少样本分类神器SetFit:只用32个样本,性能媲美全量微调BERT!
在现实世界的NLP应用中,标注数据往往是稀缺资源。你可能只有几十条带标签的样本,却希望训练一个高精度的分类模型。传统的监督学习需要大量标注数据,而少样本学习(Few-shot Learning)正是为解决这一困境而生。
今天,我们将介绍一种强大的少样本分类框架——SetFit(Sentence Transformer Fine-tuning)。它仅需每个类别提供少量标注样本(例如16条),就能达到与全量数据微调BERT相媲美的性能。我们将深入剖析SetFit的原理、实现步骤,并通过代码演示如何在情感分类任务上使用它。
一、什么是少样本分类?为什么需要SetFit?
少样本分类的目标是:仅用少量标注样本,让模型学会区分不同的类别。例如,你只有几条正面影评和几条负面影评,却希望模型能对成千上万条新影评进行准确分类。
传统做法通常依赖大规模预训练语言模型+提示工程(Prompting),但提示设计复杂且不稳定。SetFit则另辟蹊径,它基于sentence-transformers,通过对比学习生成高质量的句子嵌入,再训练一个简单的分类器,在少样本场景下表现惊艳。
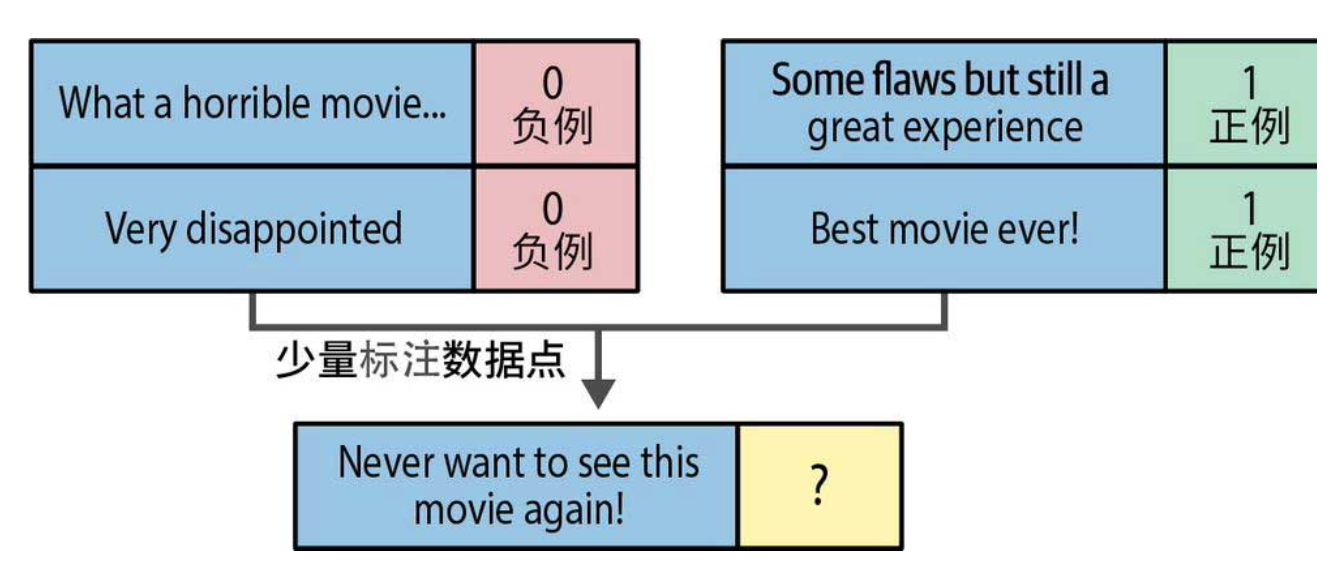
下图直观展示了少样本分类的概念:每个类别只提供几个标注样本,模型就能对未知样本进行预测。
二、SetFit的三个核心阶段
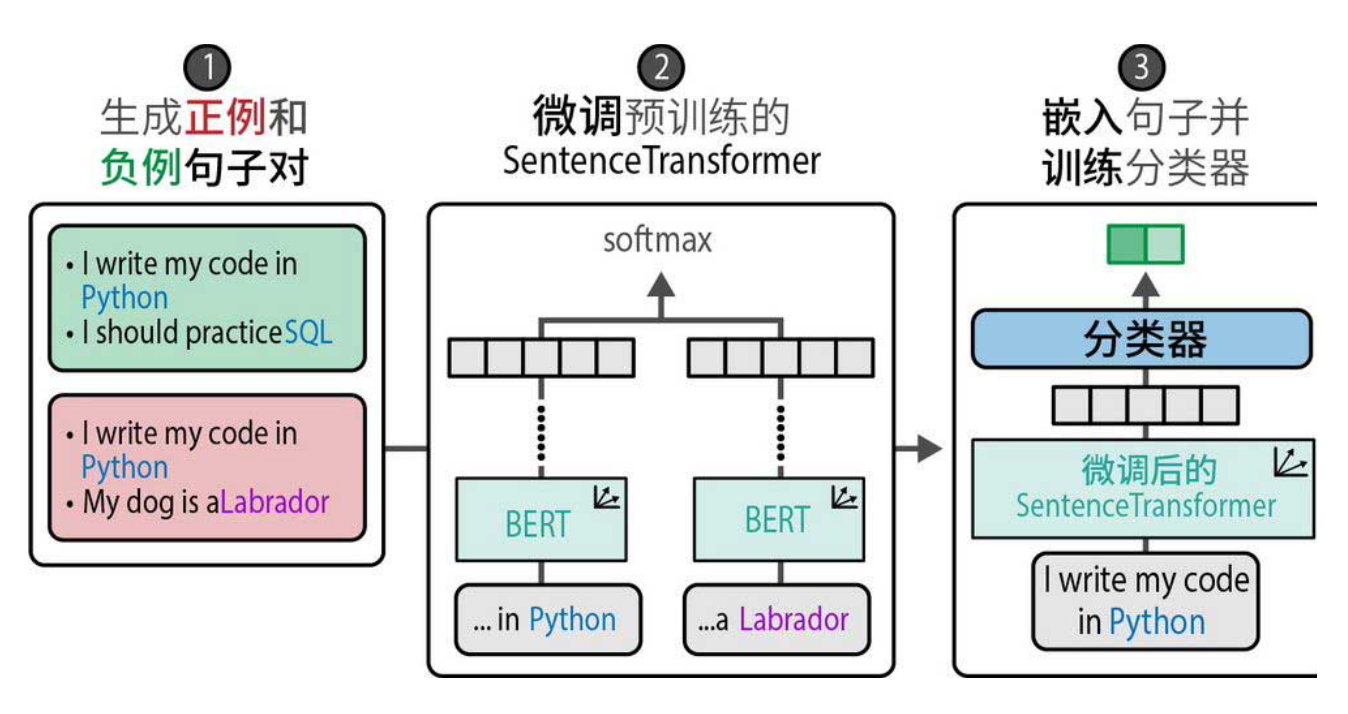
SetFit的工作流程分为三个阶段,如下图所示:
-
生成正负例句子对
-
微调嵌入模型(SentenceTransformer)
-
训练分类器
下面我们逐一详解。
2.1 阶段1:从标注数据生成句子对
原始的标注数据只有文本和类别标签,没有直接的“句子对”标注。SetFit巧妙地利用类别信息构造正负例对:
-
正例对:同一类别内的两个句子(语义相似)。
-
负例对:不同类别的两个句子(语义不相似)。
