论文总结:URWKV: Unified RWKV Model with Multi-state Perspective for Low-lightImage Restoration
URWKV: Unified RWKV Model with Multi-state Perspective for Low-lightImage Restoration
URWKV:基于多状态视角的统一RWKV模型用于弱光图像恢复
CVPR 2025文章
目录
近年来,图像恢复领域在去噪、亮度提升和去模糊等单项任务上取得了显著进展。然而,将这些传统方法直接应用于低光图像增强往往效果不佳,主要原因在于低光环境下多种退化因素是耦合的:亮度不足通常伴随着严重的噪声和可能的运动模糊。对其中任一因素的单独调整都可能加剧其他退化(例如,简单提亮会放大噪声),这种固有的权衡给解耦处理带来了巨大挑战。
尽管LLIE模型在架构上不断演进(如引入CNN、Transformer、Mamba等),并展现出处理复杂退化的潜力,但低光环境下的运动模糊依然是当前模型面临的一大挑战。这一挑战的根源在于:运动模糊的物理形成过程(曝光期间传感器上的像素位移)与经典 Retinex理论中的“光照-反射”分解假设不兼容;同时,在低光照下,运动模糊与噪声、亮度不足高度耦合,使得单纯依靠分步处理(如先提亮后去模糊)或现有端到端模型难以有效解耦。即使部分模型尝试联合学习,也常因缺乏真实的成对训练数据而难以在真实手持拍摄场景中取得理想效果。
尽管端到端模型已成为主流,并在许多图像恢复任务中取得了优异表现,但在处理复杂的低光耦合退化时仍面临挑战。例如,一些通用图像恢复模型(包括部分基于Transformer的模型)并未针对低光环境进行专门设计,缺乏对亮度、噪声和模糊之间复杂关系的显式建模,因此在低光图像上可能放大原有退化或引入新的伪影。这种局限性往往导致模型在训练集上表现良好,但在真实场景中泛化能力不足——因为真实低光图像的退化模式与训练数据存在差异,而模型无法根据具体输入动态调整处理策略。
RWKV的核心创新在于其设计的线性复杂度注意力机制,通过将Transformer的注意力计算重构为一种递归形式的WKV(Weighted Key-Value)计算,实现了O(n)的时间复杂度和O(1)的空间复杂度。具体而言,RWKV摒弃了传统注意力中的Query-Key点积计算,改用可训练的衰减因子对历史信息进行指数加权累积,从而在保持全局感受野的同时大幅降低了计算开销。这种设计使RWKV既能像Transformer一样进行高效的并行训练,又能像RNN一样实现高效的序列推理。
