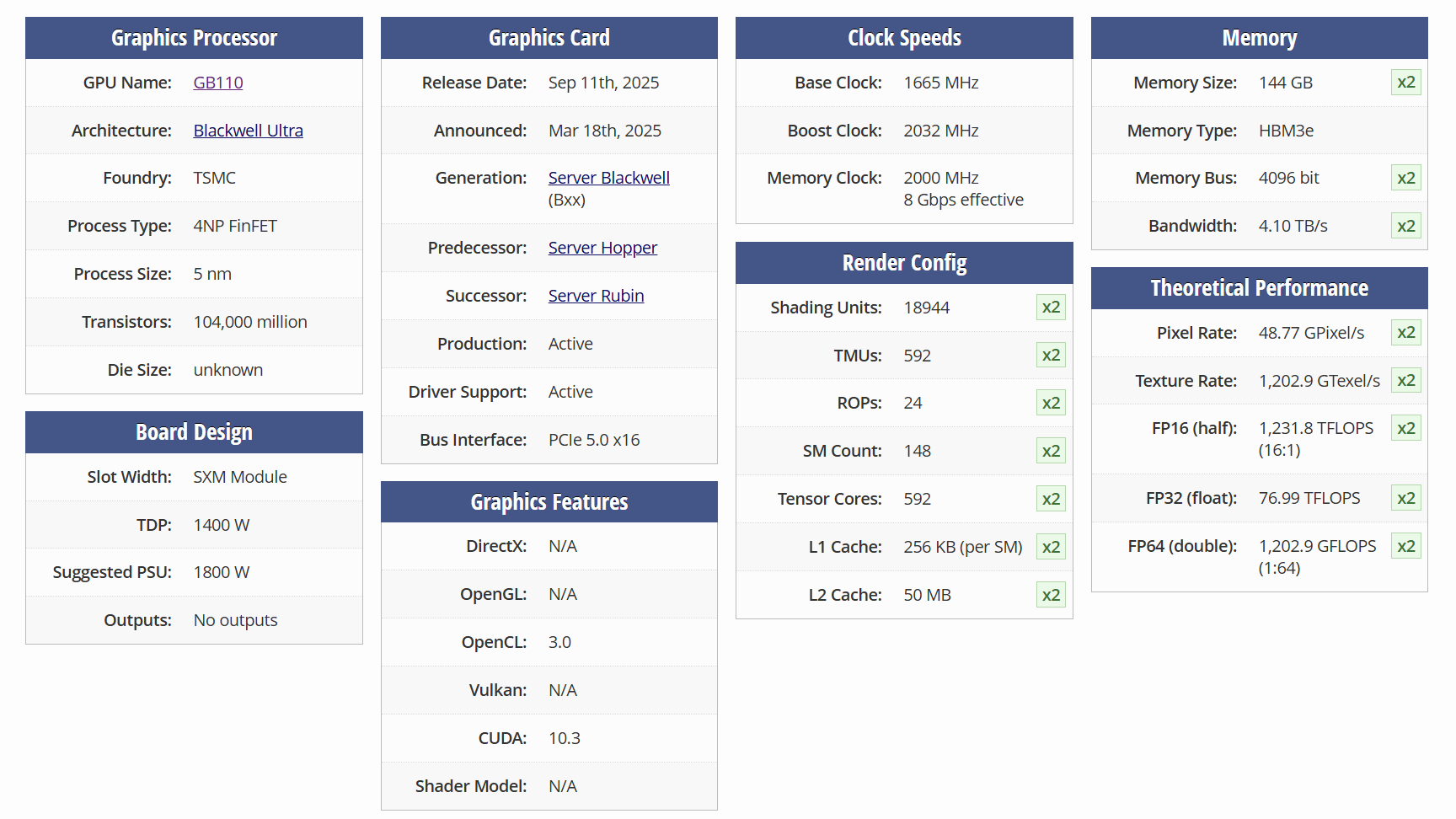
GB300 是什么?