例如,假设我们有关于“编程语言”和“宠物”的两类文本:
| 文本 | 类别 |
|---|---|
| I write my code in Python | 编程语言 |
| I should practice SQL | 编程语言 |
| My dog is a labrador | 宠物 |
| I have a Siamese cat | 宠物 |
我们可以生成的正负例对:
-
正例对: (I write my code in Python, I should practice SQL)
-
正例对: (My dog is a labrador, I have a Siamese cat)
-
负例对: (I write my code in Python, My dog is a labrador)
-
负例对: (I have a Siamese cat, I should practice SQL)
通过这种组合,即使只有少量原始样本,也能生成大量训练对。例如,每个类别有16个样本,则正例对数量为 16×(16−1)/2=12016×(16−1)/2=120 对,负例对可以跨类别组合,数量更可观。
2.2 阶段2:微调SentenceTransformer模型
有了句子对,我们就可以采用对比学习来微调一个预训练的SentenceTransformer模型(如all-mpnet-base-v2)。对比学习的目标是让正例对的嵌入向量距离更近,负例对的嵌入向量距离更远。
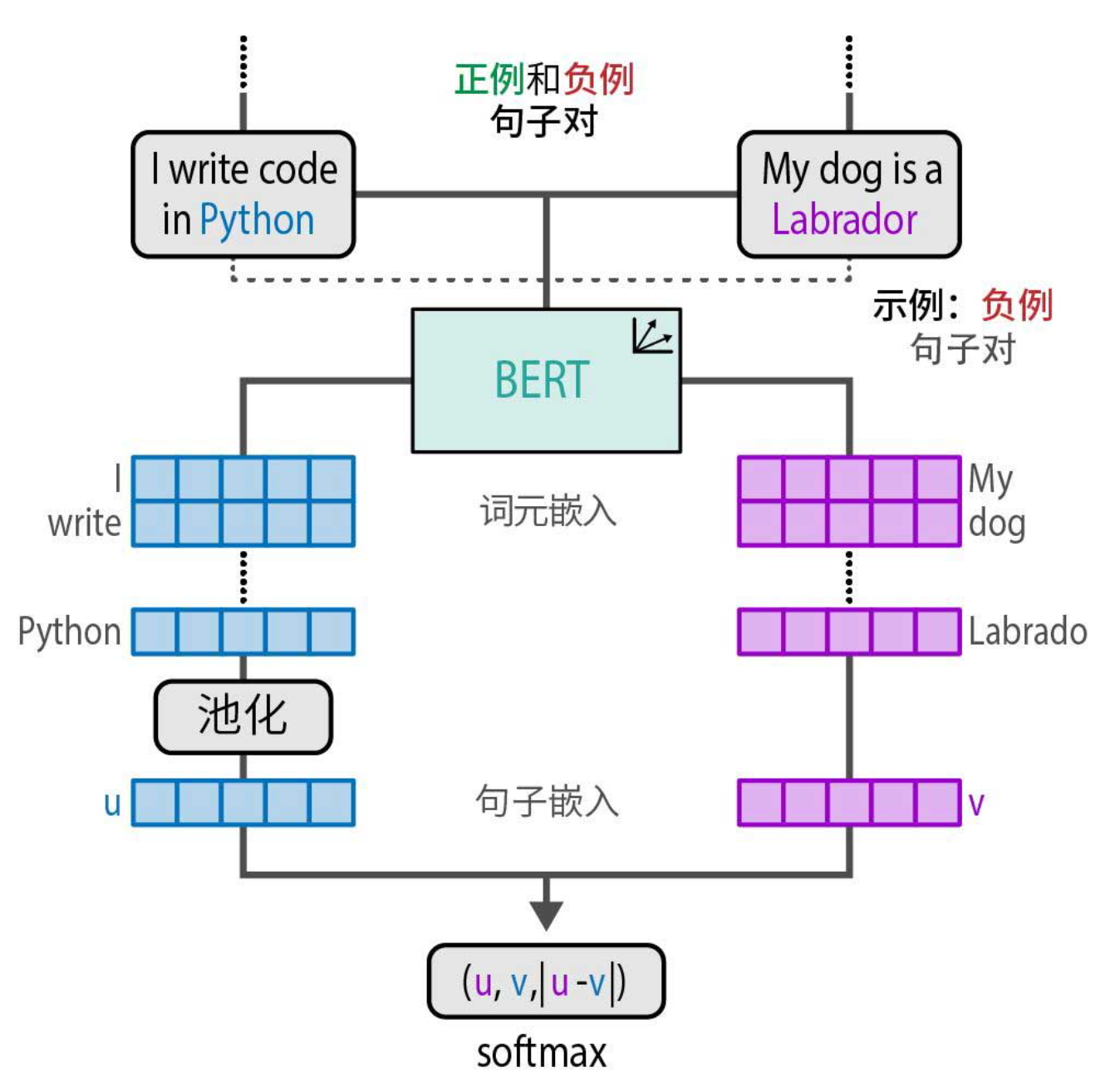
如下图所示,每个句子对通过BERT编码,经过池化得到句子嵌入u和v,然后将(u, v, |u-v|)拼接后输入一个softmax分类层,预测这对句子是相似还是不相似。通过这种方式,模型学会了将语义相似的句子映射到相近的向量空间,而这个空间正好与类别标签对齐。
2.3 阶段3:训练分类器
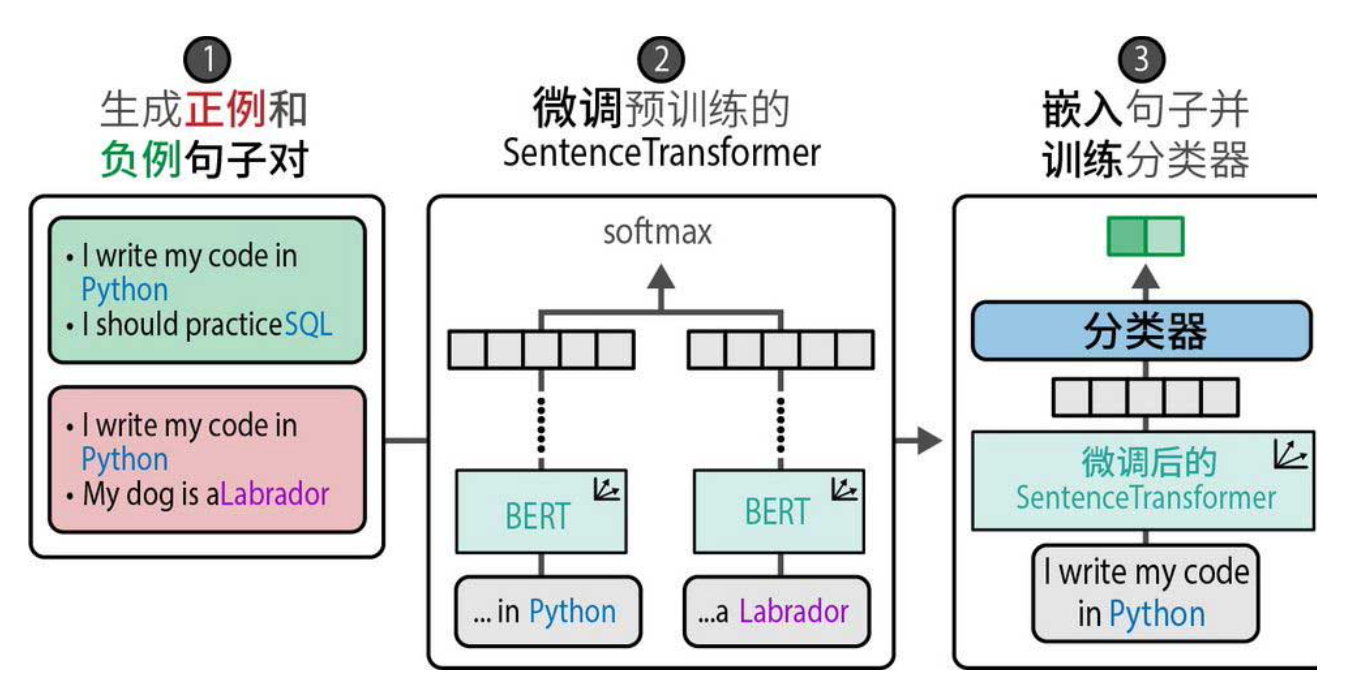
