AMP论文:amp算法推导
首先看AMP的总奖励,·奖励分为两部分,一部分为任务奖励,另一部分为风格奖励
![]()
关于判别器的优化目标
本文将重点关注风格奖励是如何计算的
风格奖励是由GAIL(生成式对抗学习)框架改进而来
GAIL的目标是学习一个策略,a是策略的直接输出,从而混淆生成策略的数据与专家数据,旨在精确复刻专家的行为决策
GAIL里有一个判别器与生成器,大概推导与GAN网络类似,但不同的是GAN网络生成独立同分布的数据点,且通过反向传播优化,而GAIL是生成具有时间依赖性的动作序列,通过rl优化
GAN网络的判别器初始优化目标为:
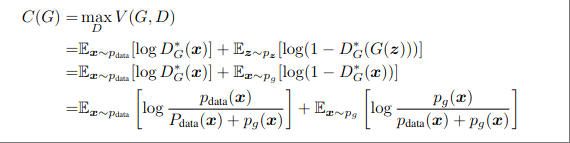
可以对比GAIL的判别器的优化目标:
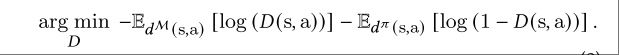
可以看到将GAN网络的x替换为判别器打出的分数再加上负号就可得到上述GAIL要优化的目标
随后将判别器的输出D(s,a),转化为一个鼓励智能体欺骗判别器的强化学习奖励
![]()
AMP的目标是学习一个运动先验,更关注运动本身的风格和质量,而不规定达成该运动的具体控制信号(动作)。其核心思想是:“存在多种不同的动作序列可以实现同一种风格的运动”。即更拟人化一些
论文中基于GAIL的改进
论文中基于GAIL的改进在于将输入判别器的(s,a)转换为(s,s)
改进的核心理由如下:
GAIL 的原始设定要求访问演示者(专家)的动作 [Ho and Ermon 2016]。然而,当演示是以“运动片段”(motion clips)的形式提供时,演示者所采取的动作是未知的,数据中仅能观察到状态
在实际应用中,我们往往只能获得角色在某时间点的位置,速度,关节角度等状态信息,但是对于action,即角色的控制信号如关节力矩或者控制信号等是不可知的,amp的专家数据也是如此,GAIL原始版本要求(s,a)是不可行的,故将输入改为(s,s)
这样做的好处显而易见,不仅可以使机器人更专注于当前的运动状态,也使得判别器的训练更具有通用性和迁移性
将GAIL的优化目标进行替换可得到amp判别器的优化目标,如下:
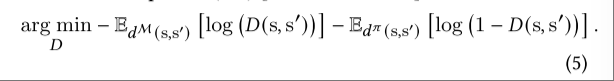
现在的问题在于怎么优化公式5,通常采用一种Sigmoid交叉熵损失函数,但是这种损失往往会引发优化难题,因为当Sigmoid函数达到饱和时会出现梯度消失的情况,这可能会阻碍策略的训练,为了解决梯度消失问题,论文中采用了为最小二乘式生成对抗网络(LSGAN)所提出的损失函数[毛等人 2017 年],该函数在图像合成任务中表现出了更稳定的训练效果和更高的质量结果。
公式如下,使用这个公式来训练判别器:
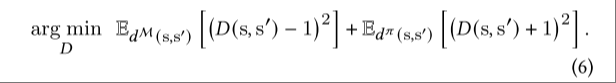
判别器是通过解决一个最小二乘回归问题来训练的,该问题旨在对来自数据集的样本预测出分数为 1,而对来自策略的样本预测出分数为 -1。
论文中所给的奖励函数如下:
![]()
再对上述奖励进行额外的偏移、缩放和裁减操作将奖励范围限定在[0,1]之间
LSGAN设计
"梯度消失"与LSGAN的设计动机:将分类问题转换为回归问题
在传统的GAN中,判别器是一个二分类器,使用二元交叉熵损失,重看GAN判别器的优化目标:
当判别器训练很好时,它对于生成样本的预测概率D(x)会非常接近0(很确定是假的),此时生成的损失函数log(1 - D(G(z)))的梯度会变得很小(趋于0),导致生成器无法获得有效的更新信号,这种现象称为梯度消失
而LSGN就是将判别器的输出任务从二分类概率转变为回归到目标值,并将损失函数改为最小二乘(均方误差):
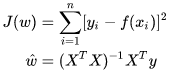
对于生成器的“假样本”:目标值为-1,即使判别器将其判为-0.9,它与目标-1之间仍存在0.01的损失能够提供有效的梯度
对于真样本:目标值为1
这种设计确保了无论在训练的哪个阶段,只要判别器的输出没有完全达到目标值,就会存在一个非零的梯度传递给生成器,缓解了梯度消失问题
专家数据的特征提取
上述我们说到amp的判别器的输入为(s,s),接下来我们对判别器的输入进行特征提取,选择合适的特征集,论文中使用了一个映射函数,提取出与特定运动特征相关的一组特征,这些特征作为判别器的输入


根部的线速度和角速度,以角色的局部坐标系来表示。
• 每个关节的局部旋转。
• 每个关节的局部速度。
末端执行器(例如手和脚)的三维位置,以角色的局部坐标系为基准进行表示。
这些提取的特征刻意过滤了与所给目标g直接相关的信息,与任务目标解耦,所以可以使用同一数据集训练的动作先验用于不同的任务
判别器的梯度惩罚

在生成对抗网络(GAN)中,判别器与生成器之间的相互作用常常会导致训练过程不稳定。这种不稳定的一个原因在于判别器的函数逼近误差,即判别器可能会在真实数据样本的曲面上赋予非零梯度值[梅舍策尔等人,2018年]。
这些非零梯度可能会导致生成器出现过度波动的情况,导致策略为了追求更高风格奖励,生成的动作偏离真实分布,出现过度拟合单一风格或运动突变问题。
为了缓解这一现象,论文作者在判别器的损失函数中加入额外惩罚项,对真实运动样本的观察特征 计算梯度的 L2 范数,惩罚非零梯度。
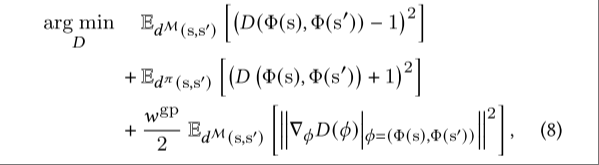
算法流程总结

数据收集:在当前环境,收集m条轨迹,对于轨迹中的每一步t:
-
接收状态
s_t,选择动作a_t。 -
执行后得到新状态
s_{t+1}和任务奖励r_t^G。 -
计算风格奖励
r_t^S(通过判别器D)。 -
计算总奖励
r_t。 -
将转移
(s_t, a_t, s_{t+1}, r_t^G, r_t, ...)存入经验回放缓冲区B
判别器更新:在收集完m条轨迹后
-
进行
n次内循环更新。 -
每次更新,从专家数据集
M和缓冲区B中采样批次。 - 通过最小化包含梯度惩罚的LSGAN损失来更新判别器
D的参数。
策略更新:在判别器更新完成后:
-
使用收集到的
m条轨迹数据(状态、动作、总奖励等)。 -
计算优势估计
Â_t(通常用GAE)。 - 通过最大化PPO的裁剪替代目标函数,更新策略
π和价值函数V的参数。
循环:用更新后的策略π,回到步骤1,开始下一次迭

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)