CPU 并行编程系列(二)《CPU 性能加速实战》
目录
本文介绍 CPU 性能加速的实战经验,重点讲解矩阵运算的并行优化方法。
测试框架说明
1. 框架用途
针对大模型推理中的矩阵运算(如 GEMM)设计,支持并行化开发与性能测试。
2. 框架获取
-
• GitHub 与 Gitee 地址(推荐Gitee以避免访问不稳定)

3. 环境配置
-
• Windows 系统推荐使用 WSL(Ubuntu子系统)进行开发。
-
• 配置步骤:微软商店安装 Ubuntu → 一键安装 → 虚拟环境开发。
4. 框架使用方法
-
• 代码拉取:通过 git clone 下载仓库代码。
-
• 构建工具:使用 xmake 进行编译,生成二进制文件。
-
• 运行程序:
-
• 编译:xmake
-
• 运行:xmake run(自动执行可执行文件)
-
框架目录结构与矩阵运算实现
1. 目录结构
重点关注 kernels 文件夹:存放矩阵运算实现代码。
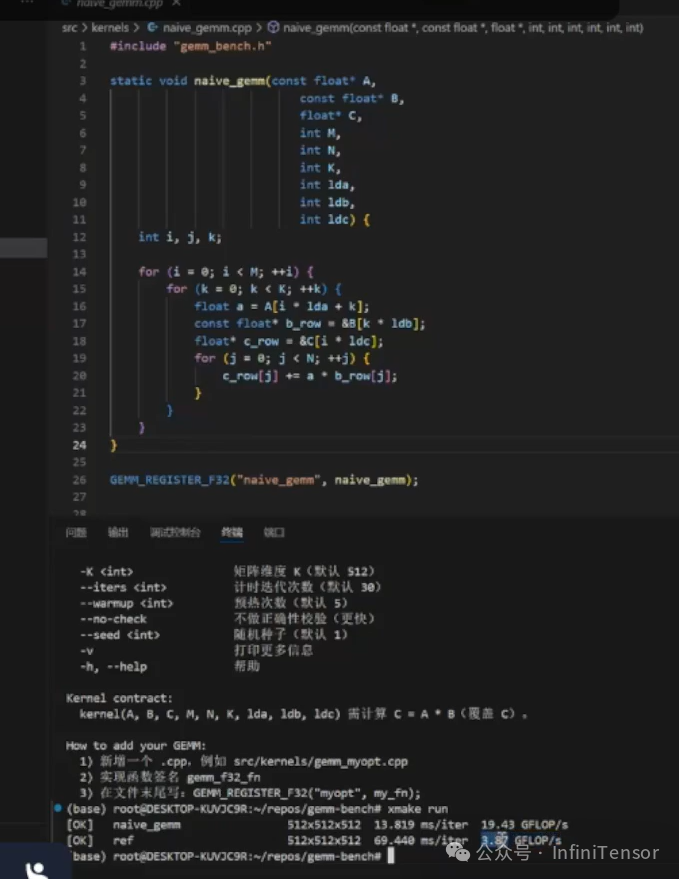
2. 示例代码分析
-
• Naive GEMM:基础矩阵乘法实现,包含内存重排优化。
-
• 性能验证:
-
• 默认矩阵大小:M=N=K=512。
-