尽管RWKV在多个领域展现出潜力,但其仍面临若干挑战:
- 非线性算子的部署难题:RWKV中的Token Shift和Sigmoid等非线性操作阻碍了参数融合,导致在模型量化和压缩时难以像Transformer那样进行平滑的参数量化,给模型在资源受限设备上的部署带来额外计算开销。
- 权重分布的特殊性:RWKV包含大量均匀分布的权重,这对基于聚类的量化方法构成挑战,导致传统的后训练量化技术在应用于RWKV时性能显著下降。
- 单向注意力机制的限制:原始RWKV主要设计用于处理一维序列数据,其单向注意力机制难以直接捕捉二维图像中的空间上下文关系,需要进行专门的架构改造才能有效应用于视觉任务。
- 长序列信息衰减问题:虽然RWKV通过指数衰减机制实现了线性复杂度,但固定的衰减因子可能导致远距离信息的过度衰减,影响对超长序列中弱信号的捕捉能力。
对于这些挑战,URWKV通过引入多状态视角,在保留RWKV高效性的同时,增强了模型对复杂退化模式的建模能力,使其能够更好地适应低光照图像恢复这一具有挑战性的任务。
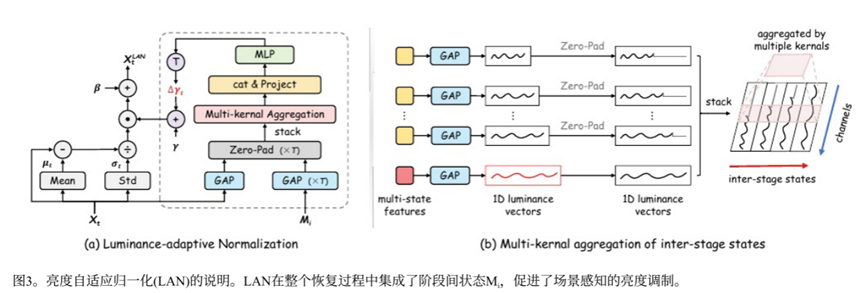
LAN(亮度自适应的归一化),传统模型中使用的LayeNorm在面对低光图像处理的时候,由于低光环境每块区域的亮度不同所以统一固定的LayeNorm对于这种不均匀的分布提亮效果往往不好,所以LAN模拟人的瞳孔,对于不同亮度的部分进行动态化的调整,暗的地方多加一些亮度。
假设我们现在在编码器的第 T 个阶段,当前输入的特征是 Xt(形状是 C×H×W)。我们手里还有前面 1 到 T-1 个阶段输出的特征 M1, M2, ..., M_{T-1}。LAN的操作步骤如下:
- 提取亮度向量:对每个特征图,沿空间维度求平均,得到一个长度为通道数的一维向量,代表每个通道的平均亮度。
- 零填充对齐:因为每个阶段的通道数不相同,所以取当前最长的通道数为Cmax,所有长度不到Cmax的填充0到Cmax。
- 堆成二维图:把这 T 个向量“摞”起来,变成一个 T×Cmax 的二维矩阵,行代表不同阶段,列代表通道。
- 多尺度卷积:对这个二维矩阵沿着通道方向(列)做一维卷积。卷积核大小有 1、3、5 三种,这样既能捕捉局部亮度变化,也能看到全局的亮度变化。三种卷积的结果拼在一起,再用 1×1 卷积融合,得到一个长度为 Cmax 的聚合特征。
- 预测亮度调制因子 Δγ:把聚合特征送进一个小型神经网络(MLP),再经过 tanh 激活,输出一个和当前阶段通道数 C_t 长度一样的向量 Δγ_t。tanh 让输出在 -1 到 1 之间,表示要在原来 γ 的基础上增加或减少多少,比如一个通道是0.2,就相当于对整个通道提亮0.2。