GB300计算托盘的方块图,该设备配备有两枚GB300超级芯片,每枚芯片均集成了两枚NVIDIA B300 Tensor Core GPU和一枚NVIDIAGrace CPU,并通过900GB/s超低功耗NVLink-C2C互连技术进行连接。
GB300 SuperChip为异构计算单元,采用NVLink-C2C超低功耗互联技术,集成:
• 1颗NVIDIA Grace ARM架构CPU
• 2颗B300 Tensor Core GPU
• 互联带宽:900GB/s
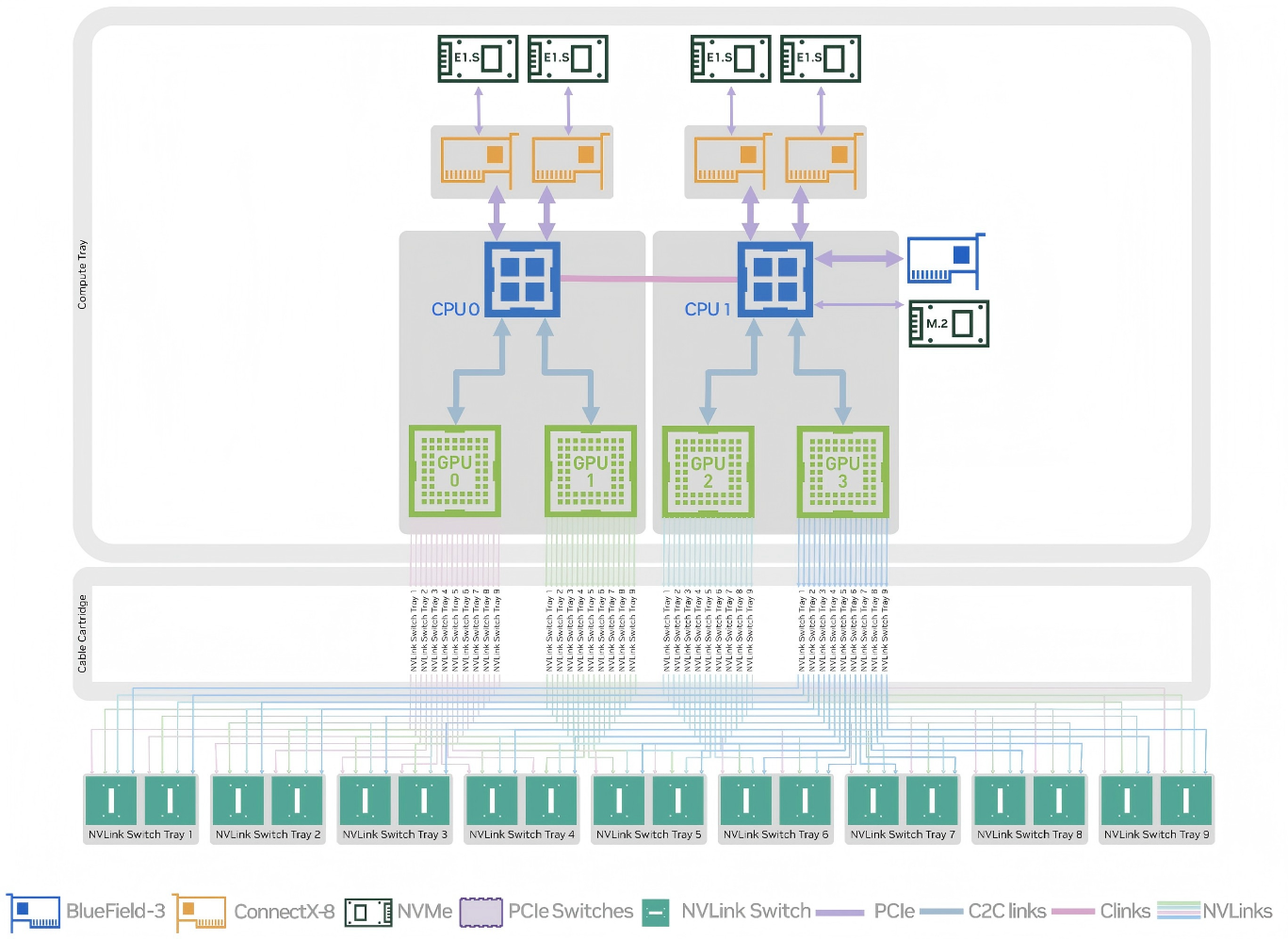
三、CX8 SuperNIC
CX-8 SuperNIC 的 IB 模式支持 1 个 800Gb/s Port 或 2 个 400Gb/s Port、Quantum-X800 InfiniBand。而 Ethernet 模式不支持 800 Gb/s Port,只能用 2 个 400Gb/s Port。
NVIDIA 的下一代 CX9 SuperNIC 会解决 CX8 不支持 800Gbps 以太网 Port 的问题,也就更容易使用第三方的 800Gbps 以太网交换机。
计算托盘集成了四张ConnectX-8网卡,支持机架间计算网络的InfiniBand QUANTUM-X800(800Gbps)连接,以及一块BlueFiled-3网卡,支持带内管理和存储网络的2x400Gbps连接。

四、NVIDIA GB300 NVL72
NVIDIA GB300 NVL72 采用全液冷机架级架构,集成了 72 块 NVIDIA Blackwell Ultra GPU 和 36 块基于 Arm® 的 NVIDIA Grace™ CPU 集成到单一平台。该系统在FP4张量核心FLOPS的密度上是NVIDIA Blackwell GPU的1.5倍,注意力性能也提升了2倍。它专为测试时间扩展推理和人工智能推理任务而设计。