• 输出指标:每次运算时间、GFLOPS(每秒十亿次浮点运算)。
-
• 性能对比:通过重排优化显著提升性能。
-
3. 实战操作
-
• 新建文件:在 kernels 文件夹中实现自定义矩阵运算代码。
-
• 性能测试:通过框架自动运行并输出性能指标。
BLAS 接口标准与矩阵运算参数
1. BLAS 接口概述
-
• 目的:统一矩阵运算库的接口规范,支持复杂参数(如矩阵存储方式、转置等)。
2. 关键参数

-
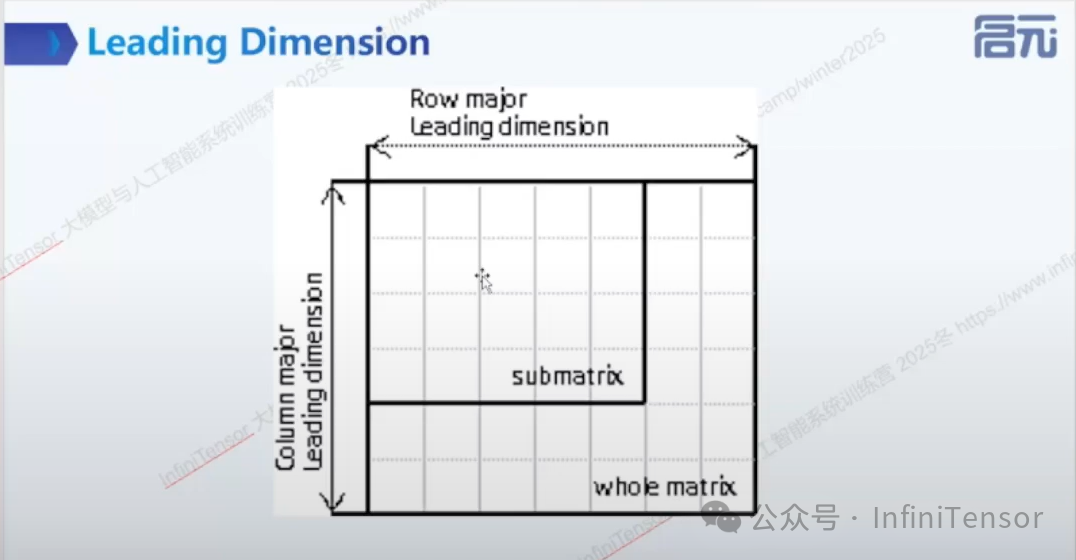
• Leading Dimension:
-
• 定义:矩阵中相邻行或列之间的元素间隔(内存连续存储的跨度)。
-
• 作用:支持子矩阵运算,避免内存拷贝开销。
-
3. 转置与 Leading Dimension 结合
-
• 转置效果:通过转置参数改变内存读取方式(行变列或列变行)。
-
• 示例:若矩阵 B 为列主序且转置,则按行读取内存。
循环重排与性能优化
1. 循环重排原理
-
• 内存连续访问:通过调整循环顺序提升缓存命中率。
-
• 示例:Naive GEMM 中的内存重排优化。
2. 性能对比
-
• 重排前:性能较低(如 Intel 处理器基准性能低)。
-
• 重排后:性能显著提升(GFLOPS 增加)。