微调完成后,我们用这个SentenceTransformer为所有训练句子生成嵌入向量。这些向量已经富含类别判别信息。接着,我们可以在这些向量上训练一个简单的分类器(默认是逻辑回归,也可以用PyTorch自定义分类头)。
如下图所示,训练好的分类器接收新句子的嵌入向量,输出类别概率。由于嵌入已经高度区分,分类器可以轻松学会分类边界。
三、实战:用SetFit进行少样本情感分类
接下来,我们使用烂番茄影评数据集(二分类)演示SetFit的用法。我们将从每个类别随机抽取16个样本(共32条)作为训练集,测试集保持原样(约数千条)。
3.1 安装与导入
SetFit是一个独立的库,基于Hugging Face的transformers和sentence-transformers。首先安装:
bash
pip install setfit
然后导入所需模块:
python
from datasets import load_dataset from setfit import sample_dataset, SetFitModel, SetFitTrainer, TrainingArguments as SetFitTrainingArguments
3.2 加载数据并采样
python
# 加载完整数据集
tomatoes = load_dataset("rotten_tomatoes")
# 从训练集中每个类别采样16条
sampled_train_data = sample_dataset(tomatoes["train"], num_samples=16)
test_data = tomatoes["test"] # 保留完整测试集用于评估
3.3 加载预训练模型
SetFit的核心是一个SentenceTransformer模型。我们选择MTEB排行榜上表现优异的all-mpnet-base-v2:
python
model = SetFitModel.from_pretrained("sentence-transformers/all-mpnet-base-v2")