由GB300 NVL72加速的AI工厂——利用NVIDIA Quantum-X800 InfiniBand或Spectrum-X™ Ethernet、ConnectX-8 SuperNICs™以及NVIDIA任务控制管理——相比基于NVIDIA Hopper的平台,AI工厂整体产出性能提升了多达50倍。
参数
|
NVIDIA GB300 NVL72 |
|
|
配置 |
72 块 NVIDIA Blackwell Ultra GPU,36 块 NVIDIA Grace CPU |
|
NVLink Bandwidth |
130 TB/s |
|
Fast Memory |
37 TB |
|
GPU Memory | Bandwidth |
20 TB | Up to 576 TB/s |
|
CPU Memory | Bandwidth |
17 TB LPDDR5X | 14 TB/s |
|
CPU Core Count |
2,592 Arm Neoverse V2 cores |
|
FP4 Tensor Core |
1440 | 10802 PFLOPS |
|
FP8/FP6 Tensor Core |
720 PFLOPS |
|
INT8 Tensor Core |
24 POPS |
|
FP16/BF16 Tensor Core |
360 PFLOPS |
|
TF32 Tensor Core |
180 PFLOPS |
|
FP32 |
6 PFLOPS |
|
FP64 / FP64 Tensor Core |
100 TFLOPS |
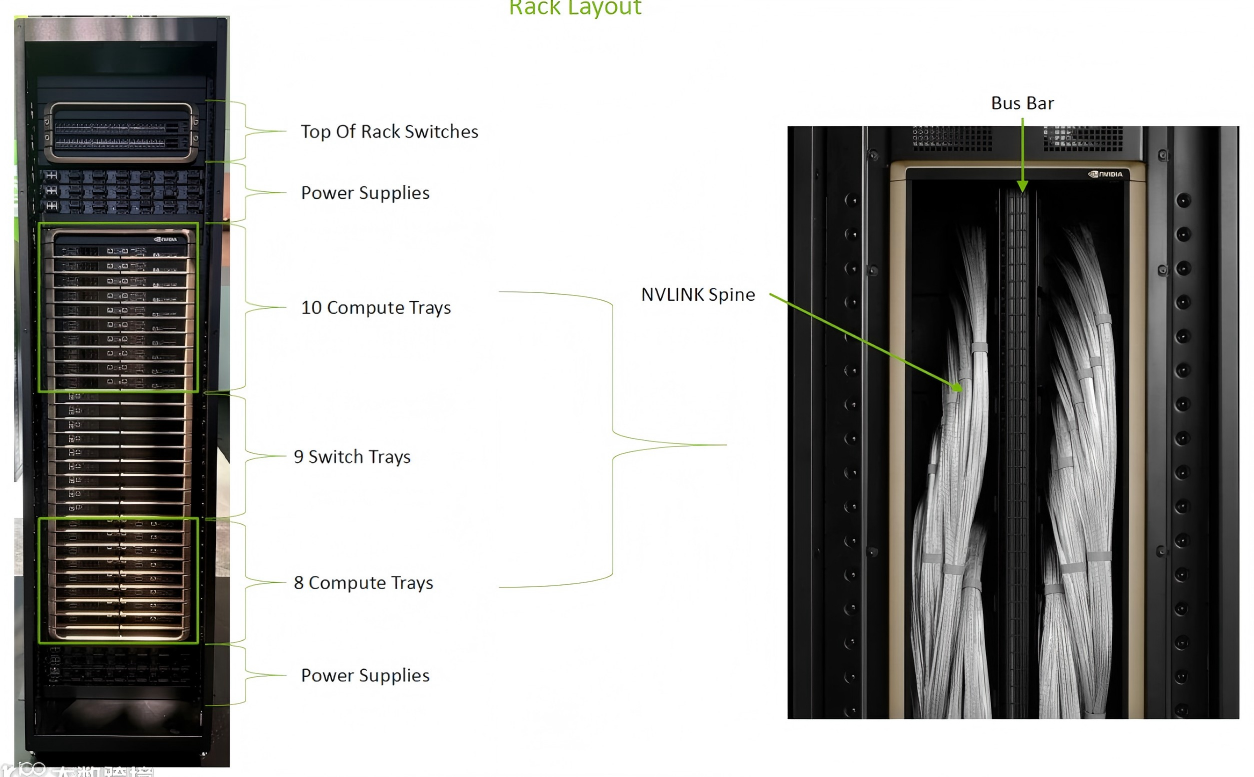
物理架构
GB300 通常提供整机柜(Rack)的 72 GPU 方案,密度更高:
①单 Rack 功耗达到 120kw,需要液冷。
②18 个 Compute Tray,每个 Tray 包含 2 个 GB300(2 个 CPU、4 个 GPU)。
