复现 NGAFID 航空维护预测任务:从 Baseline 到 CNN + Mamba
本文记录一次对论文 A Large-Scale Annotated Multivariate Time Series Aviation Maintenance Dataset from the NGAFID 的实验复现过程。
复现任务为论文中的 maintenance event detection(before-after 二分类任务),并在复现 baseline 的基础上,对数据处理和模型结构进行了简单探索。
一、任务背景
航空预测性维护(Predictive Health Management, PHM)是近年来的重要研究方向。通过分析飞行传感器数据,可以提前预测设备故障或维护需求,从而提高安全性并降低维护成本。
NGAFID(National General Aviation Flight Information Database)是一个公开的航空飞行数据平台,论文 A Large-Scale Annotated Multivariate Time Series Aviation Maintenance Dataset from the NGAFID 构建了一个大规模航空维护数据集,并提出多个预测任务。
本文关注其中的 maintenance event detection 任务。
任务目标:
判断某一航班发生在维护事件 之前(before) 还是 之后(after)。
这是一个 二分类时间序列任务。
二、数据集结构
论文提供的 benchmark subset 为 2days dataset。
数据文件主要包括:
flight_header.csv flight_data.pkl stats.csv
数据关系如下:
flight_header.csv │ │ Master Index ▼ flight_data.pkl
flight_header.csv
每一行对应一个航班样本,主要包含:
-
航班ID
-
标签信息
-
数据划分
关键字段:
before_after # before / after 标签 fold # 五折交叉验证划分
flight_data.pkl
存储时间序列数据:
{
Master Index : (T, 23)
}
其中:
-
T:时间步长度
-
23:传感器通道
因此原始数据为 变长多变量时间序列。
stats.csv
记录每个通道的最小值与最大值,用于 MinMax 归一化。
三、论文中的数据预处理
根据官方 dataset.py,baseline 预处理流程为:
-
MinMax 归一化
x = (x - min) / (max - min)
-
序列长度统一为 4096
-
长序列:截断最后 4096
-
短序列:padding 0
-
NaN → 0
np.nan_to_num()
四、数据初步分析
为了了解数据特点,对数据进行简单的统计分析。
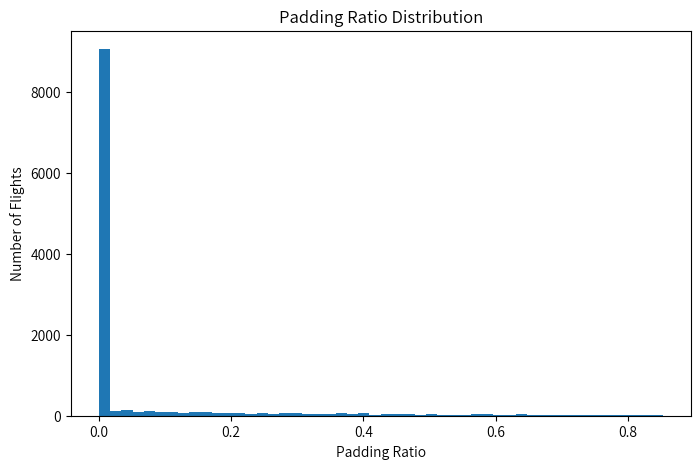
主要发现:
-
类别分布基本平衡
-
padding ratio ≈ 6%
-
73% 航班包含 NaN
-
但总体缺失比例 ≈ 1%
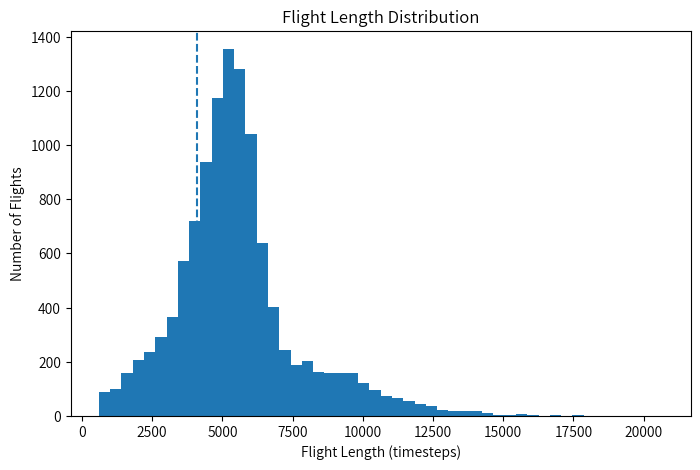
飞行长度分布呈现:
-
单峰分布
-
明显右长尾
-
大多数集中在 4000–7000 timesteps。
-
-
五、Baseline 模型复现
论文提供三个 baseline:
MiniRocket ConvMHSA InceptionTime
复现环境:
Google Colab Python 3.12
复现过程中遇到两个环境问题。
Python 3.12 删除 imp 模块
错误:
ModuleNotFoundError: No module named 'imp'
解决:
import sys import importlib sys.modules['imp'] = importlib
Google Drive 下载链接失效
原 dataset 下载链接已经不可用,需要:
-
手动下载数据
-
上传到自己的 Google Drive
-
修改 dataset.py 下载地址
六、Baseline 复现结果