3.4 配置训练参数
SetFitTrainer需要指定对比学习的轮数(num_epochs)和每对原始样本生成的句子对数量(num_iterations)。默认num_iterations=20,因此总句子对数为:20 × 样本数 × 2(因为每对需要正向和反向)。对于32个样本,即 20×32×2=128020×32×2=1280 对。
python
args = SetFitTrainingArguments(
num_epochs=3, # 对比学习轮次
num_iterations=20, # 每样本生成的句子对数量
eval_strategy="epoch" # 每轮评估
)
3.5 创建训练器并训练
python
trainer = SetFitTrainer(
model=model,
args=args,
train_dataset=sampled_train_data,
eval_dataset=test_data,
metric="f1"
)
trainer.train()
训练过程中会输出类似以下信息:
text
***** Running training ***** Num unique pairs = 1280 Batch size = 16 Num epochs = 3 Total optimization steps = 240
3.6 评估模型
训练完成后,在测试集上评估:
python
results = trainer.evaluate() print(results)
输出示例:
python
{'f1': 0.8364}
0.84的F1分数! 仅用32条标注样本,就达到了与之前用全量数据(约8500条)训练逻辑回归相当的性能(0.84 vs 0.85)。这充分展示了SetFit在少样本场景下的强大能力。
3.7 自定义分类头(可选)
默认分类器是逻辑回归,如果你想用可微分的神经网络头,可以在加载模型时指定:
python
model = SetFitModel.from_pretrained(