- 更新 γ:新 γ = 原 γ + Δγ_t。
- 归一化:对 Xt 做标准 LayerNorm(减均值、除标准差),然后用新的 γ 和原来的 β 做仿射变换,得到 LAN 的输出。
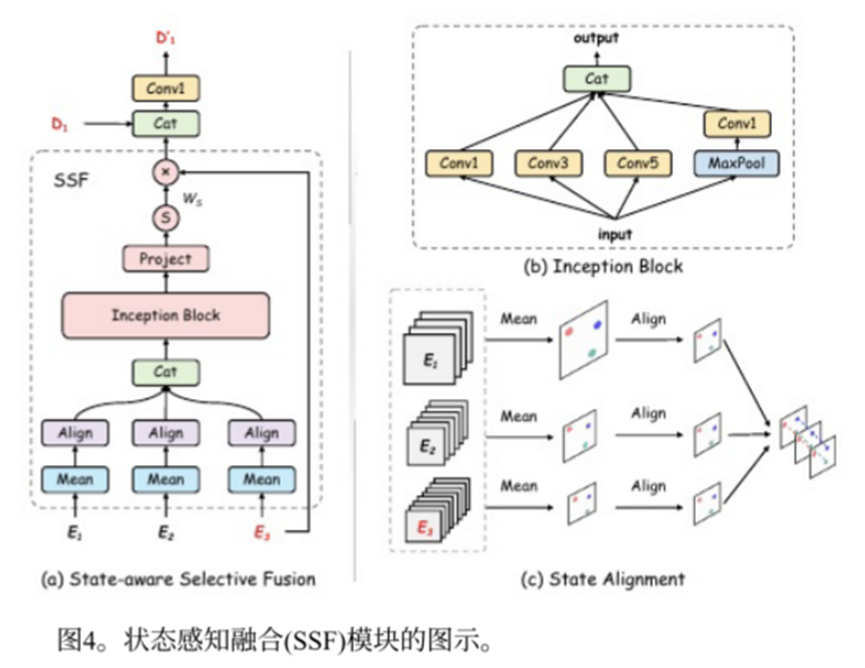
在 U-Net 结构里,通常会用跳跃连接把编码器同尺度的特征拼到解码器上,这样能补充细节。但在低光照情况下,编码器早期的特征可能包含大量噪声,直接拼过去会把噪声带进来。另外,编码器不同阶段提取的特征语义差异很大(早期是边缘纹理,后期是高级语义),直接拼接可能不太搭。SSF 就是为了解决这两个问题:有选择地融合编码器多阶段特征,只拿有用的,过滤掉有害的。
假设当前解码器要融合编码器的三个输出:E1(浅层,大分辨率)、E2(中层)、E3(深层,小分辨率)。目标是把它们融合起来,输送给当前解码器的 URWKV 块。
- 通道压缩:对每个 E 沿通道求平均(不同通道的噪声模式各异,而平均操作可以作为一种廉价的降噪手段,得到一个更鲁棒的“置信度”估计),得到单通道的特征图(1×H×W)。这一步是为了减少不同通道之间的干扰,让后面更容易学到空间上的权重。
- 自适应对齐:因为三个 E 的分辨率不同,需要把它们统一到解码器当前阶段的分辨率(比如 Hd×Wd)。用上采样或下采样(论文里叫 AdaAlign)把它们都变成 Hd×Wd。
- 堆成三通道图:把三个对齐后的单通道图拼在一起,得到一个 3×Hd×Wd 的特征图,三个通道分别对应三个阶段的压缩信息。
- 多尺度卷积(Inception块):用三个不同大小的卷积核(1×1、3×3、5×5)分别对这个三通道图做卷积,提取不同感受野上的融合信息。结果拼在一起,再用一个 1×1 卷积融合,得到一个 Hd×Wd 的聚合特征。
- 生成空间权重:把聚合特征通过一个卷积层,再用 sigmoid 激活,得到一张和 Hd×Wd 一样大的权重图 Ws,每个值在 0~1 之间,表示对应位置应该保留多少信息。
- 选择性融合:用权重图 Ws 和最深层的编码器特征 E3 逐元素相乘(即用权重给 E3 的每个位置打分),然后把加权后的 E3 与解码器当前的特征 D1 在通道维度上拼接起来,最后用一个卷积层做一次整合,得到融合后的特征 D1'。

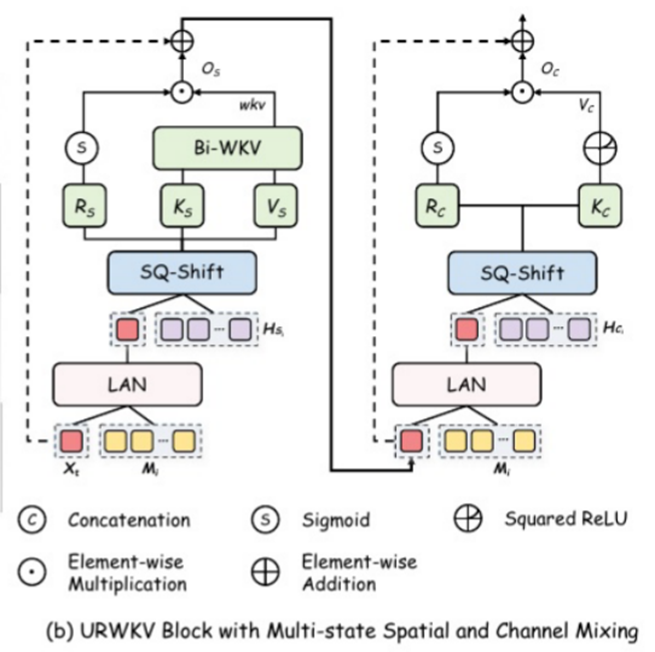
2.3.1.1 运行全流程
- 亮度自适应归一化
- 多状态四方向令牌移位(SQ-Shift)
- 线性投影得到 R, K, V
- 双向 WKV 计算(Bi-WKV)