| Model | Mean Acc |
|---|---|
| MiniRocket | 0.593 |
| ConvMHSA | 0.762 |
| InceptionTime | 0.718 |
与论文对比:
| Model | Paper | Reproduced |
|---|---|---|
| MiniRocket | 0.598 | 0.593 |
| ConvMHSA | 0.760 | 0.762 |
| InceptionTime | 0.755 | 0.719 |
总体来看:
-
MiniRocket 与 ConvMHSA 基本一致
-
InceptionTime 略低
可能原因:
-
环境差异
-
随机初始化
-
实现细节
七、数据预处理实验
由于 MiniRocket 训练速度较快,因此使用其测试数据处理方法。
尝试两种方法:
Linear Interpolation
对 NaN 进行线性插值。
Sliding Window
window = 4096 stride = 1024
实验结果:
| Method | Mean Acc |
|---|---|
| Baseline | 0.593 |
| + Linear Interpolation | 0.595 |
| + Linear Interpolation + Sliding Window | 0.603 |
结论:
-
NaN 插值略有提升
-
Sliding window 可以增加训练样本
八、模型探索:CNN + Mamba
尝试新的模型结构。
观察到:
ConvMHSA InceptionTime
均为 CNN 架构,且表现明显优于 MiniRocket。
因此尝试以 CNN 为 backbone。
为什么选择 Mamba?
在长序列建模中常见模型包括:
LSTM Transformer Mamba
Transformer 在长序列下计算复杂度为:
O(n²)
而 Mamba:
O(n)
更适合长序列任务。
因此尝试结构:
CNN + Mamba
设计思路:
CNN → 提取局部特征 Mamba → 建模长序列依赖
九、变长序列处理
对于变长序列,采用 Length Bucket Batch Sampling。
流程:
按长度分桶 ↓ 相似长度进入同一 batch ↓ batch 内 padding ↓ 生成 mask
输入形式:
(B, T, C)
十、模型实验结果
| Model | Mean Acc |
|---|---|
| CNN-only | 0.790 |
| CNN+BiMamba-v1 | 0.799 |
| CNN+BiMamba-v2 | 0.807 |
| CNN+BiMamba-v3 | 0.810 |
结果说明:
-
CNN-only 已表现很好
-
加入 Mamba 后进一步提升
十一、总结
复现了 NGAFID 数据集中的 maintenance event detection 任务,并成功复现论文 baseline 模型。
主要结论:
-
baseline 模型基本可复现
-
NaN 插值 + sliding window 可提升性能
-
CNN 在该任务中表现较好
-
CNN + Mamba 可以进一步提升性能
复现任务的实现加深了对 航空时间序列建模 和 长序列模型 的理解。主要学习到:健康管理(PHM)任务中,数据通常表现为 长时间跨度的多变量时间序列,即在连续时间点上记录多个传感器的状态指标,并按照时间顺序组织形成序列数据。在模型输入阶段,这类数据在处理方式上可以借鉴 自然语言处理(NLP)中对长短不一序列的处理方法。然而,两者在数据特性上仍存在明显差异:以飞机健康管理为例,时间序列往往具有清晰的阶段性结构,例如起飞、爬升、巡航和降落等飞行阶段;而在 NLP 任务中,模型更多关注的是词或字符之间的语义关联关系。因此,在进行航空时间序列建模时,需要同时考虑序列的 时间依赖性与阶段性结构特征。
本文代码链接:https://github.com/SongX-1/NGAFIDDATASET.git
欢迎大家多多交流讨论,特别是关于InceptionTime的复现。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)