"sentence-transformers/all-mpnet-base-v2",
use_differentiable_head=True,
head_params={"out_features": 2} # 二分类
)
然后照常训练即可。
四、SetFit的扩展:零样本分类
SetFit不仅支持少样本,还能扩展到零样本分类。原理是通过类别名称自动生成合成样本(如“This example is happy”和“This example is sad”),然后在这些合成样本上训练SetFit模型。这样,即使没有任何真实标注数据,也能进行分类。
五、为什么SetFit如此高效?
-
对比学习的力量:通过构造正负例对,模型学会了将同类样本拉近、异类样本推远,直接优化了嵌入空间的判别性。
-
轻量级分类器:最终的分类器仅需在少量嵌入上训练,不易过拟合。
-
无需提示工程:完全避免了设计模板的麻烦和不确定性。
-
数据效率极高:从少量样本中生成大量训练对,充分挖掘数据潜力。
六、总结与建议
-
适用场景:当你只有几十到几百条标注数据时,SetFit是极佳的选择。它在情感分析、意图识别、主题分类等任务上表现出色。
-
性能:在烂番茄数据集上,用32条样本达到0.84 F1,接近全量微调BERT的0.85,而数据量仅为后者的1/250。
-
易用性:SetFit库提供了简洁的API,几行代码即可完成训练。
-
扩展性:支持零样本分类,进一步降低了对标注数据的依赖。
如果你正在为标注数据不足而苦恼,不妨试试SetFit。它可能会让你惊讶:原来少样本也能做得这么好!
本文参考:图解大模型:生成式AI原理与实战
书籍pdf免费下载地址:https://pan.baidu.com/s/1mTaUQ5czcfGpBM8KvJuS2g?pwd=un44

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献131条内容
已为社区贡献131条内容

所有评论(0)