- 门控与输出投影
这里的输入是X,M和H_s
2.3.1.2 SQ-Shift
核心目标就是让把经过亮度归一化的X的每个位置融合其自身以及上下左右四个邻居的特征信息得到X-Shift。融合的流程一般是用1*1卷积,假设每个像素点只有一个通道,融合的输出就是
output = a * self + b * up + c * down + d * left + e * right + bias
如果出现在边缘的情况,一般采用的方式是补零,即如果该点不存在就用0代替,代码如下
|
import torch def shift_with_zero_padding(x): B, C, H, W = x.shape
# 向上移位(获取下方邻居信息):最后一行移走,顶部补零 x_up = torch.cat([x[:, :, 1:, :], torch.zeros(B, C, 1, W, device=x.device)], dim=2) # 向下移位(获取上方邻居信息):第一行移走,底部补零 x_down = torch.cat([torch.zeros(B, C, 1, W, device=x.device), x[:, :, :-1, :]], dim=2) # 向左移位(获取右侧邻居信息):最后一列移走,左侧补零 x_left = torch.cat([x[:, :, :, 1:], torch.zeros(B, C, H, 1, device=x.device)], dim=3) # 向右移位(获取左侧邻居信息):第一列移走,右侧补零 x_right = torch.cat([torch.zeros(B, C, H, 1, device=x.device), x[:, :, :, :-1]], dim=3)
return x_up, x_down, x_left, x_right |
2.3.1.3 线性投影
通过1*1的卷积,将上一步的输出X-shift分成RKV三个元素,三个元素的形状大小与原图完全相同,他们的作用是:
- R(receptance):相当于一个门控信号,用来控制最终输出中“接受”多少信息。它会经过 sigmoid 激活,输出 0~1 之间的值,决定每个位置、每个通道的信息保留比例。
- K(key):用于计算注意力权重,表示每个位置的特征“被关注”的程度。
- V(value):实际要聚合的信息内容,类似于 Transformer 中的 Value。
2.3.1.4 Bi-WKV
在上一篇RWKV的讲解里面,有WKV的计算公式
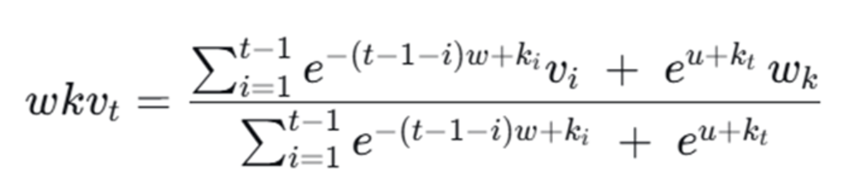