③9 个 NVSwitch Tray,每个 Tray 包含 2 个 NVSwitch,每个 NVSwitch 72 个 Port,连接所有 GPU。
④GB300 NVL72 提供 72 个 800Gb/s Port(CX-8)。
五、集群架构
DGX SuperPOD / 1个可扩展单元(Scalable Unit)基础设施
|
组件 |
技术/型号 |
描述 |
|
SU |
NVIDIA DGX GB300 NVL72 |
8个NVIDIA DGX GB300 NVL72组合成一个SU |
|
NVLink网络 |
NVIDIA NVLink 5 |
NVLink交换机支持同一计算机柜内GPU之间的快速、直接内存访问。 |
|
计算网络 |
NVIDIA Q3400 InfiniBand交换机 |
每个NVIDIA GB300 NVL72提供四个Quantum X-800连接,用于机架间的GPU通信。 |
|
存储和带内管理 |
NVIDIA Spectrum 4 SN5600以太网交换机 |
采用64端口800 Gbps以太网交换机,以高性能提供高端口密度。 |
|
InfiniBand管理 |
NVIDIA Unified Fabric Manager Appliance, Enterprise Edition (统一结构管理器设备,企业版) |
NVIDIA UFM结合了增强的实时网络遥测技术与AI驱动的网络智能和分析能力,用于管理横向扩展的InfiniBand数据中心。 |
|
NVLink管理 |
NVIDIA Network Manager eXperience (NMX-M) (网络管理器体验) |
NVIDIA NMX Manager负责管理和操作NVLink交换机,并提供实时网络遥测以管理所有NVLink基础设施。 |
|
带外管理网络 |
NVIDIA SN2201交换机 |
48端口千兆以太网交换机,采用铜缆端口以降低复杂性。 |