多线程并行化实现
1. 多线程概念
-
• 任务分块:将矩阵运算任务分配给多个线程并行执行。
2. 代码实现
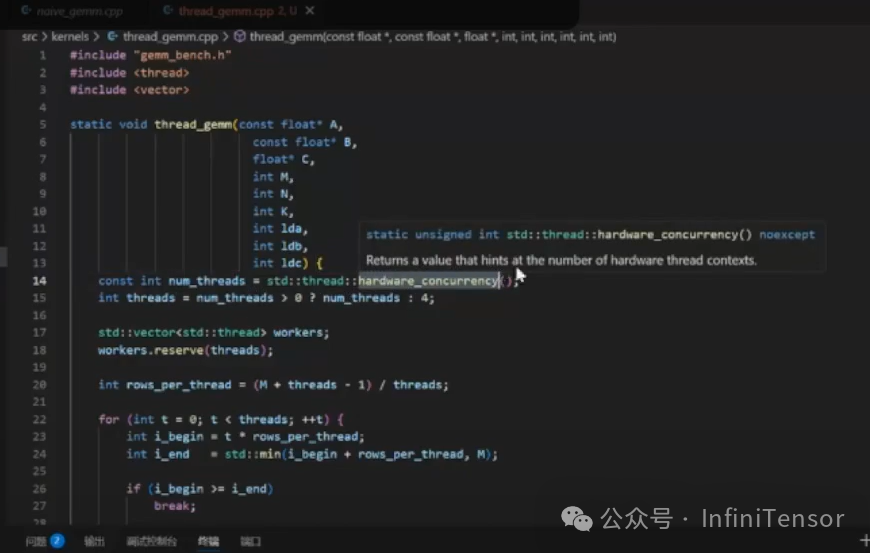
-
• 线程创建:使用 C++
<thread>库动态创建线程。 -
• 硬件并发数:通过
std::thread::hardware_concurrency()获取 CPU 支持的线程数。
-
• 任务划分:
-
• 按行分块:每个线程计算矩阵 C 的若干行。
-
• 数据结构:定义
gemtask结构体保存任务范围(begin、end)。
-
-
• 线程管理:使用
std::vector存储线程对象,通过emplace_back创建并启动线程。
3. 性能验证
-
• 多线程 GEMM:实现多线程矩阵乘法,性能提升显著(如 4 倍于 Naive 实现)。
-
• 性能波动:受系统调度影响,结果存在动态范围。
OpenMP 并行化实现
1. OpenMP 简介
-
• 作用:通过编译器指令自动实现循环并行化。
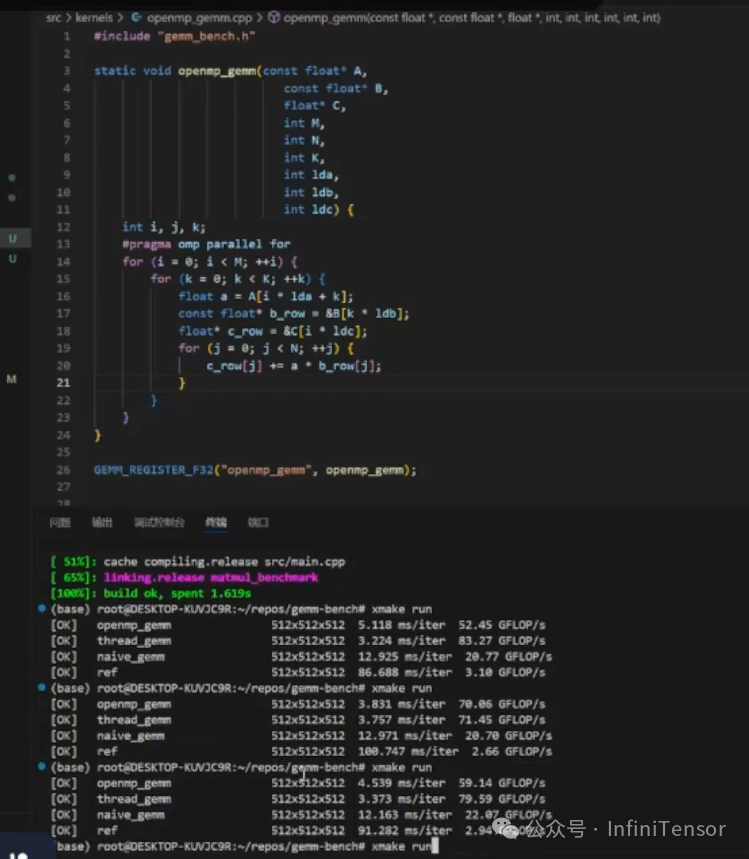
2. 代码实现
-
• 在循环前添加
#pragma omp parallel for指令。 -