Bi-WKV的本质是让每个像素既能从正向扫描路径也能从反向扫描路径聚合信息,从而模拟出类似Transformer的“双向”全局感受野,Bi-WKV操作正向的过程和RWKV一样,但它多了个反向的过程,就是好把输入序列反转,最后一位变成第一位,然后再用这个公式得到反向WKV,二者相加或者拼接就得到Bi-WKV,一般是相加,因为拼接通道数会翻倍,需要经过一个1*1的卷积再减少回原通道数,代码如下:
|
wkv_fwd = bidirectional_wkv_forward(k, v, w, u) # 正向 wkv_bwd = bidirectional_wkv_backward(k, v, w, u) # 反向(通常是对输入序列反转后计算再反转回来) wkv = wkv_fwd + wkv_bwd # 逐元素相加 |
2.3.1.5 门控与输入投影
对R进行sigmoid,σ(R_s) ∈ (0,1)。然后逐元素与WKV相乘,再通过输出投影层就可以了
O_s = (σ(R_s) ⊙ WKV) · W_O_s
这一步结束后再连接一个残差,这个子块就结束了
2.3.2.1 运行全流程
- 亮度自适应归一化(LAN)
- 多状态四方向令牌移位(SQ-Shift)
- 线性投影得到 R 和 K
- SquaredReLU 激活与值变换
- 门控与输出投影
这里的是X,M和H_c,这里H和上一子块含义一样,只是在运算时隔离运算
2.3.2.2 线性投影得到 R 和 K
这和上一子块不一样,这里只获得R和K,它们的含义如下:
- R_c:接收门,控制输出。
- K_c:键,用于生成值。
2.3.2.3 SquaredReLU 激活与值变换
对K_c应用SquaredReLU,增强非线性。
K_c' = (max(0, K_c))²
通过值投影层 W_V_c(形状 C×C)得到 V_c:
V_c = K_c' · W_V_c
最后得到的V_c的形状(B, C, H, W),相当于混合的值
2.3.2.4 门控与输出投影
对R_c使用Sigmoid函数,然后再逐元素相乘,经过投影层得到通道混合子块输出
O_c = (σ(R_c) ⊙ V_c) · W_O_c
最后再经过一个残差连接就行
空间子块和通道子块在在整体架构上看起来貌似是相同的,其核心区别就是空间子块的Bi_RWKV会让像素点与像素点之间建立联系,通俗的来说就是建立起了空间联系。但是通道混合子块是使用的SquaredReLU它的处理是对于单个像素点的通道之间的混合。总结来说:
- 空间子块:信息在像素之间流动。无论 Bi-WKV 多么复杂,它最终做的是让不同位置的特征相互影响,从而让每个像素获得全局视野。这是典型的空间建模。
- 通道子块:信息在通道之间流动。SquaredReLU 和线性变换只作用于每个像素的通道向量,像素之间完全独立。它相当于在每个位置上做一个“特征重标定”或“特征变换”,让不同通道的特征按需组合,这是典型的通道建模。
我们把整个U形网络的编码层和解码层看作由多个stage构成,由整体架构图可以看出stage=3,每个stage中有多个URWKV子块。
M就是每个stage内最后一个URWKV块的输出,它是在不同stage进行跨通道的信息传递。
H是stage内每个URWKV块的输出,它只存在于这一个stage里面。通过对代码的分析,编码器每个stage内有3个URWKV,解码器每个stage块内有2个URWKV。
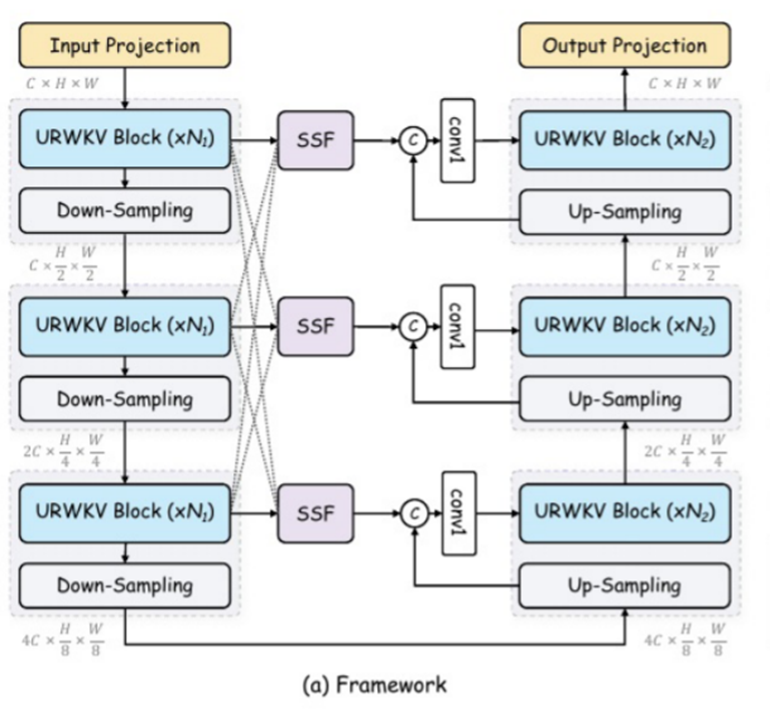
整体架构就是一个U形网络,不过需要注意的是,在编码器阶段,每个stage内有3个URWKV块,解码器阶段,每个stage有2个UREKV块。
2.5 并行训练方式
在传统RWKV里面,通过token-shift以及递归的信息传递实现了并行计算的可能,但是对于URWKV,里面它大量依赖每一步的状态H,这就不能使用传统的RWKV对每一时间步并行计算。
他所使用的是Mamba架构提出的并行关联扫描算法,本质上就是类似二叉树的结构,两两相加计算。
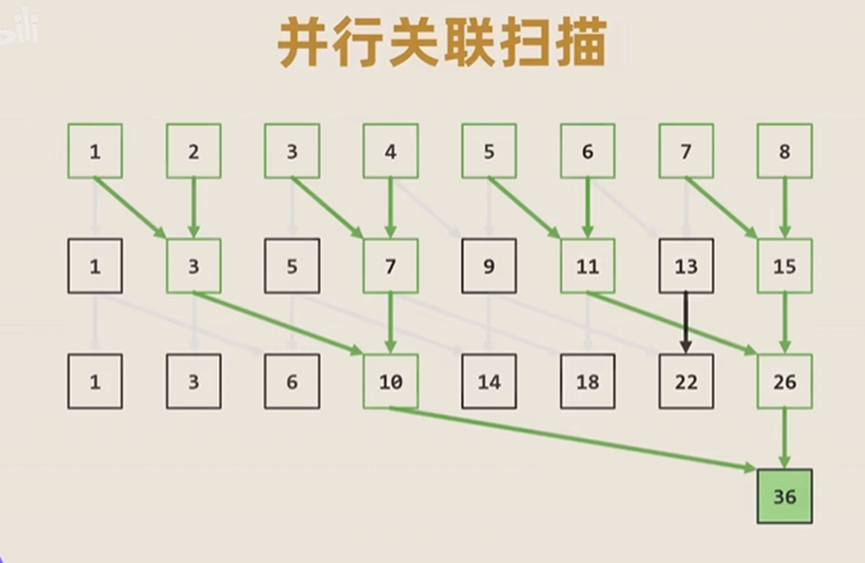


这篇文章主要就是把RWKV这个模型融入到了U形网络中,并做了一些改进以适配图像处理的任务,对于RWKV我目前还不确定这对于我来说是否是一个好的研究方向,但是LAN以及SSF这两个模块应该是可以迁移多来用的,LAN对于亮度的自适应,和SSF对于U形网络的帮助都可以很好的适配LLIE任务。
在最开始了解这篇文章的时候,我一开始想结合之前的P2N说都是减少计算量,能不能结合在一起,但后来意识到RWKV本质上还是一个大的模型,它只是相对于transformer计算量小。
在传统RWKV里面的主要问题之一就是由于没有transformer的全局注意力机制,对于细节的处理没有那么好,这篇文章通过Bi-WKV解决这个问题,但我认为这本质上还是正反串行,它串行就必然会导致2D图像斜向纹理处理有问题,即使论文已经通过一些方法建立联系。整个具体情况还要后续测试
目前对于这篇文章我还是认为RWKV对于长序列输入处理还是更适合处理大块背景

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)