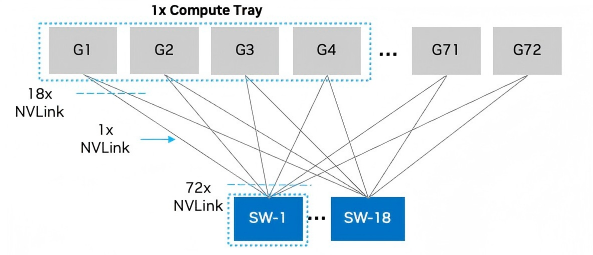
NVLink网络
每个DGX GB300机架均配备有18个计算托盘和9个NVLink交换机托盘。每个NVLink交换机托盘均配置有2个NVLink交换机芯片,负责实现同一DGXGB300架内所有72个GPU之间的全网状连接。每个B300GPU具备18个NVL5链接,并分别拥有一条专用于与18个交换机芯片进行连接的NVL5链接,总带宽为1.8TB/s的低延迟带宽。
计算网络架构
计算架构是一个平衡的、全胖树结构。计算架构采用当前最先进的NVIDIA Q3400 InfiniBand交换机高性能、低延迟网络交换机设计,并支持下一代网络硬件。
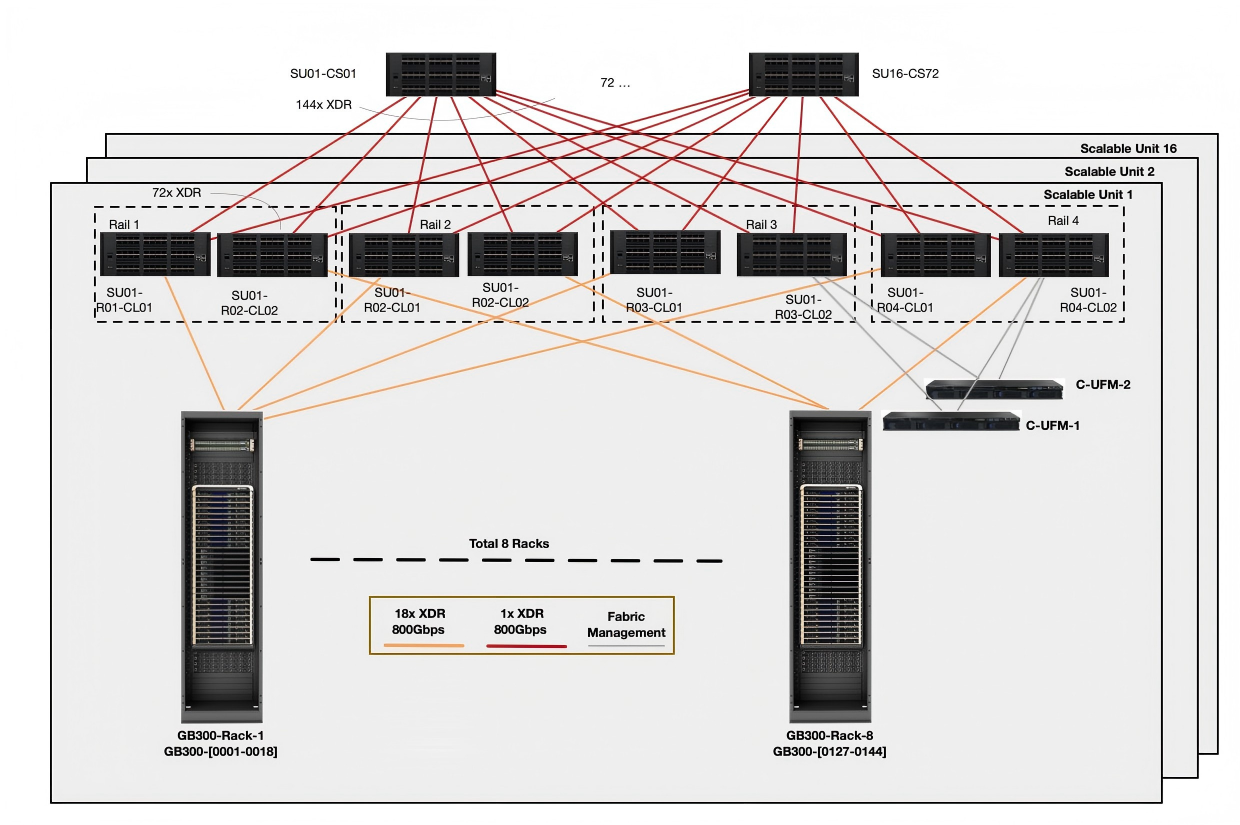
架构讲解
单SU 架构
①8 个 NVL72 Rack = 576 GPU。
②8 个 Leaf Switch,每个 Leaf Switch 144 个 800 Gbps Port。
③一个 Leaf Switch 连接 4 个 Rack,每个连接Rack 18个800 Gbps Port.占用 4 x 18 = 72 个 800 Gbps Port。
④每两个 Leaf Switch一组,构成一个 Rail,每组都会连接 8 个 Rack。
二层架构满配16个SU
①该集群二层架构使用标准的Clos 组网(Q3400 InfiniBand拥有72个上行口数 =72 Spine 台数),最多16个SU在2层架构中聚合一一总共连接9216块GPU。
GPU总计72*8*16=9216 GPU
Leaf Switch总计 对应 8 * 16(SU) = 128 个
每个 Spine Switch 都会连接 128 个 Leaf Switch。
Clos 组网架构Leaf Switch 上行还剩 72 个 Port,需要72 个 Spine Switch
存储架构(高速存储)+带内架构