• 环境配置:编译时添加
-fopenmp或/openmp。
SIMD 指令集加速
1. 寄存器优化
-
• 利用 CPU 寄存器并行处理多个数据(如 AVX 指令集处理 8 个 F32 数据)。
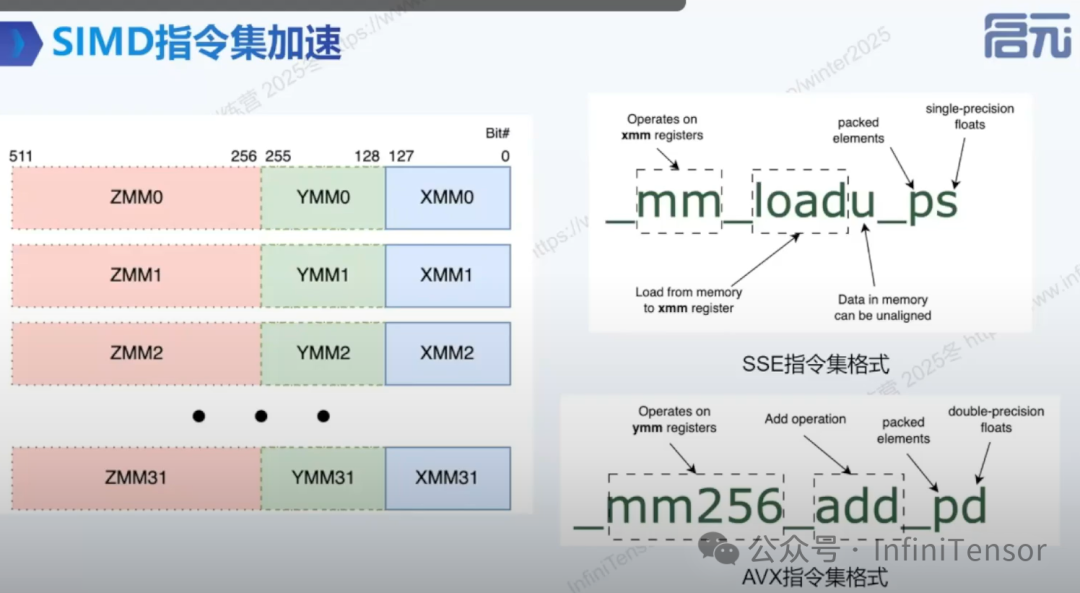
2. 代码实现
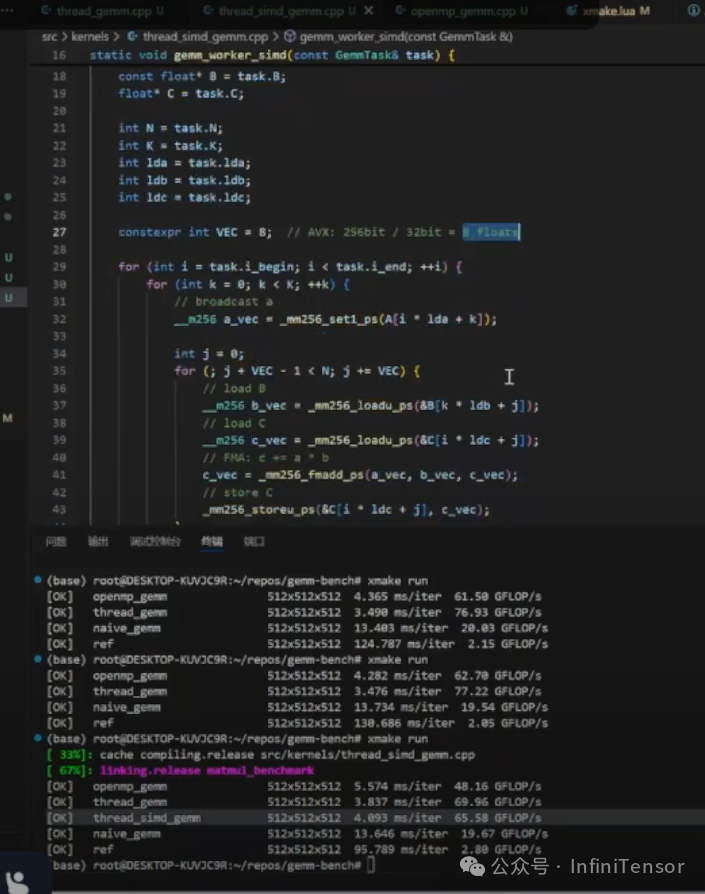
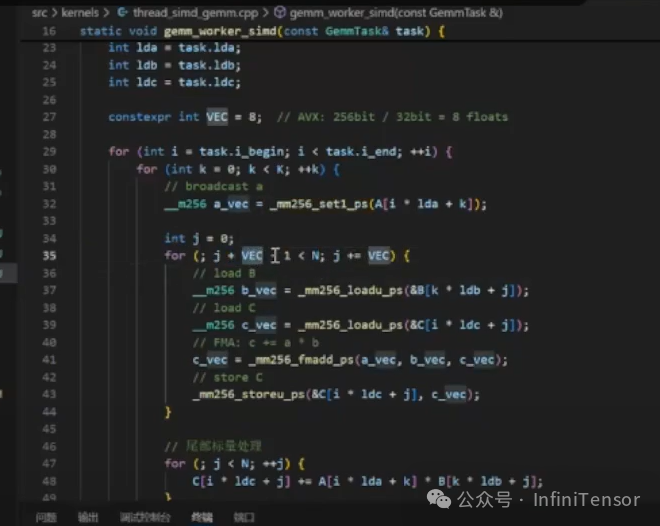
3. 性能验证
-
• SIMD GEMM:性能提升显著,但受任务划分与对齐影响可能不稳定。
Intel MKL 库最优实现
1. MKL库简介
-
• 作用:Intel 提供的优化数学库,包含高性能矩阵运算实现。
2. 代码实现
-
• 函数调用:使用
cblas_sgemm函数实现矩阵乘法。 -
• 参数配置:指定行主序、转置、缩放系数等。
3. 性能对比
-
• MKL GEMM:性能远超手动实现(如 GFLOPS 稳定在 200 以上)。
总结
本文讲解了多线程、OpenMP、SIMD、MKL库等内容,未来课程可讲解 INT8 量化加速。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)