存储架构为共享存储提供高带宽。它独立于计算架构,以最大化存储和应用性能。为每个DGX GB300计算托盘提供单节点线速400Gbps的传输速率。存储通过RDMAover Converged Ethernet提供,以实现最大性能并最小化CPU开销
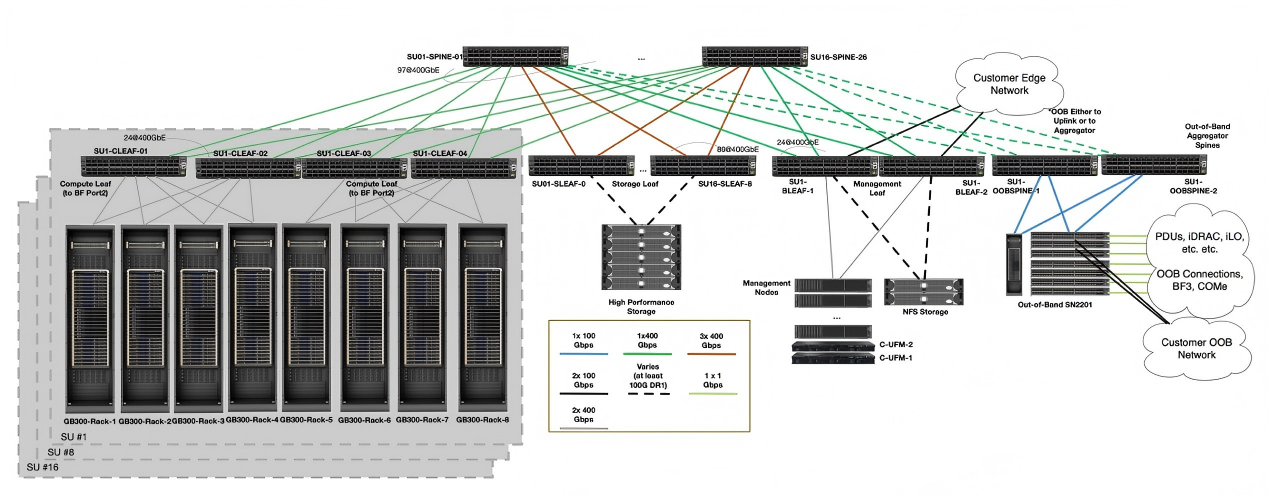
单SU存储架构
①每个SU包含2个spine,SN5600交换机。4个leaf,SN5600交换机。这些交换机与BlueField BF3240双端口卡相连,传输速率为400Gbps,以实现最佳性能和冗余性。
②支持1:3的阻塞比率,单SU拥有144个BlueField BF3240双端口。4个leaf,SN5600交换机拥有246个800G接口。以1:3的阻塞比率,4个leaf有64个上行接口,拥有192个下行接口。
③spine层剩余的接口,接入存储节点和带内管理节点。
核心按Spine-Leaf 二层架构设计,分层标注设备型号、端口速率、连接关系,同时体现计算 / 存储 / 管理三类 Leaf 的差异化设计,拓扑图核心要素如下:
顶层:Spine 交换机(最大 24 台)
中层:三类 Leaf 交换机(计算 Leaf / 存储 Leaf / 管理 Leaf,均为 SN5600D)
底层:计算节点(DGX GB300,搭载 BlueField BF3240 双端口卡)、持久化存储、管理节点、SN2201 带外交换机
链路:全 400Gbps,标注阻塞比 / 非阻塞特性、链路数量
六、总结
GB300集群基于Blackwell+Grace异构架构,依托NVLink 5与800G InfiniBand构建超大规模AI计算平台,单SU可支撑576GPU并行计算,满配16SU支持9216GPU集群,相比Hopper平台AI推理性能提升50倍,是下一代智算中心标准方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)